
- 1我的春招实习+秋招总结【前端开发】_前端找不到实习秋招是不是完了
- 2解决:fatal:unable to access‘https://github.com/xx/xx.git/‘:OpenSSL SSL_read:Connection was reset errno_fatal: unable to access
- 3数据中心GPU集群高性能组网技术分析
- 4LIama3 五一超级课堂 前置知识VScode 远程连接开发机_liama3 使用指南
- 5备忘: 使用langchain结合千问大模型,用本地知识库辅助AI生成代码_langchain和本地大语言模型 摘要提取
- 6PTA 7-9 树层次遍历_我们已知二叉树与其自然对应的树相比,二叉树中结点的左孩子对应树中结点的左孩子,
- 7MySQL数据库之索引_mysql 索引文件
- 8AI探索测试未来:人工智能与自动化测试的结合实战,文末实用干货自行领取!_面向未来的ai自动化测试工具
- 94.0 树莓派做下位机播放视频、控制电机舵机、超声波检测、paj7620手势传感器控制,树莓派串口通信等程序分析_树莓派 播放视频
- 10AITM2-0007 比光密度测定_aitm 2.0007下载
【LeetCode热榜100题(一)】_leetcode 投屏100
赞
踩
LeetCode热榜100题(一)
1.两数之和
难度(容易)
题目:给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
- 1
- 2
- 3
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
- 1
- 2
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
- 1
- 2
提示:
2 <= nums.length <= 104-109 <= nums[i] <= 109-109 <= target <= 109- 只会存在一个有效答案
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer,Integer> map = new HashMap<>();
for (int i = 0;i<nums.length;i++){
int complement = target-nums[i];
if(map.containsKey(complement)){
return new int[]{map.get(complement),i};
}
map.put(nums[i],i);
}
return null;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
通过哈希表来解决。遍历一遍数组,将每个元素的值及其下标存入哈希表中,然后再遍历一遍数组,对于每个元素,检查哈希表中是否存在一个键值等于 target 减去当前元素值的元素,如果存在则说明找到了答案,返回当前元素下标及哈希表中相应元素的下标即可。
2.两数相加
难度(中等)
题目:给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
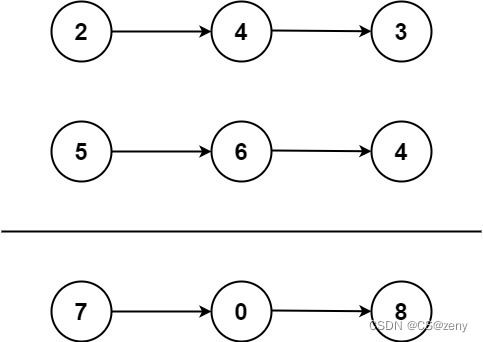
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
- 1
- 2
- 3
示例 2:
输入:l1 = [0], l2 = [0]
输出:[0]
- 1
- 2
示例 3:
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]
- 1
- 2
提示:
- 每个链表中的节点数在范围
[1, 100]内 0 <= Node.val <= 9- 题目数据保证列表表示的数字不含前导零
/** * Definition for singly-linked list. * public class ListNode { * int val; * ListNode next; * ListNode() {} * ListNode(int val) { this.val = val; } * ListNode(int val, ListNode next) { this.val = val; this.next = next; } * } */ class Solution { public ListNode addTwoNumbers(ListNode l1, ListNode l2) { ListNode dummyHead = new ListNode(0); ListNode p = l1, q = l2, curr = dummyHead; int carry = 0; while (p != null || q != null) { int x = (p != null) ? p.val : 0; int y = (q != null) ? q.val : 0; int sum = carry + x + y; carry = sum / 10; curr.next = new ListNode(sum % 10); curr = curr.next; if (p != null) p = p.next; if (q != null) q = q.next; } if (carry > 0) { curr.next = new ListNode(carry); } return dummyHead.next; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
