
- 1Unity视频播放组件VideoPlayer的简单使用步骤_怎么创建play video
- 2使用UnityWebRequest发送Post请求深度解析_unitywebrequest post
- 3如何启动股票量化系统QTYX-Python3.7/3.9环境安装Anaconda+Pycharm及TaLib
- 4神经网络训练过程中不收敛或者训练失败的原因
- 510 个“疯狂”的 Python 项目创意,值得一试!_只有通过了这五步测试才能进行交易
- 6RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB解决方案_outofmemoryerror: cuda out of memory. tried to all
- 7【数据挖掘算法分享】机器学习平台——回归算法之随机森林_随机森林回归算法原理
- 8计划任务ScheduledExecutorService的使用_setremoveoncancelpolicy
- 9图像识别与处理学习笔记(二)图像增强之频率域处理_图像相位谱决定的
- 10计算机网络——网络
fast.ai 机器学习笔记(一)
赞
踩
机器学习 1:第 1 课
原文:
medium.com/@hiromi_suenaga/machine-learning-1-lesson-1-84a1dc2b5236译者:飞龙
来自机器学习课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和 Rachel 给了我这个学习的机会。
简要课程大纲
根据时间和班级兴趣,我们将涵盖类似以下内容(不一定按照这个顺序):
训练 vs. 测试
- 有效的验证集构建
树和集成
-
创建随机森林
-
解释随机森林
什么是机器学习?为什么我们使用它?
特征工程
-
领域特定 — 日期,URL,文本
-
嵌入/潜在因子
使用 SGD 训练的正则化模型
- 广义线性模型,Elasticnet 等(注意:查看 James 讲解的内容)
基本神经网络
-
PyTorch
-
广播,矩阵乘法
-
训练循环,反向传播
KNN
CV / bootstrap(糖尿病数据集?)
伦理考虑
跳过:
-
降维
-
交互
-
监控训练
-
协同过滤
-
动量和学习率退火
随机森林:蓝皮书对于推土机
%load_ext autoreload
%autoreload 2
%matplotlib inline
from fastai.imports import *
from fastai.structured import *
from pandas_summary import DataFrameSummary
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from IPython.display import display
from sklearn import metrics
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
数据科学 ≠ 软件工程 [08:43]。你会看到一些不符合 PEP 8 的代码和import *之类的东西,但暂时跟着走一段时间。我们现在正在做的是原型模型,原型模型有一套完全不同的最佳实践,这些实践在任何地方都没有教授。关键是能够非常互动和迭代地进行操作。Jupyter 笔记本使这变得容易。如果你曾经想知道display是什么,你可以做以下三件事之一:
-
在一个单元格中键入
display,然后按 shift+enter — 它会告诉你它来自哪里<function IPython.core.display.display> -
在一个单元格中键入
?display,然后按 shift+enter — 它会显示文档 -
在一个单元格中键入
??display,然后按 shift+enter — 它会显示源代码。这对于 fastai 库特别有用,因为大多数函数都很容易阅读,而且不超过 5 行。
下载数据 [12:05]
参加 Kaggle 竞赛将让你知道你是否在这种模型中的这种数据上有竞争力。准确率低是因为数据太嘈杂,你无法做得更好吗?还是实际上是一个简单的数据集,而你犯了错误?当你在自己的项目中使用自己的数据集时,你将得不到这种反馈 — 我们只需要知道我们有良好的有效技术来可靠地构建基线模型。
机器学习应该帮助我们理解数据集,而不仅仅是对其进行预测 [15:36]。因此,选择一个我们不熟悉的领域,这是一个很好的测试,看看我们是否能够建立理解。否则,你的直觉可能会使你很难保持足够开放的心态去看待数据真正的含义。
有几种下载数据的选项:
-
下载到您的计算机并通过
scp传输到 AWS -
从 Firefox [17:32],按
ctrl + shift + i打开 Web 开发者工具。转到Network选项卡,点击Download按钮,然后取消对话框。它会显示已启动的网络连接。然后右键单击它,选择Copy as cURL。粘贴命令并在末尾添加-o bulldozer.zip(可能删除 cURL 命令中的— — 2.0)
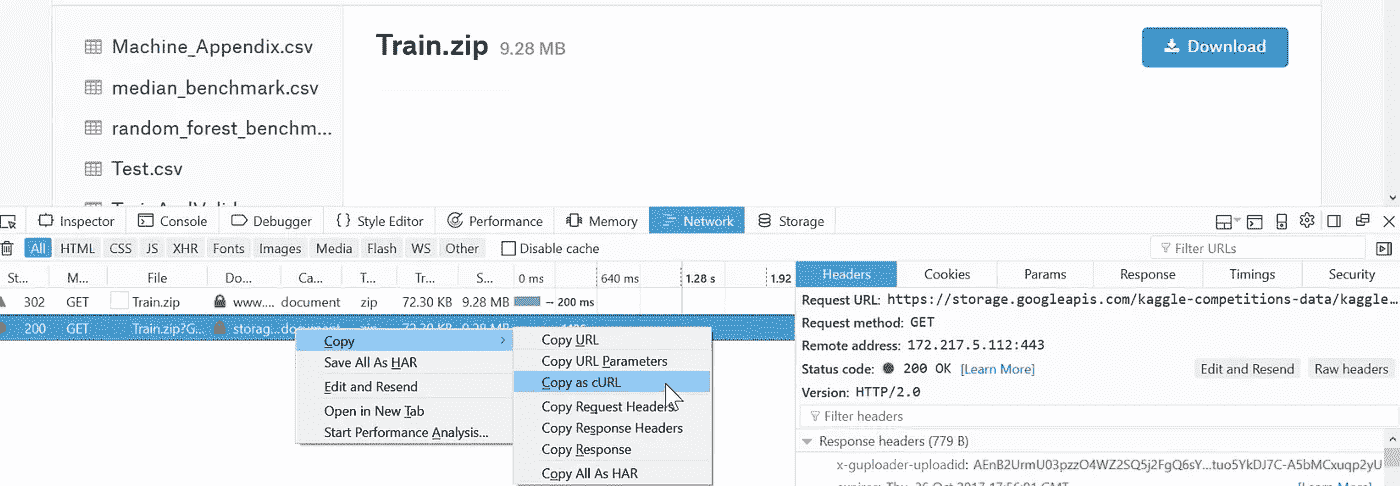
Jupyter 技巧[21:39] - 您可以打开基于 Web 的终端,如下所示:
这个竞赛的目标是使用包含截至 2011 年底的数据的训练集来预测推土机的销售价格。
让我们看看数据[25:25]:
结构化数据:代表各种不同类型事物的列,如标识符、货币、日期、大小。
非结构化数据:图像
当您处理通常作为pd导入的结构化数据时,pandas是最重要的库。
df_raw = pd.read_csv(
f'{PATH}Train.csv',
low_memory=False,
parse_dates=["saledate"]
)
- 1
- 2
- 3
- 4
- 5
-
parse_dates- 包含日期的任何列的列表 -
low_memory=False- 强制它读取更多文件以确定类型。
def display_all(df):
with pd.option_context("display.max_rows", 1000):
with pd.option_context("display.max_columns", 1000):
display(df)
display_all(df_raw.tail().transpose())
- 1
- 2
- 3
- 4
- 5
在 Jupyter Notebook 中,如果您键入一个变量名并按ctrl+enter,无论是 DataFrame、视频、HTML 等 - 它通常会找到一种显示方式供您使用[32:13]。

我们想要预测的变量在这种情况下被称为因变量,在这种情况下我们的因变量是SalePrice。
问题:因为过拟合的风险而永远不应查看数据吗?[33:08] 我们至少想知道我们已经成功导入了足够的数据,但在这一点上通常不会真正研究它,因为我们不想对它做太多假设。许多书籍建议首先进行大量的探索性数据分析(EDA)。我们今天将学习机器学习驱动的 EDA。
项目目的 - 评估[34:06]
均方根对数误差。我们使用对数的原因是因为通常,您更关心的不是差$10,而是差 10%。所以如果是$1000,000 的物品,您差$100,000,或者如果是$10,000 的物品,您差$1,000 - 我们会认为这些是等价的规模问题。
df_raw.SalePrice = np.log(df_raw.SalePrice)
- 1
np- Numpy 让我们将数组、矩阵、向量、高维张量视为 Python 变量。
什么是随机森林?[36:37]
随机森林是一种通用的机器学习技术。
-
它可以预测任何类型的东西 - 它可以是一个类别(分类),一个连续变量(回归)。
-
它可以预测任何类型的列 - 像素、邮政编码、收入等(即结构化和非结构化数据)。
-
它通常不会过度拟合,而且很容易阻止过度拟合。
-
通常情况下不需要单独的验证集。即使只有一个数据集,它也可以告诉您它的泛化程度如何。
-
它几乎没有任何统计假设。它不假设您的数据是正态分布的,关系是线性的,或者您已经指定了交互作用。
-
它需要非常少的特征工程。对于许多不同类型的情况,您不必对数据取对数或将交互作用相乘。
