
- 1AI绘画【Stable Diffusion】角色设计的福音!绘制一致性多角度头像_stable diffusion多视角
- 2VUE3注册指令的方法_vue3指令注册
- 3YOLO-V5 系列算法和代码解析(八)—— 模型移植_rk3566 yolov5
- 4用 python脚本 实现童年回忆植物大战僵尸_植物大战僵尸脚本
- 5MongoDB 覆盖索引查询:提升性能的完整指南
- 6【亲测有效】发现了适用于Mac用户的ChatGPT客户端登陆方法
- 7SqliSniper:针对HTTP Header的基于时间SQL盲注模糊测试工具
- 8《MetaGPT智能体开发入门》学习笔记 第五章 多智能体
- 9一网打尽:C++远程调试工具和策略全指南_电脑远程调试机器
- 10Git简单配置_克隆远程存储库时遇到错误: git failed with a fatal error. unabl
【计算机视觉】Segment Anything(SAM)项目整理汇总(更新到9月)_anything segmentation wechat
赞
踩
自从sam模型发布以来,基于sam的二次应用及衍生项目越来越多,将其应用于各种任务,比如图像修复( image inpainting)、图像编辑( image editing)、目标检测(objects detection)、图像标注(Image Caption)、视频跟踪(object tracking)、3d检测等等。
参考项目如下:
1. https://github.com/IDEA-Research/Grounded-Segment-Anything
2. https://github.com/MaybeShewill-CV/segment-anything-u-specify
3. https://github.com/Curt-Park/segment-anything-with-clip
4. https://github.com/fudan-zvg/Semantic-Segment-Anything
5. https://github.com/RockeyCoss/Prompt-Segment-Anything
6. https://github.com/liuyanyi/sam-with-mmdet
- 1
- 2
- 3
- 4
- 5
- 6
一、图像分割领域
1.1 集成文本模型,辅助检测
1.1.1 Grounded-Segment-Anything
计划通过结合 Grounding DINO 和 Segment Anything 来创建一个非常有趣的演示,旨在通过文本输入检测和分割任何内容!

[GroundingDINO]:通过文本进行检测

[Grounded-SAM]:通过文本提示,检测和分割一切,先通过文本得到检测box,然后将检测的box输入到sam,得到mask。
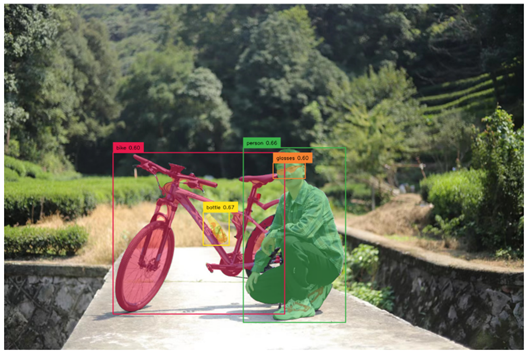
该项目背后的核心思想是结合不同模型的优势,构建一个非常强大的管道来解决复杂问题。 值得一提的是,这是一个组合强专家模型的工作流程,其中所有部件都可以单独或组合使用,并且可以替换为任何相似但不同的模型(例如用 GLIP 或其他探测器替换 Grounding DINO / 替换 Stable- 使用 ControlNet 或 GLIGEN 进行扩散/与 ChatGPT 结合)。

[Grounded-SAM]:图像编辑,将检测到的mask替换成其他

1.1.2 segment-anything-u-specify
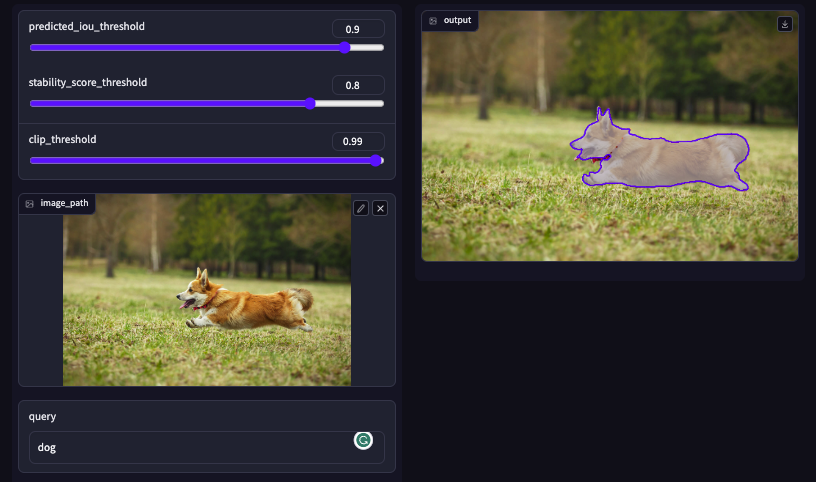
使用 SAM 和 CLIP 模型来分割我们想要的独特实例。 可以使用此存储库通过文本提示来分割图片中的任何实例。