这里我们定义了一个
ListNode类来表示链表节点,包括一个val属性和一个指向下一个节点的next属性。接下来,我们定义了一个addTwoNumbers方法,该方法接受两个链表l1和l2作为参数,并返回一个新的链表。首先,我们创建一个虚拟头节点
dummyHead,并用三个指针p、q和curr分别指向l1、l2和新链表的尾部。然后,我们使用一个变量carry来记录进位值,并从头到尾遍历两个链表。在遍历过程中,我们首先获取当前节点的值
x和y,并计算它们的和以及进位值。然后,我们将和的个位数插入到新链表的尾部,并将carry更新为和的十位数。接着,我们移动指针p、q和curr到下一个节点。最后,如果还存在进位值,则将其作为新节点插入到新链表的尾部。
这样,我们就可以得到两个链表数字的相加结果了。
3.无重复字符的最长子串
难度(中等)
题目:给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
- 1
- 2
- 3
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
- 1
- 2
- 3
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
- 1
- 2
- 3
- 4
提示:
0 <= s.length <= 5 * 104s由英文字母、数字、符号和空格组成
class Solution { public int lengthOfLongestSubstring(String s) { Set<Character> set = new HashSet<>(); int n = s.length(); int ans=0,i=0,j=0; while(i<n && j<n){ if(!set.contains(s.charAt(j))){ set.add(s.charAt(j++)); //如果set集合中没有该字符,则添加到set集合中,并且将j指针右移一位 ans = Math.max(ans,j-i); }else{ set.remove(s.charAt(i++)); //否则, 将i指针所指的位置的元素移除后再右移一位 } } return ans; } } //区分i++和++i, 前者是先读到i后再自增一, 后者是先自增一再读到i
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这是一道典型的滑动窗口问题。我们可以维护一个窗口,使得窗口中的元素都不重复,并且记录下窗口大小的最大值。
具体实现方法如下:
- 定义两个指针 i 和 j,分别表示当前窗口的左右边界。
- 使用 HashSet 存储当前窗口中的元素,如果出现重复元素,则移动左指针,直到窗口中不含有重复元素。
- 每次移动窗口时,更新窗口大小的最大值。
除了使用 HashSet 来维护当前子串中的不重复字符集合之外,我们还可以使用一个数组来记录每个字符最后一次出现的位置。这样,在遍历字符串时,当遇到重复字符时,我们可以直接跳过该字符前面所有的元素,而无需逐一移动 left(或者i)指针。
以下是Java代码的实现:
Codepublic int lengthOfLongestSubstring(String s) { if (s == null || s.length() == 0) { return 0; } int n = s.length(); int maxLen = 0; int[] lastIndex = new int[256]; Arrays.fill(lastIndex, -1); int left = 0, right = 0; while (right < n) { char c = s.charAt(right); if (lastIndex[c] >= left) { left = lastIndex[c] + 1; } lastIndex[c] = right; maxLen = Math.max(maxLen, right - left + 1); right++; } return maxLen; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
该算法的时间复杂度仍然为O(n),其中n是字符串的长度。它使用了一个数组来存储每个字符最后一次出现的位置,并且用left和right指针表示当前子串的左右边界。算法通过移动right指针来扩展当前子串,同时在保持不重复的前提下尽可能地增加子串长度。当遇到重复字符时,通过移动left指针缩小子串范围以消除重复字符。在整个过程中,算法只需要对每个字符访问一次,因此时间复杂度为线性的。
与之前的算法相比,这个算法可以减少 HashSet 的使用和维护,从而进一步优化空间复杂度。
4.寻找两个正序数组的中位数
难度(困难)
题目:给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
- 1
- 2
- 3
