
1.Docker的内核知识
Docker容器的本质是宿主机上的进程,通过namespace实现资源隔离,通过cgroups实现资源限制,通过写时复制机制实现高效的文件操作。
1.1.namespace资源隔离
Linux提供了6种namespace隔离的系统调用。

Linux内核实现namespace的主要目的就是为了实现轻量级虚拟化(容器)服务。在同一个namespace下的进程可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,仿佛自己置身于一个独立的系统环境中,以此达到独立和隔离的目的。
1.1.1.调用namespace的API
namespace的API包括clone()、setns()以及unshare(),还有/proc下的部分文件。为了确定隔离的到底是哪种namespace,在使用这些API时,通常需要指定以下六个常数的一个或多个,通过|(位或)操作来实现。你可能已经在上面的表格中注意到,这六个参数分别是CLONE_NEWIPC、CLONE_NEWNS、CLONE_NEWNET、CLONE_NEWPID、 CLONE_NEWUSER和CLONE_NEWUTS。
1.通过clone()创建新进程的同时创建namespace
使用clone()来创建一个独立namespace的进程是最常见做法,它的调用方式如下:
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg); clone()实际上是传统UNIX系统调用fork()的一种更通用的实现方式,它可以通过flags来控制使用多少功能。一共有二十多种CLONE_*的flag(标志位)参数用来控制clone进程的方方面面(如是否与父进程共享虚拟内存等等),下面外面逐一讲解clone函数传入的参数。
- 参数
child_func传入子进程运行的程序主函数。 - 参数
child_stack传入子进程使用的栈空间 - 参数
flags表示使用哪些CLONE_*标志位 - 参数
args则可用于传入用户参数
2.查看/proc/[pid]/ns文件
用户就可以在/proc/[pid]/ns文件下看到指向不同namespace号的文件,效果如下所示,形如[4026531839]者即为namespace号。
可以通过ps -ef查看容器内不同的进程,从而进入对应的ns中,会发现同一容器下,pid,mnt,net等编号相同。
如果两个进程指向的namespace编号相同,就说明他们在同一个namespace下,否则则在不同namespace里面。/proc/[pid]/ns的另外一个作用是,一旦文件被打开,只要打开的文件描述符(fd)存在,那么就算PID所属的所有进程都已经结束,创建的namespace就会一直存在。
- $ ls -l /proc/$$/ns <<-- $$ 表示应用的PID
- total 0
- lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 ipc -> ipc:[4026531839]
- lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 mnt -> mnt:[4026531840]
- lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 net -> net:[4026531956]
- lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 pid -> pid:[4026531836]
- lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 user->user:[4026531837]
- lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 uts -> uts:[4026531838]
1.1.2.UTS
UTS提供了主机名和域名的隔离,这样每个容器就可以拥有了独立的主机名和域名,在网络上可以被视作一个独立的节点而非宿主机上的一个进程。
Docker中,每个镜像基本都以自己所提供的服务命名了自己的hostname而没有对宿主机产生任何影响,用的就是这个原理。
1.1.3.IPC
IPC:容器 中进程间进行通信通常采用的消息队列,信号量,和共享内存。
IPC资源就申请了这样一个全局唯一的32位ID,所以IPC namespace中实际上包含了系统IPC标识符以及实现POSIX消息队列的文件系统。
在同一个IPC namespace下的进程彼此可见,而与其他的IPC namespace下的进程则互相不可见=====》同一ns下进程并不一定彼此可见。
1.1.4.PID
两个不同的namespace可以拥有相同的PID。每个PID namespace都有 各自的计数程序。
内核为所有的PID namespace维护了一个树状结构,最顶层的是系统初始时创建的,我们称之为root namespace。他创建的新PID namespace就称之为child namespace(树的子节点),而原先的PID namespace就是新创建的PID namespace的parent namespace(树的父节点)。通过这种方式,不同的PID namespaces会形成一个等级体系。所属的父节点可以看到子节点中的进程,并可以通过信号量等方式对子节点中的进程产生影响。
- 每个PID namespace中的第一个进程“PID 1“,都会像传统Linux中的
