
- 1企企云ERP OpenAPI接口--.Net Core Aws Sigv4 快速编码_aws signature version 4
- 2Git之深入解析如何在应用中嵌入Git
- 3mysql 对象权限设置_怎么设置SQL数据库用户权限
- 4分布式文件系统(HDFS)与linux系统文件系统关系_linux文件系统和hdfs之间有何关系?
- 5python 中collections.deque类及 collections.defaultdict类的理解_collections.defaultqueue
- 6python plt画图_python 使用plt画图,去除图片四周的白边方法
- 7每天3分钟操作系统修炼秘籍(13):两个缓冲空间Kernel Buffer和IO Buffer_如何使用一个文件描述符将两个不同内容放到两个缓存器
- 8USB协议_usb协议文档
- 9基于BERT的中文情感分析实战
- 10Linux·工作队列_linux 工作队列
【Java】IO流:字节流 字符流 缓冲流_java字符流字节流
赞
踩

接续上文,在这篇文章将继续介绍在Java中关于文件操作的一些内容
- 1
一、“流”的概念
“流”是一个抽象的概念,是对输入输出设备的一种抽象理解,在Java中,对数据的输入输出都是以“流”的的方式进行的。“流”具有方向性,输入流、输出流是相对的。当程序需要从数据源中读入数据的时候就会开启一个输入流,相反,写出数据到某个数据源目的地的时候也会开启一个输出流。数据源可以是文件、内存或者网络等
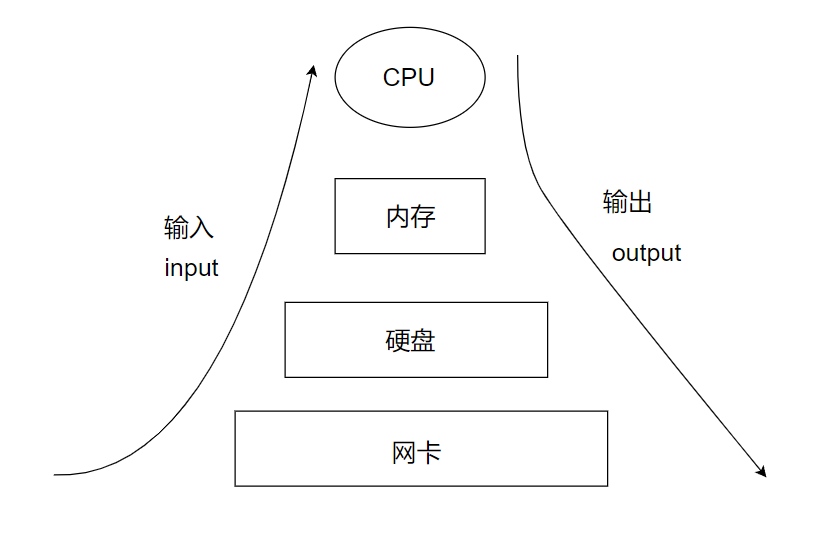
1.“流”的分类
“流”序列中的数据可以是未经加工的原始二进制数据,也可以是经过一定编码处理后符合某种格式的特定数据,因此java中的“流”分为以下三种流:
- 按数据流的方向:输入流、输出流
- 按处理数据单位:字节流、字符流
- 按功能:节点流,处理流
1.1输入流和输出流
“流”具有方向性,输入流、输出流是相对的
输入与输出是相对于应用程序而言的,比如文件读写,读取文件是输入流,写文件是输出流,这点很容易搞反。

