
- 1idea远程连接Docker调试 debug_idea docker 调试
- 2无人机集群作战仿真研究现状及在城市作战中的应用前景(附最新无人集群项目内容)_研究无人机作战的必要性和可行性
- 3【2023年电工杯数学建模竞赛B题人工智能对大学生学习影响的评价】完整思路分析+完整代码_人工智能对大学生学习影响的评价数学建模
- 4Idea之Java代码Remote JVM Debug_idea remote jvm debug
- 5【项目总结】基于SpringBoot+Ansj分词+正倒排索引的Java文档搜索引擎项目总结_springboot引入ansj统计词频
- 6【蓝桥杯计算思维题】少儿编程 蓝桥杯青少组计算思维真题及详细解析第5套_蓝桥杯小学组真题
- 7FPGA学习笔记_fpga16‘h什么意思
- 8计算机专业有哪些【含金量超高竞赛】?_计算机含金量高的比赛
- 9Devops系统化,从零开始学习容器技术(更新中)_系统学习容器化技术
- 10C++const成员函数/取地址运算符重载_const 版本的取地址运算符
一文总结图像生成必备经典模型(一)_图像生成模型
赞
踩
本文将分 2 期进行连载,共介绍 16 个在图像生成任务上曾取得 SOTA 的经典模型。
-
第 1 期:ProGAN、StyleGAN、StyleGAN2、StyleGAN3、VDVAE、NCP-VAE、StyleGAN-xl、Diffusion GAN
-
第 2 期:WGAN、SAGAN、BIG-GAN、CSGAN、LOGAN、UNet-GAN、IC-GAN、ADC-GAN
您正在阅读的是其中的第 1 期。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本期收录模型速览
| 模型 | SOTA!模型资源站收录情况 | 模型来源论文 |
|---|---|---|
| ProGAN | https://sota.jiqizhixin.com/project/0190e1fa-5643-4043-8b75-9b863a6d20db 收录实现数量:1 支持框架:TensorFlow | Progressive Growing of GANs for Improved Quality, Stability, and Variation |