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
- 1
- 2
- 3
提示:
nums1.length == mnums2.length == n0 <= m <= 10000 <= n <= 10001 <= m + n <= 2000-106 <= nums1[i], nums2[i] <= 106
解法思路:
这道题可以转化为求两个有序数组的第 k 小数。
首先,如果将两个数组合并成一个有序数组,那么中位数就是这个有序数组的中间数。但我们并不需要真正地将两个数组合并,而是模拟这个过程。
假设我们要找到第 k 小数,我们可以分别在两个数组中取出前 k/2 个数进行比较,设为 A 和 B。如果 A[k/2-1] < B[k/2-1],那么 A 中的前 k/2 个数都不可能是第 k 小数,因为即使把 A 中所有的这些数都加上,它们也不可能超过第 k 小数。因此,我们可以排除 A 数组中的前 k/2 个数,然后继续在剩余的 A 数组和 B 数组中查找第 k-k/2 小数。同理,如果 A[k/2-1] > B[k/2-1],那么我们可以排除 B 数组中的前 k/2 个数,然后继续在剩余的 A 数组和 B 数组中查找第 k-k/2 小数。
时间复杂度为 O(log(min(m,n))),其中 m 和 n 分别是两个数组的长度。
把数组最短的放前面, 找出第k小数,只需折半查找前面的数组即可找出中位数, 即第k小数。
class Solution { public double findMedianSortedArrays(int[] nums1, int[] nums2) { int m = nums1.length; int n = nums2.length; // 确保 nums1 的长度不大于 nums2 的长度 if (m > n) { //若nums1长度比num2长度大时,交换两个数组的内容 int[] temp = nums1; nums1 = nums2; nums2 = temp; // 交换两个数组的长度信息 int tmp = m; m = n; n = tmp; } // 初始化二分查找的上下限和中间点 int iMin = 0, iMax = m, halfLen = (m + n + 1) / 2; while (iMin <= iMax) { int i = (iMin + iMax) / 2; int j = halfLen - i; // 如果 i 值太小,则需要增加 i 的值 if (i < iMax && nums2[j-1] > nums1[i]){ iMin = i + 1; } // 如果 i 值太大,则需要减少 i 的值 else if (i > iMin && nums1[i-1] > nums2[j]) { iMax = i - 1; } else { // i 值恰当 // 计算左半部分的最大值 int maxLeft = 0; if (i == 0) { maxLeft = nums2[j-1]; } else if (j == 0) { maxLeft = nums1[i-1]; } else { maxLeft = Math.max(nums1[i-1], nums2[j-1]); } // 如果数组总共有奇数个元素,中位数就是左半部分的最大值 if ((m + n) % 2 == 1) { return maxLeft; } // 计算右半部分的最小值 int minRight = 0; if (i == m) { minRight = nums2[j]; } else if (j == n) { minRight = nums1[i]; } else { minRight = Math.min(nums2[j], nums1[i]); } // 如果数组总共有偶数个元素,中位数是左半部分的最大值和右半部分的最小值的平均值 return (maxLeft + minRight) / 2.0; } } return 0.0; // 没有找到中位数,返回 0.0 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
当我们需要在两个已排序的数组中寻找中位数时,可以使用二分查找算法。具体来说,我们可以通过对一个数组进行二分查找,确定其划分位置,然后根据划分位置得到另一个数组的划分位置,从而得到最终的中位数。
假设我们有两个已排序数组 nums1 和 nums2,它们的长度分别为 m 和 n。首先,我们需要确保 nums1 的长度不大于 nums2 的长度,因为这样可以确保左半部分的元素总是不少于右半部分的元素。接着,我们用二分查找在 nums1 中找到一个位置 i,将它作为划分位置,令 nums1[0] 到 nums1[i-1] 为左半部分,nums1[i] 到 nums1[m-1] 为右半部分。为了保证左半部分和右半部分分别包含 (m+n+1)/2 个元素,我们还需要对另一个数组 nums2 进行类似的划分,找到位置 j,并将 nums2[0] 到 nums2[j-1] 划分为左半部分,nums2[j] 到 nums2[n-1] 划分为右半部分。