问题:维度的诅咒是什么?[38:16] 你经常听到两个概念 - 维度的诅咒和没有免费午餐定理。它们两者在很大程度上是毫无意义的,基本上是愚蠢的,然而许多领域的人不仅知道这一点,而且认为相反,因此值得解释。维度的诅咒是这样一个想法,即你拥有的列越多,就会创造出一个越来越空的空间。有这样一个迷人的数学思想,即你拥有的维度越多,所有点就越多地位于该空间的边缘。如果你只有一个随机的维度,那么它们就会分散在各处。另一方面,如果是一个正方形,那么它们在中间的概率意味着它们不能在任一维度的边缘,因此它们不太可能不在边缘。每增加一个维度,点不在至少一个维度的边缘上的可能性就会成倍减少,因此在高维度中,一切都位于边缘。从理论上讲,这意味着点之间的距离变得不那么有意义。因此,如果我们认为这很重要,那么它会暗示当你有很多列并且没有小心删除你不关心的列时,事情将不起作用。出于许多原因,结果并非如此
-
点之间仍然有不同的距离。只是因为它们在边缘上,它们仍然在彼此之间的距离上有所不同,因此这一点在这一点上比在那一点上更相似。
-
所以像 k 最近邻居这样的东西在高维度中实际上表现得非常好,尽管理论家们声称的不同。这里真正发生的是,在 90 年代,理论主导了机器学习。有这样一个概念,支持向量机在理论上得到了很好的证明,极易进行数学分析,你可以证明关于它们的事情 - 我们失去了十年的真正实际发展。所有这些理论变得非常流行,比如维度的诅咒。如今,机器学习的世界变得非常经验主义,事实证明,在实践中,在许多列上构建模型确实效果非常好。
-
没有免费午餐定理[41:08] - 他们声称没有一种模型适用于任何类型的数据集。在数学意义上,任何随机数据集的定义都是随机的,因此不会有一种方法可以查看每个可能的随机数据集,使其在某种程度上比其他方法更有用。在现实世界中,我们看的是不随机的数据。从数学上讲,我们会说它位于某个较低维度的流形上。它是由某种因果结构创建的。其中存在一些关系,因此事实是我们并没有使用随机数据集,因此实际上有一些技术比其他技术在你查看的几乎所有数据集上都要好得多。如今,有经验的研究人员研究哪些技术在大多数情况下效果很好。决策树的集成,其中随机森林是其中最常见的技术之一。Fast.ai 提供了一种标准的方法来适当地预处理它们并设置它们的参数。
scikit-learn[42:54]
Python 中最受欢迎和重要的机器学习包。它并非在所有方面都是最好的(例如,XGBoost 比梯度提升树更好),但在几乎所有方面都表现得相当不错。
m = RandomForestRegressor(n_jobs=-1)
- 1
-
RandomForestRegressor - 回归器是一种预测连续变量(即回归)的方法
-
RandomForestClassifier - 分类器是一种预测分类变量(即分类)的方法
m.fit(df_raw.drop('SalePrice', axis=1), df_raw.SalePrice)
- 1
scikit-learn 中的所有内容都具有相同的形式。
-
为机器学习模型创建一个对象的实例
-
通过传入独立变量(你要用来预测的东西)和因变量(你想要预测的东西)来调用
fit。 -
axis=1表示删除列。 -
在 Jupyter Notebook 中按下
shift + tab将显示函数的参数检查。 -
“类似列表”意味着任何你可以在 Python 中索引的东西。

以上的代码会导致错误。数据集“Conventional”中有一个值,它不知道如何使用该字符串创建模型。我们必须将大多数机器学习模型和随机森林转换为数字。因此,第一步是将所有内容转换为数字。
这个数据集包含了连续和分类变量的混合。
-
continuous — 数字,其含义是数值,比如价格。
-
categorical — 要么是数字,其含义不是连续的,比如邮政编码,要么是字符串,比如“大”,“中”,“小”
以下是我们可以从日期中提取的一些信息 — 年份、月份、季度、月中的日期、星期几、一年中的周数、是否是假期?周末?下雨了吗?那天有体育赛事吗?这取决于你在做什么。如果你正在预测 SoMa 地区的苏打销售额,你可能想知道那天是否有旧金山巨人队的比赛。日期中包含的信息是你可以进行的最重要的特征工程之一,没有任何机器学习算法可以告诉你那天巨人队是否在比赛,以及这一点有多重要。因此,这就是你需要进行特征工程的地方。
add_datepart方法从完整的日期时间中提取特定的日期字段,以构建分类变量。在处理日期时间时,你应该始终考虑这个特征提取步骤。如果不将日期时间扩展到这些额外字段,你就无法捕捉到任何趋势/周期性行为,作为时间的函数在任何这些粒度上。
def add_datepart(df, fldname, **drop=True**):
fld = df[fldname]
if not np.issubdtype(fld.dtype, np.datetime64):
df[fldname] = fld = pd.to_datetime(
fld, infer_datetime_format=True)
targ_pre = re.sub('[Dd]ate$', '', fldname)
for n in (
'Year', 'Month', 'Week', 'Day', 'Dayofweek',
'Dayofyear', 'Is_month_end', 'Is_month_start',
'Is_quarter_end', 'Is_quarter_start', 'Is_year_end',
'Is_year_start'
):
df[targ_pre+n] = getattr(fld.dt,n.lower())
df[targ_pre+'Elapsed'] = fld.astype(np.int64) // 10**9
if drop: df.drop(fldname, axis=1, inplace=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
getattr— 查找对象内部并找到具有该名称的属性 -
drop=True— 除非指定,它将删除日期时间字段,因为我们不能直接使用“saledate”,因为它不是一个数字。
fld = df_raw.saledate
fld.dt.year
- 1
- 2
-
fld— Pandas 系列 -
dt—fld没有“year”,因为它只适用于 Pandas 系列,这些系列是日期时间对象。因此,Pandas 会将不同的方法拆分到特定于它们的属性中。因此,日期时间对象将有dt属性定义,那里你会找到所有日期时间特定的属性。
add_datepart(df_raw, 'saledate')
df_raw.saleYear.head()
- 1
- 2
问题:[55:40] df['saleYear'] 和 df.saleYear 之间有什么区别?在分配值时最好使用方括号,尤其是在列不存在的情况下。
运行add_datepart后,它添加了许多数字列并删除了saledate列。这还不足以解决我们之前看到的错误,因为我们仍然有其他包含字符串值的列。Pandas 有一个类别数据类型的概念,但默认情况下它不会将任何内容转换为类别。Fast.ai 提供了一个名为train_cats的函数,它会为所有是字符串的内容创建分类变量。在幕后,它创建了一个整数列,并将从整数到字符串的映射存储在其中。train_cats被称为“train”,因为它是特定于训练数据的。验证和测试集将使用相同的类别映射(换句话说,如果你在训练数据集中使用 1 表示“高”,那么在验证和测试数据集中 1 也应该表示“高”)。对于验证和测试数据集,使用apply_cats。
train_cats(df_raw)
df_raw.UsageBand.cat.categories
'''
Index(['High', 'Low', 'Medium'], dtype='object)
'''
- 1
- 2
- 3
- 4
- 5
df_raw.UsageBand.cat— 类似于fld.dt.year,.cat让你可以访问假设某个东西是一个类别的内容。
顺序并不太重要,但由于我们将创建一个在单个点(即高 vs. 低 和 中,高 和 低 vs. 中)分割事物的决策树,这有点奇怪。为了以合理的方式对它们进行排序,您可以执行以下操作:
df_raw.UsageBand.cat.set_categories(
['High', 'Medium', 'Low'],
ordered=True, inplace=True
)
- 1
- 2
- 3
- 4
inplace将要求 Pandas 更改现有数据框而不是返回一个新的。
有一种称为“有序”的分类变量。有序分类变量具有某种顺序(例如“低” < “中” < “高”)。随机森林对此事实并不敏感,但值得注意。
display_all(df_raw.isnull().sum().sort_index()/len(df_raw))
- 1
上述操作将为每个系列添加一些空值,我们按索引排序它们([pandas.Series.sort_index](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.sort_index.html)),并除以数据集的数量。
读取 CSV 大约需要 10 秒,处理另外需要 10 秒,因此如果我们不想再等待,最好将它们保存下来。这里我们将以 feather 格式保存。这将以与 RAM 中相同基本格式保存到磁盘。这是迄今为止最快的保存和读取方式。Feather 格式不仅在 Pandas 中成为标准,而且在 Java、Apache Spark 等中也是如此。
os.makedirs('tmp', exist_ok=True)
df_raw.to_feather('tmp/bulldozers-raw')
- 1
- 2
我们可以这样读取它:
df_raw = pd.read_feather('tmp/raw')
- 1
我们将用它们的数字代码替换类别,处理缺失的连续值,并将因变量拆分为一个单独的变量。
df, y, nas = proc_df(df_raw, 'SalePrice')
- 1
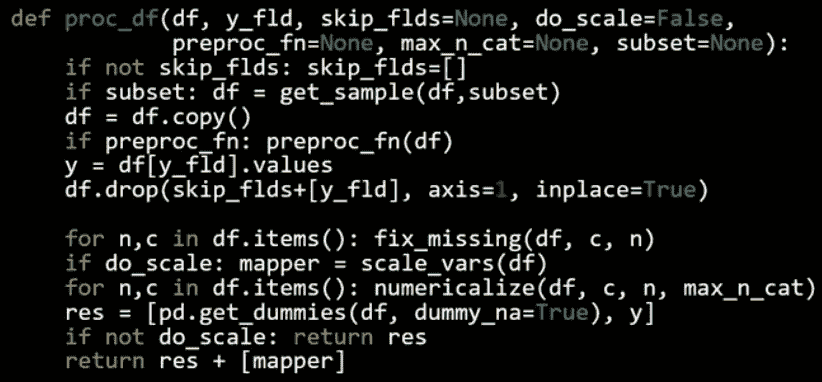
structured.py 中的 proc_df
-
df— 数据框 -
y_fld— 依赖变量的名称 -
它会复制数据框,获取依赖变量值(
y_fld),并从数据框中删除依赖变量。 -
然后它将
fix_missing(见下文) -
然后我们将遍历数据框并调用
numericalize(见下文)。 -
dummies— 有少量可能值的列,可以放入虚拟变量而不是数值化它们。但我们现在不会这样做。
fix_missing

-
对于数值数据类型,首先我们检查是否有空列。如果有,它将创建一个新列,名称末尾附加
_na,如果缺失则设置为 1;否则设置为 0(布尔值)。然后将缺失值替换为中位数。 -
我们不需要为分类变量执行此操作,因为 Pandas 会自动处理它们并将它们设置为
-1。
numericalize
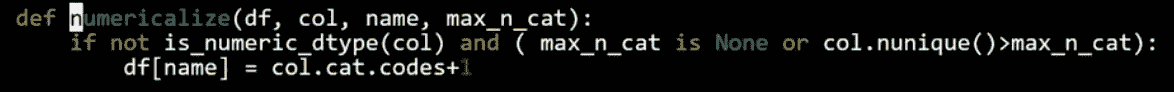
- 如果不是数字且是分类类型,我们将用其代码加 1 替换该列。默认情况下,Pandas 对缺失使用
-1,因此现在缺失将具有 ID 为0。
df.head()
- 1

现在我们有所有的数值值。请注意,布尔值被视为数字。因此我们可以创建一个随机森林。
m = RandomForestRegressor(n_jobs=-1)
m.fit(df, y)
m.score(df,y)
- 1
- 2
- 3
随机森林是极易并行化的 — 意味着如果您有多个 CPU,可以将数据分配到不同的 CPU 上并且它会线性扩展。因此,您拥有的 CPU 越多,花费的时间就会按照该数字减少(不完全准确,但大致如此)。n_jobs=-1告诉随机森林回归器为每个 CPU 创建一个单独的作业/进程。
m.score将返回 r²值(1 是好的,0 是坏的)。我们将在下周学习 r²。
哇,r²为 0.98 — 那很棒,对吧?嗯,也许不是…
机器学习中最重要的想法之一是拥有单独的训练和验证数据集。作为动机,假设您不将数据分割,而是使用全部数据。假设您有很多参数:
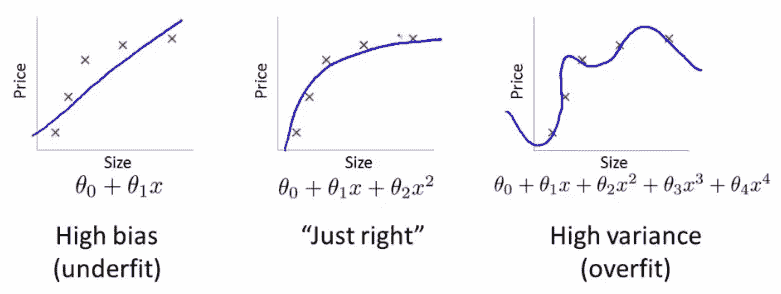
图片中数据点的误差对于最右侧的模型最低(蓝色曲线几乎完美地穿过红色点),但这并不是最佳选择。为什么呢?如果您收集一些新的数据点,它们很可能不会在右侧图表中的那条曲线上,而是会更接近中间图表中的曲线。
这说明如何使用所有数据可能导致过拟合。验证集有助于诊断这个问题。
def split_vals(a,n):
return a[:n].copy(), a[n:].copy()
n_valid = 12000 # same as Kaggle's test set size
n_trn = len(df)-n_valid
raw_train, raw_valid = split_vals(df_raw, n_trn)
X_train, X_valid = split_vals(df, n_trn)
y_train, y_valid = split_vals(y, n_trn)
X_train.shape, y_train.shape, X_valid.shape
'''
((389125, 66), (389125,), (12000, 66))
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
基础模型
通过使用验证集,您会发现验证集的 r²为 0.88。
def rmse(x,y): return math.sqrt(((x-y)**2).mean()) def print_score(m): res = [ rmse(m.predict(X_train), y_train), rmse(m.predict(X_valid), y_valid), m.score(X_train, y_train), m.score(X_valid, y_valid) ] if hasattr(m, 'oob_score_'): res.append(m.oob_score_) print(res) m = RandomForestRegressor(n_jobs=-1) %time m.fit(X_train, y_train) print_score(m) ''' CPU times: user 1min 3s, sys: 356 ms, total: 1min 3s Wall time: 8.46 s [0.09044244804386327, 0.2508166961122146, 0.98290459302099709, 0.88765316048270615] '''

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
*[训练集 rmse,验证集 rmse,训练集 r²,验证集 r²]
如果您查看 Kaggle 竞赛的公共榜单,RMSE 为 0.25 的排名将在前 25%左右。随机森林非常强大,这种完全标准化的过程对任何数据集都非常好。
下节课之前
请尝试使用这个过程尽可能多地解决 Kaggle 竞赛。您很可能会惊喜地发现,仅仅一小时的讲座您就能做得相当不错。
机器学习 1:第 2 课
原文:
medium.com/@hiromi_suenaga/machine-learning-1-lesson-2-d9aebd7dd0b0译者:飞龙
来自机器学习课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和 Rachel 给了我这个学习的机会。
随机森林深入研究
在接下来的几堂课中,我们将研究:
-
随机森林的实际工作原理
-
如果它们不能正常工作该怎么办
-
优缺点是什么
-
我们可以调整什么
-
如何解释结果
Fastai 库是一组实现最先进结果的最佳技术。对于结构化数据分析,scikit-learn 有很多优秀的代码。因此,fastai 的作用是帮助我们将事物转换为 scikit-learn,然后从 scikit-learn 中解释事物。
正如我们所指出的,深入理解评估指标是非常重要的。
均方根对数误差(RMSLE):
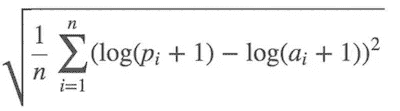