我未曾部署成功!
1.1.3 Segment Anything with Clip
Meta 发布了一个新的分割任务基础模型。 它旨在通过即时工程解决下游分割任务,例如前景/背景点、边界框、掩模和自由格式文本。 不过,文字提示尚未发布。
或者,采取了以下步骤:
- 获取 SAM(Segment Anything Model)生成的所有对象提案。
- 通过边界框裁剪对象区域。
- 从 CLIP 获取裁剪图像的特征和查询特征。
- 计算图像特征与查询特征之间的相似度。
1.2 分割结果增加标签
1.2.1 Semantic-Segment-Anything
SAM 是用于任意对象分割的强大模型,而 SA-1B 是迄今为止最大的分割数据集。 然而,SAM 缺乏预测每个掩码语义类别的能力。 (I) 为了解决上述限制,我们在 SAM 之上提出了一个管道来预测每个掩码的语义类别,称为语义分段任意 (SSA)。 (II) 此外,我们的 SSA 可以作为一个自动化的密集开放词汇注释引擎,称为语义分段任何标签引擎(SSA-engine),为 SA-1B 或任何其他数据集提供丰富的语义类别注释。 该引擎显着减少了手动注释的需求和相关成本。
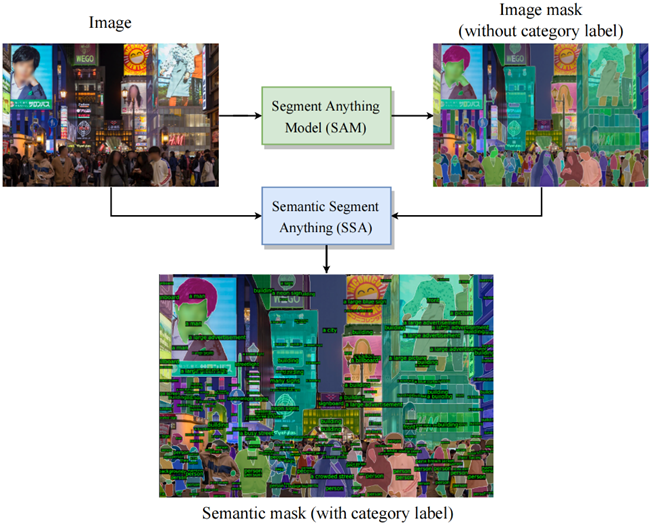
工程有什么用?
- SAM 是一种高度通用的对象分割算法,可以提供精确的掩模。 SA-1B 是迄今为止最大的图像分割数据集,提供精细的掩模分割注释。 SAM 和 SA-1B 都不提供每个掩模的类别预测或注释。 这使得研究人员很难使用强大的 SAM 算法直接解决语义分割任务或利用 SA-1B 来训练自己的模型。
- 先进的闭集分割器(如 Segformer、Oneformer)、开放集分割器(如 CLIPSeg)以及图像字幕方法(如 BLIP)可以提供丰富的语义注释。 然而,它们的掩模分割预测可能不如 SAM 生成的那样全面和准确,后者具有高度精确和详细的边界。
- 因此,通过将 SAM 和 SA-1B 的精细图像分割掩模与这些先进模型提供的丰富语义注释相结合,我们可以生成具有更强泛化能力的语义分割模型,以及大规模的密集分类图像分割数据集。
项目可以做什么?
- SSA:这是第一个利用 SAM 进行语义分割任务的开放框架。 它支持用户将现有的语义分割器与 SAM 无缝集成,而无需重新训练或微调 SAM 的权重,从而使他们能够实现更好的泛化和更精确的掩模边界。
- SSA-engine:SSA-engine为大规模SA-1B数据集提供密集的开放词汇类别注释。 经过人工审核和细化后,这些注释可用于训练分割模型或细粒度 CLIP 模型。
SSA: Semantic segment anything
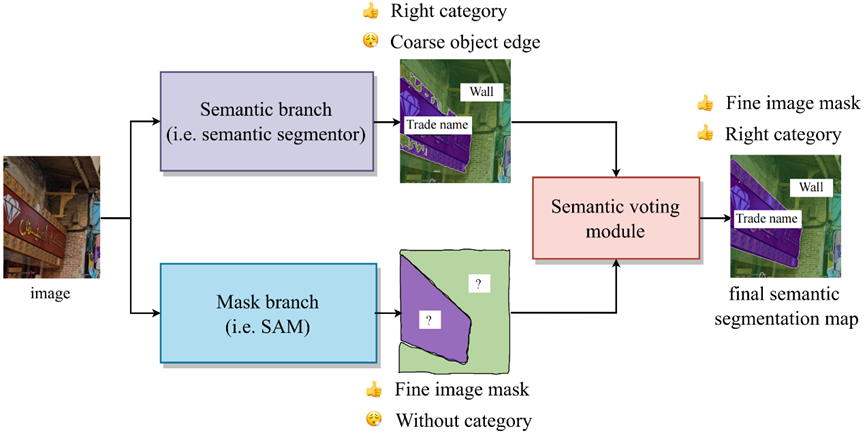
在SAM引入之前,大多数语义分割应用场景已经有了自己的模型。这些模型可以为区域提供粗略的类别分类,但边缘模糊且不精确,缺乏准确的掩模。为了解决这个问题,我们提出了一个名为 SSA 的开放框架,它利用 SAM 来增强现有模型的性能。 具体来说,原始的语义分割模型提供类别预测,而强大的 SAM 提供掩模。