1.2字节流和字符流
字节流:数据流中的最小的数据单元是字节,一次读入读出8位二进制;
字符流:数据流中的最小的数据单元是字符,一次读入读出16位二进制,java中的字符是Unicode编码,一个字符占用两个字节。
字节和字符的区别?
- 存储方式:
字节(byte):字节是计算机存储和通信的基本单位。在Java中,一个字节由8位(bit)组成,可以表示256种不同的状态,其取值范围是-128到127(对于byte类型)。
字符(char):字符用于表示文本信息。在Java中,一个字符使用Unicode编码,占用2个字节(16位)的空间。因此,Java中的char类型可以表示65536种不同的字符。
- 表示范围:
由于字节只有8位,其表示范围相对较小,只能表示-128到127之间的整数,或者0到255之间的无符号整数。
字符类型则能表示更多的字符,包括各种文字、符号等。由于使用了Unicode编码,Java中的char类型可以表示世界上几乎所有的字符。
为什么要有字符流?
在UTF8 编码中,“爱吃南瓜的北瓜”对应的字节如下
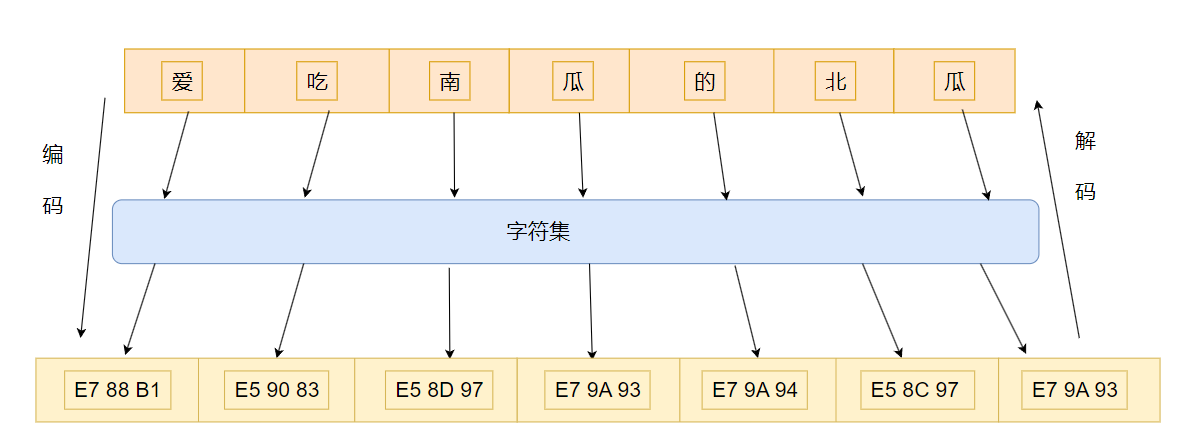
如果使用字节流处理中文,如果一次读写一个字符对应的字节数就不会有问题,一旦将一个字符对应的字节分裂开来,就会出现乱码了。为了更方便地处理中文这些字符,Java就推出了字符流。
- 用途:
字节主要用于处理二进制数据、图像、音频、视频等非文本信息,或者在网络通信中传输数据。
字符则主要用于处理文本信息,如字符串、文件名、用户输入等。
在Java中,经常需要将字节和字符进行转换。例如,当我们从文件或网络读取数据时,通常得到的是字节流,而我们需要将其转换为字符流以便进行文本处理。这时,可以使用Java提供的解码器(Decoder)将字节转换为字符。反之,当需要将文本信息写入文件或发送到网络时,需要将字符转换为字节,这时可以使用编码器(Encoder)。
- 区别
- 字节流一般用来处理图像、视频、音频、PPT、Word等类型的文件。字符流一般用于处理纯文本类型的文件,如TXT文件等,但不能处理图像视频等非文本文件。用一句话说就是:字节流可以处理一切文件,而字符流只能处理纯文本文件。
- 字节流本身没有缓冲区,缓冲字节流相对于字节流,效率提升非常高。而字符流本身就带有缓冲区,缓冲字符流相对于字符流效率提升就不是那么大了。
1.3节点流和处理流
- 节点流:节点流可以从一个特定的数据源读写数据,如FileInputStream ,FileOutputStream ,FileReader ,FileWrite

- 处理流:对一个已存在的流的链接和封装,通过对数据进行处理为程序提供功能强大、灵活的读写功能,例如BufferedInputStream(缓冲字节流)
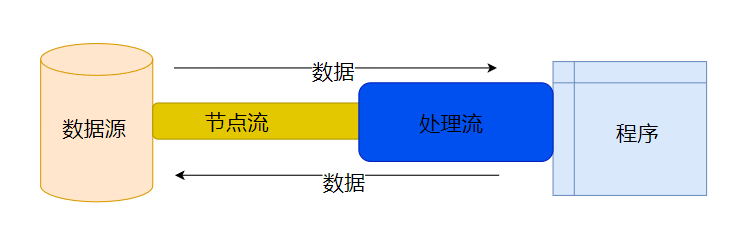
在诸多处理流中,有一个非常重要,那就是缓冲流。
我们知道,程序与磁盘的交互相对于内存运算是很慢的,容易成为程序的性能瓶颈。减少程序与磁盘的交互,是提升程序效率一种有效手段。缓冲流,就应用这种思路:普通流每次读写一个字节,而缓冲流在内存中设置一个缓存区,缓冲区先存储足够的待操作数据后,再与内存或磁盘进行交互。这样,在总数据量不变的情况下,通过提高每次交互的数据量,减少了交互次数。


