
- 1简述为什么数据要进行标准化和scale函数的应用_为什么尺度函数要标准化
- 2八大排序、时间复杂度空间复杂度_八大空间时间
- 3YOLOv10改进 | 注意力篇 | YOLOv10引入iRMB
- 4Python 报错 ‘UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xad in position 123: illegal multibyt’_unicodedecodeerror: 'gbk' codec can't decode byte
- 5Git 是什么?5分钟入门Git_git文件是个?是什么意思
- 6Hadoop学习笔记—1.基本介绍与环境配置_宿主机windows中浏览 datanode
- 7AttributeError: ‘NoneType‘ object has no attribute ‘xxx‘v_nonetype' object has no attribute
- 8大数据创业的未来到底如何?
- 9揭示数据库内核的奥秘--手写数据库toadb开源项目
- 10机器学习Python代码实战(一)线性回归算法
ICLR2022《UNIFORMER: UNIFIED TRANSFORMER FOR EFFICIENT SPATIOTEMPORAL REPRESENTATION LEARNING》_uniformerv2论文学习
赞
踩

论文下载链接:https://arxiv.org/pdf/2201.04676.pdf
代码链接:https://github.com/Sense-X/UniFormer
1. 动机
高维视频具有大量的局部冗余和复杂的全局依赖关系,而该研究主要是由3D卷积神经网络和视觉Transformer驱动。3D卷积虽然能抑制局部冗余,但由于接受域有限,它缺乏捕获全局依赖的能力;视觉Transformer在self-attention的帮助下擅长捕捉全局依赖,但由于各层token之间存在盲目相似性比较,限制了减少局部冗余。
2. 方法

为了克服时空冗余和依赖的问题,本文提出Unified transFormer (UniFormer)框架,如上图所示。每个UniFormer block主要由三部分组成:Dynamic Position Embedding (DPE), Multi-Head Relation Aggregator (MHRA), 和Feed-Forward Network (FFN)。最核心是MHRA和DPE的设计:
- MHRA
如上所述,问题是要解决大的局部冗余和复杂的全局依赖,以实现高效和有效的时空表示学习。不幸的是,流行的3D cnn和时空Transformer只关注这两个挑战中的一个。因此,这里设计了一个Relation Aggregator (RA),其可以将3D卷积和时空self-attention灵活地统一在一个简洁的transformer块中,分别解决了浅层和深层的视频冗余和依赖。具体地,具体来说,MHRA通过multi-head融合进行token关系学习(RA的关键是如何在视频中学习 A n A_n An):
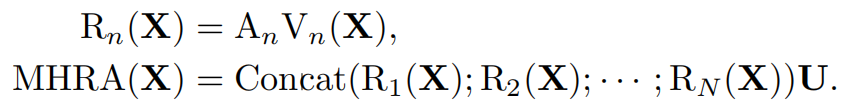
Local MHRA: (stage1和stage2中使用)在浅层中,目标是学习小三维社区中局部时空背景下的详细视频表示。这与3D卷积滤波器的设计有着相似的见解。我们将token affinity设计为一个在局部3D邻域中操作的可学习的参数矩阵(这个与local self-attention设计很像),其值仅取决于token之间的相对3D位置.
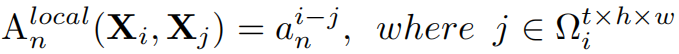
Global MHRA: (在stage3和stage4中使用)在深层,关注于在全局视频片段中捕获long-term token依赖关系。这自然与self-attention的设计有着相似的见解。
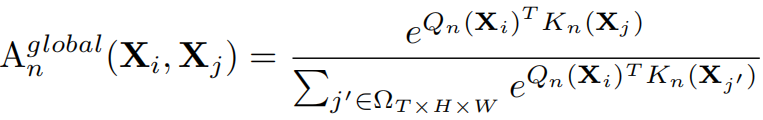
- DPE
扩展了conditional position encoding (CPE)设计的(DWConv是指简单的零填充的3D depth convolution)
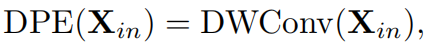
3. 部分实验结果
实验主要在两个数据集中进行:widely-used Kinetics-400,Kinetics-600。在数据集Something-Something V1&V2进行迁移学习的验证。
1) 与 Convolution+Transformer网络对比

2)与SOTA方法对比


3)消融实验
UniFormer vs. Convolution: Does transformer-style FFN help?和How much does local MHRA help?(如下图a)

UniFormer vs. Transformer: Is joint or divided spatiotemporal attention better?和Is our UniFormer more transferable?(如上图a和下图c)

Does dynamic position embedding matter to UniFormer?
通过动态位置嵌入,在ImageNet和Kinetics-400上,UniFormer将top-1精度提高0.5%和1.7%。
4)ImageNet数据集上SOTA方法对比

写这篇博客仅是为了方便自己,有任何表述不正确的,请大家多多指教O(∩_∩)O