值得注意的是,SSA适用于原始分割器预测的掩模边界精度不高的场景。 如果原始模型的分割已经非常准确,SSA 可能不会提供显着的改进。
SSA 由两个分支组成:Mask 分支和 Semantic 分支,以及一个确定每个 mask 类别的投票模块。
Mask分支(蓝色)。SAM作为Mask分支,提供一组边界清晰的mask。
语义分支(紫色)。该分支为每个像素提供类别,该类别由语义分割器实现,用户可以根据分割器的架构和感兴趣的类别进行自定义。 分割器不需要有非常详细的边界,但它应该尽可能准确地对每个区域进行分类。
语义投票模块(红色)。该模块根据掩模的位置裁剪出相应的像素类别。 这些像素类别中的 top-1 类别被视为该掩模的分类结果。
SSA-engine: Semantic segment anything labeling engine
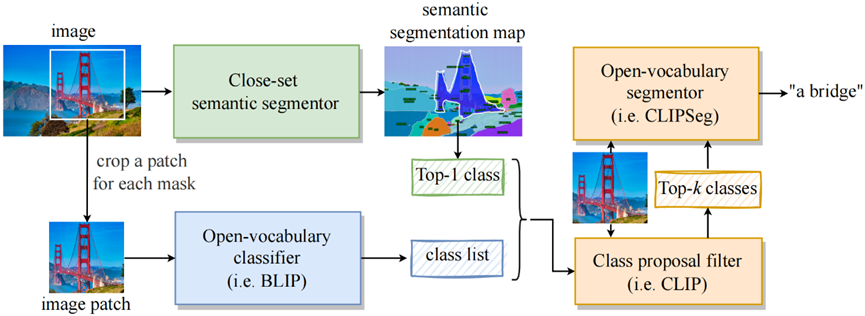
SSA-engine 是一个自动注释引擎,用作 SA-1B 数据集的初始语义标签。 虽然可能需要人工审查和细化才能获得更准确的标签。 由于闭集分割和开放词汇分割的组合架构,SSA-engine 为大多数样本提供了令人满意的标记,并且能够使用图像描述方法提供更详细的注释。
该工具填补了 SA-1B 有限的细粒度语义标记的空白,同时还显着减少了手动注释的需求和相关成本。 它有潜力作为训练大规模视觉感知模型和更细粒度的 CLIP 模型的基础。
SSA 引擎由三个组件组成:
近集语义分割器(绿色)。 使用分别在COCO和ADE20K数据集上训练的两个闭集语义分割模型来分割图像并获得粗略的类别信息。 预测类别仅包括简单和基本类别,以确保每个掩模都收到相关标签。
(II)开放词汇分类器(蓝色)。 利用图像字幕模型来描述与每个掩模相对应的裁剪后的图像块。 然后提取名词或短语作为候选开放词汇类别。 这个过程提供了更加多样化的类别标签。
(III)最终决策模块(橙色)。 SSA引擎使用类提议过滤器(即CLIP)从混合类列表中过滤出前k个最合理的预测。 最后,开放词汇分割器根据前 k 个类别和图像块预测掩模区域内最合适的类别。
示例如下:

1.3 辅助instance segmentation
1.3.1 Prompt-Segment-Anything
这是使用 Segment Anything 的零样本实例分割的实现。该存储库基于 MMDetection,并包含来自 H-Deformable-DETR 和 FocalNet-DINO 的一些代码。
集成检测模型,先用检测模型得到label和box,然后用box作为prompt,得到instance的mask。
示例如下:

二、目标检测
如上文介绍,可以结构 CLIP 和 SAM 进行目标检测,此处不再重复。
2.1 目标检测instance
2.1.1 sam-with-mmdet
A simple demo for SAM+MMDetection
利用预训练的rtmdet,和sam融合得到box内的instance mask。