联想一下生活中的例子,我们搬砖的时候,一块一块地往车上装肯定是很低效的。我们可以使用一个小推车,先把砖装到小推车上,再把这小推车推到车前,把砖装到车上。这个例子中,小推车可以视为缓冲区,小推车的存在,减少了我们装车次数,从而提高了效率。、

需要注意的是,缓冲流效率一定高吗?不一定,某些情形下,缓冲流效率反而更低
字符流自带缓冲区,为什么还要用字符缓冲流?
尽管字符流已经具备了缓冲的功能,但字符缓冲流(BufferedReader 和 BufferedWriter)仍然有其自身的优势和用途:
缓冲区大小可控:字符缓冲流提供了更大的缓冲区,可以指定缓冲区的大小。较大的缓冲区可以一次性读取或写入更多的字符数据,减少对底层I/O的频繁访问,提高读写效率。
提供了更方便的读写方法:字符缓冲流提供了一些便捷的方法,如 readLine() 方法可以一次读取一行数据,而不需要一个字符一个字符地读取。newLine() 方法可以写入一个平台特定的换行符,而不需要手动处理不同操作系统的换行符。
支持预读取和回滚:字符缓冲流具有 mark() 和 reset() 方法,可以在读取过程中进行标记(mark)并在需要时回滚(reset),方便进行预读取和回溯操作。
支持写入自动刷新:字符缓冲流提供了 flush() 方法,用于手动刷新缓冲区,并将缓冲区中的数据强制写入底层的输出流。此外,可以通过设置缓冲区的大小和自动刷新策略(如自动换行符)来控制写入时的刷新。
2.“流”的特性
一般来说关于流的特性有下面几点:
- 先进先出:最先写入输出流的数据最先被输入流读取到。
- 顺序存取:可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(RandomAccessFile除外)
- 只读或只写:每个流只能是输入流或输出流的一种,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
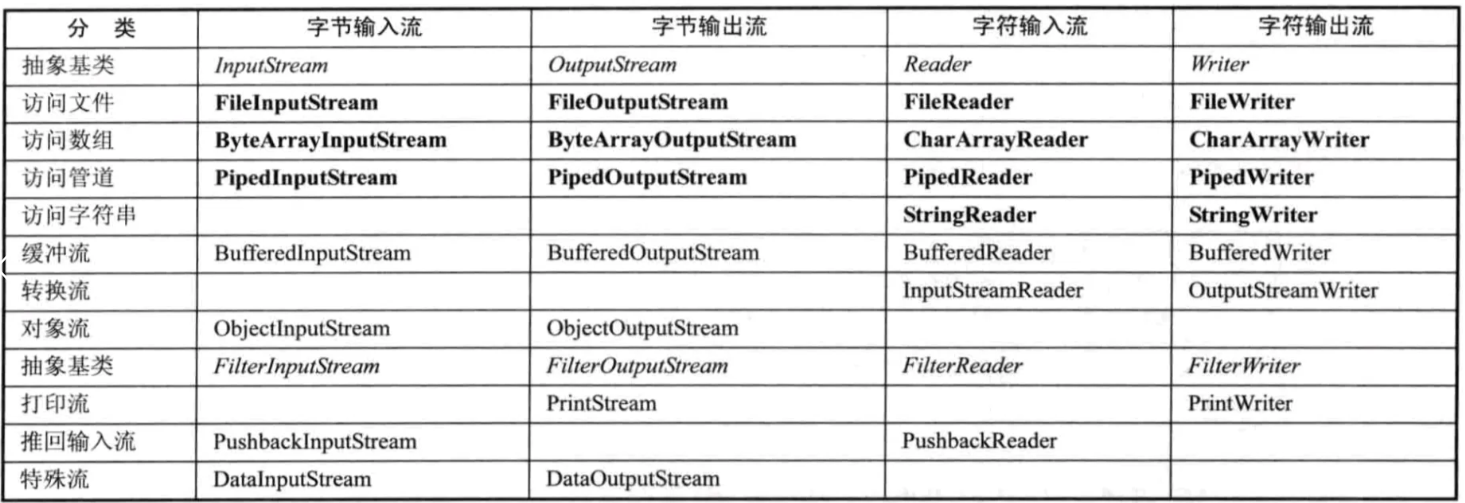
3.“流”的分类
“流”存在于Java.io包中,主要包含四种基本的类,InputStream、OutputStream、Reader及Writer类,它们分别处理字节流和字符流:
| 输入\输出 | 字节流 | 字符流 |
|---|---|---|
| 输入 | InputStream | Reader |
| 输出 | OutputStream | Writer |
二、Stream流(字节流)
1.InputStream流
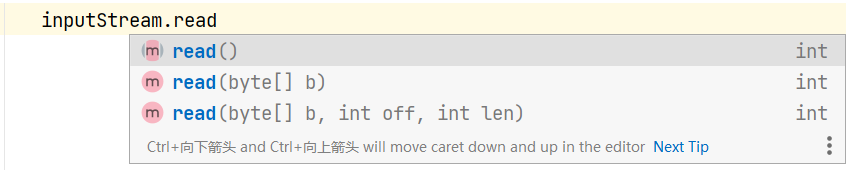
| 修饰符及返回值类型 | ⽅法签名 | 说明 |
|---|---|---|
| int | read() | 读取⼀个字节的数据,返回 -1 代表已经完全读完了 |
| int | read(byte[] b) | 最多读取 b.length 字节的数据到 b中,返回实际读到的数量;-1 代表以及读完了 |
| int | read(byte[] b, int off, int len) | 最多读取 len - off 字节的数据到 b中,放在从 off 开始,返回实际读到的数量;-1 代表以及读完了 |
| void | close() | 关闭字节流 |

