
- 12024年最全2024-JAVA-大数据-面试汇总_大数据java部门面试
- 2离线安装gcc(CentOS7)
- 32023年最新Python安装详细教程_python自定义安装,互联网大厂100道Python面试题助你冲关金三银四_安装python advanced options
- 4QT删除文件夹以及多层文件夹下的所有内容_qt的资源文件怎么一次删除多个
- 5前端开发:基于移动端的JS原生Table的使用_移动端 table_js table
- 6多传感器的联合标定(三)
- 7信通院郭雪:软件供应链安全标准体系建设与洞察_安全体系和标准体系作为软件建设要求
- 8Vivado FFT v9.1 手册基础解读(一)-------- IP核输入输出信号与通信协议_vivado fft ip核数据手册
- 9如何使用ffmpeg为Mac进行视频硬解码/硬编码(在Qt环境)_ffmpeg macbook m2 硬编码
- 10Spark job提交流程源代码分析_spark.rpc.message.maxsize 不足
深度学习之自然语言处理(单词分布式表示)
赞
踩
自然语言处理(NLP)即让计算机理解人类日常语言
1.同义词词典
以人工方式进行定义意思相近的单词,有上位-下位,整体-部分关系。利用这些“单词网络”形式教会计算机单词之间的相关性,将单词含义间接教给计算机。
1.1WordNet
最著名同义词词典,一个基于人工定义的单词网络,使用单词网络可以计算单词之间的相似度,获得单词的近义词。
存在问题:难以顺应时代变化,词意会变;人工制作词典成本高;无法表示单词的微妙差异。
2.基于计数的方法
2.1 语料库预处理
语料库:大量文本数据
基于计数方法的目的:从这些富有实践知识的语料库中,自动且高效地提取本质
例子 1
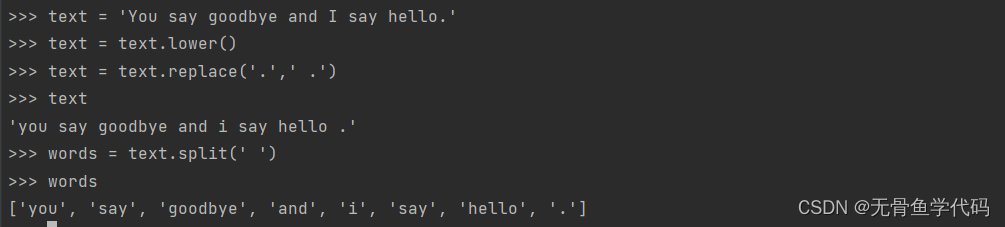
结论:lower()方法将所有字母转化为小写,replace()方法将.换成空格.(方便后续的分隔操作),split()方法将空格作为分隔符切分句子。
对上述单词标上ID,以便使用单词ID列表


变量id_to_word负责将单词ID转化为单词,word_to_id负责将单词转化为单词ID。它遍历一个名为 words 的列表中的每个单词,检查它是否已经在 word_to_id 字典中,如果不在字典中,则为该单词分配一个新的ID,并将单词与ID的映射关系分别存储在 word_to_id 和 id_to_word 字典中。

创建好单词ID和单词对应表,实际内容展示如上。还可以根据单词检索单词ID或根据单词ID检索单词。
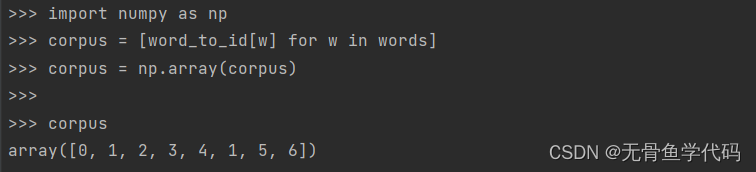
将单词列表转化为单词ID列表,这里用Python的列表解析式将单词列表转化为单词ID列表,在转化为Numpy数组。
corpus = [word_to_id[w] for w in words]:这行代码是一个列表推导式(list comprehension),用于将 words 列表中的每个单词转换为对应的ID,并存储在 corpus 列表中。假设 word_to_id 是一个单词到ID的字典,words 是包含单词的列表,那么这行代码的作用是将 words 中的每个单词通过 word_to_id 字典转换为对应的ID,并存储在 corpus 中。
2.2 单词分布式表示
分布式表示:将单词表示为固定长度的向量
分布式假设:某个单词的含义由它周围的单词形成,即单词本身没有含义,单词含义由它所在上下文(语境)形成。
上下文:某个单词(关注词)周围的单词
窗口大小:上下文的大小(即周围的单词有多少个),窗口大小为2,上下文包含左右各2个单词。
2.3 共现矩阵
用向量表示单词
例子 将窗口设置为1

