
- 1Docker 配置阿里云镜像加速器_配置阿里云镜像加速报错 --containerd=/run/containerd/container
- 2【解决】IntelliJ IDEA 重命名 Shift + F6 失效
- 3Windows环境Docker安装_windows搭建docker环境
- 4Ubuntu18.04LTS下CentOS7启动后桌面显示主文件夹内文件解决措施_centos7进入桌面后只能看到系统盘
- 5Harbor基于docker-compose部署【亲测有效】_harbor2.3.3 docker-compose2.20 高版本
- 6【Android】非线性方程的求解寻根
- 7STM32能够做到数据采集和发送同时进行吗?
- 8网络协议与攻击模拟_13缓存DNS与DNS报文
- 9私有依赖的打包与上传_npm 组件生成 tgz文件
- 10Tool-X 工具汇总
深度学习目标检测系列之YOLO9000_yolov9
赞
踩
1.闲言
在正式的学习之前,我喜欢先放飞一下自我。我觉得技术就是用来聊的,找个酒馆,找些大神,咱们听着音乐一起聊起来。所以我特别希望能把自己的文字口语化,就像玩一样。就像古代那些说书人一样,萧远山和慕容博相视一笑,王图霸业,血海深仇,尽归尘土。这是我向往的一种表达方式,但是我现在还达不到那个境界,只能尽力而为吧。
2.YOLOV2
1.十个改造点
yolov1提升了目标检测的速度,但是在MAP方面却掉了上去。所以说铁打的大神,流水的模型,他们自然会想尽各种办法来解决这个问题。在我看来这就好像程序员写bug一样,到头来总是要改的。所以yolov2可以分为两个部分,第一部分是对MAP提升所做的努力,第二部分是对原来模型的优化,当然是在保证检测速度的前提下。
下面的10个点,是V2的大神们做出的努力。这意味着什么,速度的提升?准确率的提升?模型的泛化能力提升?对,但是更重要的我觉得是工作量的体现,年终的结算。有时候看paper的时候,我们觉得这些大神们都跟圣人一样。他们做出的所有努力都是要造福社会,都是为了推动AI视觉的进一步发展。其实他们也是人,也会有来自各方面的限制,也会有自己的私心,一些小小的任性和种种生而为人而不能的无奈。所以读paper就是在和大神们对话,一边说着你真牛逼,一边在心里面想着我一定要超越你。

下来我们来解释一下,如果说模型预测出来的结果不是很令人满意,那么一般从下面三个方面寻找原因:数据、模型、训练策略。如果还不行,那么就再仔细找找!
1. 数据
1)batch norm:数据经过卷积处理之后,其均值和分布情况会发生变化,我们使用这种方式把中间层的数据拉回到跟原始数据差不多的同分布。说白了就是让数据别跑偏太严重。
2.模型
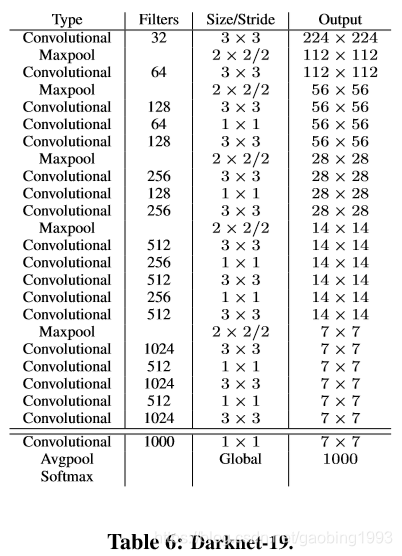
1)convolutional 使用全卷积网络,将yolov1中的后两层全连接去掉,换成卷积。全卷积有好处就是输入可以是任意的。
2)new network 设计了轻量级的darknet19网络,很大的减少了计算量和参数,并且提高了0.4个百分点精度。
3)anchor boxes 借鉴faster的anchor概念,加入了先验框的概念,每个cell预测 出5个框。