| StyleGAN | https://sota.jiqizhixin.com/project/e072cfc0-26c3-40e7-a979-60df61170c7a 收录实现数量:75 支持框架:TensorFlow、PyTorch | A Style-Based Generator Architecture for Generative Adversarial Networks |
| StyleGAN2 | https://sota.jiqizhixin.com/project/a07f5a80-bf97-4a33-a2a8-4ff938b1b82f 收录实现数量:1 支持框架:TensorFlow | Analyzing and Improving the Image Quality of StyleGAN |
| StyleGAN3 | https://sota.jiqizhixin.com/project/6f7d3d51-762a-4d23-a572-3ea79ab49b4f 收录实现数量:2 支持框架:TensorFlow、PyTorch | Alias-Free Generative Adversarial Networks |
| VDVAE | https://sota.jiqizhixin.com/project/0ed2229c-722b-47fb-b6aa-d22dedf87f1b 收录实现数量:1 支持框架:PyTorch | Very Deep VAEs Generalize Autoregressive Models and Can Outperform Them on Images |
| NCP-VAE | https://sota.jiqizhixin.com/project/74d15cbe-7f75-434a-a1cf-a69ae303eec6 | A Contrastive Learning Approach for Training Variational Autoencoder Priors |
| StyleGAN-xl | https://sota.jiqizhixin.com/project/01d16b00-e79f-4527-a7e3-08354b5d9b47 收录实现数量:1 支持框架:PyTorch | StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets |
