
- 1计算机操作系统原理复习笔记——考试版_计算机系统原理笔记
- 2Xcode13.3.1 upload ipa error:Invalid Provisioning Signature....STATE_ERROR.VALIDATION_ERROR.9016解决方案_xcode 13.3 1
- 3国产游戏引擎,竟然用来搞民航_腾讯的国产渲染引擎
- 4【STM32+HAL】语音识别模块LD3320(SPI版)_ld3320 spi版本
- 5小程序https启用tls1.2
- 6Import Error: Bad git executable._importerror: bad git executable.
- 7python 接口测试_python接口测试
- 8Python操作spark_pip install sparkapi
- 9java json 嵌套list_java-嵌套JSON的POJO格式?
- 10Java 老矣,尚能饭否?
统计语言模型(一)
赞
踩
目录
统计语言模型简介
先导引入篇
原始语句: 南京市长江大桥
Sentence1:南京市 长江大桥
Sentence2:南京 市长 江大桥
我们根据分词的方法,也就是词典来判断的话,两种语句都对,那么哪种更合理呢?
统计语言模型处理的核心是如何利用统计手法对语言来进行建模,具体说,建立一个语料库,里面的句子都是分好词的,然后我们来统计一下所有的切分方式出现的次数就可以了。
举个例子
构建一个 语料库:
商品 和 服务
商品 和服 物美价廉
商品 和 货币
这个语料库只有三句话,每句话出现的概率为1/3。
我们希望能够更准确估计一个句子分布,那么我们的方法就是增大样本数量。

语言模型任务
相关概念
模型:指的是对事物的数学抽象; 语言模型:对语言现象的数学抽象。
定义:语言模型任务是给一个句子分配概率的任务,也就是计算p(w),w是一句话。此外,语言模型也对给定单词在多个单词也就是一个词序列后的可能性进行分析,并分配概率。
那么p(w)怎么知道呢?我们就是说无法枚举全人类在过去、现在和将来生成的所以句子,所以说我们只能解释一个小型的样本空间,这个样本空间我们就称之为语料库。
因为我们真实世界的句子空间是无穷无尽的,那我们采集它的子集,样本空间,那就是一个语料库。看个例子:
The lazy dog barked loudly.
Situation:南京市 长江 ____?
我们已知 lazy dog,然后预测它下一个词为barked的可能性;或者在已知南京市长江这两个词的前提下,它后面是“大桥”的概率为75%这样子。

那么,在了解之前,我们先来看一下贝叶斯公式
贝叶斯公式
第一种表现形式:P(AB) = P(A|B) P(B) = P(B|A) P(A)
贝叶斯公式常见表现形式,有以下两种:


定义的数学解释:分配一个词在一个序列之后的概率(条件概率),给任意词序分配概率。
结论:语言模型就是给任何词序列分配一个概率。
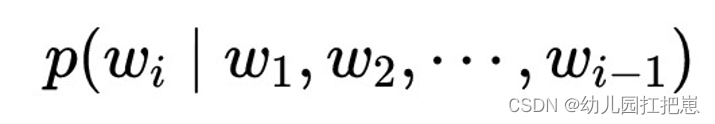 等价于
等价于 

我们定义一个统计语言模型如下:
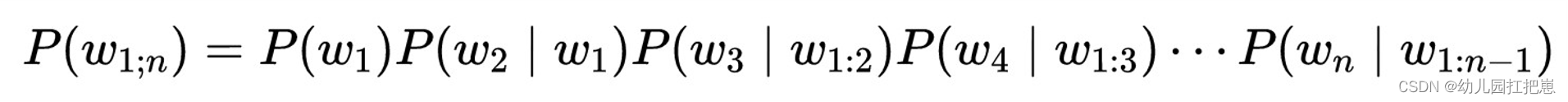
我们认为 计算一句话出现的概率 等价于 计算给定词序列之后后一个词出现的概率。
我们统计语言模型认为,我需要怎么计算这句话出现的概率呢?它不是说单单地依靠 P(Wi | W1,W2,···,Wi-1)这个公式,而是说我们要来模仿一个人说话的一个顺序,然后来得到这样一个表达式 P(W1,W2,···,Wk),这其实就是一个统计语言模型。

