
- 1Python列表操作详解_python的列表用法
- 2MATLAB --- 绘图 axis与axes_在matlb使用axis画扁平图
- 3CNN卷积神经网络实现验证码识别(准确率达99%)_如何提高深度学习验证码识别概率
- 4初识redis——分布式系统概念
- 5智能车电磁环岛处理方法_山东宁川水处理:电磁阀常见故障与解决方法
- 6git怎么合并两个分支_两个分支合并
- 7Python 人工智能实战|产生式规则推理系统:动物识别系统、智能客服系统_python动物识别系统
- 8人们记住他的名字 国研政情·谋定论道:桂海潮 一条不孤独的路
- 9GAI工具哪家强?(ChatGPT 4 vs 文心一言)
- 10基于Springboot的数字化农家乐管理平台(有报告)。Javaee项目,springboot项目。
Android应用程序开发以及背后的设计思想深度剖析(4)_掌握android 编程的基本思想
赞
踩
1.4 性能
Android使用Java作为编程语言,这一直被认为是一局雄心万丈,但凶险异常的险棋。Java的好处是多,前面我们只是列举了一小部分,但另一种普遍的现象是,Java在图形编程上的应用环境并不是那么多。除了出于Java编程的目的,我们是否使用过Java编写的应用程序?我们的传统手机一般都支持Java ME版本,有多少人用过?我们是否见过Java写就的很流畅的应用程序?是否有过流行的Java操作系统?答应应该是几乎为零。通过这些疑问,我们就可以多少了解,Android这个Java移动操作系统难度了,还不用说,我们前面看到各种设计上的考量。
首先,得给Java正名,并非Java有多么严重的性能问题,事实上,Java本是一种高效的运行环境。Android在设计上的两个选择,一个Linux内核,一个Java编程语言,都是神奇的万能胶,从服务器、桌面系统、嵌入式平台,它们都在整个计算机产业里表现了强大的实力,在各个领域里都霸主级的神器(当然,两者在桌面领域表现都不是很好,都受到了Windows的强大压力)。从Java可以充当服务器的编程语言,我们就可以知道Java本身的性能是够强大的。标准的Java虚拟机还有个特点,性能几乎会与内存与处理器能力成正比,内存越大CPU能力越强,当JIT的威力完全发挥出来时,Java语言的性能会比C/C++写出来的代码的性能还要好。
但是,这不是嵌入式环境的特色,嵌入式设备不仅是CPU与内存有限,而且还不能滥用,需要尽可能节省电源的使用。这种特殊的需求下,还需要使用Java虚拟机,就得到一个通用性极佳,但几乎无用的JAVA ME环境,因为JAVA ME的应用程序与本地代码的性能差异实在太大了。在iPhone引发的“后PC时代”之前,大家没得选择,每台手机上几乎都支持,但使用率很低。而我们现在看到的Android系统,性能上是绝对不成问题,即便是面对iPhone这样大量使用加速引擎的嵌入式设备,也没有明确差异,这里面窍门在哪里呢?
我们前面也说明了,Java在嵌入式环境里有性能问题,运行时过低的执行效率会引发使用体验问题,同时还有版权问题,几乎没有免费的嵌入式Java解决方案。如果正向去解,困难重重,那我们是否可以尝试逆向的解法呢?
在计算机工程领域,逆向思维从来都是重要武器之一,当我们在设计、算法上遇到问题时,正向解决过于痛苦时,可以逆向思考一下,往往会有奇效。比如我们做算法优化,拼了命使用各种手法提高性能,收效也不高,这时我们也可以考虑一下降低其他部分的性能。成功案例在Android里就有,在Android环境里,大量使用Thumb2这样非优化指令,只优化性能需求最强的代码,这时系统整体的性能反而比全局优化性能更好。我们做安全机制,试验各种理论模型,最终都失败于复杂带来的开销,而我们反向思考一下,借用进程模型来重新设计,这时我们就得到了“沙盒”这种模型,反而简便快捷。只要思路开阔,在计算机科学里条条大路通罗马,应该是没有解不掉的问题的。
回到Android的Java问题,如果我们正向地顺着传统Java系统的设计思路会走入痛苦之境,何不逆向朝着反Java的思路去尝试呢?这时还带来了边际收益,Java语言的版权问题也绕开了。于是,天才的Android设计者们,得到了基于Dalvik虚拟机方案:
基于寄存器式访问的Dalvik VM
Java语言天生是用于提升跨平台能力的,于是在设计与优化时,考虑得更多是如何兼容更多的环境,于它可以运行在服务器级别的环境里,也在运行在嵌入式环境。这种可伸缩的能力,便源自于它使用栈式的虚拟机实现。所谓的栈式虚拟机,就是在Java执行环境在边解释边执行的时候,尽可能使用栈来保存操作数与结果,这样可设计更精练的虚拟指令的翻译器,性能很高,但麻烦就在于需要过多地访问内存,因为栈即内存。
比如,我们写一个最简单的Java方法,读两个操作数,先加,然后乘以2,最后返回:
- public int test01( int i1, int i2 ) {
- int i3 = i1 + i2;
- return i3 * 2;
- }
- 0000: iload_1 // 01
- 0001: iload_2 // 02
- 0002: iadd
- 0003: istore_3 // 03
- 0004: iload_3 // 03
- 0005: iconst_2 // #+02
- 0006: imul
- 0007: ireturn
但问题是内存的访问过多,在嵌入式设备上则会造成性能问题。嵌入式平台上,出于成本与电池供电的因素,内存是很有限的,Android刚开始时使用的所谓顶级硬件配置,也才不过192MB。虽然现在我们现在的手机动不动就上G,还有2G的怪兽机,但我们也不太可能使用太高的内存总线频率,频率高了则功耗也就会更高,而内存总线的功耗限制也使内存的访问速度并不会太高,与PC环境还是有很大差异的。所以,直到今天,标准Java虚拟的ARM版本也没有实现,只是使用JAVA ME框架里的一种叫KVM的一种嵌入式版本上的特殊虚拟机。
