
- 1微信小程序开发 | 音乐小程序项目_微信小程序音乐小程序项目
- 2Python-OpenCV车牌识别系统_基于opencv的python车牌识别系统
- 3将SQL中几张表设为只读,这是什么奇怪需求?
- 4不安全的HTTP方法_不安全的http请求方法
- 5flask部署到阿里云ECS主机端口冲突问题解决办法_部署两个flask 服务冲突
- 6伪造高清人像——PGGAN原理解析_proggan模型讲解
- 7OpenAI官方的Prompt工程指南:可以这么玩转ChatGPT_openai prompt engineering中文翻译
- 8C++:string类(第一章)
- 9【Python单点知识】类成员汇总讲解——包含类方法、静态方法、私有成员说明_python类中的成员
- 10【计算思维题】少儿编程 蓝桥杯青少组计算思维 数学逻辑思维真题详细解析第7套_.下图中,乐乐家的位置 数对(4,3)表示,学校在乐乐家 南 向。下列选项中,
一天掌握数据结构与算法,建议收藏_一天学完算法
赞
踩
最近老是听到刚毕业的朋友说,面试的时候对算法和数据结构很头疼,于是我整理了一波资料,感觉有用的朋友,可以点个赞支持哦。
不多说,直接上内容
1、数据结构与算法知识点整理;
数据结构与算法的知识点这里直接用启航大佬整理的:
2、链表、队列和栈的区别;

链表是一种物理存储单元上非连续的一种数据结构,看名字我们就知道他是一种链式的结构,就像一群人牵着手一样。链表有单向的,双向的,还有环形的。
队列是一种特殊的线性表,他的特殊性在于我们只能操作他头部和尾部的元素,中间的元素我们操作不了,我们只能在他的头部进行删除,尾部进行添加。就像大家排队到银行取钱一样,先来的排到前面,后来的只能排到队尾,所有元素都要遵守这个操作,没有VIP会员,所以走后门插队的现象是不可能存在的,他是一种先进先出的数据结构。接下来我们再看一下栈的数据结构是什么样的。
栈也是一种特殊的线性表,他只能对栈顶进行添加和删除元素。栈有入栈和出栈两种操作,他就好像我们把书一本本的叠起来,最先放的书肯定是放在最下边,最后放的书肯定是放在最上面,叠书的时候肯定不允许从中间放进去,拿书的时候也是先从最上面开始拿,不允许从下边或者中间抽出来、
3、简述快速排序的过程;
1)选择一个基准元素,通常选择第一个元素或者最后一个元素。
2)通过一趟排序将待排序记录分割为独立的两个部分,其中一部分记录的元素值均比基准元素小,另一部分记录的元素值均比基准元素大、
3)此时基准元素在其排序后的正确位置。
4)依此法对其他元素进行同样操作,直至整个序列有序。
4、快速排序算法的原理;
是对冒泡排序的⼀种改进,不稳定,平均/最好时间复杂度 O(nlogn),元素基本有序时最坏时间复杂度O(n²),空间复杂度 O(logn)。
⾸先选择⼀个基准元素,通过⼀趟排序将要排序的数据分割成独⽴的两部分,⼀部分全部⼩于等于基准 元素,⼀部分全部⼤于等于基准元素,再按此⽅法递归对这两部分数据进⾏快速排序。
快速排序的⼀次划分从两头交替搜索,直到 low 和 high 指针重合,⼀趟时间复杂度 O(n),整个算法的时间复杂度与划分趟数有关。
最好情况是每次划分选择的中间数恰好将当前序列等分,经过 log(n) 趟划分便可得到⻓度为 1 的⼦表, 这样时间复杂度 O(nlogn)。
最坏情况是每次所选中间数是当前序列中的最⼤或最⼩元素,这使每次划分所得⼦表其中⼀个为空表 , 这样⻓度为 n 的数据表需要 n 趟划分,整个排序时间复杂度 O(n²)。
5、简述各类算法时间复杂度、空间复杂度和稳定性对比;
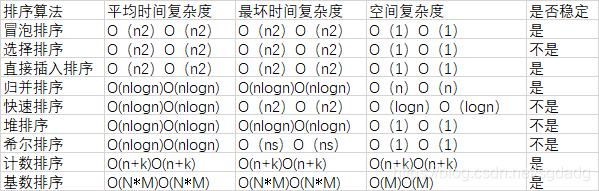
6、什么是AVL树;