| Diffusion GAN | https://sota.jiqizhixin.com/project/9aa9b499-adec-46a3-aef9-4cd73e1c13ec 收录实现数量:1 支持框架:PyTorch | Diffusion-GAN: Training GANs with Diffusion |
生成模型是一种训练模型进行无监督学习的模型,即,给模型一组数据,希望从数据中学习到信息后的模型能够生成一组和训练集尽可能相近的数据。图像生成(Image generation,IG)则是指从现有数据集生成新的图像的任务。图像生成模型包括无条件生成和条件性生成两类,其中,无条件生成是指从数据集中无条件地生成样本,即p(y);条件性图像生成是指根据标签有条件地从数据集中生成样本,即p(y|x)。
图像生成也是深度学习模型应用比较广泛、研究程度比较深的一个主题,大量的图像库也为SOTA模型的训练和公布奠定了良好的基础。在几个著名的图像生成库中,例如CIFAR-10、ImageNet64、ImageNet32、STL-10、CelebA 256、CelebA64等等,目前公布出的最好的无条件生成模型有StyleGAN-XL、Diffusion ProjectedGAN;在ImageNet128、TinyImageNet、CIFAR10、CIFAR100等库中,效果最好的条件性生成模型则是LOGAN、ADC-GAN、StyleGAN2等。
我们在这篇文章中介绍图像生成必备的TOP模型,从无条件生成模型和条件性生成模型两个类别分别介绍。图像生成模型的发展非常快,所以与其它几个topic不同,图像生成中必备的TOP模型介绍主要以近两年的SOTA模型为主。
一、无条件生成模型
1.1 ProGAN
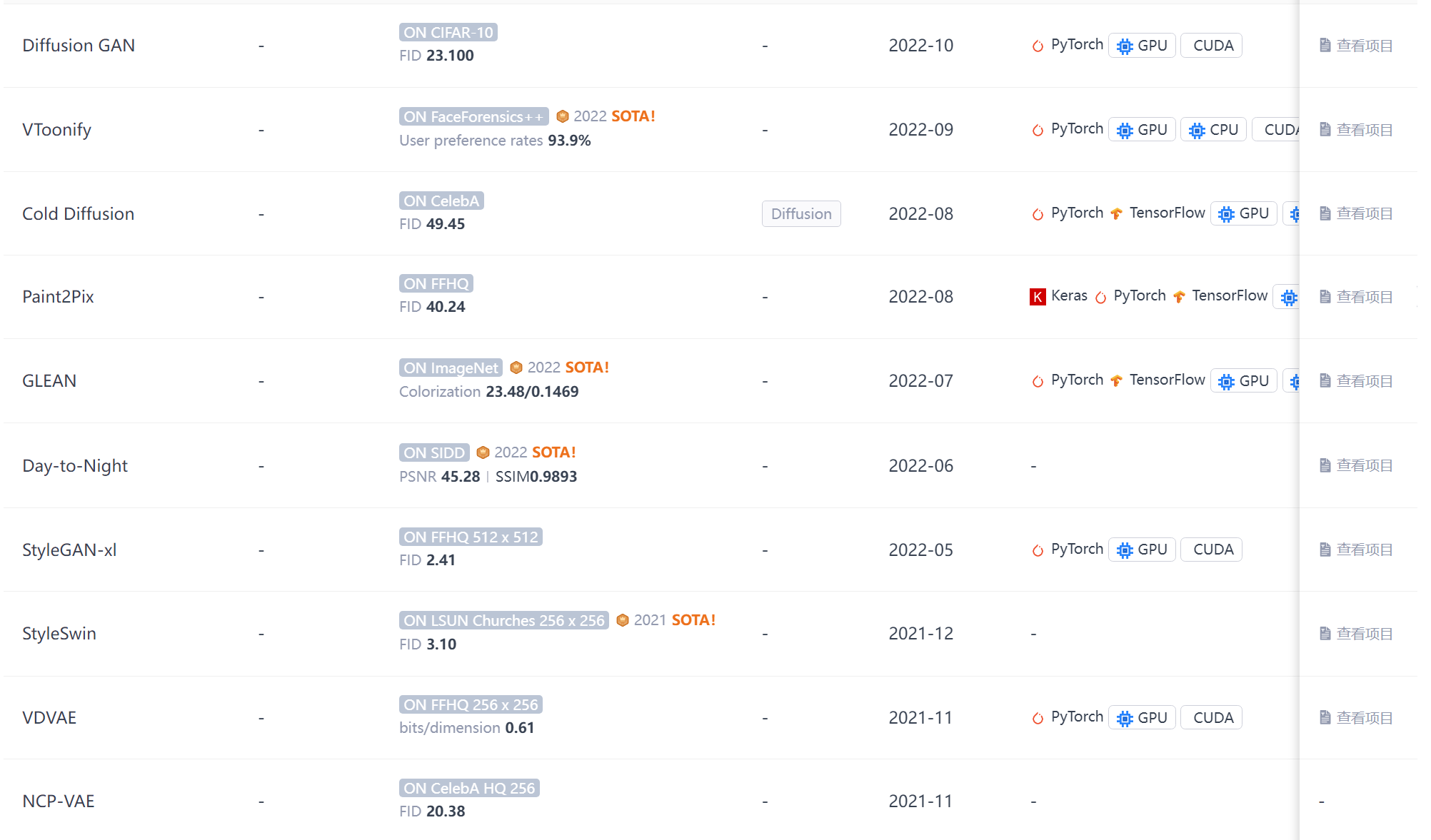
生成性对抗网络(GAN)是机器学习中一个相对较新的概念,于2014年首次引入。GAN的目标是合成与真实图像无法区分的人工样本,如图像。GAN的基本组成部分是两个神经网络:一个新样本的生成器(G),一个从训练数据和生成器输出中提取样本并预测它们是“真”还是“假”的鉴别器(D)。生成器的输入是一个随机向量(噪声),因此其初始输出也是噪声。随着训练的进行,当它收到鉴别器的反馈时,会学习合成更“真实”的图像。鉴别器还通过将生成的样本与真实样本进行比较,随着训练的进行不断改进,使得生成器更难欺骗它。
