
- 1当一名测试工程师准备找工作时,你需要准备什么?(纯干货)_测试找工作应做哪些准备
- 2BERT模型中的多头注意力机制解读_bert 多头注意力机制
- 3卷积网络中卷积核大小和步长对输出矩阵大小的影响_卷积后矩阵大小
- 4机器视觉初步6:图像分割专题_halcon实例分割判定原理
- 5《深入浅出Pandas:利用Python进行数据处理与分析》——第1部分 Pandas入门_深入浅出pandas pdf下载
- 6面试题--Zookeeper
- 7数字中台与架构设计_数字中台的通用架构
- 8使用GnuPG加密和签名
- 9VMware Tools安装教程(适用windows虚拟机)_windows虚拟机安装vm tools csdn
- 10web安全——基础知识_web安全体系知识
PaliGemma视觉大模型目标检测任务微调教程
赞
踩
PaliGemma 是 Google 于 2024 年 5 月发布的大型多模态模型 (LMM)。你可以使用 PaliGemma 进行视觉问答 (VQA),检测图像上的物体,甚至生成分割蒙版。
虽然 PaliGemma 具有零样本能力(这意味着模型无需微调即可识别物体),但这种能力是有限的。Google 强烈建议对模型进行微调,以在特定领域获得最佳性能。
基础模型通常表现不佳的一个领域是医学成像。在本指南中,我们将介绍如何微调 PaliGemma 以检测 X 射线图像中的骨折。为此,我们将使用 Roboflow Universe 上可用的数据集之一。
JAX/FLAX PaliGemma 3B 有三个不同的版本,输入图像分辨率(224、448 和 896)和输入文本序列长度(分别为 128、512 和 512 个标记)不同。
为了限制 GPU 内存消耗并在 Google Colab 中启用微调,我们将在本教程中使用最小版本 paligemma-3b-pt-224。你需要具有至少 12GB 可用 RAM 的 GPU 运行时,而配备 NVIDIA T4 的 Google Colab 就足够了。
为了微调 PaliGemma,我们将:
- 下载 PaliGemma JSONL 格式的对象检测数据集;
- 安装所需的依赖项;
- 从 Kaggle 下载预先训练的 PaliGemma 权重和标记器;
- 使用 JAX 微调 PaliGemma;
- 保存我们的模型以供日后使用。
事不宜迟,让我们开始吧!

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、下载对象检测数据集
要微调 PaliGemma 进行对象检测,你需要一个 PaliGemma JSONL 格式的数据集。此格式通常不用于训练 YOLO 等传统计算机视觉模型,但通常用于训练语言模型。JSONL 格式的数据集的每一行都是一个单独的 JSON 对象,就像单个记录的列表一样。
在我们的例子中,每个记录都包含关联图像的名称、将传递给模型的前缀(提示)以及来自模型的后缀(预期响应)。以下是来自我们数据集的单个对象:
{'image': 'n_0_2513_png_jpg.rf.1f679ff5dec5332cf06f6b9593c8437b.jpg', 'prefix': 'detect fracture', 'suffix': '<loc0390><loc0241><loc0472><loc0440> fracture'}在提示中,请注意关键字detect,后面跟着我们想要“检测”的类列表,以分号分隔。预期的检测结果由'<loc{Y1}><loc{X1}><loc{Y2}><loc{X2}>'中的边界框和类名描述。值X1、Y1、X2和Y2描述边界框的位置,标准化为1024x1024的图像大小。每个值应该有4位数字;如果坐标更短,则用零填充。
Roboflow完全支持PaliGemma JSONL格式,可用于导出Roboflow Universe上250,000多个数据集中的任何一个。
首先,安装下载和解析数据集所需的依赖项:
pip install roboflow supervision对于本指南,我们将使用 Roboflow API 密钥下载骨折检测数据集:
- from google.colab import userdata
- from roboflow import Roboflow
-
- ROBOFLOW_API_KEY = userdata.get('ROBOFLOW_API_KEY')
-
- rf = Roboflow(api_key=ROBOFLOW_API_KEY)
- project = rf.workspace("srinithi-s-tzdkb").project("fracture-detection-rhud5")
- version = project.version(4)
- dataset = version.download("PaliGemma")
在开始微调之前,让我们通过可视化数据集中的一个示例来确保数据集的格式正确。
- from PIL import Image
- import json
-
- first = json.loads(open(f"{dataset.location}/dataset/_annotations.train.jsonl").readline())
- print(first)
-
- image = Image.open(f"{dataset.location}/dataset/{first.get('image')}")
- CLASSES = first.get('prefix').replace("detect ", "").split(" ; ")
- detections = from_pali_gemma(first.get('suffix'), image.size, CLASSES)
-
- sv.BoundingBoxAnnotator().annotate(image, detections)

现在我们知道标注已正确显示,我们可以设置 Python 环境并开始微调。本节中的大部分代码来自 PaliGemma 团队发布的官方 Google Colab。
2、模型设置
为了训练用于对象检测的 PaliGemma 模型,我们将使用 Google Research 维护的 big_vision 项目。我们可以使用以下代码安装此项目:
- import os
- import sys
-
- # TPUs with
- if "COLAB_TPU_ADDR" in os.environ:
- raise "It seems you are using Colab with remote TPUs which is not supported."