init进程一样拥有特权,起特殊作用。 - 一个namespace中的进程,不可能通过
kill或ptrace影响父节点或者兄弟节点中的进程,因为其他节点的PID在这个namespace中没有任何意义。 - 如果你在新的PID namespace中重新挂载
/proc文件系统,会发现其下只显示同属一个PID namespace中的其他进程。 - 在root namespace中可以看到所有的进程,并且递归包含所有子节点中的进程。
(1)PID namespace中的init进程
当我们新建一个PID namespace时,默认启动的进程PID为1。
PID namespace维护这样一个树状结构,非常有利于系统的资源监控与回收。Docker启动时,第一个进程也是这样,实现了进程监控和资源回收,它就是dockerinit。
(2)信号量与init进程
PID Namespace如此特殊,自然内核也赋予它了特殊权限---信号量屏蔽。
如果init进程没有写处理某个代码逻辑,那么再同一个PID namespace下的进程即使拥有超级权限,发送给他的信号量都会被屏蔽。这个功能防止了init进程被误杀。
如果是init的父进程 ,如果不是SIGKILL(销毁进程)或SIGSTOP(暂停进程)也会被忽略。但如果发送SIGKILL或SIGSTOP,子节点的init会强制执行(无法通过代码捕捉进行特殊处理),也就是说父节点中的进程有权终止子节点中的进程。
1.1.5.Mount
Mount namespace通过隔离文件挂载点来对文件进程隔离,是第一个出现的namespace。
隔离后,不同mount namespace中的文件结构发生变化也互不影响。
你可以通过/proc/[pid]/mounts查看到所有挂载在当前namespace中的文件系统,还可以通过/proc/[pid]/mountstats看到mount namespace中文件设备的统计信息,包括挂载文件的名字、文件系统类型、挂载位置等等。
一个挂载状态可能为如下的其中一种:
- 共享挂载(shared)
- 从属挂载(slave)
- 共享/从属挂载(shared and slave)
- 私有挂载(private)
- 不可绑定挂载(unbindable)
1.1.6.Network
Network namespace主要提供了网络资源的隔离,包括网络设备,IPv4和IPv6协议栈、IP路由表、防火墙、/proc/net目录、/sys/class/net目录、端口(socket)等等。
1.1.7User
User namespace主要隔离了安全相关的标识符(identifiers)和属性(attributes),包括用户ID、用户组ID、root目录、key(指密钥)以及特殊权限。说得通俗一点,一个普通用户的进程通过clone()创建的新进程在新user namespace中可以拥有不同的用户和用户组。
1.2.cgroups资源限制
cgroups是Linux内核提供的一种机制,这种机制可以根据需求把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。
cgroups可以限制、记录任务组所使用的物理资源(包括CPU、Memory、IO等),为容器实现虚拟化提供基本保证、是构建Docker等一系列虚拟化管理工具的基石。
1.2.1.cgroups特点
1.cgroups的api以一个伪文件系统的方式实现,用户态的程序可以通过文件操作实现cgroups的组织管理。
2. cgroups的组织管理操作单元可以细粒到线程级别,另外用户可以创建和销毁cgroup,从而实现资源再分配。
3.所有资源管理的功能,都以子系统的方式实现,接口统一。
4.子任务创建之初与其父任务处于同一个cgroups控制组。
1.2.2.cgroups作用
实现cgroups的主要目的是为不同用户层面的资源管理,提供一个统一化的接口。从单个任务的资源控制到操作系统层面的虚拟化,cgroups提供了四大功能。
1.资源限制:cgroups可以对任务使用的资源总额进行限制,如一旦超过设定的内存限制就发出OOM
2.优先级分配:通过分配的CPU时间片数量及磁盘IO带宽大小。
3.资源统计:cgroups可以统计系统的资源使用量。
4.任务控制:cgroups可以对任务进行挂起、恢复等操作。
1.2.3.术语
- task(任务):cgroups的术语中,task就表示系统的一个进程。
- cgroup(控制组):cgroups 中的资源控制都以cgroup为单位实现。cgroup表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个cgroup,也可以从某个cgroup迁移到另外一个cgroup。
- subsystem(子系统):cgroups中的subsystem就是一个资源调度控制器(Resource Controller)。比如CPU子系统可以控制CPU时间分配,内存子系统可以限制cgroup内存使用量。
- hierarchy(层级树):hierarchy由一系列cgroup以一个树状结构排列而成,每个hierarchy通过绑定对应的subsystem进行资源调度。hierarchy中的cgroup节点可以包含零或多个子节点,子节点继承父节点的属性。整个系统可以有多个hierarchy。
1.2.4.组织结构与基本规则
(1)同一个hierarchy可以附加一个或者多个subsystem。
(2)一个subsystem可以附加到多个hierarchy,当且仅当这些hierarchy只有这唯一一个subsystem。