所以向量[0,1,0,0,0,0,0]代表单词you。

以此类推,各行即对应单词的向量,称为共现矩阵。
例子:
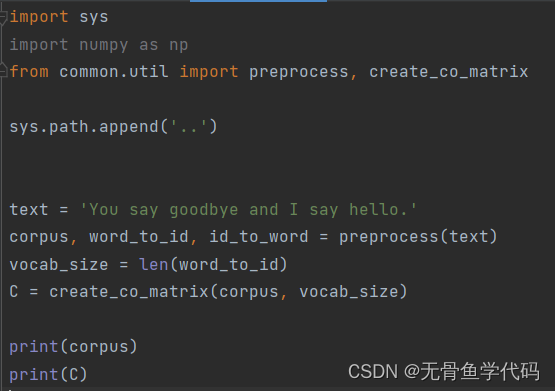

2.4 向量间相似度
方法:余弦相似度(直观表示两个向量在多大程度上指向同一方向。当方向完全相同,余弦相似度为1;完全相反,余弦相似度为-1)
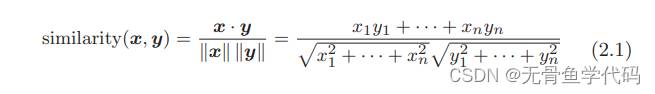
例子:

结论:可知you和i余弦相似度为0.7
2.5 相似单词排序

argsort()方法:对数组索引重新排序(返回值是数组的索引)
例:

例:

结论:按降序显示you这个查询词的前5个相似单词,单词旁边的是余弦相似度。缺点:语料库太小,和现实感觉又差距。
3. 基于计数方法的改进
使用更实用的语料库,获得单词“真实的”分布式表示。
3.1 点互信息(PMI)
用于解决常用词(the)和实用词(car)的相关性
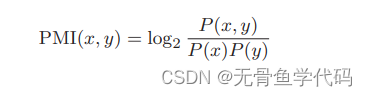


重写共现矩阵式
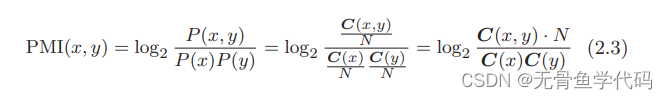
例:

结论:符合实际情况。因为多计算了(the)这个单词单独出现的次数
例:将共现矩阵转化为PPMI矩阵


结论:存在问题,单词向量维数增加,PPMI矩阵也不好处理。
3.2 降维
保留“重要信息”基础上减少向量维度。
例:
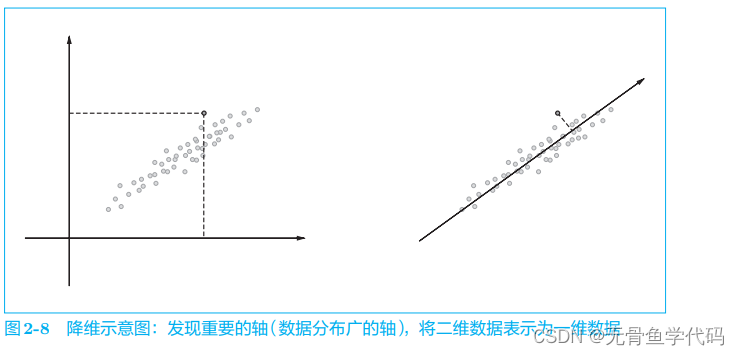
降维方法:奇异值分解(SVD:将任意矩阵分解为3个矩阵乘积)

3.3 PTB数据集
一种用于学习的语料库,弥补之前语料库小的问题。
安装sklearn模块,实现更快速的SDV执行大矩阵(未完成该例子,模块导入问题,电脑内存不足问题)
总结
通过运用各种方法逐步递进对语料库的处理,以达到计算出单词之间相似度问题。