计算实例
语料库:
BOS 商品 和 服务 EOS BOS 商品 和服 物美价廉 EOS BOS 服务 和 货币 EOS
BOS为标记符,(begining of sentence),表示句子开始了,方便模型计算;
EOS同理,为 end of sentence,表示句子结束了。
例如,在句子开头的时候,它这个词就是“商品”的概率为2/3,三份中有两份。
很容易就可得出:
P(商品 | BOS) = 2/3
P(和 | BOS 商品) = 1/2
P(服务 | BOS 商品 和) = 1/1
P(EOS | BOS 商品 和 服务) = 1/1
那么,P (BOS,商品,和,服务,EOS)
= P(商品|BOS) x P(和|BOS,商品) x P(服务|BOS,商品,和) x P(EOS|BOS,商品,和,服务)
= 2/3 x 1/2 x 1/1 x 1/1
= 1/3
总结
语言模型任务的完美表现是预测序列中的下一个单词具有与人类参与者所需的相同或更低的猜测数目,就比如说我已知“商品,和”,下一个字词可能为“货币”或者“服务”的概率,这是人类智能的体现。
此外,语言模型还可以用于对机器翻译和语音识别的结果进行打分,这其实就是概率是否是比较高的。语言模型是NLP、人工智能、机器学习研究的主要角色。
缺点
- 句子越长,概率越低,根据计算的公式,P(W1)是一个小于1的数字,后边再乘上越来越小的数字,趋于0,那么矩阵就越洗漱。
- 句子越长,计算的代价就大,那么要根据句子来计算和储存的p也就越多,建立的索引就越多。
- 最后一个词取决于这句话前面的所有词,使得高效建模整句话难度大,这就造成一个低效的情况。因为在一个语料库中,正常来说,它不需要取决于这句话前面每一个词语的每一个词是什么的,因为语言是灵活的。

改进方法:n-gram
最经典和最传统的改进方法,就是n阶马尔可夫模型,也叫n元语法或者n-gram。
一个k阶马尔科夫假设,假设序列中下一个词的概率只依赖于其前k个词。用公式表示如下(i为要预测的词的位置或索引,w代表词):
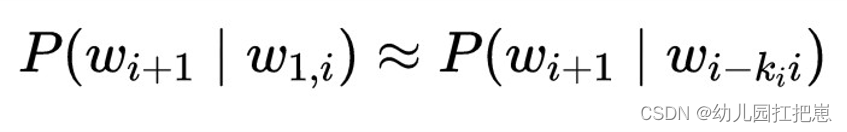
那句子的概率估计就变为:
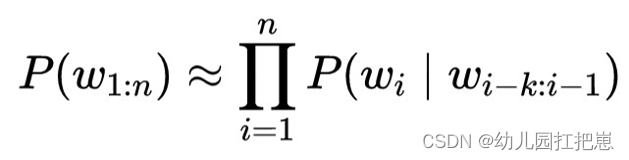
如果一个词的出现与它周围的词是独立的,则称之为unigram,也就是一元语言模型,即:
P(W1,W2,···,Wm) = P(W1) P(W2) P(W3) ··· P(Wm-1) =
如果一个词的出现仅仅依赖于它前面一个词,则称之为bigram,也就是二元语言模型,即:
P(W1,W2,···,Wm) = P(W1) P(W2 | W1) P(W3 | W2) ··· P(Wm-1 | Wm-2) =
如果一个词的出现仅仅依赖于它前面两个词,则称之为trigram,也就是三元语言模型,即:
P(W1,W2,···,Wm) = P(W1) P(W2 | W1) P(W3 |W2 W1) ··· P(Wm-1 | Wm-2 Wm-3) =
举个例子
我现在想预测出一个完整句子 “我 要去 吃 冰激凌” ,
按照之前的统计模型,我们可以得出概率:
p(我 要去 吃 冰激凌)= p(我) x p(要去|我) x p(吃|我,要去) x p(冰激凌|我,要去,吃)
而若我们基于n-gram模型:p(冰激凌|我 要去 吃)=p(冰激凌|吃)
整个句子出现的概率:
p(我 要去 吃 冰激凌) = p(我) x p(要去|我) x p(吃|要去) x p(冰激凌|吃) ----- bigram
p(我 要去 吃 冰激凌) = p(我) x p(要去|我) x p(吃|我,要去) x p(冰激凌|要去,吃) ----- trigram
使用实例
统计语言模型可以做成什么事?