基于Java虚拟机的实现,于是这时就可以使用逆向思维进行设计,栈式虚拟机的对立面就是寄存器式的。于是Android在系统设计便使用了Dan Bornstein开发的,基于寄存器式结构的虚拟机,命名源自于芬兰的一个小镇Dalvik,也就是Dalivk虚拟机。虽然Dalvik虚拟机在实现上有很多技巧的部分,有些甚至还是黑客式的实现,但其核心思想就是寄存器式的实现。
所谓的寄存器式,就是在虚拟机执行过程中,不再依赖于栈的访问,而转而尽可能直接使用寄存器进行操作。这跟传统的编程意义上的基于寄存器式的系统构架还是有概念上的区别,即便是我们的标准的栈式的标准Java虚拟机,在RISC体系里,我们也会在代码执行被优化成大量使用寄存器。而这里所指的寄存器,是指执行过程里的一种算法上的思路,就是不依赖于栈式的内存访问,而通过伪指令(opcode)里的虚拟寄存器来进行翻译,这种虚拟寄存器会在运行态被转义成空闲的寄存器,进行直接数操作。如果这里的解释不够清晰,大家可以把栈式看成是正常的函数式访问,几乎所有的语言都基于栈来实现函数调用,此时虚拟机里每个伪指令(opcode),都类似于基于栈进行了函数调用。而基于寄存器式,则可以被看成是宏,宏在执行之前就会被编译器翻译成直接执行的一段代码,这时将不再有过多的压栈出栈操作,而是会尽可能使用立即数进行运算。
我们上面标准虚拟机里编译出来的代码,经过dx工具转出来的.dex文件,格式就会跟上面很不一样:
代码编译伪指令
- 9000 0203 0000 add-int v0, v2, v3
- da00 0002 0002 mul-int/lit8 v0, v0, #int 2 // #02
- 0f00 0004 return v0
像Dalvik这样虚拟机实现里,当我们进行执行的时候,我们就可以通过将00,02,03这样的虚拟寄存器,找一个空闲的真实的寄存器换上去,执行时会将立即数通过这些寄存器进行运算,而不再使用频繁的栈进行存取操作。这时得到的代码大小、执行性能都得到了提升。
如果寄存器式的虚拟机实现这么好,为什么不大家都使用这种方式呢?也不是没有过尝试,寄存器试的虚拟机实现一直是学术研究上的一个热点,只是在Dalvik虚拟机之前,没有成功过。寄存器式,在实际应用中,未必会比栈式更高效,而且如果是通用的Java虚拟机,需要运行在各种不同平台上,寄存器式实现还有着天生的缺陷。比如说性能,我们也看到在Dalvik的这种伪指令体系里,使用16位的opcode用于实现更多支持,没有栈访问,则不得不靠增加opcode来弥补,再加需要进行虚拟寄存器的换算,这时解析器(Interpreter)在优化时就远比简单的8位解析器要复杂得多,复杂则优化起来更困难。从上面的函数与宏的对比里,我们也可以看到寄存器实现上的毛病,代码的重复量会变大,原来不停操作栈的8bit代码会变成更长的加寄存器操作的代码,理论上这种代码会使代码体系变大。之所以在前面我们看到.dex代码反而更精减,只不过是Dalvik虚拟机进行了牺牲通用性代码固化,这解决了问题,但会影响到伪代码的可移植性。在栈式虚拟机里,都使用8bit指令反复操作栈,于是理论上16bit、32bit、64bit,都可以有针对性的优化,而寄存器式则不可能,像我们的Dalvik虚拟机,我们可以看到它的伪代码会使用32位里每个bit,这样的方式不可能通用,16bit、32bit、64bit的处理器体系里,都需要重新设计一整套新的指令体系,完全没有通用性。最后,所有的操作都不再经过栈,则在运行态要得到正确的运算操作的历史就很难,于是JIT则几乎成了不可能完成的任务,于是Dalvik虚拟机刚开始则宣称JIT是没有必要,虽然从2.2开始加入了JIT,但这种JIT也只是统计意义上的,并不是完整意义上的JIT运算加速。所有这些因素,都导致在标准Java虚拟机里,很难做出像Dalvik这样的寄存器式的虚拟机。
幸运的是,我们上面说的这些限制条件,对Android来说,都不存在。嵌入式环境里的CPU与内存都是有限的资源,我们不太可能通过全面的JIT提升性能,而嵌入式环境以寄存器访问基础的RISC构架为主,从理论上来说,寄存器式的虚拟机将拥有更高的性能。如果是嵌入式平台,则基本上都是32位的处理器,而出于功耗上的限制,这种状况将持续很长一段时间,于是代码通用性的需求不是那么高。如果我们放弃全面支持Java执行环境的兼容性,进一步通过固化设计来提升性,这时我们就可以得到一个有商用价值的寄存器式的虚拟机,于是,我们就得到了Dalvik。
Dalvik虚拟机的性能上是不是比传统的栈式实现有更高性能,一直是一个有争议的话题,特别是后面当Dalvik也从2.2之后也不得不开始进行JIT尝试之后。我们可以想像,基于前面提到的寄存器式的虚拟机的实现原理,Dalvik虚拟机通过JIT进行性能提升会遇到困难。在Dalvik引入JIT后,性能得到了好几倍的提升,但Dalvik上的这种JIT,并非完整的JIT,如果是栈式的虚拟机实现,这方面的提升会要更强大。但Dalvik实现本身对于Android来讲是意义非凡的,在Java授权上绕开了限制,更何况在Android诞生时,嵌入式上的硬件条件极度受限,是不太可能通过栈式虚拟机方式来实现出一个性能足够的嵌入式产品的。而当Android系统通过Dalvik虚拟机成功杀出一条血路,让大家都认可这套系统之后,围绕Android来进行虚拟机提速也就变得更现实了,比如现在也有使用更好的虚拟机来改进Android的尝试,比如标准栈式虚拟机,使用改进版的Java语言的变种,像Scalar、Groovy等。
