- 1RayLink远程控制软件【文件传输】功能正式上线!!!_raylink连接同一网络中的电脑
- 2《机器学习》读书笔记:总结“第3章线性模型”中的概念
- 3腾讯云 Web 超级播放器开发实战_腾讯视频播放器开发
- 4准备提交到 App Store_app 内购买项目准备提交
- 5IntelliJ IDEA 控制台中文乱码,统一设置 UTF-8,解决方案都在这里了,完美解决乱码_控制台乱码
- 6Flink集群运行模式
- 7基于python实现去除视频的水印_python 视频去水印
- 8VTK_3D坐标系(vtkAxesActor/vtkCubeAxesActor)_vtk绘制背景刻度
- 9从头搭建pytorch Docker镜像_docker pytorch镜像
- 10一篇了解NLP中的注意力机制_注意力nlp
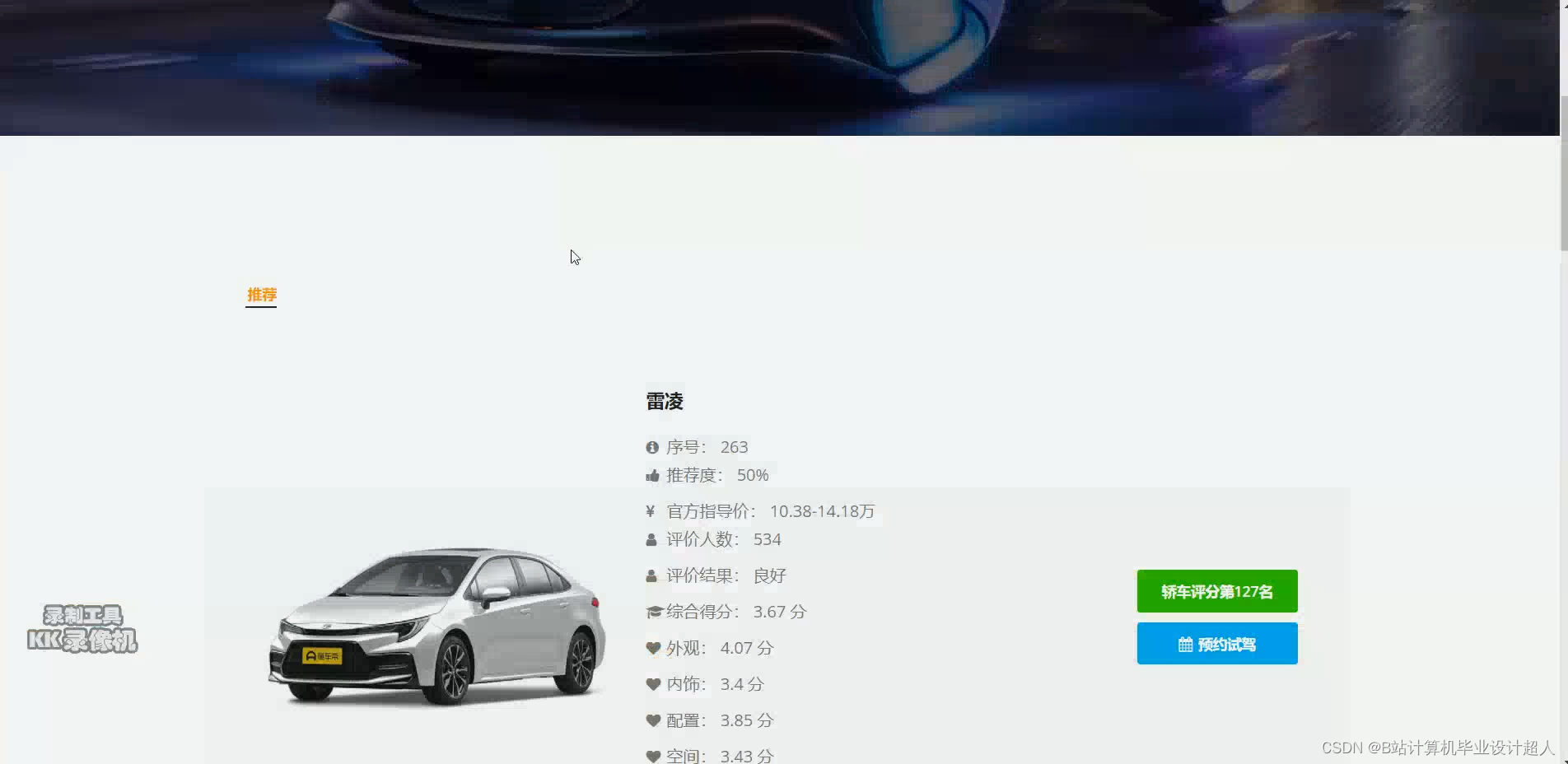
计算机毕业设计hadoop+spark+hive新能源汽车数据分析可视化大屏 汽车推荐系统 新能源汽车推荐系统 汽车爬虫 汽车大数据 机器学习 大数据毕业设计 深度学习 知识图谱 人工智能_基于hive的新能源汽车统计分析
赞
踩
二、设计的目的、要求、思路与预期成果
(1)设计目的
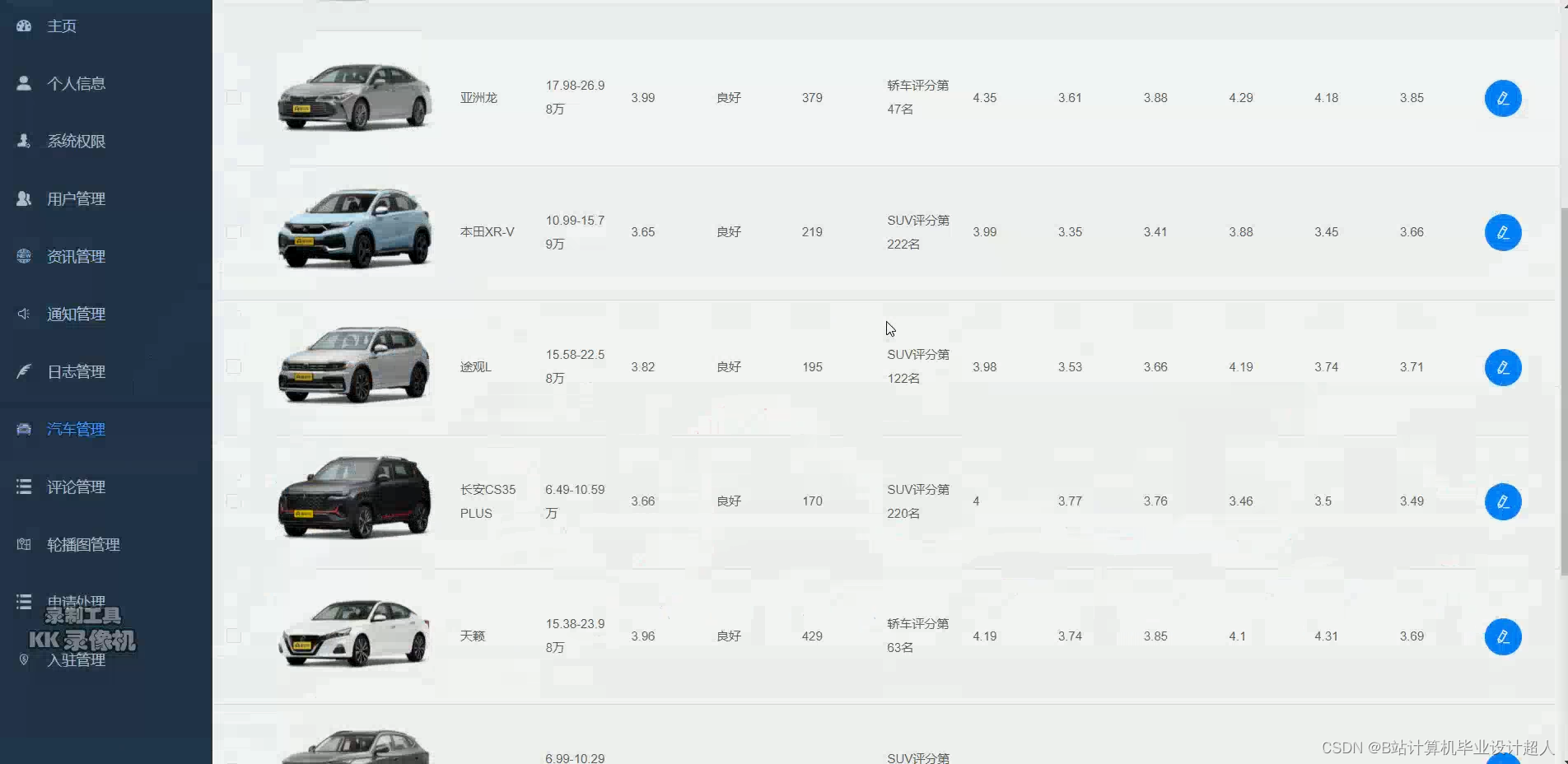