因此,我们取价格的对数并使用均方根误差(RMSE)。
df_raw.SalePrice = np.log(df_raw.SalePrice)
- 1
然后我们通过以下方式将数据集中的所有内容转换为数字:
-
add_datepart— 提取日期时间特征Elapsed表示自 1970 年 1 月 1 日以来经过的天数。 -
train_cats— 将string转换为 pandascategory数据类型。然后我们通过运行**proc_df**将分类列替换为类别代码。 -
proc_df还用中位数替换连续列的缺失值,并添加名为[column name]_na的列,并将其设置为 true 以指示它是缺失的。
m = RandomForestRegressor(n_jobs=-1)
m.fit(df, y)
m.score(df, y)
'''
0.98304680998313232
'''
- 1
- 2
- 3
- 4
- 5
- 6
什么是 R²?
Jeremy 的回答

-
yi : 实际/目标数据
-
ȳ : 平均值
-
SStot: 数据变化的程度 -
上周我们想出的最简单的非愚蠢模型是创建一个平均值的列并将其提交给 Kaggle。在这种情况下,RMSE =
SStot(即一个天真模型的 RMSE) -
fi: 预测
-
SSres是实际模型的 RMSE -
如果我们正好像只预测平均值一样有效,
SSres/SStot= 1 并且 R² = 0 -
如果我们完美(即 yi = fi 对于所有情况),
SSres/SStot= 0 并且 R² = 1
R²的可能范围是多少?
正确答案:任何等于或小于 1 的值。如果你为每一行预测无穷大,R² = 1 −∞
因此,当你的 R²为负数时,这意味着你的模型比预测平均值更差。
R² 不一定是你实际尝试优化的内容,但它是一个你可以用于每个模型的数字,你可以开始感受到 0.8 看起来是什么样子,0.9 看起来是什么样子。你可能会发现有趣的是创建具有不同随机噪声量的合成 2D 数据集,并查看它们在散点图上的样子和它们的 R²,以了解它们与实际值有多接近。
R²是你的模型有多好(RMSE)与天真的平均模型有多好(RMSE)之间的比率。
过拟合 [17:33]
在我们的案例中,R²= 0.98 是一个非常好的模型。然而,可能会出现像右边这样的情况:
它擅长运行我们给定的点,但不会很好地运行我们没有给定的点。这就是为什么我们总是希望有一个验证集的原因。
创建验证集是进行机器学习项目时最重要的事情。您需要做的是提出一个数据集,您的模型在该数据集上的得分将代表您的模型在真实世界中的表现如何。
如果您的数据集中有一个时间部分(如蓝皮书比赛中),您可能希望预测未来的价格/价值等。Kaggle 所做的是在训练集中给我们提供代表特定日期范围的数据,然后测试集呈现了训练集中没有的未来日期集。因此,我们需要创建一个具有相同属性的验证集:
def split_vals(a,n):
return a[:n].copy(), a[n:].copy()
n_valid = 12000 # same as Kaggle's test set size
n_trn = len(df)-n_valid
raw_train, raw_valid = split_vals(df_raw, n_trn)
X_train, X_valid = split_vals(df, n_trn)
y_train, y_valid = split_vals(y, n_trn)
X_train.shape, y_train.shape, X_valid.shape
'''
((389125, 66), (389125,), (12000, 66))
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
现在我们有了一个希望看起来像 Kaggle 测试集的东西-足够接近,使用这个将给我们相当准确的分数。我们想要这样做的原因是因为在 Kaggle 上,您只能提交很多次,如果您提交得太频繁,最终您会适应排行榜。在现实生活中,我们希望构建一个在生产中表现良好的模型。
问题:您能解释验证集和测试集之间的区别吗[20:58]?今天我们要学习的一件事是如何设置超参数。超参数是会改变模型行为的调整参数。如果您只有一个保留集(即一个您不用来训练的数据集),并且我们用它来决定使用哪组超参数。如果我们尝试一千种不同的超参数组合,我们可能最终会过拟合到那个保留集。因此,我们要做的是有一个第二个保留集(测试集),在那里我们可以说我已经尽力了,现在就在最后一次,我要看看它是否有效。
您必须实际上从数据中删除第二个保留集(测试集),将其交给其他人,并告诉他们在您承诺完成之前不要让您看到它。否则很难不去看它。在心理学和社会学领域,这被称为复制危机或 P-值调整。这就是为什么我们想要有一个测试集。
问题:我们已经将分类变量转换为数字,但其他模型使用独热编码将其转换为不同的列-应该使用哪种方法[22:55]?我们今天将解决这个问题。
基础模型[23:42]

正如您所看到的,训练集上的 R²为 0.982,验证集上仅为 0.887,这让我们认为我们过拟合得相当严重。但并不是太糟糕,因为 RMSE 为 0.25 会让我们进入比赛的前 25%。
问题:为什么不选择随机行集作为验证集[24:19]?因为如果我们这样做,我们将无法复制测试集。如果您实际上查看测试集中的日期,您会发现这些日期比训练集中的任何日期都要新。因此,如果我们使用一个随机样本作为验证集,那将更容易,因为我们正在预测在这一天的工业设备的价值,而我们已经有了那一天的一些观察结果。一般来说,每当您构建具有时间元素的模型时,您希望您的测试集是一个单独的时间段,因此您确实需要您的验证集也是一个单独的时间段。
问题:最终不会过拟合验证集吗?[25:30] 是的,实际上这就是问题所在。最终可能会在验证集上过拟合,当你在测试集上尝试或提交到 Kaggle 时,结果可能并不好。这在 Kaggle 竞赛中经常发生,他们实际上有第四个数据集,称为私人排行榜集。每次提交到 Kaggle 时,你实际上只会得到在公共排行榜集上的表现反馈,你不知道它们是哪些行。在比赛结束时,你将根据完全不同的数据集进行评判,称为私人排行榜集。避免这种情况的唯一方法是成为一个优秀的机器学习从业者,并尽可能有效地设置这些参数,这部分我们今天和未来几周将会做。
PEP8[27:09]
def rmse(x,y):
return math.sqrt(((x-y)**2).mean())
- 1
- 2
这是一个代码不符合 PEP8 规范的例子。能够用眼睛一次看到某些东西,并随着时间学会立即看出发生了什么具有很大的价值。在数据科学中,始终使用特定的字母或缩写表示特定的含义是有效的。但是如果你在家里面试中测试,要遵循 PEP8 标准。
执行时间[29:29]
如果你加上%time,它会告诉你花了多长时间。经验法则是,如果某个操作花费超过 10 秒,那么用它进行交互式分析就太长了。所以我们要确保事情能在合理的时间内运行。然后当我们一天结束时,我们可以说好了,这个特征工程,这些超参数等都运行良好,我们现在将以大慢精确的方式重新运行它。
加快速度的一种方法是将 subset 参数传递给 proc_df,这将随机抽样数据:
df_trn, y_trn, nas = proc_df(
df_raw, 'SalePrice',
subset=30000,
na_dict=nas
)
X_train, _ = split_vals(df_trn, 20000)
y_train, _ = split_vals(y_trn, 20000)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
请确保验证集不会改变
-
还要确保训练集与日期不重叠
如上所示,在调用split_vals时,我们没有将结果放入验证集。_表示我们丢弃了返回值。我们希望保持验证集始终相同。
在将训练集重新采样为 30,000 个子集中的前 20,000 个后,运行时间为 621 毫秒。
构建单棵树[31:50]
我们将建立由树组成的森林。让我们从树开始。在 scikit-learn 中,他们不称之为树,而是估计器。
m = RandomForestRegressor(