我们再看看,在寄存器式的虚拟机之外,Android在性能设计上的其他一些特点。
以Android API为基础,不再以Java标准为基础
当我们对外提供的是一个系统,一种平台之时,就必须要考虑到系统的可持续升级的能力,同时又需要保持这种升级之后的向后兼容性。使用Java语言作为编程基础,使我们的Android环境,得到了另一项好处,那就是可兼容性的提升。
在传统的嵌入式Linux方案里,受限于有限的CPU,有限的内存,大家还没有能力去实施一套像Android这样使用中间语言的操作系统。使用C语言还需要加各种各样的加速技巧才能让系统可以运行,基至有时还需要通过硬件来进行加速,再在这种平台上运行虚拟机环境,则很不靠谱。这样的开发,当然没有升级性可言,连二次开发的能力都很有限,更不用说对话接口了,所谓的升级,仅仅是增加点功能,修改掉一些Bug,再加入再多Bug。而使用机器可以直接执行的代码,就算是能够提供升级和二次开发的能力,也会有严重问题。这样的写出来的代码,在不同体系架构的机器(比如ARM、X86、MIPS、PowerPC)上,都需要重新编译一次。更严重的是,我们的C或者C++,都是通过参数压栈,再进行指令跳转来进行函数调用的,如果升级造成了函数参数变动,则还必须修改所开发的源代码,不然会直接崩溃掉。而比较幸运的是,所有的嵌入式Linux方案,在Android之前,都没有流行开,比较成功的最多也不过自己陪自己玩,份额很小,大部分则都是红颜薄命,出生时是demo,消亡时也是demo。不然,这样的产品,将来维护起来也会是个很吐血的过程。
而Android所使用的Java,从一开始就是被定位于“一次编写,到处运行”的,不用说它极强大的跨平台能力,就是其升级性与兼容性,也都是Java语言的制胜法宝之一。Java编译生成的结果,是.class的伪代码,是需要由虚拟器来解析执行的,我们可以提供不同体系构架里实现的Java虚拟机,甚至可以是不同产商设计生产的Java虚拟机,而这些不同虚拟机,都可以执行已经编译过的.class文件,完全不需要重新编译。Java是一种高级语言,具有极大的重用性,除非是极端的无法兼容接口变动,都可以通过重载来获得更高可升级能力。最后,Java在历史曾应用于多种用途的运行环境,于是定义针对不同场合的API标准,这些标准一般被称为JSR(Java Specification Request),特别是嵌入式平台,针对带不带屏幕、屏幕大小,运算能力,都定义了详细而复杂的标准,符合了这些标准的虚拟机应该会提供某种能力,从而保证符合同一标准的应用程序得以正常执行。我们的JAVA ME,就是这样的产物,在比较长周期内,因为没有可选编程方案,JAVA ME在诸多领域里都成为了工业标准,但性能不佳,实用性较差。
JAVA ME之所以性能会不佳的一个重要原因,是它只是一种规范,作为规范的东西,则需要考虑到不同平台资源上的不同,不容易追求极致,而且在长期的开发与使用的历史里,一些历史上的接口,也成为了进一步提升的负担。Android则不一样,它是一个新生事物,它不需要遵守任何标准,即使它能够提供JAVA ME兼容,它能得到资源回报也不会大,而且会带来JAVA ME的授权费用。于是,Android在设计上就采取了另一次的反Java设计,不兼容任何Java标准,而只以Android的API作为其兼容性的基础,这样就没有了历史包袱,可以轻装上阵进行开发,也大大减小了维护的工作量。作为一个Java写的操作系统,但又不兼容任何Java标准,这貌似是比较讽刺的,但我们在整个行业内四顾一下,大家应该都会发现这样一种特色,所有不支持JAVA ME标准的系统,都发展得很好,而支持JAVA ME标准,则多被时代所淘汰。这不能说JAVA ME有多大的缺陷,或是晦气太重,只不过靠支持JAVA ME来提供有限开发能力的系统,的确也会受限于可开发能力,无法走得太远罢了。
这样会不会导致Java写的代码在Android环境里运行不起来呢?理论上来说不会。如果是一些Java写的通用算法,因为只涉及语言本身,不存在问题。如果是代码里涉及一些基本的IO、网络等通用操作,Android也使用了Apache组织的Harmony的Java IO库实现,也不会有不兼容性。唯一不能兼容的是一些Java规范里的特殊代码,像图形接口、窗口、Swing等方面的代码。而我们在Android系统里编程,最好也可以把算法与界面层代码分离,这样可以增加代码复用性,也可以保证在UI编程上,保持跟Android系统的兼容性。
Android的版本有两层作用,一是描述系统某一个阶段性的软硬件功能,另外就是用于界定API的规范。描述功能的作用,更多地用于宣传,用于说该版本的Android是个什么东西,也就是我们常见的食物版本号,像éclair(2.0,2.1),Froyo(2.2), Gingerbread(2.3),Icecream Sandswich(4.0),Jelly Bean(4.1),大家都可以通过这些美味的版本号,了解Android这个版本有什么功能,有趣而易于宣传。而对于这样的版本号,实际上也意味着API接口上的升级,会增加或是改变一些接口。
所谓的API版本,是位于应用程序层与Framework层之间的一层接口层,如下所示:
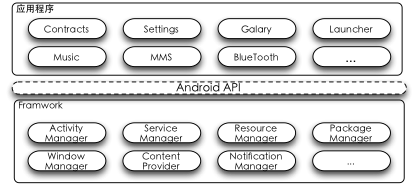
应用程序只通过AndroidAPI来对下进行访问,而我们每一个版本的Android系统,都会通过Framework来对上实现一套完整的API接口,提供给应用程序访问。只要上下两层这种调用与被调用的需求能够在一定范围内合拍,应用程序所需要的最低API版本低于Framework所提供的版本,这时应用程序就可以正常执行。从这个意义来说,API的版本,更大程度算是Android Framework实现上的版本,而Android系统,我们也可以看成就是Android的Framework层。