ProGAN是NVIDIA投稿ICLR 2018的一篇文章,ProGAN关键创新在于渐进式训练,它在经典GAN的基础上首先通过学习在低分辨率图像中也可以显示的基本特征,来创建图像的基本部分,并且随着分辨率的提高和时间的推移,学习越来越多的细节。低分辨率图像的训练不仅简单、快速,而且有助于更高级别的训练,因此,整体的训练也就更快。ProGAN被认为是后来大热的StyleGAN的前身。
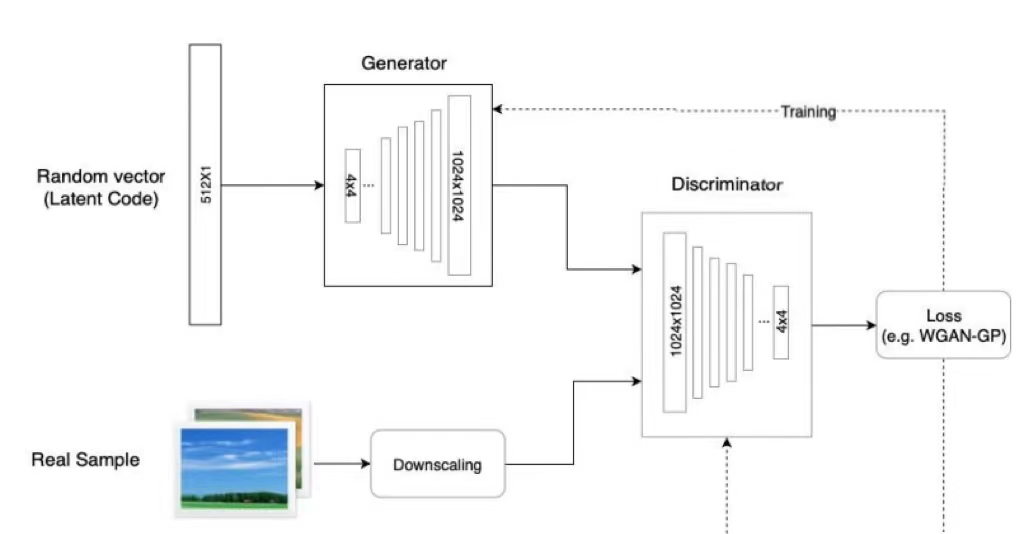
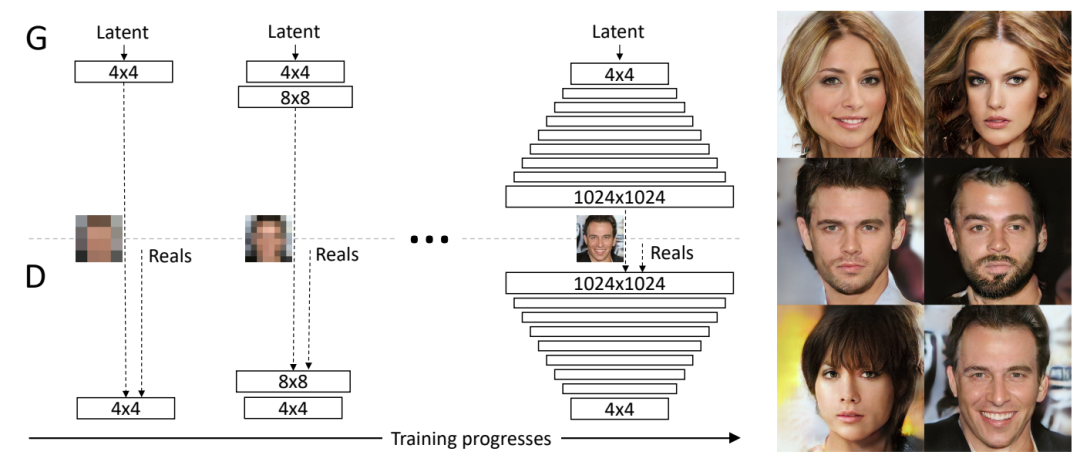
ProGAN的训练部分,从低分辨率的图像开始,通过向网络添加层来逐步提高分辨率,如图2所示。这种递增的性质允许训练首先发现图像分布的大规模结构,然后将注意力转移到越来越精细的细节上,而不是同时学习所有的尺度。使用生成器和鉴别器网络,它们是彼此的镜像,并且总是同步增长。在整个训练过程中,两个网络中的所有现有层都是可训练的。当新的层被添加到网络中时,平稳地将它们淡化,如图3所示。这就避免了对已经训练好的小分辨率层的突然冲击。
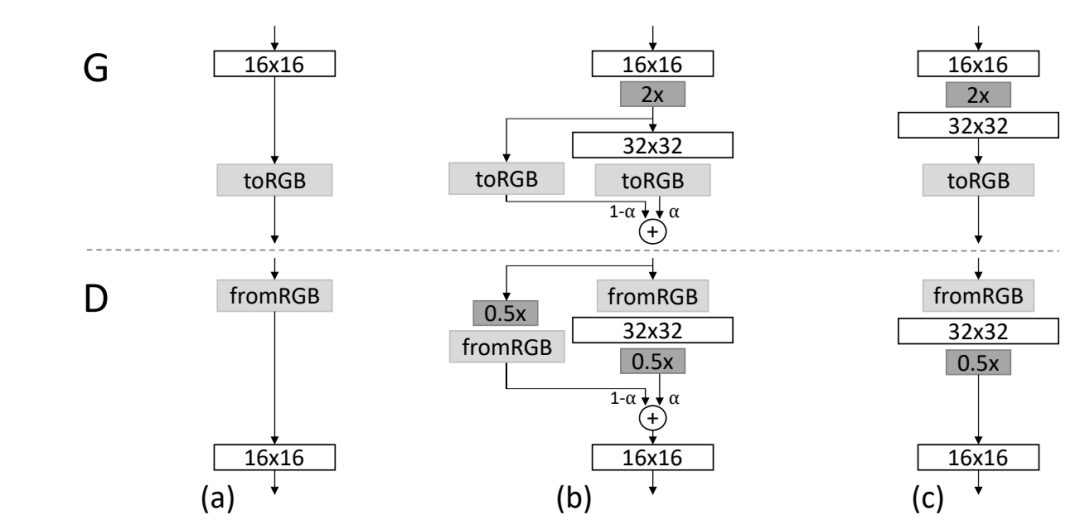
GAN还有一个问题是只捕捉训练数据中发现的变化的一个子集,mini-batch就是为了解决这个问题提出的,它是通过在鉴别器的末尾添加一个minibatch层来实现的,该层学习一个大的张量,将输入激活投射到一个统计数组。mini-batch中的每个样本都会产生一组单独的统计数据,并将其串联到该层的输出中,这样鉴别器就可以在内部使用这些统计数据。
ProGAN的简化方案既没有可学习的参数,也没有新的超参数,而是引入了特征的标准差作为衡量标准。首先计算每个特征在每个空间位置上的标准偏差。然后,在所有特征和空间位置上平均这些估计值,得到一个单一的值。复制这个值并将其连接到所有的空间位置和minibatch上,产生一个额外的(恒定)特征图。这一层可以插入鉴别器的任何地方,将其在最后插入效果最好。这个特征图中包含了不同样本之间的差异性信息,送入鉴别器后,经过训练,生成样本的差异性也会与训练样本的相似。
此外,ProGAN还对生成器和鉴别器进行了归一化处理,归一化主要是用来控制信号幅度,从而减少G与D之间的不正常竞争,沿channel维度对每个像素的特征长度归一化。minibatch statistic layer沿着batch维度求标准差,而它沿着channel维度求norm。
1.2 StyleGAN
转载于机器之心:ProGAN、StyleGAN、Diffusion GAN…你都掌握了吗?一文总结图像生成必备经典模型(一)