(3)系统每次新建一个hierarchy时,该系统上的所有task默认构成了这个新建的hierarchy的初始化cgroup,这个cgroup也称为root cgroup。
1.2.5.subsystem
subsystem:cgroups的资源控制系统。每种subsystem控制一种资源,目前Docker使用了如下8中subsystem:
- blkio:为块设备设定输入/输出限制,比如物理驱动设备(包括磁盘、固态硬盘、USB等)。
- cpu: 使用调度程序控制task对CPU的使用。
- cpuacct: 自动生成cgroup中task对CPU资源使用情况的报告。
- cpuset: 为cgroup中的task分配独立的CPU(此处针对多处理器系统)和内存。
- devices :可以开启或关闭cgroup中task对设备的访问。
- freezer :可以挂起或恢复cgroup中的task。
- memory :可以设定cgroup中task对内存使用量的限定,并且自动生成这些task对内存资源使用情况的报告。
- perf_event :使用后使得cgroup中的task可以进行统一的性能测试。{![perf: Linux CPU性能探测器,详见https://perf.wiki.kernel.org/index.php/Main_Page]}
- *net_cls 这个subsystem Docker没有直接使用,它通过使用等级识别符(classid)标记网络数据包,从而允许 Linux 流量控制程序(TC:Traffic Controller)识别从具体cgroup中生成的数据包。
查询mount 的cgroup的文件系统

以cpu子系统为例
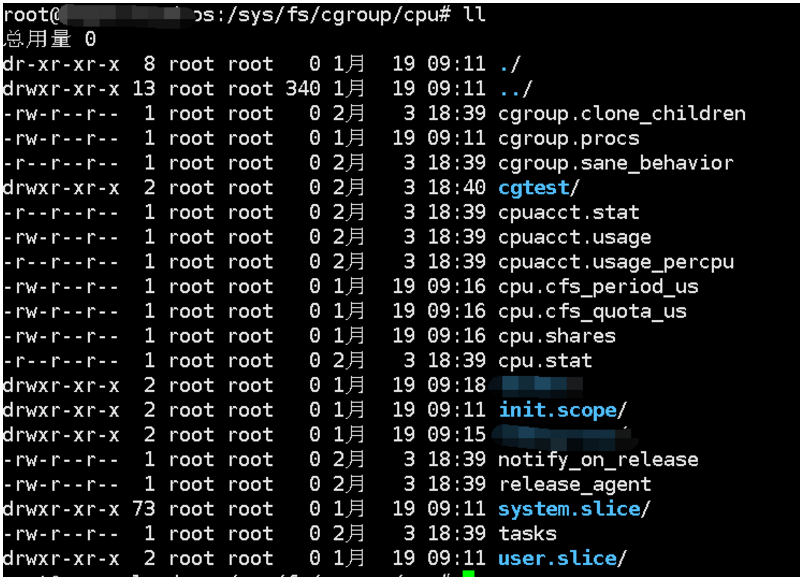
在/sys/fs/cgroup的cpu子目录下创建控制组,控制组目录创建成功后,多了下面类似文件
- $/sys/fs/cgroup/cpu# mkdir cgtest2
- $/sys/fs/cgroup/cpu# ls cgtest2/
- cgroup.clone_children cgroup.procs cpuacct.stat cpuacct.usage cpuacct.usage_percpu cpu.cfs_period_us cpu.cfs_quota_us cpu.shares cpu.stat notify_on_release tasks
-
- #限制18828进程
- $echo 18828 >> /sys/fs/cgroup/cpu/cgtest2/tasks
- #将cpu限制为最高使用20%
- $echo 2000 > /sys/fs/cgroup/cpu/cgtest2/cpu.cfs_quota_us
-
- #查看docker控制组目录
- $/sys/fs/cgroup/cpu# tree docker/
- docker/
- ├── 20fb25551e96ba42b2401ef70785da68e96ffc10525b10c2434e2b9ad4f1e477 #容器ID
- │ ├── cgroup.clone_children
- │ ├── cgroup.procs
- │ ├── cpuacct.stat
- │ ├── cpuacct.usage
- │ ├── cpuacct.usage_percpu
- │ ├── cpu.cfs_period_us
- │ ├── cpu.cfs_quota_us
- │ ├── cpu.shares
- │ ├── cpu.stat
- │ ├── notify_on_release
- │ └── tasks

1.2.3.cgroups实现方式机工作原理
1.cgroups如何判断资源超限机超出限额后的措施
cgroups提供了统一的接口对资源进行控制和统计,但限制的方式不尽相同。
2./sys/fs/cgroup/cpu/docker/<container-ID>下文件的作用
一个cgroup创建完成,不管绑定了何种子系统,其目录下都会生产下面几个文件,用来描述cgroup信息,把相应的信息写入这些配置文件就可以生效。
tasks:罗列了所有在该cgroup中任务的TID,即所有进程及线程。
cgroup.procs:罗列了所有在该cgroup中的TGID(线程组ID)
notify_on_release:表示是否在cgroup中最后一个任务推出时通知运行releaseagent,填0或者1,默认为0表示不运行
1.2.4.cgroups的使用方法简介
1.安装cgroup
#apt-get install cgroup-bin# mkdir /cgroup 这个目录可以用于挂载subsystem2.查看cgroup及子系统挂载状态
- 查看所有的cgroup:
lscgroup - 查看所有支持的子系统:
lssubsys -a - 查看所有子系统挂载的位置:
lssubsys –m - 查看单个子系统(如memory)挂载位置:
lssubsys –m memory
3.创建hierarchy并挂载子系统
创建hierarchy
#mount -t tmpfs yaohongcgroups /sys/fs/cgroup
创建对应文件夹
#mkdir /sys/fs/cgroup/yh
创建subsystem到对应层级
# mount -t cgroup -o subsystems yhsubsystem /cgroup/yhtest1.3.Docker 架构预览
Docker时采用client-server架构模式,如下图所示,Docker client向Docker daemno发送信息进行互相交互.