AVL 树是平衡⼆叉查找树,增加和删除节点后通过树形旋转重新达到平衡。右旋是以某个节点为中⼼,将它沉⼊当前右⼦节点的位置,⽽让当前的左⼦节点作为新树的根节点,也称为顺时针旋转。同理左旋是以某个节点为中⼼,将它沉⼊当前左⼦节点的位置,⽽让当前的右⼦节点作为新树的根节点,也称为逆时针旋转。
7、什么是红黑树;
红⿊树 是 1972 年发明的,称为对称⼆叉 B 树,1978 年正式命名红⿊树。主要特征是在每个节点上增加⼀个属性表示节点颜⾊,可以红⾊或⿊⾊。

红⿊树和 AVL 树 类似,都是在进⾏插⼊和删除时通过旋转保持⾃身平衡,从⽽获得较⾼的查找性能。与 AVL 树 相⽐,红⿊树不追求所有递归⼦树的⾼度差不超过 1,保证从根节点到叶尾的最⻓路径不超过最短路径的 2 倍,所以最差时间复杂度是 O(logn)。
红⿊树通过重新着⾊和左右旋转,更加⾼效地完成了插⼊和删除之后的⾃平衡调整。红⿊树在本质上还是⼆叉查找树,它额外引⼊了 5 个约束条件: ① 节点只能是红⾊或⿊⾊。 ② 根节点必须是⿊⾊。 ③ 所有 NIL 节点都是⿊⾊的。 ④ ⼀条路径上不能出现相邻的两个红⾊节点。 ⑤ 在任何递归⼦树中,根节点到叶⼦节点的所有路径上包含相同数⽬的⿊⾊节点。
这五个约束条件保证了红⿊树的新增、删除、查找的最坏时间复杂度均为 O(logn)。如果⼀个树的左⼦节点或右⼦节点不存在,则均认定为⿊⾊。红⿊树的任何旋转在 3 次之内均可完成。
8、AVL树和红黑树的区别;
红⿊树的平衡性不如 AVL 树,它维持的只是⼀种⼤致的平衡,不严格保证左右⼦树的⾼度差不超过 1。这导致节点数相同的情况下,红⿊树的⾼度可能更⾼,也就是说平均查找次数会⾼于相同情况的 AVL 树。
在插⼊时,红⿊树和 AVL 树都能在⾄多两次旋转内恢复平衡,在删除时由于红⿊树只追求⼤致平衡,因此红⿊树⾄多三次旋转可以恢复平衡,⽽ AVL 树最多需要 O(logn) 次。AVL 树在插⼊和删除时,将向上回溯确定是否需要旋转,这个回溯的时间成本最差为 O(logn),⽽红⿊树每次向上回溯的步⻓为 2,回溯成本低。因此⾯对频繁地插⼊与删除红⿊树更加合适。
9、B树和B+树的区别;

B 树中每个节点同时存储 key 和 data,⽽ B+ 树中只有叶⼦节点才存储 data,⾮叶⼦节点只存储 key。InnoDB 对 B+ 树进⾏了优化,在每个叶⼦节点上增加了⼀个指向相邻叶⼦节点的链表指针,形成了带有顺序指针的 B+ 树,提⾼区间访问的性能。
B+ 树的优点在于: ① 由于 B+ 树在⾮叶⼦节点上不含数据信息,因此在内存⻚中能够存放更多的key,数据存放得更加紧密,具有更好的空间利⽤率,访问叶⼦节点上关联的数据也具有更好的缓存命 中率。 ② B+树的叶⼦结点都是相连的,因此对整棵树的遍历只需要⼀次线性遍历叶⼦节点即可。⽽ B 树则需要进⾏每⼀层的递归遍历,相邻的元素可能在内存中不相邻,所以缓存命中性没有 B+树好。但是 B 树也有优点,由于每个节点都包含 key 和 value,因此经常访问的元素可能离根节点更近,访问也更迅速。
10、排序有哪些分类;

