- 1Navicat for MYSQL破解教程
- 2【ROS2机器人入门到实战】Navigation 2 介绍与安装_navigation2源码安装
- 3【问题】git --no-replace-objects ls-remote ssh://git@github.com/nhn/raphael.git
- 4uniapp app运行到ios详细流程_uniapp用window电脑运行到ios
- 5大数据分析R中泊松回归模型实例
- 6mac地址厂商查询_3.15干货你的手机mac地址泄漏了吗
- 7MySQL中的SUM函数使用示例_假设有一个名为orders的表,包含以下列:order_id(订单id)、customer_id(客
- 8虚拟机配置(hadoop)前置准备
- 9AI视频教程下载:用ChatGPT和React.js开发AI聊天机器人
- 10常规波束形成——时域与频域常规窄带波束形成、信噪比计算(附代码)
【自然语言处理】seq2seq模型—机器翻译_seq2seq模型——机器翻译
赞
踩
清华大学驭风计划课程链接
学堂在线 - 精品在线课程学习平台 (xuetangx.com)
代码和报告均为本人自己实现(实验满分),只展示主要任务实验结果,如果需要详细的实验报告或者代码可以私聊博主
有任何疑问或者问题,也欢迎私信博主,大家可以相互讨论交流哟~~
案例简介
seq2seq是神经机器翻译的主流框架,如今的商用机器翻译系统大多都基于其构建,在本案例中,我们将使用由NIST提供的中英文本数据训练一个简单的中英翻译系统,在实践中学习seq2seq的具体细节,以及了解机器翻译的基本技术。
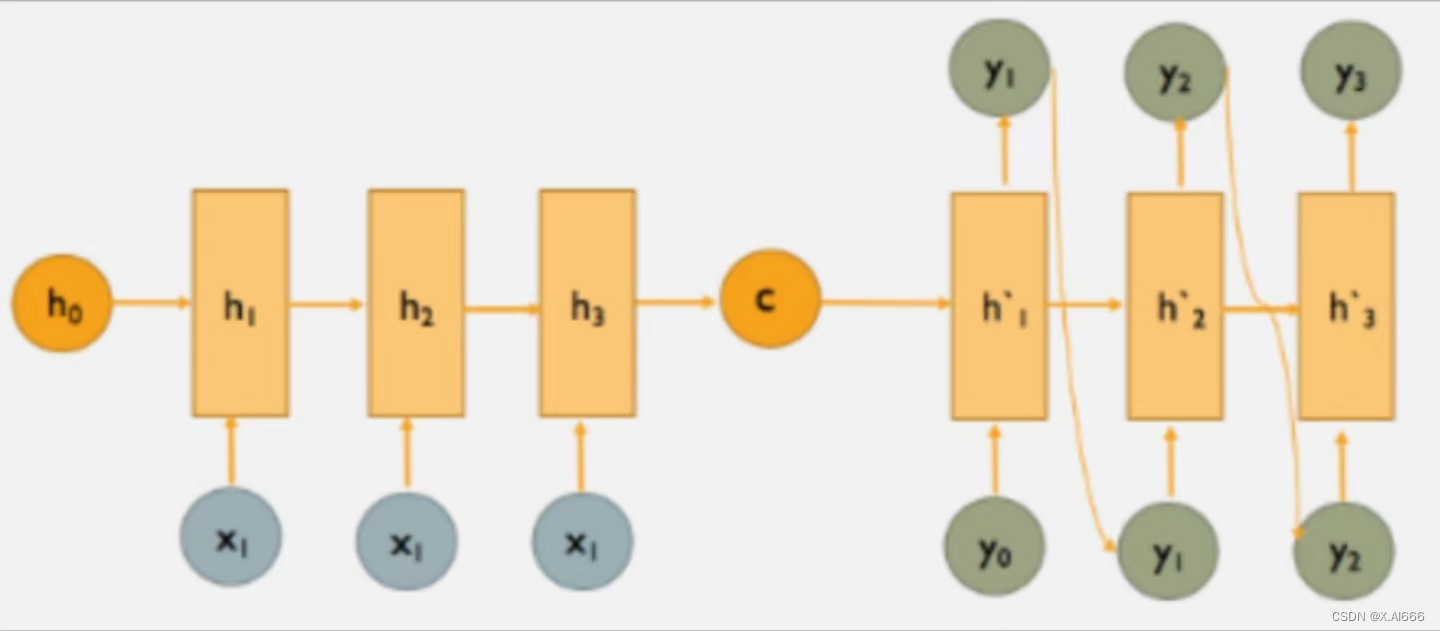
seq2seq模型
从根本上讲,机器翻译需要将输入序列(源语言中的单词)映射到输出序列(目标语言中的单词)。正如我们在课堂上讨论的那样,递归神经网络(RNN)可有效处理此类顺序数据。机器翻译中的一个重要难题是输入和输出序列之间没有一对一的对应关系。即,序列通常具有不同的长度,并且单词对应可以是不平凡的(例如,彼此直接翻译的单词可能不会以相同的顺序出现)。
