
- 1热门不再!科技大厂放缓招聘,美国计算机专业学生求职四处碰壁
- 2Vue中实现文字向上滚动的动画效果_vue文字向上循环滚动
- 3【心电信号ECG】基于Butterworth带通滤波器实现心电信号分析去噪、提取R周期、峰值及信号的幅频、相频和功率谱特征参数附Matlab代码_心电图ecg常用滤波器
- 4计算机大三学生怎么找实习工作?学了计算机很迷茫怎么办?_大三计算机怎么找实习
- 5QT上位机串口+STM32单片机项目_qt stm32
- 6VS2022+QT5环境搭建_vs2022 qt5
- 7【LSTM时间序列预测】麻雀算法优化LSTM时间序列预测(含前后对比)【含Matlab源码 2029期】
- 8The cached zip file gradle-5.6.4-all.zip may be corrupted. Delete file and sync project
- 9com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException解决
- 10支付宝H5嵌入APP内部支付_app内嵌h5支付宝支付功能
Python和MySQL对比(1):用Pandas 实现MySQL语法效果_pandas和mysql的处理对比
赞
踩
一、前言
本文主要介绍 MySQL 中的关键字:SELECT、AS、WHERE、DISTINCT、GROUP BY、ORDER BY、HAVING、LIMIT等的查询语句,如何使用pandas实现,同时二者又有什么区别。
注:Python是很灵活的语言,达成同一个目标或有多种途径,我提供的只是其中一种解决方法,大家有其他的方法也欢迎留言讨论。
二、语法对比
数据表
本次使用的数据结构如下: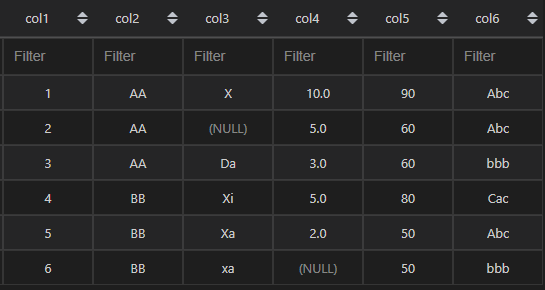
共6列6行,col3和col4各有一个null值。
使用 Python 构建该数据集的语法如下:
import pandas as pd
import numpy as np
df1 = pd.DataFrame({ 'col1' : list(range(1,7))
,'col2' : ['AA','AA','AA','BB','BB','BB']#list('AABCA')
,'col3' : ['X',np.nan,'Da','Xi','Xa','xa']
,'col4' : [10,5,3,5,2,None]
,'col5' : [90,60,60,80,50,50]
,'col6' : ['Abc','Abc','bbb','Cac','Abc','bbb']
})
df1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注:直接将代码放 jupyter 的 cell 跑即可。后文都直接使用
df1调用 Python 的数据
使用 MySQL 构建该数据集的语法如下:
with t1 as(
select 1 as col1, 'AA' as col2, 'X' as col3, 10.0 as col4, 90 as col5, 'Abc' as col6 union all
select 2 as col1, 'AA' as col2, null as col3, 5.0 as col4, 60 as col5, 'Abc' as col6 union all
select 3 as col1, 'AA' as col2, 'Da' as col3, 3.0 as col4, 60 as col5, 'bbb' as col6 union all
select 4 as col1, 'BB' as col2, 'Xi' as col3, 5.0 as col4, 80 as col5, 'Cac' as col6 union all