这种机制在Android发展过程中一直实施得很好,直到Android 2.3,都保持了向前发展,同时也保持向后兼容。Android 2.3也是Android历史上的一个里程碑,一台智能手机所应该实现的功能,Android2.3都基本上完成了。但这时又出现了平板(pad)的系统需求,从2.3又发展出一个跟手机平台不兼容的3.0,然后这两个版本再到4.0进行融合。在2.3到4..0,因为运行机制都有大的变动,于是这样的兼容性遇到了一定的挑战,现在还是无法实现100%的从4.0到2.3的兼容。
只兼容自己API,是Android系统自信的一种体现,同时,也给它带来另一个好处,那就是可以大量使用JNI加速。
大量使用JNI加速
JNI,全称是Java本地化接口层(Java Native Interface),就是通过给Java虚拟机加动态链接库插件的方式,将一些Java环境原本不支持功能加入到系统中。
我们前面说到过Dalvik虚拟机在JIT实现上有缺陷,这点在Android设计人员的演示说明里,被狡猾地掩盖了。他们说,在Android编程里,JIT不是必须的,Android在2.2之前都不提供JIT支持,理由是应用程序不可能太复杂,同时Android本身是没有必要使用JIT,因为系统里大部分功能是通过JNI来调用机器代码(Native代码)来实现的。这点也体现了Android设计人员,作为技术狂热者的可爱之处,类似这样的错误还不少,比如Android刚开始的设计初衷是要改变大家编程的习惯,要通过Android应用程序在概念上的封装,去除掉进程、线程这样底层的概念;甚至他们还定义了一套工具,希望大家可以像玩积木一样,在图形界面里拖拉一下,在完全没有编程背景的情况下也可以编程;等等。这些错误当然也被Android强大的开源社区所改正了。但对于Android系统性能是由大量JNI来推进的,这点诊断倒没有错,Android发展也一直顺着这个方向在走。
Android系统实现里,大量使用JNI进行优化,这也是一个很大的反Java举动,在Java的世界里,为了保持在各个环境的兼容性,除了Java虚拟机这个必须与底层操作系统打交道的执行实体,以及一些无法绕开底层限制的IO接口,Java环境的所有代码,都尽可能使用Java语言来编写。通过这种方式,可以有效减小平台间差异所引发的不兼容。在Java虚拟机的开发文档里,有详尽的JNI编程说明,同时也强烈建议,这样的编程接口是需要避免使用的,使用了JNI,则会跟底层打上交道,这时就需要每个体系构架,每个不同操作系统都提供实现,并每种情况下都需要编译一次,维护的代价会过高。
但Android则是另一个情况,它只是借用Java编程语言,应用程序使用的只是Android API接口,不存在平台差异性问题。比如我们要把一个Android环境运行在不那么流行的MIPS平台之上,我们需要的JNI,是Android源代码在MIPS构架上实现并编译出来的结果,只要API兼容,则就不存在平台差异性。对于系统构架层次来说,使用JNI造成的差异性,在Framework层里,就已经被屏蔽掉了:
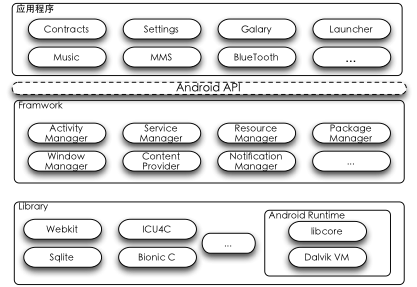
如上图所示,Android应用程序,只知道有Framework层,通过API接口与Framework通信。而我们底层,在Library层里,我们就可以使用大量的JNI,我们只需要在Framework向上的部分保持统一的接口就可以了。虽然我们的Library层在每个平台上都需要重新编译(有些部分可能还需要重新实现),但这是平台产商或是硬件产商的工作,应用程序开发者只需要针对API版本写代码,而不需要关心这种差异性。于是,我们即得到高效的性能(与纯用机器实现的软件系统没有多少性能差异),以使用到Java的一些高级特性。
单进程虚拟机
使用单进程虚拟机,是Android整个设计方案里反Java的又一表现。我们前面提到了,如果在Android系统里,要构建一种安全无忧的应用程序加载环境,这时,我们需要的是一种以进程为单位的“沙盒(Sandbox)”模型。在实现这种模型时,我们可以有多种选择,如果是遵循Java原则的话,我们的设计应该是这个样子的:
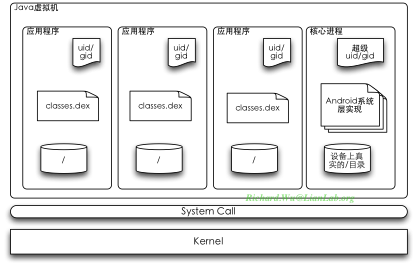
我们运行起Java环境,然后再在这个环境里构建应用程序的基于进程的“小牢房”。按照传统的计算机理论,或是从资源有效的角度考虑,特别是如果需要使用栈式的标准Java虚拟机,这些都是没话说的,只有这种构建方式才最优。
Java虚拟机,之所以被称为虚拟机,是因为它真通过一个用户态的虚拟机进程虚拟出了一个虚拟的计算机环境,是真正意义上的虚拟机。在这个环境里,执行.class写出来的伪代码,这个世界里的一切都是由对象构成的,支持进程,信号,Stream形式访问的文件等一切本该是实际操作系统所支持的功能。这样就抽象出来一个跟任何平台无关的Java世界。如果在这个Java虚拟世界时打造“沙盒”模式,则只能使用同一个Java虚拟机环境(这不光是进程,因为Java虚拟机内部还可以再创建出进程),这样就可以通过统一的垃圾收集器进行有效的对象管理,同时,多进程则内存有可能需要在多个进程空间里进行复制,在使用同一个Java虚拟机实例里,才有可能通过对象引用减小复制,不使用统一的Java虚拟机环境管理,则可复用性就会很低。