那么中位数就是 maxLeft 和 minRight 的平均值,其中 maxLeft 表示左半部分的最大值,minRight 表示右半部分的最小值。如果数组总共有奇数个元素,则中位数就是 maxLeft;如果数组总共有偶数个元素,则中位数是 maxLeft 和 minRight 的平均值。因此,我们只需要在二分查找过程中计算出 maxLeft 和 minRight 即可得到最终的中位数。
在实现上,我们可以使用 while 循环来不断缩小 i 值的范围,直到找到恰当的划分位置。具体来说,我们用 iMin 和 iMax 来表示 i 的可能取值的下限和上限,然后对它们进行二分查找。在每次循环中,我们令 i = (iMin + iMax) / 2,并计算出 j = halfLen - i,其中 halfLen = (m + n + 1) / 2 表示左半部分和右半部分总共的元素个数。接着,我们比较 nums1[i] 和 nums2[j-1] 以及 nums1[i-1] 和 nums2[j] 的大小关系,根据比较结果调整 i 的取值范围,直到找到恰当的划分位置。
最后,如果没有找到中位数,则返回 0.0。
5.最长回文子串
难度(中等)
题目: 给你一个字符串 s,找到 s 中最长的回文子串。如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。
示例 1:
- 输入:s = “babad”
- 输出:“bab”
解释:“aba” 同样是符合题意的答案。
示例 2:
- 输入:s = “cbbd”
- 输出:“bb”
提示:
- 1 <= s.length <= 1000
- s 仅由数字和英文字母组成
使用动态规划来解决这个问题。
定义状态: d p [ i ] [ j ] dp[i][j] dp[i][j] 表示以 i i i开始,以 j j j结尾的子串是否为回文串。
状态转移方程:如果 s [ i ] = s [ j ] s[i]=s[j] s[i]=s[j] 且 d p [ i + 1 ] [ j − 1 ] = t r u e dp[i+1][j−1]=true dp[i+1][j−1]=true,则 d p [ i ] [ j ] = t r u e dp[i][j]=true dp[i][j]=true。
初始化:单个字符肯定是回文串,即 d p [ i ] [ i ] = t r u e dp[i][i]=true dp[i][i]=true。
最终找到最长的回文子串就是 s s s 中所有 d p [ i ] [ j ] = t r u e dp[i][j]=true dp[i][j]=true 的子串中长度最长者。
时间复杂度为 O ( n 2 ) O(n^2) O(n2),空间复杂度也是 O ( n 2 ) O(n^2) O(n2)。
方法一: 动态规划实现,以下是Java代码实现:
class Solution { public String longestPalindrome(String s) { int n = s.length(); boolean[][] dp = new boolean[n][n]; String res =""; for(int i = n-1; i>=0; i--){ for(int j=i; j<n; j++){ dp[i][j] = s.charAt(i) == s.charAt(j) && (j-i<2||dp[i+1][j-1]); if(dp[i][j]&&j-i+1>res.length()){ res = s.substring(i,j+1); //用于截取字符串中指定位置的子字符串,顾头不顾腚,截取i到j之间的字符 } } } return res; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
其中 dp[i][j] 表示 s 中从 i 到 j 是否为回文子串,初始化为 false。状态转移方程为:当 s[i] == s[j] 时,如果子串 s[i+1…j-1] 是回文子串,那么 s[i…j] 肯定也是回文子串。边界条件为单个字符肯定是回文子串。
最后在更新 dp 数组的同时记录最长的回文子串,返回即可。
方法二: 中心扩展算法
public String longestPalindrome(String s) { if (s == null || s.length() < 1) { return ""; } int start = 0; int end = 0; for (int i = 0; i < s.length(); i++) { int len1 = expandAroundCenter(s, i, i); int len2 = expandAroundCenter(s, i, i + 1); int len = Math.max(len1, len2); if (len > end - start) { start = i - (len - 1) / 2; end = i + len / 2; } } return s.substring(start, end + 1); } private int expandAroundCenter(String s, int left, int right) { int L = left; int R = right; while (L >= 0 && R < s.length() && s.charAt(L) == s.charAt(R)) { L--; R++; } return R - L - 1; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