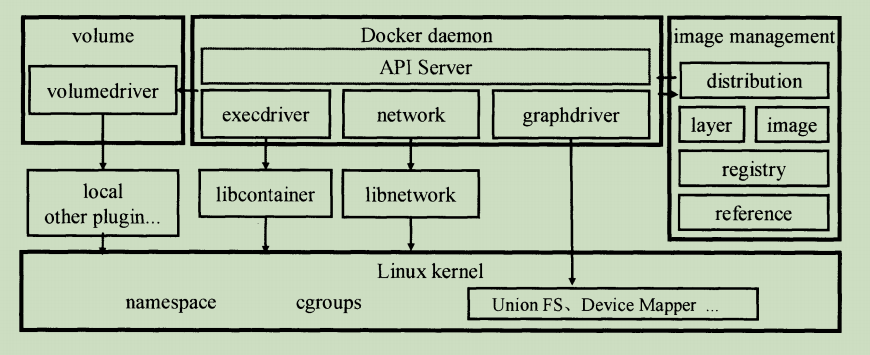
Docker 通过driver模块来实现容器执行环境的创建和管理.
通过镜像管理中的distribution、registry模块从Docker registry中下载镜像,
通过镜像管理中的image、reference和layer存储镜像的元数据;
通过镜像驱动graphdriver将镜像文件存储到具体的文件系统中;
当需要为Docker容器创建网络环境时,通过网络管理模块network调用libnetwork创建并配置Docker容器的网络环境;
当需要为容器创建数据卷volume时,通过volume调用某个具体的volumedriver创建一个数据卷,来创建一个数据卷并负责后续的挂载操作;
当需要限制Docker容器运行资源或者执行用户指令等操作时,咋通过execdriver来完成。
libcontainer时对cgroups和namespace的二次封装,
execdriver时通过libcontainer来实现对容器的具体管理,包括利用UTS、IPC、PID、network、mount、user等namespace实现容器之间的资源隔离和利用cgroups实现资源限制
【Docker daemon】
后台核心进程,用户相应client的请求,该进程会在后台启动一个API Server,负责接收由Docker client发送的请求,请求有daemon分发调度,再由具体的函数来执行请求。
【Docker client】
用于想Docker daemon发起请求,执行相应的容器管理操作,它即是可以命令行工具docker,也是遵循Docker API的客户端。
【image mamagement】
Docker通过distribution、registry、layer、image、reference等模块实现Docker镜像的管理,这些模块统称为镜像管理【image mamagement】
1.distribution:负责与Docker registry进行交换,上传下载镜像以及存储与v2相关的元数据。
2.register:负责与Docker registry有关的身份验证,镜像查找,验证及管理
3.image:负责与镜像元数据有关的存储,查找,镜像层的引用
4.reference(参考):负责存储本地所有镜像的repository(存储库),并维护与镜像ID之间的映射关系。
5.layer:负责与镜像层和容器层元数据有关的增删查改,并负责将镜像层的增删查改操作映射到实际存储镜像层文件系统的graphdriver模块。
1.4.client和daemon
1.4.1.client模式
Docker命令对应源文件时docker/docker.go,它的使用方式如下:
docker [OPTIONS] COMMAND [arg ...]
其中OPTIONS参数称为flag,任何时候执行一个docker命令,Docker都需要先解析这些flag,然后按照用户声明的COMMAND向子命令执行对应的操作。
client模式下的docker命令工作流程包含如下几个步骤。
1.解析flag信息
这里列出几个client模式比较重要的OPTIONS
Debug,对应-D和–debug参数,这个flag用于启动调试模式
LogLevel,对应-l和–log-level参数,默认等级是info,可选参数有:panic、error、warn、info、debug。
Hosts,对应-H和–host=[]参数,对于client模式,就是指本次操作需要连接的Docker daemon位置,而对于daemon模式,则提供所要监听的地址。若Hosts变量或者系统环境变量 DOCKER_HOST不为空,说明用户指定了host对象;否则使用默认设定,默认情况下Linux系统设置为unix:///var/run/docker.sock.