这里InputStream是一个抽象类,不能实例化
因为它不仅仅对应的是硬盘的文件,也可以对应网卡,也可以对应控制台,也可以对应蓝牙设备
这里我们是对文件进行操作,所以我们使用系统提供对应的api来进行实例
这里使用FileInputStream
| 签名 | 说明 |
|---|---|
| FileInputStream(File file) | 利⽤ File 构造⽂件输⼊流 |
| FileInputStream(String name) | 利⽤⽂件路径构造⽂件输⼊流 |
版本一(无参)read()
版本一(无参类型)读取的是字节类型,那么为什么返回值的类型却是int呢???
我们点开read()的源码

手动翻译一下
从输入流中读取下一个字节的数据。返回值byte为int型,取值范围为0到255。如果由于到达流的末尾而没有可用的字节,则返回值-1。此方法将一直阻塞,直到输入数据可用、检测到流的结尾或抛出异常。子类必须提供此方法的实现。返回:数据的下一个字节,如果到达流的结尾则返回-1。抛出:IOException -如果I/O错误发生。
此处返回int
1)为了有额外的余地来表示“到达末尾”-1这样的情况
2)确保读到的数据都是正数
原则上来说,字节这样的概念,本应该是无符号的
但是byte类型,本身是有符号的。
此处使用int就可以确保读出来的字节都是正数,按照“无符号”来处理了.
3)为什么不用short?
因为short是两个字节,int是四个字节
随着计算机技术的发展,空间的存储成本会越来越低的,
CPU的不断发展,每次读取的数据也会越来越长
对于32位的CPU来说,一次读取四个字节的数据
也就是说在计算机内部,如果是short也会转换成int来处理
对于64位的CPU来说,一次就会读取八个字节的数据
所以short的使用会逐步的减少,由int来代替,
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
public static void main(String[] args) {
try (InputStream inputStream = new FileInputStream("D:/hello.txt")){
while (true){
int b = inputStream.read();
if (b == -1){
break;
}
System.out.printf("0x%x ",b);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
版本二 read(byte[] b)
public static void main(String[] args) { try (InputStream inputStream = new FileInputStream("D:/hello.txt")){ byte[] bytes = new byte[1024]; int len; while (true){ len = inputStream.read(bytes); if (len == -1){ break; } for (int i = 0; i < len; i++) { System.out.printf("0x%x ", bytes[i]); } } } catch (IOException e) { throw new RuntimeException(e); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这两种版本的访问速度谁更快呢?
版本二速度快,
访问硬盘是低效操作,IO次数越多,整体速度就越慢.
版本三 read(byte[] b,int offset,int len)
一次读取一部分,放置到指定位置
在网络协议中,一个报文就是由 报头 和 载荷 组成的
我们就可以用版本三来读取
2.OutPutStream流
| 修饰符及返回值类型 | ⽅法签名 | 说明 |
|---|---|---|
| void | write(int b) | 写⼊要给字节的数据 |
| void | write(byte[] b) | 将 b 这个字符数组中的数据全部写⼊ os 中 |
| int | write(byte[] b, int off, int len) | 将 b 这个字符数组中从 off 开始的数据写⼊ os 中,⼀共写 len 个 |
| void | close() | 关闭字节流 |
| void | flush() | 重要:我们知道 I/O 的速度是很慢的,所以,⼤多的 OutputStream为了减少设备操作的次数,在写数据的时候都会将数据先暂时写⼊内存的⼀个指定区域⾥,直到该区域满了或者其他指定条件时才真正将数据写⼊设备中,这个区域⼀般称为缓冲区。但造成⼀个结果,就是我们写的数据,很可能会遗留⼀部分在缓冲区中。需要在最后或者合适的位置,调⽤ flush(刷新)操作,将数据刷到设备中。 |
OutputStream 同样只是⼀个抽象类,要使⽤还需要具体的实现类。我们现在还是只关⼼写⼊⽂件中,所以使⽤ FileOutputStream
同read一样,也是三个版本

