
- 1省钱!NewBing硬核新玩法;手把手教你训练AI模特;用AI替代同事的指南;B站最易上手AI绘画教程 | ShowMeAI日报_ai绘画教程bilibili
- 2一口气说出 Redis 16 个常见使用场景_redis使用场景
- 3动态规划-思考解决动态规划问题_你的公司老板给了你一张n×n个格子组成的动态规划
- 4B样条曲线优化各种路径规划算法,matlab栅格地图。_b样条优化
- 5three.js流动线_threejs流动线
- 6自然语言处理工具包:NLTKspaCy
- 7超星高级语言程序设计实验作业 (实验01顺序程序设计)_分别输入三个浮点数代表a、b、c的值;如果c的值为0,直接输出-1,否则计算并输出多项
- 8笔记本wifi与台式机、内网服务器共网、共享wifi详细教程_服务器没有网,怎么共享笔记本网络
- 9核函数kernal
- 10Android~获取WiFi MAC地址和IP方法汇总_android 获取本机wlan mac地址
3D卷积网络论文阅读笔记_swin unetr: swin transformers for semantic segment
赞
踩
3D卷积网络
- 1、What is the best data augmentation approach for brain tumor segmentation using 3D U-Net?
- 2、TransBTS: Multimodal Brain Tumor Segmentation Using Transformer