但这种方案,存在一些不容易解决的问题。这种单Java虚拟机环境的假设,是建立在标准Java虚拟机之上的,但如前面所说,这样的选择困难重重,于是Android是使用Dalvik虚拟机。这种单虚拟机实例设计,需要一个极其强大稳定的虚拟机实现,而我们的Dalvik虚拟机未必可以实现得如此功能复杂同时又能保证稳定性(简单稳定容易,复杂稳定则难)。Android必须要使用大量的JNI开发,于是会进一步破坏虚拟机的稳定性,如果系统里只有一个虚拟机实例,则这个实例将会非常脆弱。当在Java环境里的进程,有恶意代码或是实现不当,有可能破坏虚拟机环境,这时,我们只能靠重启虚拟机来完成恢复,这时会影响到虚拟机里运行的其他进程,失去了“沙盒”的意义。最后,虚拟机必须给预足够的权限运行,才能保证核心进程可访问硬件资源,则权限控制有可能被某个恶意应用程序破坏,从而失去对系统资源的保护。
Android既然使用是非标准的Dalvik虚拟机,我们就可以继续在反Java的道路上尝试得更远,于是,我们得到的是Android里的单进程虚拟机模型。在基于Dalvik虚拟机的方案里,虚拟机的作用退回到了解析器的阶段,并不再是一个完整的虚拟机,而只是进程中一个用于解析.dex伪代码的解析执行工具:
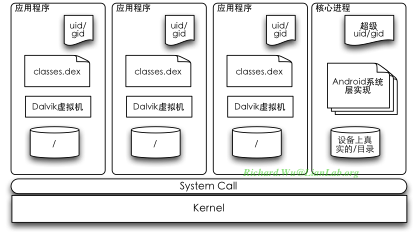
在这种沙盒模式里,每个进程都会执行起一个Dalvik虚拟机实例,应用程序在编程上,只能在这个受限的,以进程为单位的虚拟机实例里执行,任何出错,也只影响到这个应用程序的宿主进程本身,对系统,对其他进程都没有严重影响。这种单进程的虚拟机,只有当这个应用程序被调用到时才予以创建,也不存在什么需要重启的问题,出了错,杀掉出错进程,再创建一个新的进程即可。基于uid/gid的权限控制,在虚拟机之外的实现,应用程序完全不可能通过Java代码来破坏这种操作系统级别的权限控制,于是保护了系统。这时,我们的系统设计上反有了更高的灵活度,我们可以放心大胆地使用JNI开发,同时核心进程也有可能是直接通过C/C++写出来的本地化代码来实现,再通过JNI提供给Dalvik环境。而由于这时,由于我们降低了虚拟机在设计上的复杂程序,这时我们的执行性能必然会更好,更容易被优化。
当然,这种单进程虚拟机设计,在运行上也会带来一些问题,比如以进程以单位进行GC,数据必然在每个进程里都进行复制,而进程创建也是有开销的,造成程序启动缓慢,在跨进程的Intent调用时,严重影响用户体验。Java环境里的GC是标准的,这方面的开销倒是没法绕开,所以Android应用程序编程优化里的重要一招就是减小对象使用,绕开GC。但数据复制造成的冗余,以及进程创建的开销则可以进行精减,我们来看看Android如何解决这样的问题。
尽可能共享内存
在几乎所有的Unix进程管理模型里,都使用延时分配来处理代码的加载,从而达到减小内存使用的作用,Linux内核也不例外。所谓的进程,在Linux内核里只是带mm(虚存映射)的task_struct而已,而所谓的进程创建,就是通过fork()系统调用来创建一个进程,而在新创建的进程里使用execve()系列的系统调用来执行新的代码。这两个步骤是分两步进行,父进程调用fork(),子进程里调用execve():
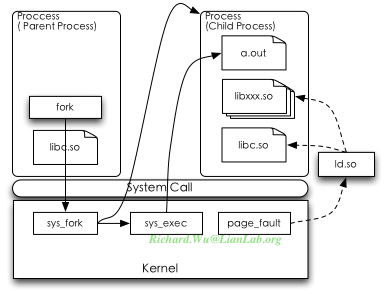
上图的实线代表了函数调用,虚线代码内存引用。在创建一个进程执行某些代码时,一个进程会调用fork(),这个fork()会通过libc,通过系统调用,转入内核实现的sys_fork()。然后在sys_fork()实现里,这时就会创建新的task_struct,也就是新的进程空间,形成父子进程关系。但是,这时,两个进程使用同一个进程空间。当被创建的子进程里,自己主动地调用了execve()系列的函数之后,这时才会去通过内核的sys_execve()去尝试解析和加载所要执行的文件,比如a.out文件,验证权限并加载成功之后,这时才会建立起新的虚存映射(mm),但此时虽然子进程有了自己独立的进程空间,并不会分配实际的物理内存。于是有了自己的进程空间,当下次执行到时,才会通过一次缺页中断加载a.out的代码段,数据段,而此时,libc.so因为两个进程都需要使用,于是会直接通过一次内存映射来完成。
通过Linux的进程创建,我们可以看到,进程之间虽然有独立的空间,但进程之间会大量地通过页面映射来实现内存页的共享,从而减小内存的使用。虽然在代码执行过程中都会形成它自己的进程空间,有各自独立的内存类,但对于可执行文件、动态链接库等这些静态资源,则在进程之间会通过页面映射进行共享进行共享。于是,可以得到的解决思路,就是如何加强页面的共享。
加强共享的简单一点的思路,就是人为地将所有可能使用到的动态链接库.so文件,dalvik虚拟机的执行文件,都通过强制读一次,于是物理内存里便有了存放这些文件内容的内存页,其他部分则可以通过mmap()来借用这些被预加载过的内存页。于是,当我们的用户态进程被执行时,虽然还是同样的执行流程,但因为内存里面有了所需要的虚拟机环境的物理页,这时缺页中断则只是进行一次页面映射,不需要读文件,非常快就返回了,同时由于页面映射只是对内存页的引用,这种共享也减小实际物理页的使用。我们将上面的fork()处理人为地改进一下,就可以使用如下的模式:
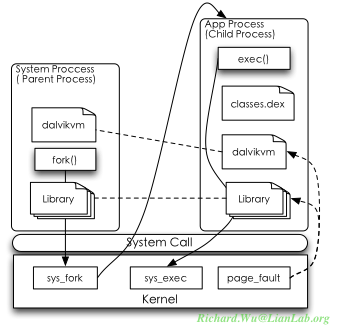
这时,对于任一应用程序,在dalvik开始执行前,它所需要的物理页就都已经存在了,对于非系统进程的应用程序而言,它所需要使用的Framework提供的功能、动态链接库,都不会从文件系统里再次读取,而只需要通过page_fault触发一次页面映射,这时就可以大大提供加载时的性能。然后便是开始执行dalvik虚拟,解析.dex文件来执行应用程序的独特实现,当然,每个classes.dex文件的内容则是需要各自独立地进行加载。我们可以从.dex文件的解析入手,进一步加强内存使用。