public static void main(String[] args) {
try (OutputStream outputStream = new FileOutputStream("D:/hello.txt",true)) {
outputStream.write(97);
outputStream.write(98);
outputStream.write(99);
outputStream.write(100);
outputStream.write(101);
outputStream.write(102);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这里的参数中多了一个Boolean类型
这个是打开了"追加写"的意思
这个功能是在对文件内容进行写入时,不会清空上次文件中的内存
会在文件的原有内容中继续写入,

为什么要将InputStream OutputStream流的创建写入到try() {} catch 里的小括号内呢?
这是因为我们在创建流后,在流使用后,需要对流进行关闭,在写入到try后面的小括号内时,我们就可以不必手动的来进行流的关闭,减少一些情况下我们忘记关闭流这一操作带来的风险,
这一语法被称作 try–with–resources。
但并非所有的类都可以放到try()的括号里,这个类必须实现Closeable接口
我们点开InputStream的源码

可以看到,InputStream流实现了closeable接口。
三、Stream流(字符流)
reader
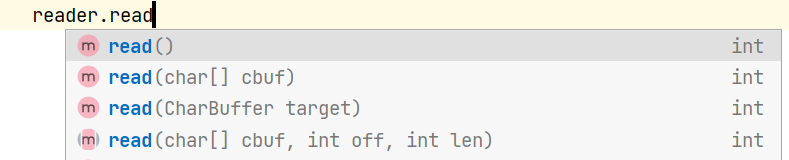
点开read()的源码

手动翻译一下
读取单个字符。此方法将阻塞,直到字符可用、发生I/O错误或到达流的末尾。想要支持有效的单字符输入的子类应该覆盖这个方法。返回:读取的字符,取值范围为0到65535 (0x00-0xffff)的整数,如果到达流的末尾则为-1。抛出:IOException -如果发生I/O错误
取值范围为0到65535 (0x00-0xffff)也就是读取两个字节
public static void main(String[] args) {
try(Reader reader = new FileReader("D:/hello.txt")){
while (true){
int c = reader.read();
if (c == -1){
break;
}
char ch = (char)c;
System.out.printf("%c",ch);
}
}catch (IOException e){
e.printStackTrace();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
那么不出意外的话,意外就要来了
Java中的char是两个字节,而汉字确实三个字节
但是read()确可以正常读取,这是为什么呢?
在文件中的原始数据,是三个字节一个字符
read在读取操作时,能够识别文件时UTF8编码方式
读的是三个字节,返回成一个char的时候,把UTF8编码方式,转换成了Unicode,在Unicode中一个汉字是两个字节的
链接: Java中一个汉字究竟占几个字节?
在Java内部,
char用的是Unicode
String里面默认是UTF8
那么有小可爱就可能会提出疑问了
那直接用char来接收read的返回值不就可以了,还可以省去转换这一步
这样做肯定有这样做的道理
char只能表示两个字节
文件末尾的-1怎么表示呢?
writer
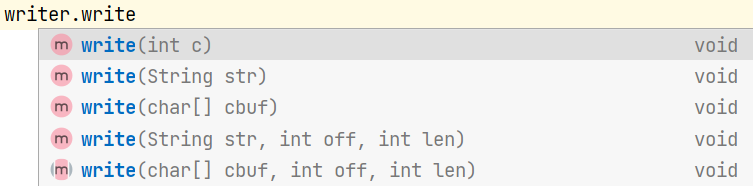
writer也存在“追加写”

四、 scanner
Scanner scanner = new Scanner(System.in);
- 1
你是否好奇Sacnner里的System.in到底是什么
我们点开in的源码

以上就是本文所有内容,如果对你有帮助的话,点赞收藏支持一下吧!
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