n_estimators=1,
max_depth=3,
bootstrap=False,
n_jobs=-1
)
m.fit(X_train, y_train)
print_score(m)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
n_estimators=1— 创建只有一棵树的森林 -
max_depth=3— 使其成为一棵小树 -
bootstrap=False— 随机森林会随机化很多东西,我们希望通过这个参数关闭它
这棵小的确定性树在拟合后的 R²为 0.4028,所以这不是一个好模型,但比平均模型好,因为它大于 1,我们实际上可以绘制[33:00]:

一棵树由一系列二进制决策组成。
-
第一行表示二进制分割标准
-
根节点的
samples为 20,000,因为这是我们在拆分数据时指定的。 -
较深的颜色表示较高的
value -
value是价格的对数的平均值,如果我们构建了一个模型,只使用平均值,那么均方误差mse将为 0.495 -
我们能够做出的最佳单一二进制分割结果是
Coupler_system ≤ 0.5,这将使mse在错误路径上提高到 0.109;在正确路径上为 0.414。
我们想要从头开始构建一个随机森林[36:28]。第一步是创建一棵树。创建树的第一步是创建第一个二进制决策。你打算如何做?
-
我们需要选择一个变量和一个值来分割,使得这两个组尽可能不同
-
对于每个变量,对于该变量的每个可能值,看看哪个更好。
-
如何确定哪个更好?取两个新节点的加权平均值
-
得到的模型将类似于平均模型——我们有一个具有单一二进制决策的模型。对于所有
coupler_system大于 0.5 的人,我们将填入 10.345,对于其他人,我们将填入 9.363。然后我们将计算这个模型的 RMSE。
现在我们有一个单一数字来表示一个分割有多好,这个数字是创建这两个组的均方误差的加权平均值。我们还有一种找到最佳分割的方法,就是尝试每个变量和每个可能的值,看哪个变量和哪个值给出了最佳得分的分割。
问题:是否有情况下最好分成 3 组?在一个级别上永远不需要做多次分割,因为你可以再次分割它们。
这就是创建决策树的全部过程。停止条件:
-
当达到所请求的限制(
max_depth) -
当你的叶节点只有一个元素时
让我们的决策树更好
现在,我们的决策树的 R²为 0.4。让我们通过去掉max_depth=3来使其更好。这样做后,训练 R²变为 1(因为每个叶节点只包含一个元素),验证 R²为 0.73——比浅树好,但不如我们希望的那么好。
m = RandomForestRegressor(
n_estimators=1,
bootstrap=False,
n_jobs=-1
)
m.fit(X_train, y_train)
print_score(m)
'''
[6.5267517864504e-17, 0.3847365289469930, 1.0, 0.73565273648797624]
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
为了让这些树更好,我们将创建一个森林。要创建一个森林,我们将使用一种称为bagging的统计技术。
Bagging
迈克尔·乔丹开发了一种称为小自助袋的技术,他展示了如何对任何类型的模型使用 bagging,使其更加稳健,并为您提供置信区间。
随机森林——一种 bagging 树的方法。
那么什么是 bagging?Bagging 是一个有趣的想法,即如果我们创建了五个不同的模型,每个模型只是有些预测性,但这些模型给出的预测彼此之间没有相关性。这意味着这五个模型对数据中的关系有着截然不同的见解。如果你取这五个模型的平均值,你实际上是将每个模型的见解带入其中。因此,平均模型的这种想法是一种集成技术。
如果我们创建了很多树——大的、深的、过度拟合的树,但每棵树只选择数据的随机 1/10。假设我们这样做了一百次(每次使用不同的随机样本)。它们都过度拟合了,但由于它们都使用不同的随机样本,它们在不同的方面以不同的方式过度拟合。换句话说,它们都有错误,但这些错误是随机的。一堆随机错误的平均值是零。如果我们取这些树的平均值,每棵树都是在不同的随机子集上训练的,那么错误将平均为零,剩下的就是真正的关系——这就是随机森林。
m = RandomForestRegressor(n_jobs=-1)
m.fit(X_train, y_train)
print_score(m)
- 1
- 2
- 3
n_estimators默认为 10(记住,estimators 就是树)。
问题:你是在说我们平均了 10 个糟糕的模型,然后得到了一个好模型吗?确实是这样。因为这些糟糕的模型是基于不同的随机子集,它们的错误之间没有相关性。如果错误是相关的,这种方法就行不通。
这里的关键见解是构建多个比没有好的模型,而且错误尽可能不相关的模型。
要使用的树的数量是我们要调整的第一个超参数,以实现更高的度量。
问题:您选择的子集,它们是互斥的吗?是否可以重叠?[52:27]我们讨论了随机选择 1/10,但 scikit-learn 默认情况下是对n行进行替换选择n行——这称为自助法。如果记忆无误,平均而言,63.2%的行将被表示,其中许多行将多次出现。
机器学习中建模的整个目的是找到一个模型,告诉您哪些变量很重要,它们如何相互作用以驱动您的因变量。在实践中,使用随机森林空间来找到最近邻居与欧几里得空间之间的区别是一个模型做出良好预测和做出无意义预测之间的区别。
有效的机器学习模型能够准确地找到训练数据中的关系,并且能够很好地泛化到新数据[55:53]。在装袋中,这意味着您希望每个单独的估计器尽可能具有预测性,但希望每棵树的预测尽可能不相关。研究界发现,更重要的事情似乎是创建不相关的树,而不是更准确的树。在 scikit-learn 中,还有另一个称为ExtraTreeClassifier的类,它是一种极端随机树模型。它不是尝试每个变量的每个分割,而是随机尝试几个变量的几个分割,这样训练速度更快,可以构建更多的树——更好的泛化。如果您有糟糕的单独模型,您只需要更多的树来获得一个好的最终模型。
提出预测[1:04:30]
preds = np.stack([t.predict(X_valid) for t in m.estimators_])
preds[:,0], np.mean(preds[:,0]), y_valid[0]
'''
(array([ 9.21034, 8.9872 , 8.9872 , 8.9872 , 8.9872 , 9.21034, 8.92266, 9.21034, 9.21034, 8.9872 ]),
9.0700003890739005,
9.1049798563183568)
'''
preds.shape
'''
(10, 12000)
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
每棵树都存储在名为estimators_的属性中。对于每棵树,我们将使用验证集调用predict。np.stack将它们连接在一起形成一个新轴,因此结果preds的形状为(10, 12000)(10 棵树,12000 个验证集)。对于第一个数据的 10 个预测的平均值为 9.07,实际值为 9.10。正如你所看到的,没有一个单独的预测接近 9.10,但平均值最终相当不错。

这里是给定前i棵树的 R²值的图。随着我们添加更多的树,R²值会提高。但似乎已经趋于平缓。

正如你所看到的,添加更多的树并没有太大帮助。它不会变得更糟,但也不会显著改善事情。这是要学会设置的第一个超参数——估计器的数量。一种设置的方法是,尽可能多地拟合,而且实际上似乎有所帮助。
添加更多的树会减慢速度,但使用更少的树仍然可以获得相同的见解。所以当 Jeremy 构建大部分模型时,他从 20 或 30 棵树开始,项目结束或当天工作结束时,他会使用 1000 棵树并在夜间运行。
袋外(OOB)得分[1:10:04]
有时您的数据集会很小,您不想提取验证集,因为这样做意味着您现在没有足够的数据来构建一个好的模型。然而,随机森林有一个非常聪明的技巧,称为袋外(OOB)误差,可以处理这种情况(以及更多!)