为了解决这个问题,我们将使用一种更灵活的架构,称为seq2seq模型。该模型由编码器和解码器两部分组成,它们都是RNN。编码器将源语言中的单词序列作为输入,并输出RNN层的最终隐藏状态。解码器与之类似,除了它还具有一个附加的全连接层(带有softmax激活),用于定义翻译中下一个单词的概率分布。以此方式,解码器本质上用作目标语言的神经语言模型。关键区别在于,解码器将编码器的输出用作其初始隐藏状态,而不是零向量。
数据和代码
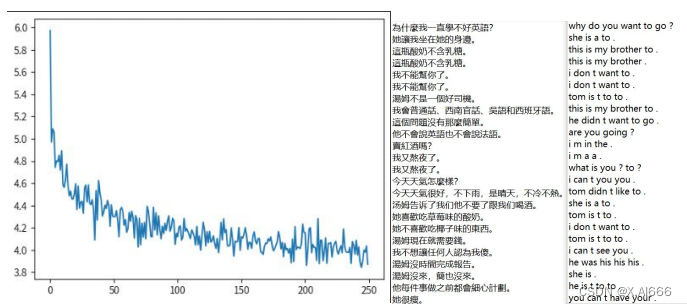
本案例使用了一个小规模的中英平行语料数据,并提供了一个简单的seq2seq模型实现,包括数据的预处理、模型的训练、以及简单的评测。
评分要求
分数由两部分组成,各占50%。第一部分得分为对于简单seq2seq模型的改进,并撰写实验报告,改进方式多样,下一小节会给出一些可能的改进方向。第二分部得分为测试数据的评测结果,我们将给出一个中文测试数据集(test.txt),其中每一行为一句中文文本,需要同学提交模型做出的对应翻译结果,助教将对于大家的提交结果统一机器评测,并给出分数。请以附件形式提交实验报告!
改进方向
初级改进:
-
将RNN模型替换成GRU或者LSTM
-
使用双向的encoder获得更好的源语言表示
-
对于现有超参数进行调优,这里建议划分出一个开发集,在开发集上进行grid search,并且在报告中汇报开发集结果
-
引入更多的训练语料(如果尝试复杂模型,更多的训练数据将非常关键)
进阶改进:
-
使用注意力机制(注意力机制是一个很重要的NMT技术,建议大家优先进行这方面的尝试,具体有许多种变体,可以参考这个综述)
-
在Encoder部分,使用了字级别的中文输入,可以考虑加入分词的结果,并且将Encoder的词向量替换为预训练过的词向量,获得更好的性能
复杂改进:
-
使用beam search的技术来帮助更好的解码,对于beam-width进行调优
-
将RNN替换为Transformer模型,以及最新的改进变体