select 5 as col1, 'BB' as col2, 'Xa' as col3, 2.0 as col4, 50 as col5, 'Abc' as col6 union all
select 6 as col1, 'BB' as col2, 'xa' as col3, null as col4, 50 as col5, 'bbb' as col6
)
select * from t1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注:直接将代码放 MySQL 代码运行框跑即可。后文跑 SQL 代码时,默认带上数据集(代码的1~8行),仅展示查询语句,如第9行。
SELECT
检索数据,一般分三种情况,检索所有列的数据、检索单个列的数据和检索多个列的数据,下面分这三种情况来看看二者的呈现结果。
1、检索所有列
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1 | select * from t1; |
| 结果 | 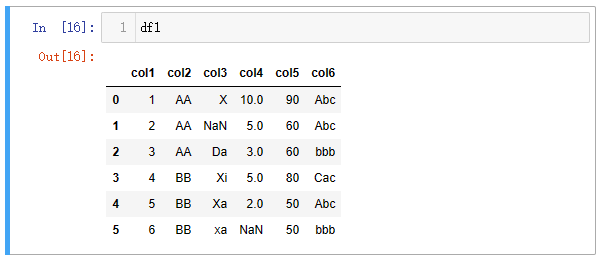 | 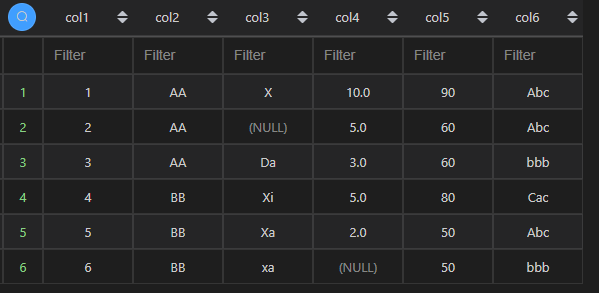 |
2、检索单个列
注意df1[['col2']]返回的是一个 DataFrame 类型,而其他两个是 Series。从 Series 转化为 DataFrame 也可以使用 to_frame()方法,比如:df1.col2.to_frame(),如果需要修改转化后的列名,可以直接把新的名字以字符串形式传递给to_frame(),如df1.col2.to_frame('new_name')。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.col2 或 df1[‘col2’]或df1[[‘col2’]] | select col2 from t1; |
| 结果 | 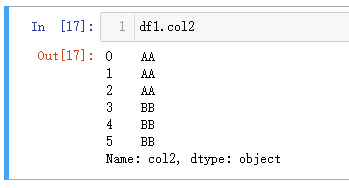 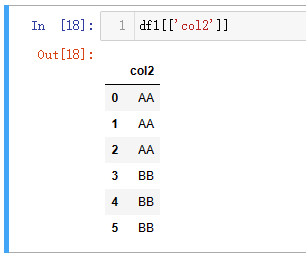 | 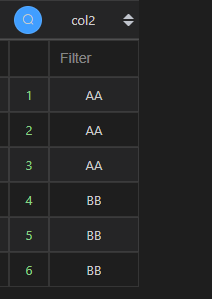 |
3、检索多个列
当检索更多列时,直接在 Python 代码的col3后新增列名即可。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[[‘col2’, ‘col3’]]或df1.loc[:,[‘col2’, ‘col3’]] | select col2,col3 from t1; |
| 结果 |  | 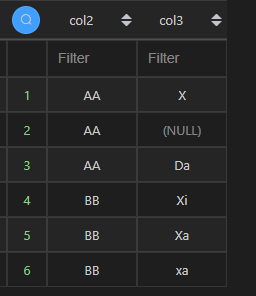 |
AS
命别名,这也是一个比较常用的语法。名别名主要有两种形式,一个是对字段名取别名,一个是对表名取别名。字段名一般会有两种情况:一是原有字段重命名,一是新生成的字段重命名。
1、字段名-原有字段重命名
对已知的字段命别名,Python 中使用rename()方法,给columns参数传递一个字典,把需要重新命名的字段全部以键值对的形式放到字典中。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[[‘col1’, ‘col2’]].rename(columns={‘col1’:‘index’,‘col2’:‘name’}) | select col1 as index,col2 as name from t1; |
| 结果 | 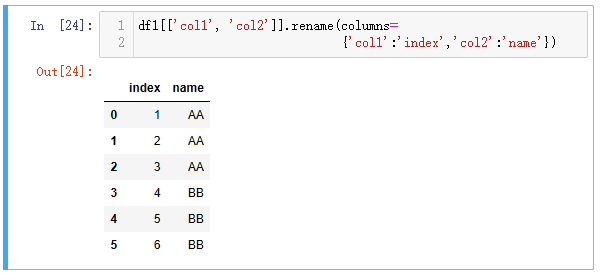 | 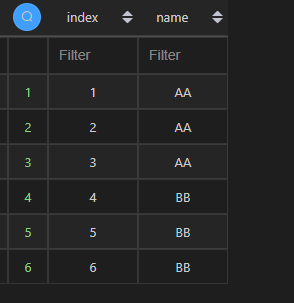 |
2、字段名-生成字段重命名