Android环境里,会使用dx工具,将.class文件翻译成.dex文件,.dex文件与.class文件,不光是伪指令不同,它们的文件格式也完全不同,从而达到加强共享的目的。标准的Java一般使用.jar文件来包装一个软件包,在这个软件里会是以目录结构组织的.class文件,比如org/lianlab/hello/Hello.class这样的形式。这种格式需要在运行时进行解压,需要进行目录结构的检索,还会因为.class文件里分散的定义,无法高效地加载。而在.dex文件里,所有.class文件里实现的内容,会合并到一个.dex文件里,然后把每个.class文件里的信息提取出来,放到同一个段位里,以便通过内存映射的方式加速文件的操作与加载。
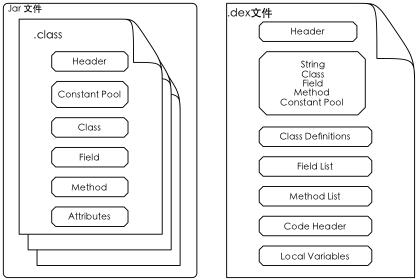
这时,我们的各个不同的.class文件里内容被检索并合并到同一个文件里,这里得到的.dex文件,有特定情况下会比压缩过的.jar文件还要小,因为此时可以合并不同.class文件里的重复定义。这样,在可以通过内存映射来加速的基础上,也从侧面降低了内存的使用,比如用于.class的文件系统开销得到减小,用于加载单个.class文件的开销也得以减小,于是得到了加速的目的。
这还不是全部,需要知道,我们的dalvik不光是一个可执行的ELF文件而已,还是Java语言的一个解析器,这时势必需要一些额外的.class文件(当然,在Android环境里,因为使用了与Java虚拟机不兼容的Dalvik虚拟机,这样的.class文件也会被翻译成.dex文件)里提供的内容,这些额外的文件主要就是Framework的实现部分,还有由Harmony提供的一些Java语言的基本类。还不止于此,作为一个系统环境,一些特定的图标,UI的一些控件资源文件,也都会在执行过程里不断被用到,最好我们也能实现这部分的预先加载。出于这样的目的,我们又会面临前面的两难选择,改内核的page_fault处理,还是自己设计。出于设计上的可移植性角度考虑,还是改设计吧。这时,就可以得到Android里的第一个系统进程设计,Zygote。
我们这时对于Zygote的需求是,能够实现动态链接库、Dalvik执行进程的共享,同时它最好能实现一些Java环境里的库文件的预加载,以及一些资源文件的加载。出于这样的目的,我们得到了Zygote实现的雏形:
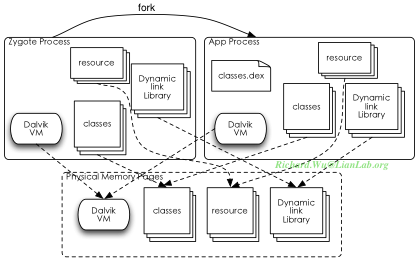
这时,Zygote基本上可以满足我们的需求,可以加载我们运行一个应用程序进程除了classes.dex之外的所有资源,而我们前面也看到.dex这种文件格式本身也被优化过,于是对于页面共享上的优化基本上得以完成了。我们之后的操作完全可以依赖于zygote进程,以后的设计里,我们就把所有的需要特权的服务都在zygote进程里实现就好了。
有了zygote进程则我们解决掉了共享的问题,但如果把所有的功能部分都放在Zygote进程里,则过犹不及,这样的做法反而更不合适。Zygote则创建应用程序进程并共享应用程序程序所需要的页,而并非所有的内存页,我们的系统进程执行的绝大部分内容是应用程序所不需要的,所以没必要共享。共享之后还会带来潜在问题,影响应用程序的可用进程空间,另外恶意应用程序则可以取得我们系统进程的实现细节,反而使我们的辛辛苦苦构建的“沙盒”失效了。
Zygote,英文愿意是“孵化器”的意思,既然是这种名字,我们就可以在设计上尽可能保持其简单性,只做孵化这么最简单的工作,更符合我们目前的需求。但是还有一个实现上的小细节,我们是不是期望zygote通过fork()创建进程之后,每个应用程序自己去调用exec()来加载dalvik虚拟机呢?这样实现也不合理,实现上很丑陋,还不安全,一旦恶意应用程序不停地调用到zygote创建进程,这时系统还是会由于创建进程造成的开销而耗尽内存,这时系统也还是很脆弱的。这些应该是由系统进程来完成的,这个系统进程应该也需要兼职负责Intent的分发。当有Intent发送到某个应用程序,而这个应用程序并没有被运行起来时,这时,这个系统进程应该发一个请求到Zygote创建虚拟机进程,然后再通过系统进程来驱动应用程序具体做怎么样的操作,这时,我们的Android的系统构架就基本上就绪了。在Android环境里,系统进程就是我们的System Server,它是我们系统里,通过init脚本创建的第一个Dalvik进程,也就是说Android系统,本就是构建在Dalvik虚拟机之上的。
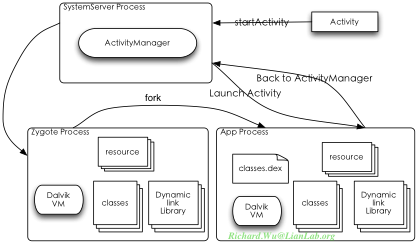
在SystemServer里,会实现ActivityManager,来实现对Activity、Service等应用程序执行实体的管理,分发Intent,并维护这些实体生命周期(比如Activity的栈式管理)。最终,在Android系统里,最终会有3个进程,一个只负责进程创建以提供页面共享,一个用户应用程序进程,和我们实现一些系统级权限才能完成的特殊功能的SystemServer进程。在这3种进程的交互之下,我们的系统会坚固,我们不会盲目地创建进程,因为应用程序完全不知道有进程这回事,它只会像调用函数那样,调用一个个实现具体功能的Activity,我们在完成内存页共享难题的同时,也完成Android系统设计的整体思路。
这时对于应用程序处理上,还剩下最后一个问题,如果加快应用程序的加载。
应用程序进程“永不退出”
虽然我们拥有了内存页的预加载实现,但这还是无法保证Android应用程序执行上的高效性的。根据到现在为此我们分析到的Android应用程序支持,我们在这方面必将面临挑战。像Activity之间进行跳转,我们如果处理跳转出的Activity所依附的那个进程呢?直接杀死掉,这时,当我们从被调用Activity返回时怎么办?