-
- # Fetch big_vision repository if python doesn't know about it and install
- # dependencies needed for this notebook.
- if not os.path.exists("big_vision_repo"):
- !git clone --quiet --branch=main --depth=1 \
- https://github.com/google-research/big_vision big_vision_repo
-
- # Append big_vision code to python import path
- if "big_vision_repo" not in sys.path:
- sys.path.append("big_vision_repo")
-
- # Install missing dependencies. Assume jax~=0.4.25 with GPU available.
- !pip3 install -q "overrides" "ml_collections" "einops~=0.7" "sentencepiece"

安装 big_vision 后,接下来需要下载 PaliGemma 模型权重。这些权重可在 Kaggle 上找到。你需要一个 Kaggle 帐户才能下载权重。你必须同意 Kaggle 中的 PaliGemma 服务条款才能使用模型权重。
设置 Kaggle 帐户并同意服务条款后,可以使用以下代码下载 PaliGemma 权重:
- import os
- from google.colab import userdata
-
- # Note: `userdata.get` is a Colab API. If you're not using Colab, set the env
- # vars as appropriate or make your credentials available in ~/.kaggle/kaggle.json
-
- os.environ["KAGGLE_USERNAME"] = userdata.get('KAGGLE_USERNAME')
- os.environ["KAGGLE_KEY"] = userdata.get('KAGGLE_KEY')
-
- import os
- import kagglehub
-
- MODEL_PATH = "./PaliGemma-3b-pt-224.f16.npz"
- if not os.path.exists(MODEL_PATH):
- print("Downloading the checkpoint from Kaggle, this could take a few minutes....")
- # Note: kaggle archive contains the same checkpoint in multiple formats.
- # Download only the float16 model.
- MODEL_PATH = kagglehub.model_download('google/PaliGemma/jax/PaliGemma-3b-pt-224', MODEL_PATH)
- print(f"Model path: {MODEL_PATH}")
-
- TOKENIZER_PATH = "./PaliGemma_tokenizer.model"
- if not os.path.exists(TOKENIZER_PATH):