protoAddrParts,这个信息来自于-H参数中://前后的两部分组合,即与Docker daemon建立通信的协议方式与socket地址。
2.创建client实例
client的创建就是在已有配置参数信息的基础上,调用api/client/cli.go#NewDockerCli,需要设置好proto(传输协议)、addr(host的目标地址)和tlsConfig(安全传输层协议的配置),另外还会配置标准输入输出及错误输出。
3.执行具体的命令
Docker client对象创建成功后,剩下的执行具体命令的过程就交给cli/cli.go来处理。
1.4.2.daemon模式
Docker运行时如果使用docker daemon 子命令,就会运行Docker daemon。一旦docker进入了daemon模式,剩下的初始化和启动工作就都由Docker的docker/daemon.go#CmdDaemon来完成。
Docker daemon通过一个server模块(api/server/server.go)接收来自client的请求,然后根据请求类型,交由具体的方法去执行。
下面是Docker daemon启动与初始化过程的详细解析
1.API Server的配置和初始化过程
首先,在docker/daemon.go#CmdDaemon中,Docker会继续按照用户的配置完成server的初始化并启动它。这个server为API Server,就是专门负责响应用户请求并将请求交给daemon具体方法去处理的进程。它的启动过程如下。
(I)整理解析用户指定的各项参数。
(2)创建PID文件。
(3)加载所需的serve辅助配置,包括日志、是否允许远程访问、版本以及TLS认证信息等。
(4)根据上述server配置,加上之前解析出来的用户指定的server配置(比如Hosts ),通过goroutine的方式启动API Server。这个server监听的socket位置就是Hosts的值。
(5)创建一个负责处理业务的daemon对象(对应daemon/damone.go)作为负责处理用户请求的逻辑实体。
(6)对APIserver中的路由表进行初始化,即将用户的请求和对应的处理函数相对应起来。
(7)设置一个channel,保证上述goroutine只有在server出错的情况下才会退出。
(8)设置信号捕获,当Docker daemon进程收到INT, TERM, QUIT信号时,关闭API Server,调用shutdownDaemon停止这个daemon。
(9)如果上述操作都成功,API ServergjG会与上述daemon绑定,并允许接受来自client的连接。
(10)最后,Docker daemon进程向宿主机的init守护进程发送“READY=1”信号,表示这个Docker daemon已经开始正常工作了。
2.daemon对象的创建与初始化过程
docker daemon是如何创建出来的?是通过daemon/daemon.go#NewDaemon方法。
NewDaemon过程会按照Docker的功能特点,完成所需的属性设置用户或者系统指定的值,需要完成的配置至少包括以下特点:
(1)Docker容器的配置信息:设置默认的网络最大传输单元,检测网桥配置信息
(2)检测系统支持及用户权限
(3)工作路径,默认为/var/lib/docker
(4)配置Docker容器所需的文件环境
配置graphdriver目录,用于完成Docker容器镜像管理所需的底层存储驱动层

1.5.libcontainer
libcontainer是Docker对容器管理的包,它基于Go语言实现,通过管理namespace、cgroups、capabilities以及文件系统来进行容器控制。
你可以使用libcontainer创建容器,并对容器进行生命周期的管理。
1.5.1libcontainer特性
目前版本的libcontainer,功能实现上涵盖了包括namespaces使用、cgroups管理,Rootfs的配置启动,默认的Linux capability权限集、以及经常运行环境变量配。
1.建立文件系统:文件系统方面,容器运行rootfs。所有容器中要执行的指令,都需要包含在rootfs所有挂载在容器销毁时都会被卸载。
2.资源管理:Docker使用cgroup进行资源管理和限制,包括设备、内存、CPU、输入输出等。
3.安全特性:libcontainer目前可通过配置capabilities、SELinux、apparmor 以及seccomp进行一定的安全防范。
4.在运行着的容器中执行新进程:就是我们熟悉的docker exec功能,指令的二进制文件需要包含在容器的rootfs之内。
5.容器热迁移:通过libcontainer你已经可以把一个正在运行的进程状态保存到磁盘上,然后在本地或其他机器中重新恢复当前的运行状态。