这也会是个比较复杂的问题。一是前一个进程的状态如何处理,二是我们又如何对待上一个已经暂时退出执行的进程。
我们老式的应用程序是不存在这样的问题的,因为它不具备跨进程交互的能力,唯一的有可能进行跨进程交互的方式是在应用程序之间进行复制/粘贴操作。而对于进程内部的界面之间的切换,实际上只会发生在同一个While循环里面,一旦退出某一个界面,则相应的代码都不会被执行到,直到处理完成再返回原始界面:
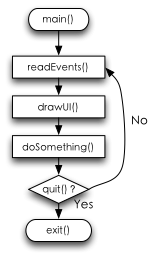
而这种界面模型,在Android世界里,只是一个UI线程所需要完成的工作,跟界面交互倒并不相关。我们的Android 在界面上进行交互,实际上是在Activity之间进行切换,而每个进程内部再维护一套上述的UI循环体:

在这样的运行模式下,如果我们退出了某一个界面的执行,则没有必要再维持其运行,我们可以通过特殊的设计使其退出执行。但这种调用是无论处理完,还是中途取消,我们还是会回到上一个界面,如果要达到一体化看上去像同一个应用程序的效果,这里我们需要恢复上一个界面的状态。比如我们例子里,我们打了联系列表选择了某个联系人,然后通过Gallery设置大头贴,再返回到联系人列表时,一定要回到我们正在编译联系人的界面里。如果这时承载联系人列表的进程已经退出了话,我们将要使整个操作重做一次,很低效。
所以综合考虑,最好的方式居然会是偷懒,对上个进程完全不处理,而需要提供一种暂停机制,可以让不处理活跃交互状态的进程进入暂停。当我们返回时则直接可以到上次调用前的那个界面,这时对用户来说很友好,在多个进程间协作在用户看来会是在同一个应用程序进行,这才是Android设计的初衷。
因为针对需要暂停的处理,所以我们的应用程序各个实体便有了生命周期,这种生命周期会随着Android系统变得复杂而加入更多的生命周期的回调点。但对于偷懒处理,则会有后遗症,如果应用程序一直不退出,则对系统会是一个灾难。系统会因为应用程序不断增加而耗尽资源,最后会崩溃掉。
不光Android会有这样的问题的,Linux也会有。我们一直都说Linux内核强劲安全,但这也是相对的,如果我们系统里有了一些流氓程序,也有可能通过耗尽资源的方式影响系统运行。大家可以写一些简单的例子做到这点,比如:
- while(1)
- {
- char * buf = malloc (30 * 1000);
- memset (buf, ‘a’, 30*1000);
- if (!fork() )
- fork();
- }
一旦发生OOM事件,这时系统会通过一定规则杀死掉某种类型的进程来回收内存,所谓枪打出头鸟,被杀的进程应该是能够提供更多内存回收机会的,比如进程空间很大、内存共享性很小的。这种机制并不完全满足Android需要,如果刚好这个“出头鸟”就是产生调用的进程,或是系统进程,这时反而会影响到Android系统的正常运行。
这时,Android修改了Linux内核里标准的OOM Killer,取而代之是一个叫LowMemKiller的驱动,触发Out Of Memory事件的不再是Linux内核里的Notifier,而由Android系统进程来驱动。像我们前面说明的,在Android里负责管理进程生成与Activity调用栈的会是这个系统进程,这样在遇到系统内存不够(可以直接通过查询空闲内存来得到)时,就触发Low Memory Killer驱动来杀死进程来释放内存。
这种设计,从我们感性认识里也可以看到,用adb shell free登录到设备上查看空闲内存,这时都会发现的内存的剩余量很低。因为在Android设备里,系统里空闲内存数量不低到一定的程度,是不会去回收内存的,Android在内存使用上,是“月光族”。Android通过这种方式,让尽可能多的应用程序驻留在内存里,从而达到一个加速执行的目的。在这种模型时,内存相当于一个我们TCP协议栈里的一个窗口,尽可能多地进行缓冲,而落到窗口之外的则会被舍弃。
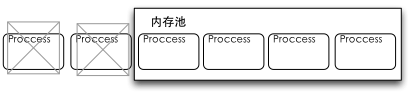
理论上来说,这是一种物尽其用,勤俭执家的做法,这样使Android系统保持运行流畅,而且从侧面也刺激了Android设备使用更大内存,因为内存越多则内存池越大,可同时运行的任务越多,越流畅。唯一不足之处,一些试图缩减Android内存的厂商就显得很无辜,精减内存则有可能影响Android的使用体验。
我们经常会见到系统间的对比,说Android是真实的多任务操作系统,而其他手机操作平台只是伪多任务的。这是实话,但这不是被Android作为优点来设计的,而只是整个系统设计迫使Android系统不得不使用这种设计,来维持系统的流畅度。至于多任务,这也是无心插柳柳成荫的运气吧。
Pre-runtime运算
在Android系统里,无论我们今天可以得到的硬件平台是多么强大,我们还是有降低系统里的运算量的需求。作为一个开源的手机解决方案,我们不能假设系统具备多么强劲的运算能力,出于成本的考虑,也会有产商生产一些更廉价的低端设备。而即便是在一些高端硬件平台之上,我们也不能浪费手机上的运算能力,因为我们受限于有限的电池供电能力。就算是将来这些限制都不存在,我们最好也还是减少不必要的损耗,将计算能力花到最需要使用它们的地方。于是,我们在前面谈到的各种设计技巧之外,又增加了降低运算量的需求。
这些技巧,貌似更高深,但实际上在Android之前的嵌入式Linux开发过程里,大家也被迫干过很多次了。主要的思路时,所有跟运行环境无关运算操作,我们都在编译时解决掉,与运行环境相关的部分,则尽可能使用固化设计,在安装时或是系统启动时做一次。
与运算环境无关的操作,在我们以前嵌入式开发里,Codec会用到,比如一些码表,实际上每次算出来都是同样或是类似的结构,于是我们可以直接在编译时就把这张表算出来,在运行时则直接使用。在Android里,因为大量使用了XML文件,而XML在运行时解析很消耗内存,也会占用大量内存空间,于是就把它在编译时解析出来,在应用程序可能使用的内存段位里找一个空闲位置放进去,然后再将这个内存偏移地址写到R.java文件里。在执行时,就是直接将二进制的解析好的xml树形结构映射到内存R.java所指向的位置,这时应用程序的代码在执行时就可以直接使用了。