我们可以意识到,在我们的第一棵树中,一些行没有用于训练。我们可以通过第一棵树传递那些未使用的行,并将其视为验证集。对于第二棵树,我们可以通过未用于第二棵树的行,依此类推。实际上,我们将为每棵树创建一个不同的验证集。为了计算我们的预测,我们将对所有未用于训练的行进行平均。如果您有数百棵树,那么很可能所有行都会在这些袋外样本中多次出现。然后,您可以在这些袋外预测上计算 RMSE、R²等。
m = RandomForestRegressor(
n_estimators=40,
n_jobs=-1,
oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.10198464613020647, 0.2714485881623037, 0.9786192457999483, 0.86840992079038759, 0.84831537630038534]
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
将oob_score设置为 true 将执行此操作,并为模型创建一个名为oob_score_的属性,如您在 print_score 函数中看到的,如果具有此属性,它将在最后打印出来。
问题:oob_score_难道不总是低于整个森林的分数吗[1:12:51]?准确率往往较低,因为在 OOB 样本中,每行出现的树较少,而在完整树集中出现的次数较多。因此,OOB R²会稍微低估模型的泛化能力,但是您添加的树越多,这种低估就越不严重。
在设置超参数时,OOB 分数会派上用场[1:13:47]。我们将设置相当多的超参数,并希望找到一种自动化的方法来设置它们。一种方法是进行网格搜索。Scikit-learn 有一个名为网格搜索的函数,您可以传入要调整的所有超参数的列表以及要尝试的所有这些超参数的值。它将在所有这些超参数的所有可能组合上运行您的模型,并告诉您哪一个是最佳的。OOB 分数是一个很好的选择,可以告诉您哪一个是最佳的。
子采样[1:14:52]
之前,我们取了 30,000 行,并创建了使用该 30,000 行不同子集的所有模型。为什么不每次取一个完全不同的 30,000 子集?换句话说,让我们保留全部 389,125 条记录,如果我们想加快速度,每次选择一个不同的 30,000 子集。因此,而不是对整个行集进行自助抽样,只需随机抽取数据的一个子集。
df_trn, y_trn = proc_df(df_raw, 'SalePrice')
X_train, X_valid = split_vals(df_trn, n_trn)
y_train, y_valid = split_vals(y_trn, n_trn)
set_rf_samples(20000)
- 1
- 2
- 3
- 4
set_rf_samples:与之前一样,我们在训练集中使用 20,000 个样本(之前是 30,000,这次是 389,125)。

这将花费与之前相同的时间来运行,但是每棵树都可以访问整个数据集。在使用 40 个估计器后,我们得到了 R²分数为 0.876。
问题:这个 OOB 分数是在哪些样本上计算的[1:18:26]?Scikit-learn 不支持这个功能,因此set_rf_samples是一个自定义函数。因此,在使用set_rf_samples时,需要关闭 OOB 分数,因为它们不兼容。reset_rf_samples()将把它恢复到原来的状态。
最重要的提示[1:20:30]:大多数人总是使用最佳参数在所有时间内在所有数据上运行所有模型,这是毫无意义的。如果您想找出哪些特征重要以及它们之间的关系,那么准确度的第四位小数点根本不会改变您的任何见解。在足够大的样本量上运行大多数模型,使得您的准确度合理(在最佳准确度的合理距离内),并且训练时间短,以便您可以交互式地进行分析。
另外两个参数[1:21:18]
让我们为这个完整集合建立一个基准来进行比较:
reset_rf_samples()
m = RandomForestRegressor(
n_estimators=40,
n_jobs=-1,
oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.07843013746508616, 0.23879806957665775, 0.98490742269867626, 0.89816206196980131, 0.90838819297302553]
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这里 OOB 高于验证集。这是因为我们的验证集是不同的时间段,而 OOB 样本是随机的。预测不同时间段要困难得多。
min_sample
m = RandomForestRegressor(
n_estimators=40,
min_samples_leaf=3,
n_jobs=-1,
oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.11595869956476182, 0.23427349924625201, 0.97209195463880227, 0.90198460308551043, 0.90843297242839738]
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
min_sample_leaf=3:当叶节点具有 3 个或更少的样本时停止训练树(之前我们一直下降到 1)。这意味着将减少一到两个决策级别,这意味着我们需要训练的实际决策标准数量减半(即更快的训练时间)。 -
对于每棵树,我们不仅仅取一个点,而是取至少三个点的平均值,我们期望每棵树都能更好地泛化。但是每棵树本身的能力会稍微减弱。
-
效果很好的数字是 1、3、5、10、25,但相对于您的整体数据集大小而言。
-
通过使用 3 而不是 1,验证 R²从 0.89 提高到 0.90
max_feature [1:24:07]
m = RandomForestRegressor(
n_estimators=40,
min_samples_leaf=3,
max_features=0.5,
n_jobs=-1,
oob_score=True
)
m.fit(X_train, y_train)
print_score(m)
'''
[0.11926975747908228, 0.22869111042050522, 0.97026995966445684, 0.9066000722129437, 0.91144914977164715]
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
max_features=0.5:这个想法是,树之间的相关性越小,越好。想象一下,如果有一列比其他所有列更好地预测,那么您构建的每棵树总是从那一列开始。但是可能存在一些变量之间的相互作用,其中该相互作用比单个列更重要。因此,如果每棵树总是首次在相同的内容上分裂,那么这些树的变化就不会很大。 -
除了取一部分行之外,在每个单独的分割点,取不同的列子集。
-
对于行抽样,每棵新树都基于一组随机行,对于列抽样,每个单独的二元分割,我们从不同的列子集中选择。
-
0.5 意味着随机选择其中一半。您可以使用特殊值,如
sqrt或log2 -
使用的好值是
1、0.5、log2或sqrt
0.2286 的 RMSLE 将使我们进入这场比赛的前 20 名——只需使用一些无脑的随机森林和一些无脑的次要超参数调整。这就是为什么随机森林不仅是机器学习的第一步,而且通常是唯一的一步。很难搞砸。
为什么随机森林效果如此好[1:30:21]
让我们看看小单树中的一个分割点。
fiProductClassDesc ≤ 7.5将分割:
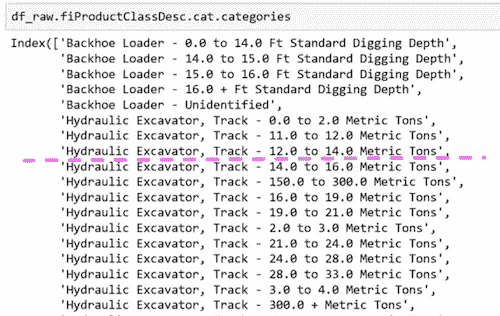
为什么这样做有效呢?想象一下,唯一重要的是液压挖掘机,履带−0.0 到 2.0 公吨,其他都不重要。它可以通过首先分割fiProductClassDesc ≤ 5.5然后fiProductClassDesc > 4.5来选择单个元素。只需两次分割,我们就可以提取出一个单一类别。即使是具有分类变量的树也是无限灵活的。如果有一个具有不同价格水平的特定类别,它可以通过多次分割逐渐缩小到这些组。随机森林非常易于使用,而且非常弹性。
下一课,我们将学习如何分析模型,了解更多关于数据的信息,使其变得更好。
机器学习 1:第 3 课
原文:
medium.com/@hiromi_suenaga/machine-learning-1-lesson-3-fa4065d8cb1e译者:飞龙