- print("Downloading the model tokenizer...")
- !gsutil cp gs://big_vision/PaliGemma_tokenizer.model {TOKENIZER_PATH}
- print(f"Tokenizer path: {TOKENIZER_PATH}")
3、训练 PaliGemma 模型进行对象检测
下载模型权重后,我们现在可以在自定义对象检测数据集上训练 PaliGemma 模型。此步骤的代码很长,因此本指南将不包含代码。按照随附的笔记本获取训练模型所需的所有代码。
训练模型需要遵循的步骤是:
- 导入所有必需的依赖项
- 使用 ml_collections 库构建模型。
- 将模型权重加载到 RAM 中以供训练使用。
- 将参数移动到 GPU/TPU 内存以供训练使用。
- 定义图像和标记的预处理函数。
- 使用 PaliGemma jsonl 格式定义一个训练循环,该循环将迭代所有训练和验证示例。
- 以指定的学习率和示例数量运行训练循环以微调模型。
所有这些步骤都记录在本帖附带的 Colab 笔记本中。
在我们的 Colab 中,我们将批量大小设置为 8,学习率为 0.01,并将训练和评估步骤的数量定义为:
- BATCH_SIZE = 8
- TRAIN_EXAMPLES = 512
- LEARNING_RATE = 0.01
-
- TRAIN_STEPS = TRAIN_EXAMPLES // BATCH_SIZE
- EVAL_STEPS = TRAIN_STEPS // 8
有了训练好的模型,我们现在可以测试它了。
4、测试经过微调的对象检测模型
在我们的 Colab 笔记本中,我们声明了一个名为 make_predictions 的函数,该函数接受一个遍历图像并对每个图像运行推理的函数。
我们可以使用此函数来测试经过微调的对象检测模型:
- html_out = ""
- for image, caption in make_predictions(validation_data_iterator(), batch_size=4):
- html_out += render_example(image, caption)
- display(HTML(html_out))
以下是我们模型在项目的验证数据集上运行时的一些结果:
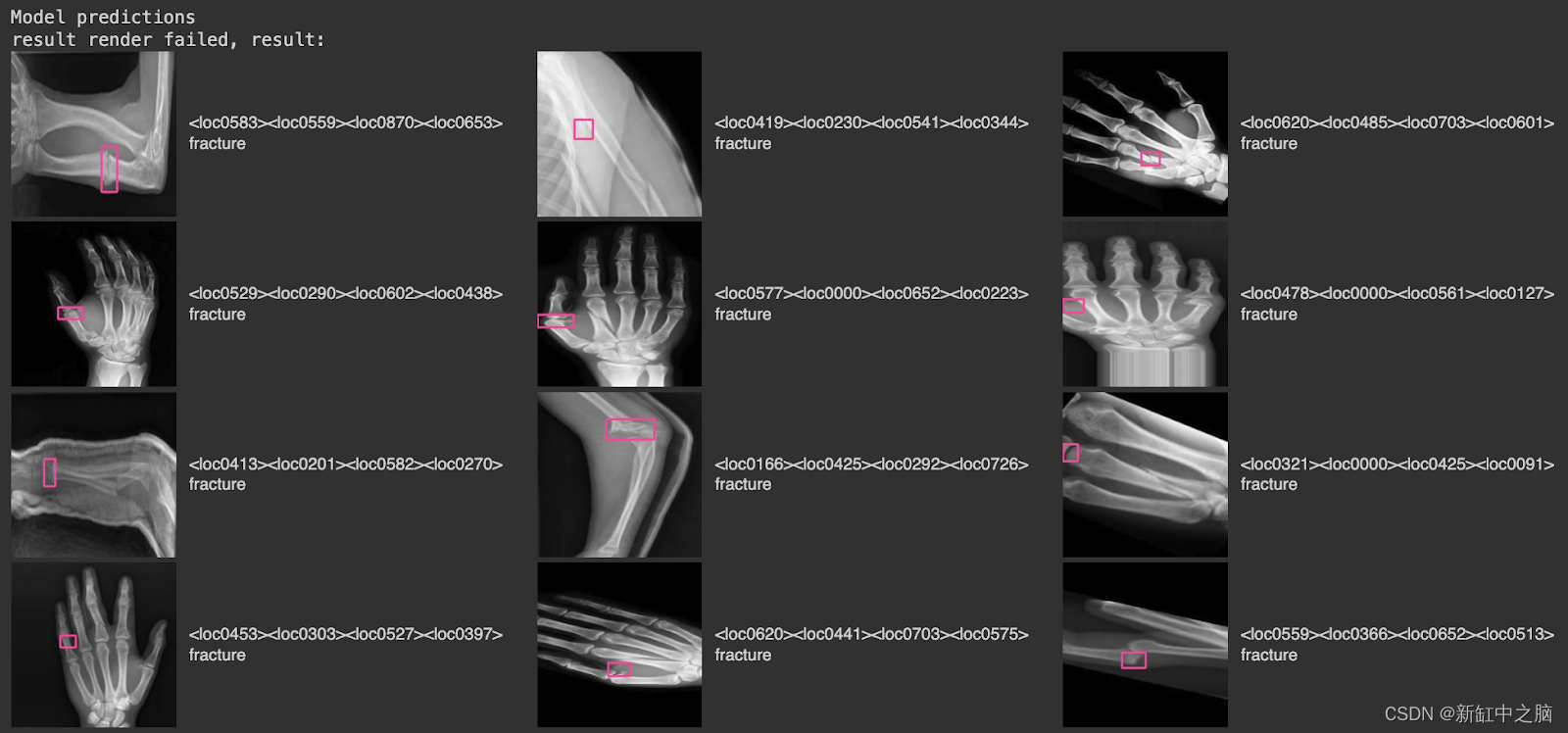
在此图像中,有来自验证集的图像,其中粉色边界框对应于模型的检测结果,右侧的文本标签告诉我们识别出的类别(“骨折”)。
可以使用以下代码保存模型以供日后使用:
- flat, _ = big_vision.utils.tree_flatten_with_names(params)
- with open("/content/fine-tuned-PaliGemma-3b-pt-224.f16.npz", "wb") as f:
- np.savez(f, **{k: v for k, v in flat})
5、结束语
PaliGemma 是 Google 开发的多模态视觉模型。PaliGemma 可用于识别图像中物体的位置,并识别与图像中特定物体相对应的分割蒙版。
在本指南中,我们介绍了如何使用自定义数据集对 PaliGemma 进行对象检测微调,并参考了改编自 Google 官方 PaliGemma 微调笔记本的笔记本。
我们从 Roboflow Universe 下载了一个兼容的数据集,目视检查以确保注释正确存储在 PaliGemma 格式中,然后在 Google Colab 上运行了一项训练作业。然后,我们使用项目的相应验证数据集测试了我们的模型,取得了很好的效果。