在 MySQL 中,一气呵成。但是在 Python 需要先显式新增一列,然后再查询出对应的数据。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[‘col7’]=df1.col5*df1.col4 df1[[‘col2’,‘col7’]] | select col2,col5*col4 as col7 from t1; |
| 结果 | 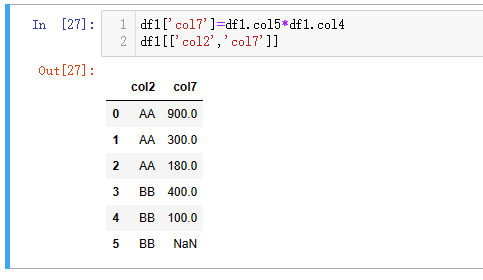 | 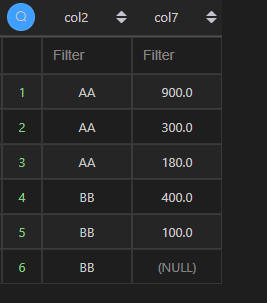 |
3、表名名别名
表是否名别人,从数据上看不出来,此处省略结果。
Python 给表命别名,其实就是再新增一个变量,把数据赋值给它。新旧变量本质不是同一个,但数据内容一致,在处理数据层面没有太大差异。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | t2 = df1[:] t2 | select * from t1 as t2; |
| 结果 | - | - |
WHERE
WHERE 的内容相对比较多一些,分单条件、多条件,也分检索单列、多列、所有列,单列比较简单,可以从多列窥探一二,故省略。
1、单条件,所有列
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[df1.col2==“AA”] | select * from t1 where col2 = ‘AA’; |
| 结果 | 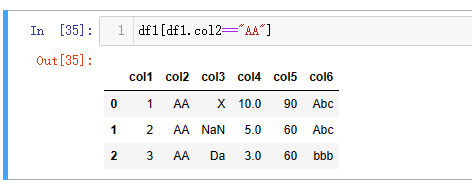 | 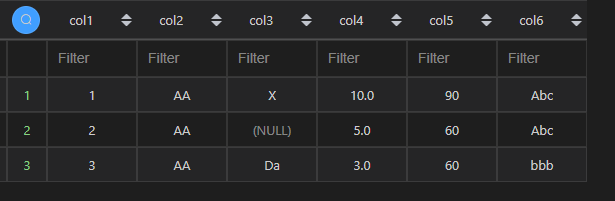 |
2、多条件,所有列
注意:多个条件时,每个条件加括号,然后用符号链接,and 为 &,or 为 | 。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[(df1[‘col2’]==‘AA’) & (df1[‘col4’]==5)] | select * from t1 where col2 = ‘AA’ and col4 = 5; |
| 结果 |  | 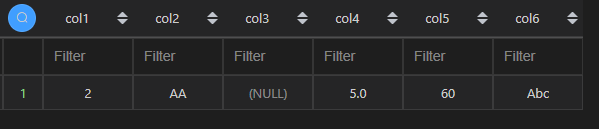 |
3、单条件,多列
该例子中,两种 Python 的实现方式都可以。第一种df1[df1.col2=='AA'][['col1','col2']]是先where,再select;第二种df1[['col1','col2']][df1.col2=='AA']是先select,再where。虽然顺序不一样,但是殊途同归。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[df1.col2==‘AA’][[‘col1’,‘col2’]] df1[[‘col1’,‘col2’]][df1.col2==‘AA’] | select col1,col2 from t1 where col2 = ‘AA’; |
| 结果 | 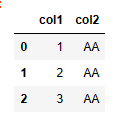 | 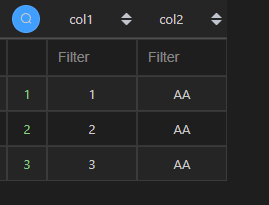 |
4、多条件,多列
Python 的两种实现方法和3、单条件,多列类似。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[(df1[‘col2’]==‘AA’) & (df1[‘col4’]5)][[‘col1’, ‘col2’]] df1[[‘col1’, ‘col2’]][(df1[‘col2’]‘AA’) & (df1[‘col4’]==5)] | select col1, col2 from t1 where col2=‘AA’ and col4=5; |
| 结果 |  | 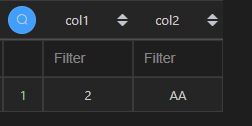 |