排序可以分为内部排序和外部排序,在内存中进⾏的称为内部排序,当数据量很⼤时⽆法全部拷⻉到内存需要使⽤外存,称为外部排序。
内部排序包括⽐较排序和⾮⽐较排序,⽐较排序包括插⼊/选择/交换/归并排序,⾮⽐较排序包括计数/ 基数/桶排序。
插⼊排序包括直接插⼊/希尔排序,选择排序包括直接选择/堆排序,交换排序包括冒泡/快速排序。
11、直接插入排序的原理;
稳定,平均/最差时间复杂度 O(n²),元素基本有序时最好时间复杂度 O(n),空间复杂度 O(1)。
每⼀趟将⼀个待排序记录按其关键字的⼤⼩插⼊到已排好序的⼀组记录的适当位置上,直到所有待排序 记录全部插⼊为⽌。
直接插⼊没有利⽤到要插⼊的序列已有序的特点,插⼊第 i 个元素时可以通过⼆分查找找到插⼊位置insertIndex,再把 i~insertIndex 之间的所有元素后移⼀位,把第 i 个元素放在插⼊位置上。
12、希尔排序原理;
⼜称缩⼩增量排序,是对直接插⼊排序的改进,不稳定,平均时间复杂度 O(n1.3),最差时间复杂度O(n²),最好时间复杂度 O(n),空间复杂度 O(1)。
把记录按下标的⼀定增量分组,对每组进⾏直接插⼊排序,每次排序后减⼩增量,当增量减⾄ 1 时排序完毕。
13、直接选择排序的原理;
不稳定,时间复杂度 O(n²),空间复杂度 O(1)。
每次在未排序序列中找到最⼩元素,和未排序序列的第⼀个元素交换位置,再在剩余未排序序列中重复 该操作直到所有元素排序完毕。
14、堆排序的原理;
是对直接选择排序的改进,不稳定,时间复杂度 O(nlogn),空间复杂度 O(1)。
将待排序记录看作完全⼆叉树,可以建⽴⼤根堆或⼩根堆,⼤根堆中每个节点的值都不⼩于它的⼦节点 值,⼩根堆中每个节点的值都不⼤于它的⼦节点值。
以⼤根堆为例,在建堆时⾸先将最后⼀个节点作为当前节点,如果当前节点存在⽗节点且值⼤于⽗节点,就将当前节点和⽗节点交换。在移除时⾸先暂存根节点的值,然后⽤最后⼀个节点代替根节点并作 为当前节点,如果当前节点存在⼦节点且值⼩于⼦节点,就将其与值较⼤的⼦节点进⾏交换,调整完堆 后返回暂存的值。
15、冒泡排序的原理;
稳定,平均/最坏时间复杂度 O(n²),元素基本有序时最好时间复杂度 O(n),空间复杂度 O(1)。
⽐较相邻的元素,如果第⼀个⽐第⼆个⼤就进⾏交换,对每⼀对相邻元素做同样的⼯作,从开始第⼀对 到结尾的最后⼀对,每⼀轮排序后末尾元素都是有序的,针对 n 个元素重复以上步骤 n -1 次排序完毕。
当序列已经有序时仍会进⾏不必要的⽐较,可以设置⼀个标志记录是否有元素交换,如果没有直接结束⽐较。
16、快速排序的原理;
是对冒泡排序的⼀种改进,不稳定,平均/最好时间复杂度 O(nlogn),元素基本有序时最坏时间复杂度O(n²),空间复杂度 O(logn)。
⾸先选择⼀个基准元素,通过⼀趟排序将要排序的数据分割成独⽴的两部分,⼀部分全部⼩于等于基准 元素,⼀部分全部⼤于等于基准元素,再按此⽅法递归对这两部分数据进⾏快速排序。
快速排序的⼀次划分从两头交替搜索,直到 low 和 high 指针重合,⼀趟时间复杂度 O(n),整个算法的时间复杂度与划分趟数有关。
最好情况是每次划分选择的中间数恰好将当前序列等分,经过 log(n) 趟划分便可得到⻓度为 1 的⼦表, 这样时间复杂度 O(nlogn)。
最坏情况是每次所选中间数是当前序列中的最⼤或最⼩元素,这使每次划分所得⼦表其中⼀个为空表 , 这样⻓度为 n 的数据表需要 n 趟划分,整个排序时间复杂度 O(n²)。
17、循环和递归不同的点;
递归算法:
优点:代码少、简介。
缺点:它的运行需要较多次数的函数调用,如果调用层数比较深,需要增加额外的堆栈处理,比如参数传递需要压栈等操作,会对执行效率有一定影响。但是,对于某些问题,如果不使用递归,那将是极端难看的代码。
循环算法:
优点:速度快,结构简单。
缺点:并不能解决所有的问题。有的问题适合使用递归而不是循环。如果使用循环并不困难的话,最好使用循环。
18、排序算法怎么选择。
据量规模较⼩,考虑直接插⼊或直接选择。当元素分布有序时直接插⼊将⼤⼤减少⽐较和移动记录的次数,如果不要求稳定性,可以使⽤直接选择,效率略⾼于直接插⼊。
数据量规模中等,选择希尔排序。
数据量规模较⼤,考虑堆排序(元素分布接近正序或逆序)、快速排序(元素分布随机)和归并排序稳定性)。⼀般不使⽤冒泡。
踏上了编程之路,也就意味着你选择了一种终身学习的生活方式。每一个程序员都要练就十八般武艺,而掌握数据结构与算法就像修炼了九阳神功。换句话说,掌握了数据结构与算法,你的内功修炼速度就会有质的飞跃。
结束收工~