本次设计一个基于Hive的新能源汽车数据仓管理系统。企业管理员登录系统后可以在汽车保养时,根据这些汽车内置传感器传回的数据分析其故障原因,以便维修人员更加及时准确处理相关的故障问题。或者对这些数据分析之后向车主进行预警提示车主注意保养汽车,以提高汽车行驶的安全系数。
(2)设计要求
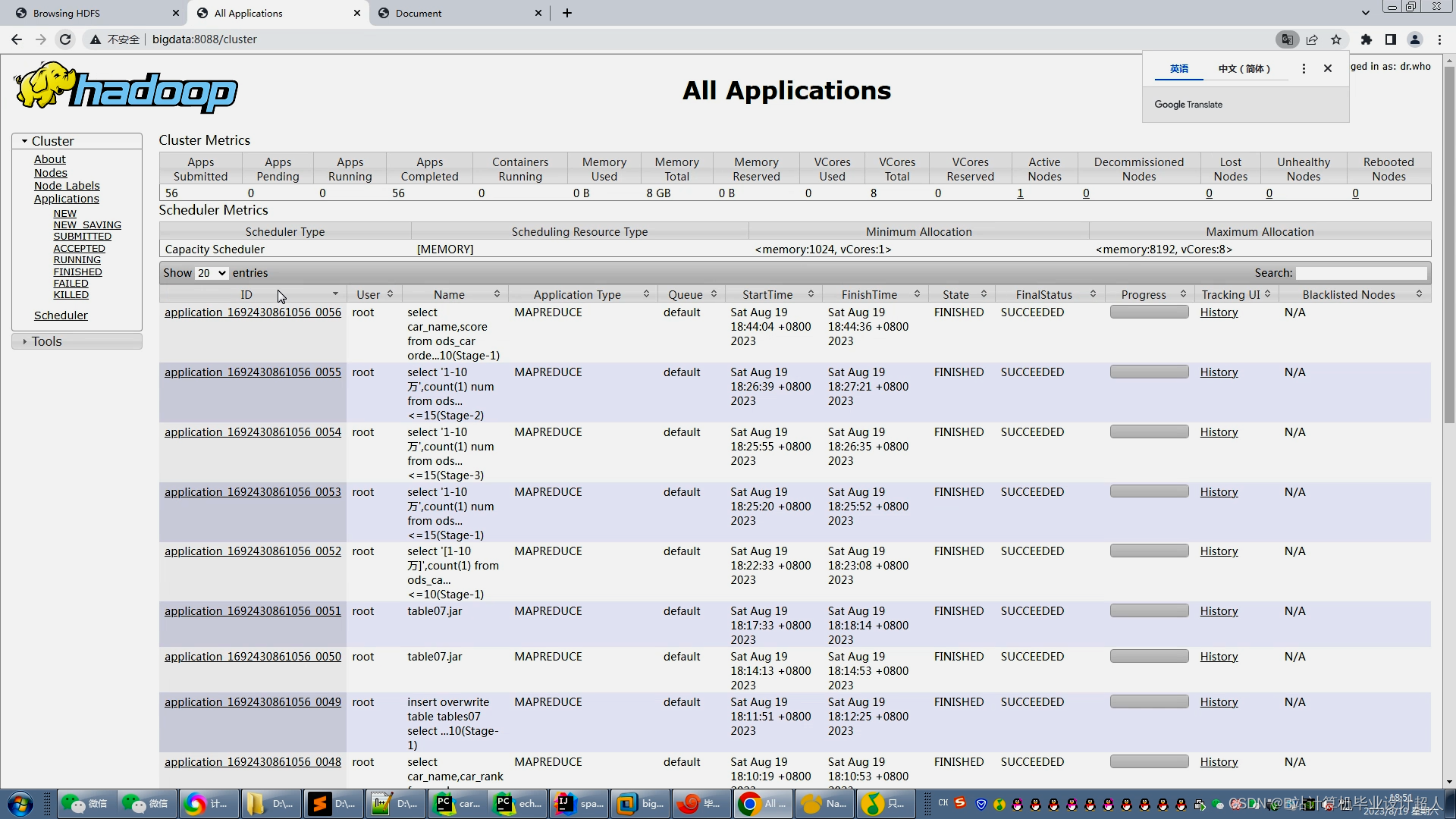
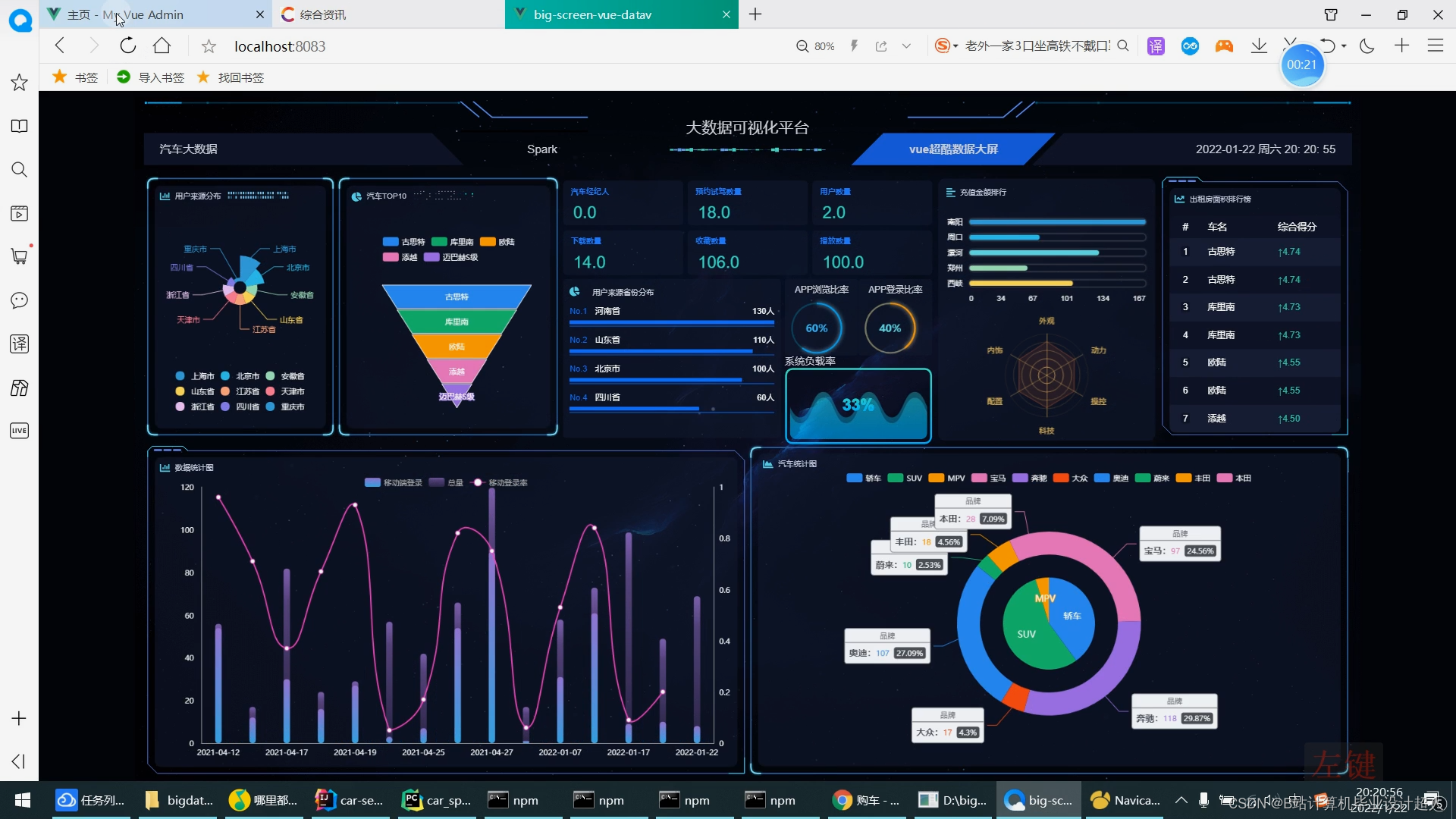
利用Flume进行分布式的日志数据采集,Kafka实现高吞吐量的数据传输,DateX进行数据