5、带有null值的条件
除了前面3或4介绍的两种方法,还可以使用loc方法,具体如下例子。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[df1[‘col3’].isnull()][[‘col1’,‘col3’]] df1[[‘col1’,‘col3’]][df1[‘col3’].isnull()] df1.loc[df1[‘col3’].isnull(), [‘col1’,‘col3’]] df1[[‘col1’,‘col3’]][df1[‘col3’].isnull()] | select col1,col3 from t1 where col3 is null; |
| 结果 |  | 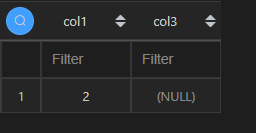 |
DISTINCT
去重主要分单列去重和多列去重。
1、单列去重
Python 中,取唯一值可以使用unique()方法,不过该方法仅作用于 Series,而且返回的是数组,如果要使得结果是 Series,需要进行显式转化。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | pd.Series(df1.col2.unique()) | select distinct col2 from t1; |
| 结果 | 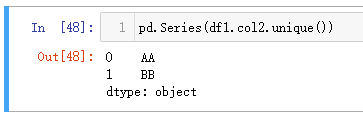 | 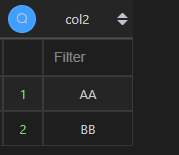 |
2、多列去重
Python 中,unique()仅作用于 Series,当涉及多列去重时,使用的是 DataFrame,这时unique()便不再适用。
通过drop_duplicates()方法可以实现多列去重。df1[['col2','col5']].drop_duplicates()不指定去重列,默认全部列一起去重;而向drop_duplicates()传递一个列表参数,可以对指定的列进行去重,如:df1[['col2','col5']].drop_duplicates(["col2","col5"])。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[[‘col2’,‘col5’]].drop_duplicates() 或 df1[[‘col2’,‘col5’]].drop_duplicates([“col2”,“col5”]) | select distinct col2,col5 from t1; |
| 结果 | 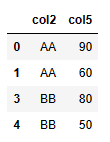 | 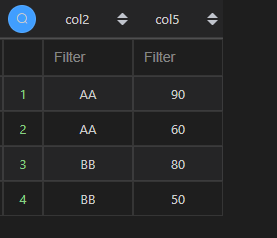 |
GROUP BY
聚合主要有3种情况:没有GROUP BY,直接聚合、指定单列聚合、指定多列聚合。
1、直接聚合-计数
直接统计行数,在 Python 的DataFrame 类型中,可以直接通过shape获取到。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.shape[0] | select count(*) from t1; |
| 结果 | 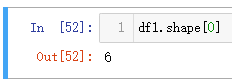 | 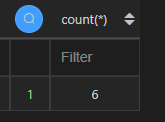 |
2、直接聚合-去重计数
去重计数,需要对重复列先去重,保留唯一值,然后再计数。这里使用到duplicated()方法,它可以判断指定的列是否重复,然后返回一个掩码。由于返回的掩码是判断是否重复,实际应用,我们需要的是没有重复,所以需要反向取值,加一个~。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[~df1.duplicated(‘col2’)].shape[0] df1[~df1.col2.duplicated()].shape[0] | select count(distinct col2) from t1; |