4)passthrough 将最后一个池化层之前的特征图26*26和最后的特征13*13进行concat拼接,一起用来进行最终的检测。这里有点FPN的 思想,因为浅层信息会携带更多的形状信息,并且更适合检测小物体;深层特征携带更多的语义信息,适合检测大的物体。融合之后模型可以提高对于小物体的预测能力。
3.训练策略
1)hi-res classifier:高分辨率分类器,把imagenet的224*224图片转换为448*448进行十个轮次的预训练。相比于yolov1的直接在224上进行训练,然后在448上进行提取特征。这样模型的分类能力会得到提高。
2)dimension priors 跟faster中手动定义先验框的尺寸和比例不同的是,yolov2在训练之前使用k-means对数据进行聚类,使用1-IOU来计算框与框之间的距离,聚类后的簇心框的宽高作为先验框的宽高。
3)location prediction 跟faster中不同的是 yolov2预测框的x、y是相对于cell左上角的偏移量,并且为了预测框中心点 超出cell,对其进行了sigmoid归一处理。因为faster的预测方式会导致模型的不稳定,特别是在开始的几个轮次,可能是中心点经常会超出预测框中心点的位置

4)multi-scale 多尺寸的训练,每个10个轮次就随机更换输入图片的尺寸(这就是全卷积的豪横之处吧),尺寸从320,352,...,608,均为32的倍数。因为输入图像的尺寸和主干网络卷积层的 输出是32倍下采样的关系。这样训练出来的模型,泛化能力更强,对比不同尺寸图像的预测会更准确。
5)hi-res detector 最后这点的话更多像是一个副产品,对于高分辨率图片预测的更准确,因为训练的时候是在高分辨率进行的,所以高分辨率就预测的越准。并且对于高分辨率图片来说,其本身的解释性就很强,语义信息更丰富。
3.yolo9000
为什么起这么豪横的名字,给人的感觉像yolo已经进化了好久似的。这里的9000表示yolo可以准确的预测出9000种类别。如何做到的呢?我们都知道用来分类的imagenet数据集,共有14197122幅图像,总共分为21841个类别;用来检测的数据集标记的工作量更大一些,所以数据集中图片数量和分类数量都会较少些。例如coco数据集中大概有33万张图片,80分类。
从本质上来说目标框的预测和分类任务是两个不同的任务,所以我们可以尝试着使用分类数据集来进行分类,使用检测数据集来进行检测+分类(因为检测数据集中肯定是有类别信息的)。这样的话模型可以对更多种类的物体图片进行打框,标记。
理想很丰满,如何实现呢?我们使用损失的反向传播来进行控制,说的太高大上了,其实就是当分类的数据集进来的时候,只有分类的损失会参与反向调节。
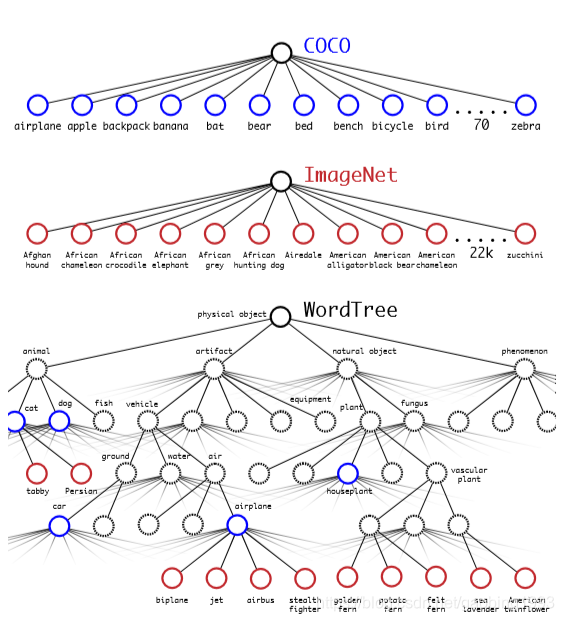
但是还有一个问题就是,两个数据集中有一些类别信息并不是相互独立的。比如猫和加菲猫,加菲猫也属于猫的一种。这是一件大事,因为深度学习对于数据的假设就是相互独立,这可怎么搞。然后大神就找到了一棵树,你看果然伟大的事情都和树有关。wordtree,如下图所示,所有的类别信息被使用树形的结构连接了起来,每一个子节点到根节点的路径都是唯一的。这个唯一性就 消除了猫和加菲猫的重复性带来的困扰。我们的游戏可以继续了,预测的时候每一个节点对应的概率输出,等于其所在路径所有节点的输出之积。简直完美!