在Android系统里使用的另一项编译态运算是prelink。我们Linux内核之睥系统环境,一般都会使用Gnu编译器的动态链接功能,从而可以让大量代码通过动态链接库的方式进行共享。在动态链接处理里,一般会先把代码编译成位置无关代码(Position Independent Code,PIC),然后在链接阶段将共用代码编译成.so动态链接库,而将可执行代码链接到这样的.so文件。而在动态链接处理里,无论是.so库文件还是可执行文件,在.text段位里会有PLT(Procedure Linkage Table),在.data段位里会有GOT(Global Offset Table)。这样,在代码执行时,这两个文件都会被映射到同一进程空间,可执行程序执行到动态链接库里的代码,会通过PLT,找到GOT里定位到的动态链接库里代码具体实现的位置,然后实现跳转。
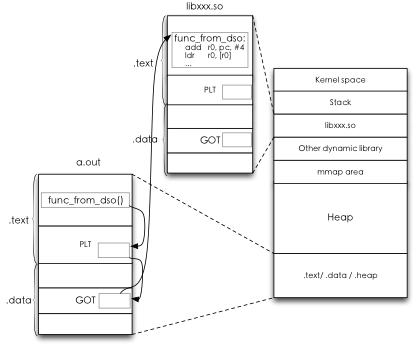
通过这样的方式,我们就可以实现代码的共享,如上图中,我们的可执行文件a.out,是可以与其他可执行程序共享libxxx.so里实现的func_from_dso()的。在动态链接的设计里,PLT与GOT分开是因为.text段位一般只会被映射到只读字段,避免代码被非法偷换,而.data段位映射后是可以被修改的,所以一般PLT表保持不动,而GOT会根据.so文件被映射到进程空间的偏移位置再进行转换,这样就实现了灵活的目的。同时,.so文件内部也是这样的设计,也就是动态链接库本身可以再次使用这样的代码共享技术链接到其他的动态链接库,在运行时这些库都必须被映射到同一进程空间里。所以,实际上,我们的进程空间可能使用到大量的动态链接库。
动态链接在运行时还进行一些运行态处理,像GOT表是需要根据进程上下文换算成正确的虚拟地址上的依稀,另外,还需要验证这些动态链接代码的合法性,并且可能需要处理链接时的一些符号冲突问题。出于加快动态连接库的调用过程,PLT本身也会通过Hash表来进行索引以加快执行效率。但是动态链接库文件有可能很大,里面实现的函数很多很复杂,还有可能可执行程序使用了大量的动态链接库,所有这些情况会导致使用了动态链接的应用程序,在启动时都会很慢。在一些大型应用程序里,这样的开销有可能需要花好几秒才能完全。于是有了prelink的需求。Prelink就是用一个交叉编译的完整环境,模拟一次完整地运行过程,把参与运行的可执行程序与动态链接所需要使用的地址空间都算出来一个合理的位置,然后再就这个值写入到ELF文件里的特殊段位里。在执行时,就可以不再需要(即便需要,也只是小范围的改正)进行动态链接处理,可以更快完成加载。这样的技术一直是Linux环境里一个热门研究方向,像firefox这样的大型应用程序经过prelink之后,可以减少几乎一半的启动时间,这样的加速对于嵌入式环境来说,也就更加重要了。
但这种技术有种致命缺陷,需要一台Linux机器,运行交叉编译环境,才能使用prelink。而Android源代码本就设计成至少在MacOS与Linux环境里执行的,它使用的交叉编译工具使用到Gnu编译的部分只完成编译,链接还是通过它自己实现的工具来完成的。有了需求,但受限于Linux环境,于是Android开发者又继续创新。在Android世界里使用的prelink,是固定段位的,在链接时会根据固定配置好地址信息来处理动态链接,比如libc.so,对于所有进程,libc.so都是固定的位置。在Android一直到2.3版本时,都会使用build/core/prelink-linux-arm.map这个文件来进行prelink操作,而这个文件也可以看到prelink处理是何其简单:
- # core system libraries
- libdl.so 0xAFF00000 # [<64K]
- libc.so 0xAFD00000 # [~2M]
- libstdc++.so 0xAFC00000 # [<64K]
- libm.so 0xAFB00000 # [~1M]
- liblog.so 0xAFA00000 # [<64K]
- libcutils.so 0xAF900000 # [~1M]
- libthread_db.so 0xAF800000 # [<64K]
- libz.so 0xAF700000 # [~1M]
- libevent.so 0xAF600000 # [???]
- libssl.so 0xAF400000 # [~2M]
- libcrypto.so 0xAF000000 # [~4M]
- libsysutils.so 0xAEF00000 # [~1M]
虽然作了这方面的努力,但当Android到4.0版时,为了加强系统的安全性,开始使用新的动态链接技术,地址空间分布随机化(Address Space Layout Randomization,ASLR),将地址空间上的固定分配变成伪随机分布,这时就也取消了prelink。
Android系统设计上,对于性能,在各方面都进行了相当成功的尝试,最后得到的效果也非常不错。大家经常批评Android整个生态环境很恶劣,高中低档的设备充斥市场,五花八门的分辨率,但抛开商业因素不谈,Android作为一套操作系统环境,可以兼容到这么多种应用情境,本就是一种设计上很成功的表现。如果说这种实现很复杂,倒还显得不那么神奇,问题是Android在解决一些很难的工程问题的时候,用的技巧还是很简单的,这就非常不容易了。我们写过代码的人都会知道,把代码写得极度让人看不懂,逻辑复杂,其实并不需要太高智商,反而是编程能力不行所致。逻辑清晰,简单明了,又能解决问题,才真正是大神级的代码,业界成功的项目,linux、git、apache,都是这方面的典范。
Android所有这些提升性能的设计,都会导致另一个间接收益,就是所需使用的电量也相应大大降低。同样的运算,如果节省了运算上的时间,变相地也减少了电量上的损失。但这不够,我们的手机使用的电池非常有限,如果不使用一些特殊的省电技术,也是不行的。于是,我们可以再来透过应用程序,看看Android的功耗管理。