| 结果 |   | 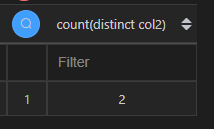 |
3、直接聚合-多个聚合字段
在 Python 中,多个聚合字段需要使用到agg()方法。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.agg({‘col5’: [‘min’, ‘max’, ‘mean’,‘sum’]}).T | select max(col5), min(col5), avg(col5),sum(col5) from t1; |
| 结果 | 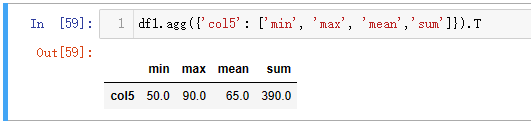 | 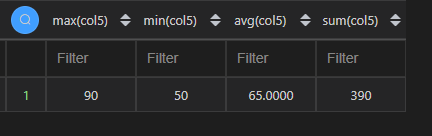 |
4、指定一列聚合
Python 可通过groupby指定聚合列进行聚合操作。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.groupby([‘col2’])[‘col5’].sum().reset_index() | select col2, sum(col5) from t1 group by col2; |
| 结果 | 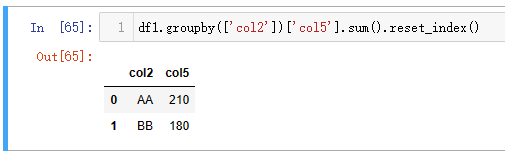 | 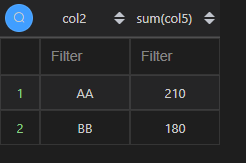 |
5、指定多列聚合
Python 在使用groupby进行聚合的时候,需要注意保证被指定的列都无null值,以便最终聚合结果正确。
保险起见,每次建议都加一步填充,再进行聚合。
size()语法是对数据进行计数。reset_index()则是重置所以。
注意:在本例中,返回的结果是有差异的,MySQL 把col3的Xa和xa视为一类,而 Python 中则视为不同的两类。所以返回结果有出入。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.fillna(999).groupby([‘col2’, ‘col3’]).size().reset_index() | select col2,col3,count(*) from t1 group by col2,col3; |
| 结果 | 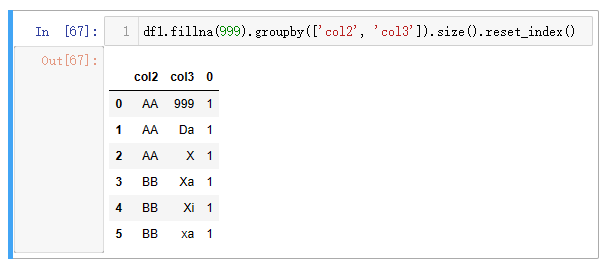 | 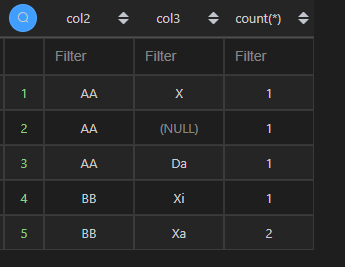 |
ORDER BY
1、单列升序
从执行结果看,我们可以发现,在升序排序前提下,Python 中 NaN 值是排在最后,而且先排大写,再排小写;而 MySQL 的 NULL 值排在第一位,大小写视为一类。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.col3.sort_values() | select col3 from t1 order by col3; |
| 结果 |  | 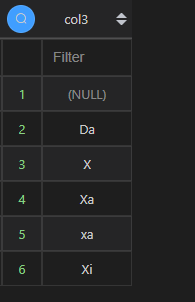 |
2、单列降序
MySQL 的降序,直接在字段后加上DESC即可,而 Python 则需要通过 ascending参数。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[[‘col2’,‘col3’]].sort_values(by=[‘col3’],ascending=False) | select col2,col3 from t1 order by col3 desc; |