清洗、转换和整合,MySQL存储结构化数据,HDFS存储大规模原始日志数据,Hive进行数据仓库查询和分析,Spark进行分布式数据计算,Dolphinscheduler进行全流程调度管理,帆软BI工具实现可视化大屏展示。实现数据采集、传输、清洗、存储、查询、计算、调度和展示全流程功能。提供监控、数据质量管理、多维度数据分析等功能。
(3)设计思路
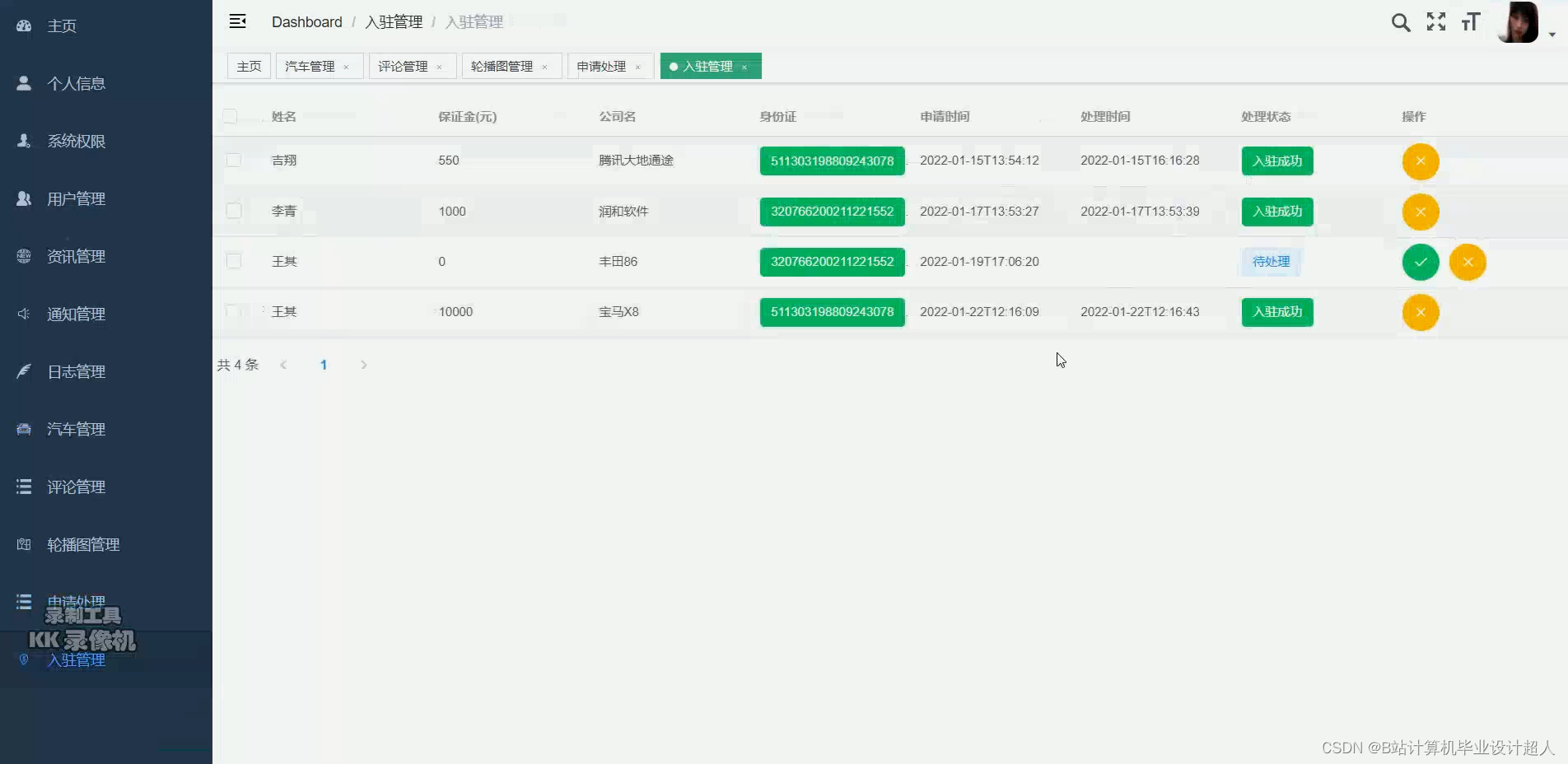
新能源汽车数据仓库管理系统,主要服务于新能源汽车车主,企业负责本系统的登录维护,在进行工作流调度时设置Admin用户进行环境管理或环境创建,设置普通用户权限进行项目工作流的创建和任务节点的配置,在FineBI中设置管理员账号进行环境的搭建以及对数据进行处理展示,使管理人员能够更加直观的获取想要的数据,企业根据系统中的数据为车主提供相关服务。其设计思路着重于多方位的数据处理,涵盖了全面数据采集、数据清洗和质量保障、大规模数据存储、高效数据管理、数据分析与挖掘、可扩展性与灵活性、用户友好的数据查询与报告、高性能与低延迟等多个方面。整体设计思路旨在打造一套高效、安全、可靠的大数据处理平台,为新能源汽车行业提供全面的数据支持,助力业务决策并确保系统在未来的发展中具备良好的可扩展性和适应性。
————————————————