来自机器学习课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和 Rachel 给了我这个学习的机会。
今天的课程内容:
通过使用机器学习更好地理解数据
- 这个想法与常见的说法相反,即随机森林等东西是隐藏我们意义的黑匣子。事实恰恰相反。随机森林让我们比传统方法更深入更快地理解我们的数据。
如何查看更大的数据集
- 拥有超过 1 亿行的数据集 - 杂货销售预测
问题:何时使用随机森林[2:41]?我无法想到任何绝对不会至少有些用处的情况。因此,值得一试。真正的问题可能是在什么情况下我们应该尝试其他方法,简短的答案是对于非结构化数据(图像,声音等),您几乎肯定要尝试深度学习。对于协同过滤模型(杂货竞赛属于这种类型),随机森林和深度学习方法都不是您想要的,您需要做一些调整。
上周回顾[4:42]
读取 CSV 花了一两分钟,我们将其保存为羽毛格式文件。羽毛格式几乎与 RAM 中的格式相同,因此读写速度非常快。我们在第 2 课笔记本中做的第一件事是读取羽毛格式文件。
proc_df 问题[5:28]
在这一周期间提出的一个有趣的小问题是在proc_df函数中。proc_df函数执行以下操作:
-
查找具有缺失值的数值列,并创建一个额外的布尔列,同时用中位数替换缺失值。
-
将分类对象转换为整数代码。
问题#1:您的测试集中可能有一些列中的缺失值,这些列在训练集中不存在,反之亦然。如果发生这种情况,当您尝试进行随机森林时,您将会出现错误,因为“缺失”布尔列出现在训练集中,但不在测试集中。
问题#2:测试集中数值的中位数可能与训练集不同。因此,它可能将其处理为具有不同语义的内容。
解决方案:现在有一个额外的返回变量nas从proc_df,它是一个字典,其键是具有缺失值的列的名称,字典的值是中位数。可选地,您可以将nas作为参数传递给proc_df,以确保它添加这些特定列并使用这些特定中位数:
df, y, nas = proc_df(df_raw, 'SalePrice', nas)
Corporación Favorita 杂货销售预测[9:25]
让我们走一遍当您处理一个真正大的数据集时的相同过程。几乎相同,但有一些情况下我们不能使用默认值,因为默认值运行速度有点慢。
能够解释您正在处理的问题是很重要的。在机器学习问题中理解的关键事项是:
-
独立变量是什么?
-
什么是因变量(您试图预测的东西)?
在这个比赛中
-
因变量 — 在两周期间每天每个商店销售了多少种产品。
-
自变量 — 过去几年每个产品在每个商店每天销售了多少单位。对于每个商店,它的位置在哪里以及它是什么类型的商店(元数据)。对于每种产品,它是什么类别的产品等。对于每个日期,我们有元数据,比如油价是多少。
这就是我们所说的关系数据集。关系数据集是指我们可以将许多不同信息连接在一起的数据集。具体来说,这种关系数据集是我们所说的“星型模式”,其中有一张中心交易表。在这个比赛中,中心交易表是train.csv,其中包含了按日期、store_nbr和item_nbr销售的数量。通过这个表,我们可以连接各种元数据(因此称为“星型”模式 — 还有一种叫做“雪花”模式)。
读取数据[15:12]
types = { 'id': 'int64', 'item_nbr': 'int32', 'store_nbr': 'int8', 'unit_sales': 'float32', 'onpromotion': 'object' } %%time df_all = pd.read_csv( f'{PATH}train.csv', parse_dates=['date'], dtype=types, infer_datetime_format=True ) ''' CPU times: user 1min 41s, sys: 5.08s, total: 1min 46s Wall time: 1min 48s '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
-
如果设置
low_memory=False,无论您有多少内存,它都会耗尽内存。 -
为了在读取时限制占用的空间量,我们为每个列名创建一个字典,指定该列的数据类型。您可以通过运行或在数据集上使用
less或head来找出数据类型。 -
通过这些调整,我们可以在不到 2 分钟内读取 125,497,040 行数据。
-
Python 本身并不快,但几乎我们在 Python 中进行数据科学时想要做的一切都已经为我们用 C 或更常见的 Cython 编写好了,Cython 是一种类似 Python 的语言,可以编译成 C。在 Pandas 中,很多代码是用汇编语言编写的,这些代码经过了大量优化。在幕后,很多代码都是调用基于 Fortran 的线性代数库。
问题:指定int64与int是否有任何性能考虑[18:33]?这里的关键性能是使用尽可能少的位数来完全表示列。如果我们对item_nbr使用int8,最大的item_nbr大于 255,将无法容纳。另一方面,如果我们对store_nbr使用int64,它使用的位数比必要的多。鉴于这里的整个目的是避免耗尽 RAM,我们不希望使用比必要多 8 倍的内存。当您处理大型数据集时,很多时候最慢的部分是读取和写入 RAM,而不是 CPU 操作。另外,作为一个经验法则,较小的数据类型通常会运行得更快,特别是如果您可以使用单指令多数据(SIMD)矢量化代码,它可以将更多数字打包到一个单独的矢量中一次运行。
问题:我们不再需要对数据进行洗牌了吗[20:11]?尽管在这里我已经读取了整个数据,但当我开始时,我从不会一开始就读取整个数据。通过使用 UNIX 命令shuf,您可以在命令提示符下获取数据的随机样本,然后您可以直接读取该样本。这是一个很好的方法,例如,找出要使用的数据类型 — 读取一个随机样本,让 Pandas 为您找出。通常情况下,我会尽可能多地在样本上工作,直到我确信我理解了样本后才会继续。
要使用shuf从文件中随机选择一行,请使用-n选项。这将限制输出为指定的数量。您还可以指定输出文件:
shuf -n 5 -o sample_training.csv train.csv
'onpromotion': ‘object' [21:28]— object是一个通用的 Python 数据类型,速度慢且占用内存。原因是它是一个布尔值,还有缺失值,所以我们需要在将其转换为布尔值之前处理它,如下所示:
df_all.onpromotion.fillna(False, inplace=True)
df_all.onpromotion = df_all.onpromotion.map({
'False': False,
'True': True
})
df_all.onpromotion = df_all.onpromotion.astype(bool)
%time df_all.to_feather('tmp/raw_groceries')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
fillna(False): 我们不会在没有先检查的情况下这样做,但一些探索性数据分析显示这可能是一个合适的做法(即缺失值表示 false)。 -
map({‘False’: False, ‘True’: True}):object通常读取为字符串,所以用实际的布尔值替换字符串‘True’和‘False’。 -
astype(bool):最后将其转换为布尔类型。 -
拥有超过 1.25 亿条记录的 feather 文件占用了不到 2.5GB 的内存。
-
现在它以一个很好的快速格式,我们可以在不到 5 秒的时间内将它保存为 feather 格式。
Pandas 通常很快,所以你可以在 20 秒内总结所有 1.25 亿条记录的每一列:
%time df_all.describe(include='all')
- 1

-
首先要看的是日期。日期很重要,因为你在实践中放入的任何模型,都会在比你训练的日期晚的某个日期放入。所以如果世界上的任何事情发生变化,你需要知道你的预测准确性也会如何变化。所以对于 Kaggle 或你自己的项目,你应该始终确保你的日期不重叠。
-
在这种情况下,训练集从 2013 年到 2017 年 8 月。
df_test = pd.read_csv(
f'{PATH}test.csv',
parse_dates = ['date'],
dtype=types,
infer_datetime_format=True
)
df_test.onpromotion.fillna(False, inplace=True)
df_test.onpromotion = df_test.onpromotion.map({
'False': False,
'True': True