| 结果 | 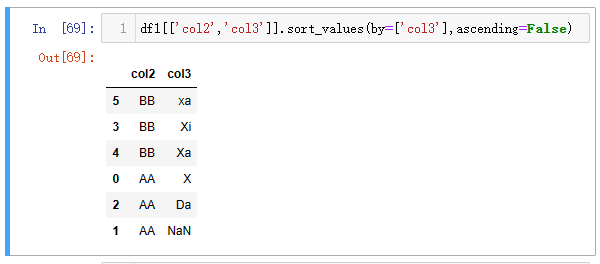 | 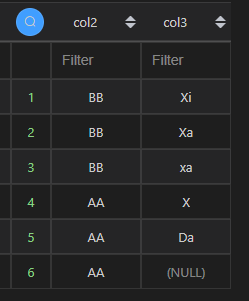 |
3、多列混序
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[[‘col2’,‘col3’]].sort_values([‘col2’,‘col3’],ascending=[True,False]) | select col2,col3 from t1 order by col2,col3 DESC; |
| 结果 |  | 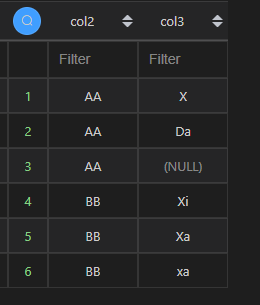 |
HAVING
该案例比较复杂,具体含义是取col5大于等于60的值,按col2聚合,并筛选出聚合个数超过1的行,同时对聚合个数进行降序排序,最终返回col2列和聚合的个数。
Python 的实现先提取所有的符合having的数据,然后再一步groupby聚合。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1[df1.col5>=60].groupby(‘col2’).filter(lambda x:len(x)>1).groupby(‘col2’).size().sort_values(ascending=False) | select col2, count() from t1 where col5 >=60 group by col2 having count() > 1 order by count(*) desc; |
| 结果 | 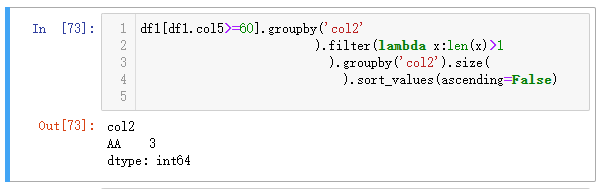 | 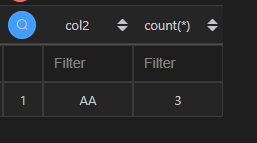 |
LIMIT
MySQL 的 limit 相当于 Python 的head()或切片。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.head(2)或 df1[0:2] | select * from t1 limit 2; |
| 结果 | 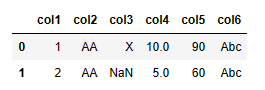 | 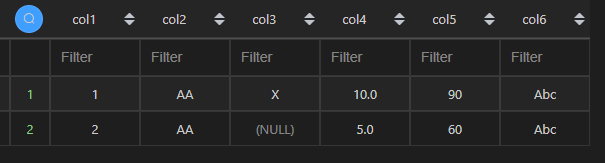 |
结合ORDER BY进行定向取值的时候,在 Python 中可以使用nlargest()方法或nsmallest()方法辅助取值。nlargest()方法是从大到小的降序逻辑,nsmallest()方法则反过来。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1.nlargest(3, columns=‘col5’)[[‘col2’,‘col5’]] | select col2,col5 from t1 order by col5 desc limit 3; |
| 结果 | 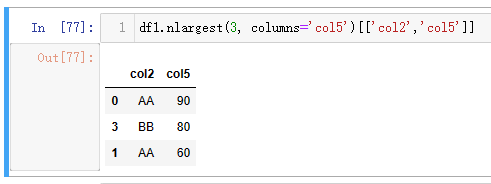 | 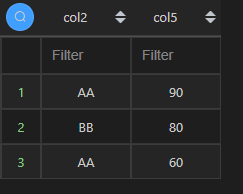 |
补充一点,由于数据量小,所以LIMIT返回的数据看不出什么差异,实际上,当表单数据较大时,MySQL 的查询会随机返回数据,而 Python 不会。
三、小结
作为一门开发语言,Python 的灵活性是很强的,基本上MySQL的语法都可以在 Python 中实现。当然,局部也有一些内容会有一些出入,比如在ORDER BY语法中就有排序上的差异,但是不影响大方向的使用。关于排序这点也可以通过自定义排序设置不区分大小写以及 null 值的顺序,不过似乎没有这个必要,即使同为SQL的其他语言,也和MySQL有一定的差异,比如 PgSQL 的 null 值排序和 MySQL 就是反着来的。