- 3、TransBTSV2: Wider Instead of Deeper Transformer for Medical Image Segmentation
- 4、Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images
- 5、Robust Semantic Segmentation of Brain Tumor Regions from 3D MRIs
- 6、Fully Transformer Networks for Semantic Image Segmentation
1、What is the best data augmentation approach for brain tumor segmentation using 3D U-Net?
实验
数据集
BraTS 2020
数据增强方法
• Flipping翻转: 以1/3的概率随机沿着三个轴之一翻转
• Rotation旋转: 从限定范围(0到 15◦或到30◦或到60◦或到90◦)的均匀分布中随机选择角度旋转
• Scale缩放: 通过从范围为±10%或为±20%的均匀分布中随机选择的因子,对每个轴进行缩放
• Brightness亮度调整: 幂律γ强度变换,其参数增益(g)和γ从均匀分布的0.8-1.2之间随机选择。亮度(I)根据公式:Inew=g·Iγ随机改变
• Elastic deformation弹性变形: 带正方形变形网格的弹性变形,位移采样来自标准差σ=2、4、6或8体素的正态分布,其中平滑由每个维的3阶样条滤波器完成
实验结果
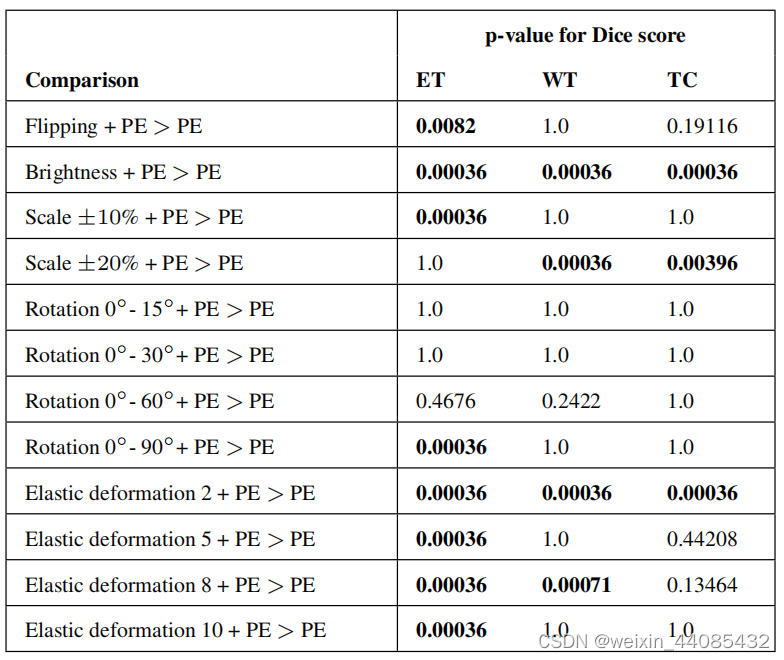
PE:Patch extraction
结论
数据增强在许多情况下显著提高了分割网络的性能,且亮度增强和弹性形变的效果最好,并且与仅使用一种增强技术相比,不同的增强技术的组合并不能提供进一步的改进。
代码
(作者的EVALUATION OF AUGMENTATION METHODS IN CLASSIFYING AUTISM SPECTRUM DISORDERS FROM FMRI DATA WITH 3D CONVOLUTIONAL NEURAL NETWORKS表明,数据增强对分类的准确性只提供了微小的改进)
2、TransBTS: Multimodal Brain Tumor Segmentation Using Transformer
代码:https://github.com/Wenxuan-1119/TransBTS
论文:https://arxiv.org/abs/2103.04430
创新点
使用卷积提取局部特征,使用transformer得到全局特征;
网络结构
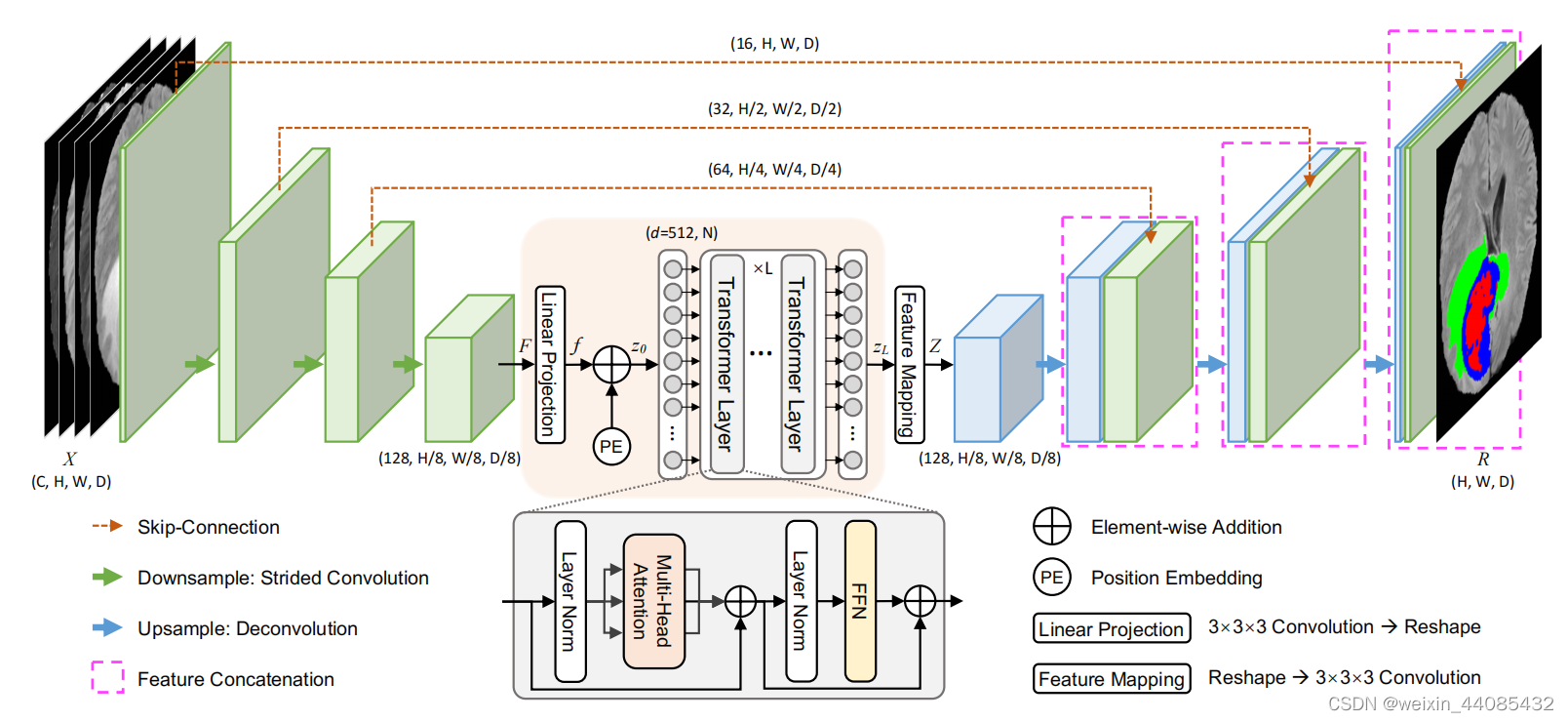
类似于3d U-net,有收缩路径和展开路径,但是用跨步卷积取代了双卷积+最大池化