1.6.libcontainer实现原理
在Docker中,对容器管理的模块为execdriver,目前Docker支持的容器管理方式有两种,一种就是最初支持的LXC方式,另一种称为native,即使用libcontainer进行容器管理。
虽然在execdriver中只有LXC和native两种选择,但是native(即libcontainer)通过接口的方式定义了一系列容器管理的操作,包括处理容器的创建(Factory)、容器生命周期管理(Container)、进程生命周期管理(Process)等一系列接口。
1.6.Docker镜像管理
1.6.1.什么是Docker镜像
Docker镜像:Docker镜像是一个只读性的Docker容器模板,含有启动Docker容器所需的文件系统结构及其内容是启动一个Docker容器的基础。
1.rootfs
rootfs:Docker镜像的文件内容以及一些运行Docker容器的配置文件组成了Docker容器的静态文件系统环境。
可以这么理解,Docker镜像是Docker 容器的静态视角,Docker容器时Docker镜像的运行状态。
在Docker架构中,当Docker daemon为Docker容器挂载rootfs时,沿用了linux内核启动时的方法,即将rootfs设置为只读模式。在挂载完毕后,利用联合挂载(union mount)技术在已有的只读rootfs上再挂载一个读写层。这样,可读写层处于Docker容器文件系统的最顶层,其下可能联合挂载多个只读层,只有再Docker容器运行过程中国文件系统发生变化,才会将变化的内容写到可读写层,并且隐藏只读层中老文件。
容器文件系统其实是一个相对独立的组织,分为1.可读写部分(read-write layer及volumes),2.init-layer,3.只读层(read-only layer)这3个部分共同组成的一个容器所需的下层文件系统。
2.镜像的主要特点
(1)分层:docker commit提交这个修改过的容器文件系统为一个新的镜像时,保存的内容仅为最上层读写文件系统中被更新过的文件。
(2)写是复制:多个容器之间共享镜像,不需要再复制出一份镜像,而是将所有的镜像层以只读的方式挂载到一个挂载点,而在上面覆盖一个可读写层的容器层。
(3)内容寻址:对镜像层的内容计算校验和,生成一个内容哈希值,并以此哈希值替代之前的UUID作为镜像的唯一标志,
(4)联合挂载(union mount):可以在一个挂载点同时挂载多个文件系统,将挂载点的原目录与被挂载内容进行整合,使得最终可见的文件系统将会包含整合之后的各层文件和目录。
1.6.2.Docker镜像关键概念
(1)registry:保持Docker镜像,其中还包括镜像层次结构和关于镜像的元数据。
(2)repository(存储库):registry是repository的集合,repository是镜像的集合。
(3)manifest(描述文件):主要存在于registry中作为Docker镜像的元数据文件,在pull、push、save和load中作为镜像结构和基础信息的描述文件。
(4)image:用来存储一组镜像相关的元数据,主要包括镜像的架构(amd64、arm64)、镜像默认配置信息,构建镜像的容器配置信息,包含所有镜像层信息的rootfs。
(5)layer(镜像层):用来管理镜像层的中间概念,主要存放镜像层的DIFF_ID、size、cache-id和parent等内容。
(6)dockerfile:
1.8.Docker网络管理
1.8.1.Docker网络架构
Docker公司再libnetwork中使用了CNM。CNM定义了构建容器虚拟化网络的模型,同时还提供了可以用于开发多种网络驱动的标准化接口和组件。
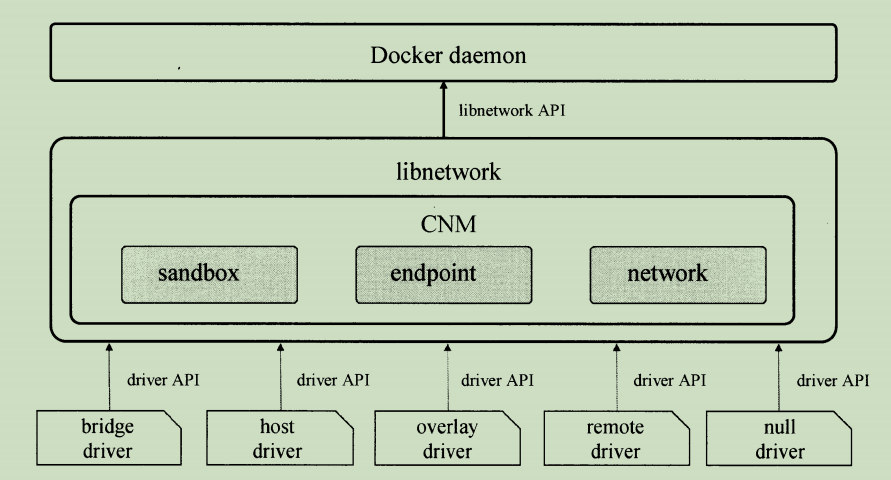
libnetwork和Docker Daemon及各个网络驱动的关系可以通过下图表示:
Docker daemon通过调用libnetwork对外提供的API完成网络的创建个管理等功能。
libnetwork中则使用了CNM来完成网络功能的提供,CNM中主要有sandbox、endpoint、network这3种组件。
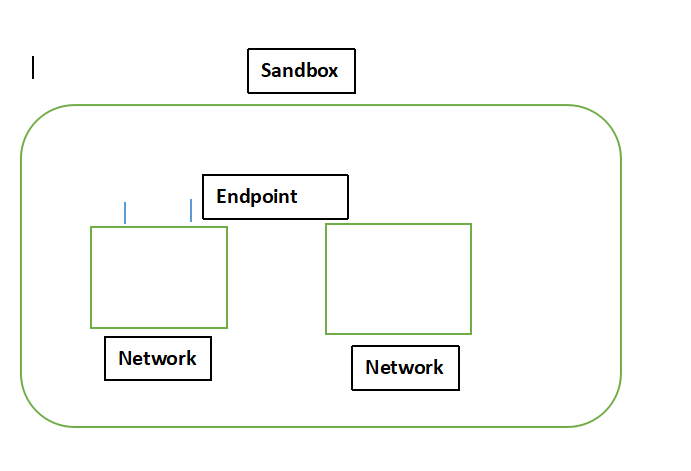
CNM中的3个核心组件如下:
(1)沙盒:一个沙盒包含了一个容器网络栈的信息。沙盒可以对容器的接口、路由、DNS等设置进行管理。沙盒可以有多个端点和网络。
(2)端点:一个端点可以加入一个沙盒和一个网络。一个端点只可以属于一个网络并且只属于一个沙盒。
(3)网络:一个网络时一组可以直接互相联调的端点,一个网络可以包括多个端点。
libnetwork中有一下5个内置驱动:
- bridge:默认驱动,网桥模式。
- host:去掉容器和Docker主机之间的网络隔离,直接使用主机的网络。不会为Docker模式创建网络协议栈,即不会创建network namespace。
- overlay:覆盖网络将多个Docker daemons 连接在一起,使swarm服务能够相互通信。
- macvlan:macvlan网络允许您将MAC地址分配给容器,使其显示为网络上的物理设备。Docker daemons 按其MAC地址将通信路由到容器。在处理希望直接连接到物理网络而不是通过Docker主机的网络堆栈路由的遗留应用程序时,使用macvlan驱动程序有时是最佳选择。
- null:Docker容器拥有自己的namepsace但不进行网络配置。
创建网络:
- # docker network ls
- NETWORK ID NAME DRIVER SCOPE
- 77a80a9afsdfff bridge bridge local
- 94694ffrfrfrfrfb host host local
- 39573frfrfrfrs4 none null local
-
-
- # docker network create backend
- ead41d30f820c2699ed532e84d0fsdffb5a1f4c37eea6c54bfa687b903649
-
- # docker network create fronted
- 8d94c681869f96b668c3abb72d3cb6aa14af236e94ef4fac7e38c157260787a6
-
- # docker network ls
- NETWORK ID NAME DRIVER SCOPE
- ead41dsssff820 backend bridge local
- 77a80a9a5c6bc bridge bridge local
- 8d94ccccc1869f fronted bridge local
- 9469402ccc53b host host local
- 395736cvc0e54 none null local
指定容器网络
# docker run -it --name container1 --net backend busybox
1.8.2.bridge网络
此条路由表示目的IP地址的数据包时docker0发出的。
- # route -n
- 172.25.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
如下图,docke0就时一个网桥,网桥的概念就类似与一个交换机,为连在其上的设备转发数据帧。
网桥上的veth网卡设备相当于交换机上的端口,可以将多个容器或虚拟机连接在其上,docker 0网桥就为连在其上的容器转发数据帧,是得同一台宿主机上的Docker容器之间可以互相通信。
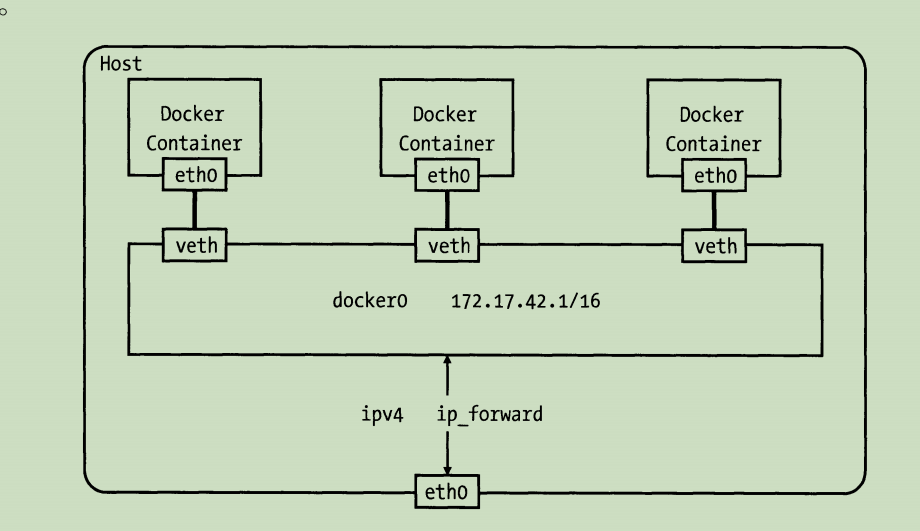
查看机器上的网桥和上面的端口:
- # brctl show
- bridge name bridge id STP enabled interfaces
- docker0 8000.02420e64d653 no veth7eb3e54
- yhbro 8000.000000000000 no
创建网桥:
# brctl show addbr yhbro
网桥参数设置:
--bip=CIDR:设置docker0的ip地址和子网范围。
--fixed-cidr=CIDR:限制Docker容器获取IP范围。
1.8.3.Docker daemon网络配置原理
Docker自身的网络,主要分为两部分,第一是Docker daemon的网络配置,第二是libcontainer的网络配置。Docker daemon的网络指的daemon启动时,在主机系统上所作的网络设置,可以被所有的docker容器使用,libcontainer的网络正对具体的容器是使用docker run命令启动容器是时,根据传入的参数为容器做的网络配置工作。
1.8.4.libcontainer网络配置原理
1.9.Docker与容器安全
1.9.1.Docker的安全机制
1.Docker daemon安全:默认使用Unix域套接字的方式与客户端进行通信,这种形式相对于TCP的形式比较安全。
2.镜像安全:registry访问权限控制可以保证镜像的安全。
registry安全:添加了仓库访问认证。
验证校验和:保证镜像的完整性。
3.内核安全:内核容器提供了两种技术cgroups和namespace。
4.容器之间网络安全:--icc可以禁止容器之间通信,主要通过设定iptables规划和实现。
5.容器能力限制:可以通过允许修改进程ID,用户组ID,等能力限制