4.性能
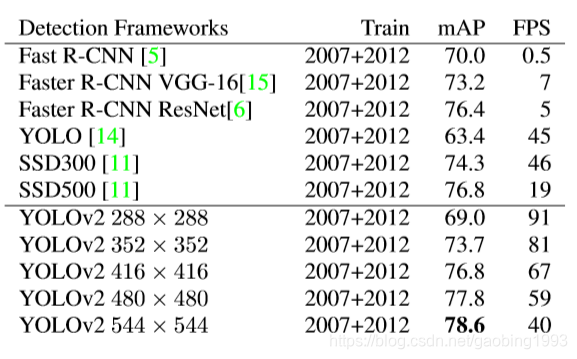
1.VOC2007
2.VOC2012

3.coco
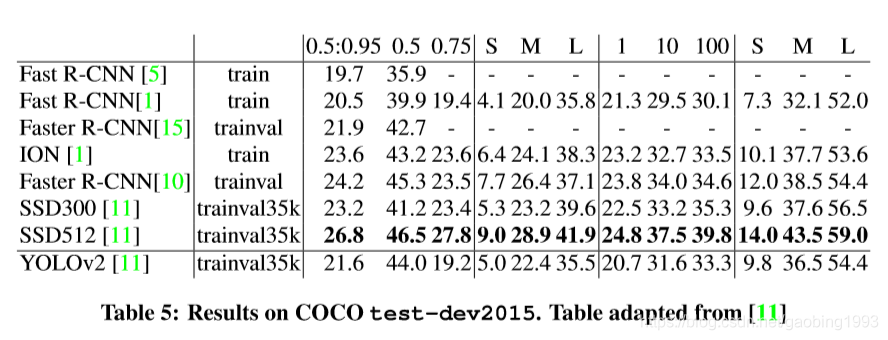
我们可以看到,yolov2版本较之于v1,其性能和准确度方面确实有所提升,但是其表现对比SSD还是有一些差距。不过他的速度确实是很快的。所以永不服输的yolo还会有很多努力,我们后续会为大家一一奉上。
4.总结
本文我们介绍了yolov2相对于v1版本进行的改进。主要包括三个方面,数据方面:BN;模型方面:darkenet19、全卷积、passthrough、anchor box;训练策略方面:高分辨率分类、高分辨率检测、聚类、多尺寸训练、损失调整;然后介绍了yolo9000的工作原理,分类数据集只进行分类损失反向调节。为了解决类别信息不独立问题,我们引入了wordtree;最终模型可以成功检测9000种物体。最后总结了yoloV2的性能和准确度,其准确度有很大提升,但是在coco数据集上相对于ssd还是有差距。yolo永不言弃!我们下篇再见。
5.甜点时刻
我非常看重一种能力,叫做相信的能力。我觉得人能相信一些看似不可能的事情,这种信本身就已经足够伟大。小孩子想成为蜘蛛侠,我们觉得他好可爱呀!但是长大以后还是相信呢?他的智商就一定有问题吗?不一定,真的不一定。对于世界我们知道的又有多少呢?可怜兮兮的。这仅有的一点知识的准确度又有多高呢?可怜兮兮的。发现真理的第一步是相信它。所以,我一直相信现在地球上的我们都是一些残缺不全的人,我们原本是完美的。颜值、品行、无限的光明、还有很多我想象不到的方面。我不能准确的知道为什么要来,但是我深深的相信总有一天是要回去的。回到本来的样式,一种完美的样式。但也许并不是所有的 人都能够回去,这个世界也许就是个赌场,赌输了也许就回不去了。那么赌注是什么呢?或许就是赌当我们变得不完美之后,我们会不会去做一些不好的事情。
【重磅】贾斯汀比伯最新电音单曲《Cold Water》出炉~全程好听到哭@油兔不二字幕组