实验
数据集
BraTS2019: 335 cases of patients for training and 125 cases for validation
BraTS2020: 369 cases for training, 125 cases for validation and 166 cases for testing
标签
标签具有四个类别:背景(0),坏死性和非增强性肿瘤(标记1),肿瘤周围水肿(2)和GD增强性肿瘤(4)。
评价指标
通过Dice系数和Hausdirff距离(95%)指标来测量分割的准确性,以增强区域(ET,1),肿瘤核心区域(TC,1,4)以及整个肿瘤区域(WT,1,2,4)。
数据增强
(1) random cropping: from 240 × 240 × 155 to 128 × 128 × 128
(2) random mirror flipping across the axial, coronal and sagittal planes by a probability of 0.5
(3) random intensity shift between [-0.1, 0.1] and scale between [0.9, 1.1].
训练细节
softmax Dice损失用于训练网络,L2 Norm用于正则化,权重衰减率为10-5
实验结果
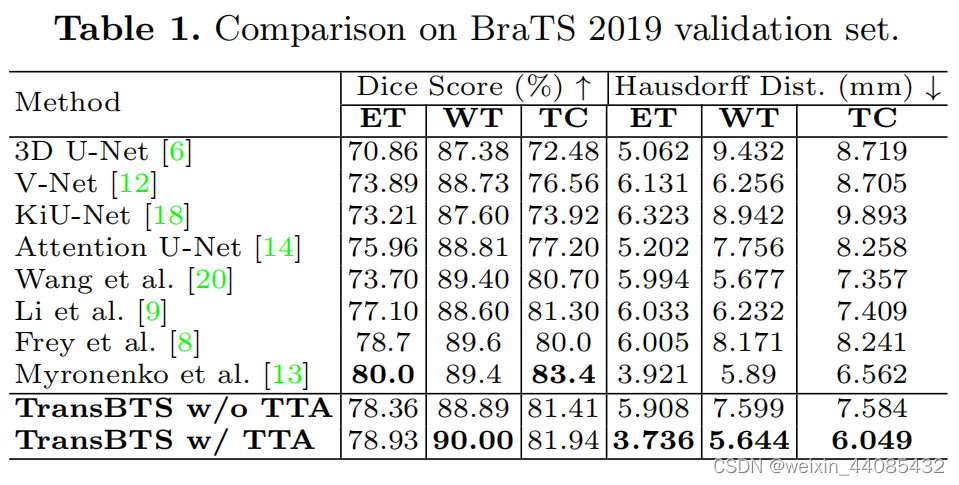