6.限制能力:比如不需要setgid、setuid能力,可以再run容器时添加--cap-drop SETUID --cap-drop SETGID。
7.添加能力:比如启动容器时使用--cap-add ALL --cap-add SYS_TIME来增加允许修改系统时间能力。
1.9.DockerFile实践
-
Dockerfile整体就两类语句组成:
- # Comment 注释信息
- Instruction arguments 指令 参数,一行一个指令。
- Dockerfile文件名首字母必须大写。
- Dockerfile指令不区分大小写,但是为方便和参数做区分,通常指令使用大写字母。
- Dockerfile中指令按顺序从上至下依次执行。
- Dockerfile中第一个非注释行必须是FROM指令,用来指定制作当前镜像依据的是哪个基础镜像。
-
Dockerfile中需要调用的文件必须跟Dockerfile文件在同一目录下,或者在其子目录下,父目录或者其它路径无效。
DockerFile目前支持的参数:
1.ADD:
ADD的时候要复制的文件可以是个网络文件的URL。
2.COPY:COPY <src> <dest>
<src>:要复制的源文件或者目录,支持通配符,COPY复制指向的文件或者目录到镜像中,
<dest>:目标路径,即正创建的镜像的文件系统路径,建议使用绝对路径,否则,COPY指令会以WORKDIR为其起始路径。如果路径中如果包含空白字符,建议使用第二种格式用引号引起来,否则会被当成两个文件。
3.ENV:指定环境变量,同docker run -e,为镜像定义所需的环境变量,并可被ENV指令后面的其它指令所调用。
调用格式为$variable_name或者${variable_name},使用docker run启动容器的时候加上 -e 的参数为variable_name赋值,可以覆盖Dockerfile中ENV指令指定的此variable_name的值。
但是不会影响到dockerfile中已经引用过此变量的文件名。
4.FROM:FROM指令必须为Dockerfile文件开篇的第一个非注释行,用于指定构建镜像所使用的基础镜像,后续的指令运行都要依靠此基础镜像,所提供的的环境(简单说就是假如Dockerfile中所引用的基础镜像里面没有mkdir命令,那后续的指令是没法使用mkdir参数的
5.LABEL:同docker run -l,让用户为镜像指定各种元数据(键值对的格式)
6.STOPSIGNAL:指定发送使容器退出的系统调用信号。docker stop之所以能停止容器,就是发送了15的信号给容器内PID为1的进程。此指令一般不会使用。
7.USER:用于指定docker build过程中任何RUN、CMD等指令的用户名或者UID。默认情况下容器的运行用户为root。
8.VOLUME:docker run -v简化版,用于在镜像中创建一个挂载点目录。指定工作目录,可以指多个,每个WORKDIR只影响他下面的指令,直到遇见下一个WORKDIR为止。
9.WORKDIR:同docker run -w, Docker的镜像由只读层组成,每个只读层对应一个Dockerfile的一个指令,各个层堆叠在一起,每一层都是上一层的增量。WORKDIR也可以调用由ENV指令定义的变量。
- FROM ubuntu:1804 #从ubuntu:18.04Docker映像创建一个图层。
- COPY . /app #从Docker客户端的当前目录添加文件。
- RUN mkdir /APP #使用构建您的应用程序make
- CMD python /app/aa.py #指定要在容器中运行的命令
尽可能通过字母数字排序多行参数来简化以后的更改。这有助于避免软件包重复,并使列表更易于更新。这也使PR易于阅读和查看。在反斜杠(\)之前添加空格也有帮助。
- RUN apt-get update && apt-get install -y \
- bzr \
- cvs \
- git \
- mercurial \
- subversion
2.总结
2.1.什么是Docker
Docker本质上是一个进程,用namespace进行隔离,cgroup进行资源限制,rootfs作为文件系统。
2.2.namespace
namespace共分为6种,UTS,IPC,PID,NETWORK,MOUNT,USER。
UTS:隔离主机名和域名。IPC:隔离消息队列,信号量和共享内存。PID:隔离进程。network:隔离网络。mount:隔离挂载。user:隔离用户。
隔离的作用就是产生轻量级的虚拟化,相同namespace下进程可以感知彼此的变化,不同namespace的进程直接彼此无感知。
2.3.cgroup
2.4Docker的架构及相关组件
2.5.Docker网络
2.6.Docker安全