})
df_test.onpromotion = df_test.onpromotion.astype(bool)
df_test.describe(include='all')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-
在我们的测试集中,它们从第二天开始直到月底。
-
这是一个关键的事情 —— 除非你理解这个基本的部分,否则你无法真正做出任何有用的机器学习。你有四年的数据,你正在尝试预测接下来的两周。在你能够做好这个工作之前,这是你需要理解的基本事情。
-
如果你想使用一个较小的数据集,我们应该使用最近的 —— 而不是随机的集合。
问题:四年前大约在同一时间段重要吗(例如在圣诞节左右)?确实。并不是说四年前没有有用的信息,所以我们不想完全抛弃它。但作为第一步,如果你要提交平均值,你不会提交 2012 年销售额的平均值,而可能想要提交上个月销售额的平均值。之后,我们可能希望更高权重最近的日期,因为它们可能更相关。但我们应该进行大量的探索性数据分析来检查。
df_all.tail()
- 1
这是数据底部的样子。
df_all.unit_sales = np.log1p(np.clip(df_all.unit_sales, 0, None))
- 1
-
我们必须对销售额取对数,因为我们正在尝试预测根据比率变化的某些东西,而他们告诉我们,在这个比赛中,均方根对数误差是他们关心的事情。
-
np.clip(df_all.unit_sales, 0, None): 有一些代表退货的负销售额,组织者告诉我们在这个比赛中将它们视为零。clip截断到指定的最小值和最大值。 -
np.log1p:值加 1 的对数。比赛细节告诉你他们将使用均方根对数加 1 误差,因为 log(0)没有意义。
%time add_datepart(df_all, 'date')
'''
CPU times: user 1min 35s, sys: 16.1 s, total: 1min 51s
Wall time: 1min 53s
'''
- 1
- 2
- 3
- 4
- 5
我们可以像往常一样添加日期部分。这需要几分钟,所以我们应该先在样本上运行所有这些,以确保它有效。一旦你知道一切都是合理的,然后回去在整个集合上运行。
n_valid = len(df_test)
n_trn = len(df_all) - n_valid
train, valid = split_vals(df_all, n_trn)
train.shape, valid.shape
'''
((122126576, 18), (3370464, 18))
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这些代码行与我们在推土机比赛中看到的代码行是相同的。我们不需要运行train_cats或apply_cats,因为所有的数据类型已经是数字的了(记住apply_cats将相同的分类代码应用于验证集和训练集)。
%%time
trn, y, nas = proc_df(train, 'unit_sales')
val, y_val, nas = proc_df(valid, 'unit_sales', nas)
- 1
- 2
- 3
调用proc_df来检查缺失值等。
def rmse(x,y):
return math.sqrt(((x-y)**2).mean())
def print_score(m):
res = [
rmse(m.predict(X_train), y_train),
rmse(m.predict(X_valid), y_valid),
m.score(X_train, y_train),
m.score(X_valid, y_valid)
]
if hasattr(m, 'oob_score_'):
res.append(m.oob_score_)
print(res)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这些代码行再次是相同的。然后有两个变化:
set_rf_samples(1_000_000)
%time x = np.array(trn, dtype=np.float32)
'''
CPU times: user 1min 17s, sys: 18.9 s, total: 1min 36s
Wall time: 1min 37s
'''
m = RandomForestRegressor(
n_estimators=20,
min_samples_leaf=100,
n_jobs=8
)
%time m.fit(x, y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们上周学习了set_rf_samples。我们可能不想从 1.25 亿条记录中创建一棵树(不确定需要多长时间)。你可以从 10k 或 100k 开始,然后找出你可以运行多少。数据集的大小与构建随机森林所需时间之间没有关系,关系在于估计器数量乘以样本大小。
问题: n_job是什么?过去,它总是-1[29:42]。作业数是要使用的核心数。我在一台大约有 60 个核心的计算机上运行这个,如果你尝试使用所有核心,它会花费很多时间来启动作业,速度会变慢。如果你的计算机有很多核心,有时你想要更少(-1表示使用每个核心)。
另一个变化是x = np.array(trn, dtype=np.float32)。这将数据框转换为浮点数组,然后我们在其上进行拟合。在随机森林代码内部,他们无论如何都会这样做。鉴于我们想要运行几个不同的随机森林,使用几种不同的超参数,自己做一次可以节省 1 分 37 秒。
分析器:%prun[30:40]
如果你运行一行需要很长时间的代码,你可以在前面加上%prun。
%prun m.fit(x, y)
- 1
-
这将运行一个分析器,并告诉你哪些代码行花费了最多的时间。这里是 scikit-learn 中将数据框转换为 numpy 数组的代码行。
-
查看哪些事情占用了时间被称为“分析”,在软件工程中是最重要的工具之一。但数据科学家往往低估了它。
-
有趣的是,尝试不时运行
%prun在需要 10-20 秒的代码上,看看你是否能学会解释和使用分析器输出。 -
Jeremy 在分析器中注意到的另一件事是,当我们使用
set_rf_samples时,我们不能使用 OOB 分数,因为如果这样做,它将使用其他 124 百万行来计算 OOB 分数。此外,我们希望使用最近日期的验证集,而不是随机的。
print_score(m)
'''
[0.7726754289860, 0.7658818632043, 0.23234198105350, 0.2193243264]
'''
- 1
- 2
- 3
- 4
所以这让我们得到了 0.76 的验证均方根对数误差。
m = RandomForestRegressor(
n_estimators=20,
min_samples_leaf=10,
n_jobs=8
)
%time m.fit(x, y)
- 1
- 2
- 3
- 4
- 5
- 6
这使我们降到了 0.71,尽管花了更长的时间。
m = RandomForestRegressor(
n_estimators=20,
min_samples_leaf=3,
n_jobs=8
)
%time m.fit(x, y)
- 1
- 2
- 3
- 4
- 5
- 6
这将错误降低到 0.70。min_samples_leaf=1并没有真正帮助。所以我们在这里有一个“合理”的随机森林。但是这在排行榜上并没有取得好的结果[33:42]。为什么?让我们回头看看数据:

这些是我们必须用来预测的列(以及由add_datepart添加的内容)。关于明天预计销售多少的大部分见解可能都包含在关于商店位置、商店通常销售的物品种类以及给定物品的类别是什么的细节中。随机森林除了在诸如星期几、商店编号、物品编号等方面创建二元分割之外,没有其他能力。它不知道物品类型或商店位置。由于它理解正在发生的事情的能力有限,我们可能需要使用整整 4 年的数据才能得到一些有用的见解。但是一旦我们开始使用整整 4 年的数据,我们使用的数据中有很多是非常陈旧的。有一个 Kaggle 内核指出,你可以做的是[35:54]:
-
看看最后两周。
-
按商店编号、物品编号、促销情况的平均销售额,然后跨日期取平均。
-
只需提交,你就能排在第 30 名左右
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/77987
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