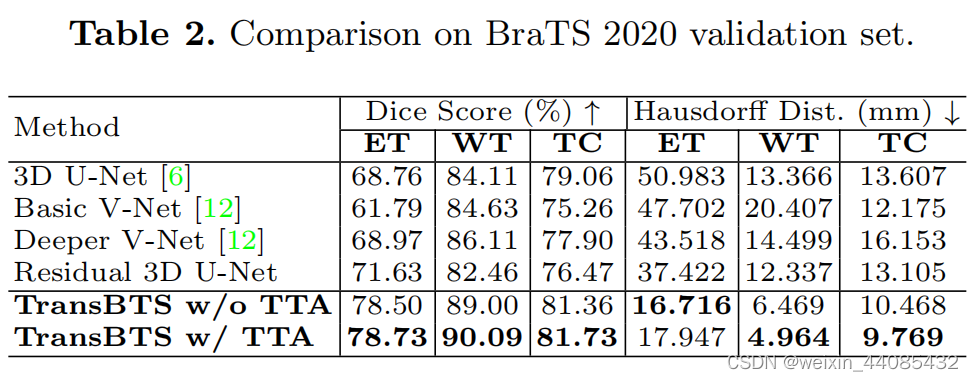
(在评论区看到复现效果差,存疑)
3、TransBTSV2: Wider Instead of Deeper Transformer for Medical Image Segmentation
代码:https://github.com/Wenxuan-1119/TransBTS
论文:https://arxiv.org/abs/2201.12785
创新点
(1)Transformer中原始的自注意机制导致了关于序列长度的O(n2)时间和空间复杂度。同时Transformer的性能在很大程度上取决于数据集的规模,为了缓解这个问题,许多最先进的方法转向大规模数据集的预训练。然而,医学图像数据集普遍缺乏可用的训练样本,使得Transformer对医学图像的预训练变得不切实际
inspired by the inverted design in MobileNetV2, we propose a
novel insight to pursue wider instead of deeper Transformer
architecture.
采取这种方法,与最初的TransBTS相比,模型复杂性显著降低(参数减少了53.62%,FLOPs减少了27.75%)
(2)不规则形病变给医学图像分割带来了巨大的挑战。在U-Net体系结构中,编码器中的特征图对几何信息更为敏感,对目标区域的识别也至关重要。