该算法的时间复杂度为 O ( n 2 ) O(n^2) O(n2),其中 n n n 是字符串的长度。
- 首先检查输入字符串是否为空,如果为空,则返回空字符串。
- 初始化两个指针 start 和 end,用于记录当前最长回文子串的起始位置和结束位置。
- 对于字符串 s 的每个位置 i,分别以 i 为中心或者以 i 和 i+1 为中心进行回文扩展(调用 expandAroundCenter 方法)。其中,expandAroundCenter 方法会向左右两侧依次扩展,直到遇到不同字符为止,返回扩展的长度。
- 取两种扩展方式中的最大值 len,如果 len 大于当前最长回文子串的长度 end-start,则更新 start 和 end 的值。
- 最后,返回从 start 到 end 的子串,即为最长回文子串。
- expandAroundCenter 方法实现了向左右两侧扩展的逻辑。它接受三个参数:字符串 s、左右两个指针 left 和 right。在循环中,首先判断左右两侧的字符是否相等,如果相等则向左右两侧扩展;否则循环终止。返回扩展的长度 R-L-1。
与动态规划算法相比,这段代码的时间复杂度为 O ( n 2 ) O(n^2) O(n2),空间复杂度为 O ( 1 ) O(1) O(1)。而动态规划算法的时间复杂度也是 O ( n 2 ) O(n^2) O(n2),但空间复杂度为 O ( n 2 ) O(n^2) O(n2)。因此,这段代码在空间上更节省,并且常数项较小,实际运行速度可能会更快。
此外,这段代码的思路简单明了,易于理解和实现。动态规划算法对于初学者来说可能会比较难以理解,需要一定的数学知识作为基础。因此,如果只是为了解决求最长回文子串这个具体问题,使用这段代码实现更为方便。
方法三: 使用 Manacher 算法来优化时间复杂度,该算法的时间复杂度为 O ( n ) O(n) O(n),其中 n n n 是字符串的长度。
class Solution { public String longestPalindrome(String s) { if (s == null || s.length() < 1) { return ""; } StringBuilder sb = new StringBuilder(); for (int i = 0; i < s.length(); i++) { sb.append("#").append(s.charAt(i)); } sb.append("#"); String str = sb.toString(); int[] p = new int[str.length()]; int center = 0; int maxRight = 0; int maxLen = 0; int start = 0; for (int i = 1; i < str.length() - 1; i++) { if (i < maxRight) { p[i] = Math.min(maxRight - i, p[2 * center - i]); } // while (str.charAt(i + p[i] + 1) == str.charAt(i - p[i] - 1)) { // p[i]++; // } while (i + p[i] + 1 < str.length() && i - p[i] - 1 >= 0 && str.charAt(i + p[i] + 1) == str.charAt(i - p[i] - 1)) { p[i]++; } if (i + p[i] > maxRight) { center = i; maxRight = i + p[i]; } if (p[i] > maxLen) { maxLen = p[i]; start = (i - maxLen) / 2; } } return s.substring(start, start + maxLen); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
Manacher 算法,它是一个时间复杂度为 O(n) 的算法,比动态规划和中心扩展算法更快。下面是具体说明:
- 对于输入字符串 s,首先将每个字符之间都插入一个特殊符号(如 #),这样可以保证字符串长度为奇数,方便后续处理。
- 定义一个数组 p,用于记录以每个字符为中心的最长回文半径。
- 定义三个变量 center、maxRight 和 maxLen,分别表示当前已知的最长回文子串的中心位置、右边界位置和长度。同时,定义变量 start 用于记录最长回文子串的起始位置。
- 从左向右遍历字符串 str,对于每个字符 i,首先判断是否在已知最长回文子串的范围内。如果是,则利用对称性计算出以 i 为中心的回文半径;否则直接暴力扩展。
- 如果以 i 为中心的回文子串的右边界超过了已知最长回文子串的右边界,就更新中心位置和右边界。
- 每次更新完以 i 为中心的回文子串的信息,就更新最长回文子串的信息。
- 最后返回 s 中从起始位置 start 长度为 maxLen 的子串即可。
相较于中心扩展算法,Manacher 算法的时间复杂度更低,且较为简洁。这段代码实现了一个更优化的算法用于求解最长回文子串问题。