为此,提出了一个有效的和高效的可变形瓶颈模块(DBM),它可以从编码器特征学习体积空间偏移,并适应分割目标的各种转换。
网络结构
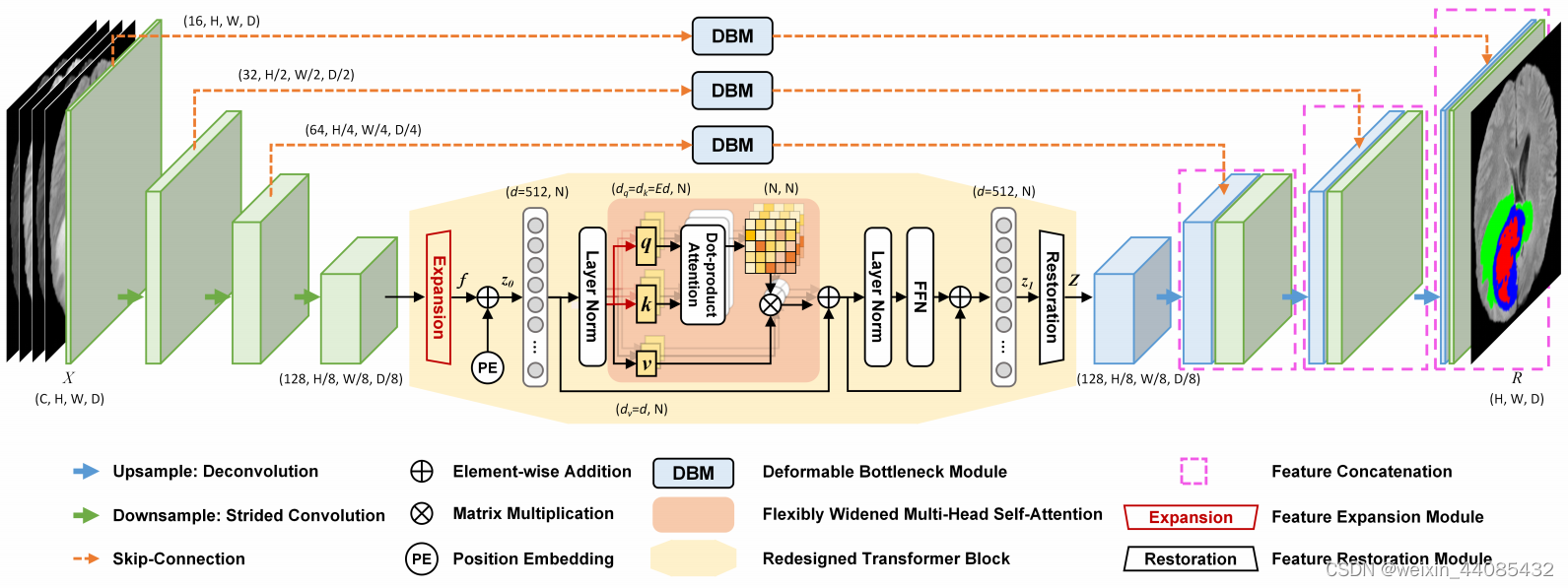
Transformer部分由L个重新设计的Transformer模块组成,每个模块包含flexibly widened multihead self-attention (FW-MHSA) block和feed-forward
Network (FFN)
第l个模块的输出可以表示为:(LN(∗) is the layer normalization)
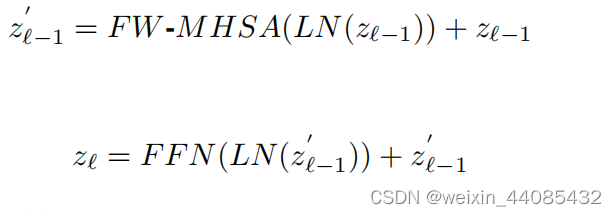
在最初的TransBTS中,transformer层的数量为L=4,Transformer部分占模型参数的70.81%。在本文章中,把transformer层数减为1,但是宽度变为2。
DBM模块
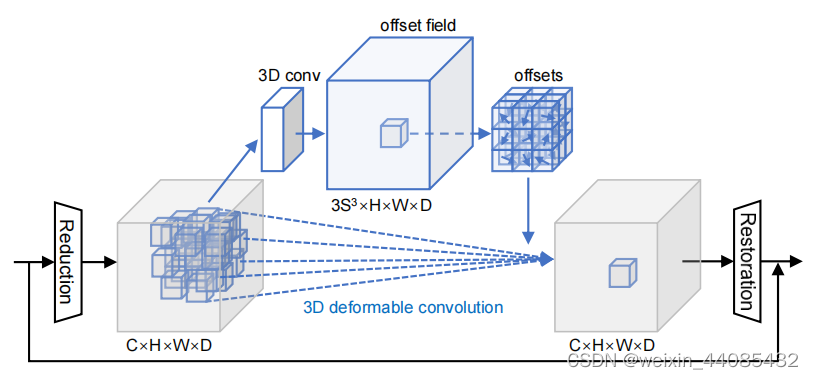
每个DBM由两个1×1×1卷积、一个3×3×3可变形卷积和传统残差连接组成。为了最大限度地减少提出的DBM带来的计算开销,作者部署了两个1 × 1 × 1卷积(即上图所示的Reduction和Restoration layer)来降低和恢复信道维数
实验
数据集和对应的数据增强方法
(1)BraTS 2019 and BraTS 2020
灰度强度归一化、
(2)LiTS 2017
(3)KiTS 2019
在LiTS2017和KiTS2019数据集上,由于这两个CT数据集的体素间隔是不均匀的,因此需要将所有情况重新采样到一个共同的体素间距。
random cropping, random mirror flipping and random intensity shift
实验结果
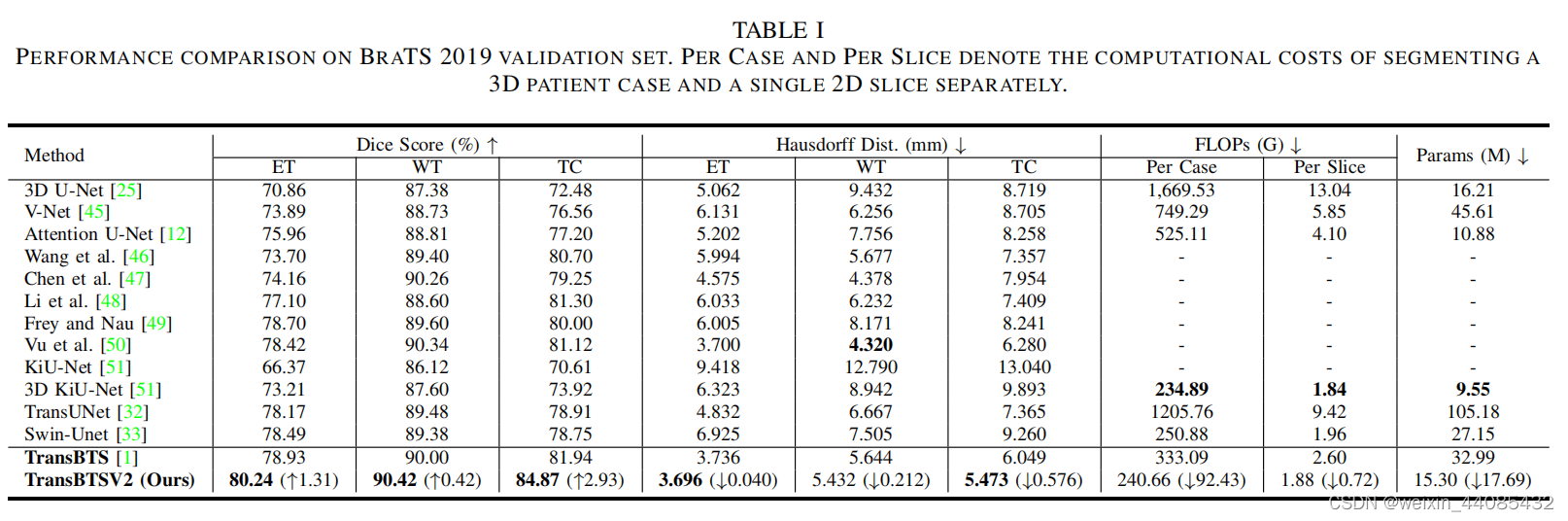
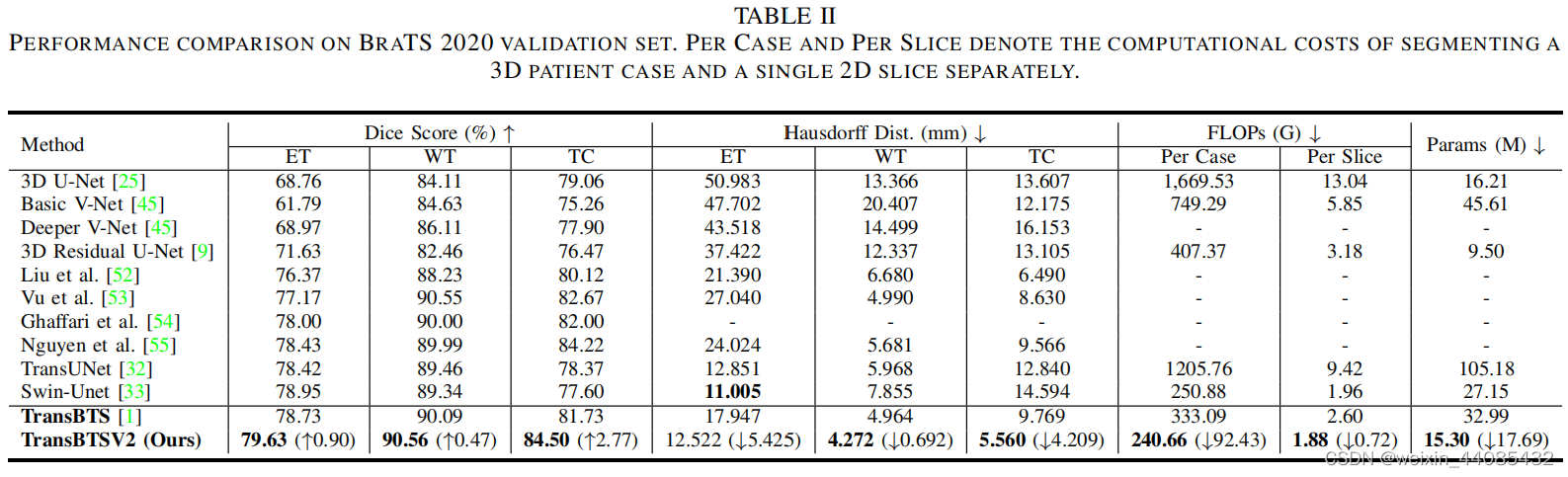
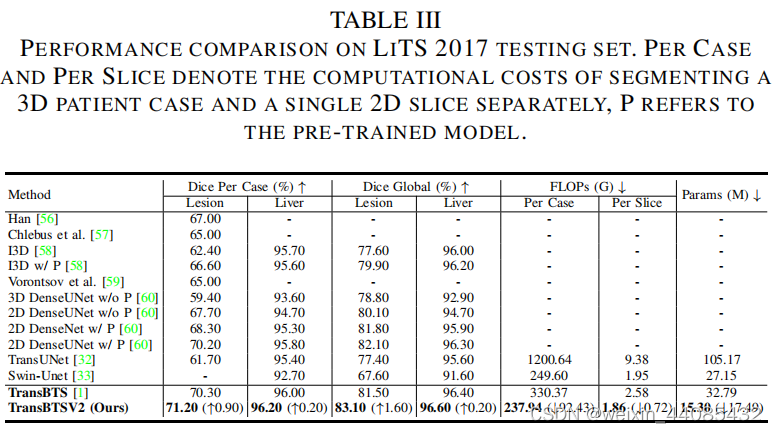
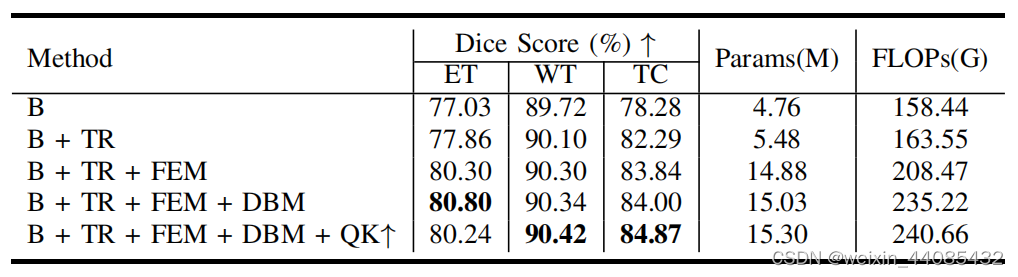
B, TR, FEM, DBM, QK↑ REFERS TO BASELINE, TRANSFORMER, FEATURE EXPANSION MODULE, DEFORMABLE BOTTLENECK MODULE, THE PROPOSED FW-MHSA IN REDESIGNED TRANSFORMER BLOCK.
TransBTS是一个中等大小的模型,具有32.99M参数和333G FLOPs。通过本文提出的改进架构设计,TransBTSV2只有15.30M参数和241G FLOPs,与作者原来的TransBTS相比,追求更宽而不是更深的Transformer可以大大降低复杂度(参数减少53.62%,FLOPs减少27.63%),但同时显著提高了模型性能。

