
利用生成式 AI 技术构建结构化信息提取任务的应用与实践
赞
踩

背景
在如今生成式 AI 变革的时代浪潮下,大语言模型(LLM)已经深刻影响了信息处理。信息的提取和处理工作已从原来匹配规则或依靠人工操作,转变为可以由 LLM 对文本数据进行处理,同时也可以通过构建训练数据集对模型进行微调来进一步提升大语言模型对下游特定任务的准确性。这一变化的原因在于:
LLM 拥有大量预训练的知识背景,以及超强的语义理解能力,可以精确匹配文本中的信息,进行信息抓取和组织。
LLM 强大的能力减轻了对文本处理和理解的模型定制需要,通过有序调用 LLM,可以在很短的时间内完成大规模的信息抽取任务,实现对海量文本的高效信息处理和提取。
应用场景
假设我们的使用场景是从海量的 HTML 网页文件中提取有价值的内容,保存成结构化信息,以方便后续的统计与分析。这类应用场景通常具有以下特点:
数据量庞大
数据需要进行预处理
数据提取复杂,可能需要解析 HTML
需要兼容不同的数据格式
在这种场景下,由于数据量庞大、格式复杂,如果采用传统的人工处理或定制化程序的方法,需要投入大量的时间和成本。利用大语言模型 LLM 的能力实现自动化信息抽取,通过 LLM 强大的自然语言理解和总结能力,可以实现对海量文本的高效信息处理。
我们以一篇亚马逊云科技官方博客为例,目标是提取文章中 Amazon EC2 实例的相关信息,如实例类型、CPU 型号等信息。


亚马逊云科技官方博客
扫码了解更多
由此示例可见,我们需要提取的内容分布在文章标题和段落中,且没有标准格式。必须通过语义理解的方式对其进行分析之后才能进行信息提取。针对数据源复杂、数据结构复杂、语义复杂的这种场景,我们接下来的步骤需要:
01
数据预处理,减少对 LLM 的干扰,进行必要的清洗,以提取出文本的核心内容。
02
将文本输入 LLM 进行针对性的内容提取。利用 LLM 强大的语义理解能力,分析文本中的语义关系,提取出所需的关键信息。
03
对提取结果进行过滤和整理,生成最后的结构化数据,进行存储。
04
根据实际需求,迭代优化 LLM 的提取策略,以提高提取精度。
05
构建信息提取的管道系统,实现大规模自动化处理。
本文通过结合工作流编排和大语言模型(LLM)的方法, 高效地从复杂语义文本中提取结构化信息,大幅降低手工处理的工作量,实现自动化信息提取。
解决方案概述
在生成式 AI 应用中,LLM 模型只是冰山一角,本文所描述的场景需要实现批量推理并从大量文本中提取结构化信息进行存储,如果需要构建端到端的应用,还有很多工程化的问题需要考虑。比如我们需要提供安全的调用接口、创建编排任务执行高效可扩展的批量推理任务、以弹性可扩展的方式部署大语言模型的算力资源,以及考虑如何减轻后期运维的复杂度和成本。云平台本身提供了各类托管服务,无疑是我们实现类似方案的不二之选,以下根据本文的需求实现的一套基于亚马逊云科技平台的无服务器(Serverless)部署架构。
架构图
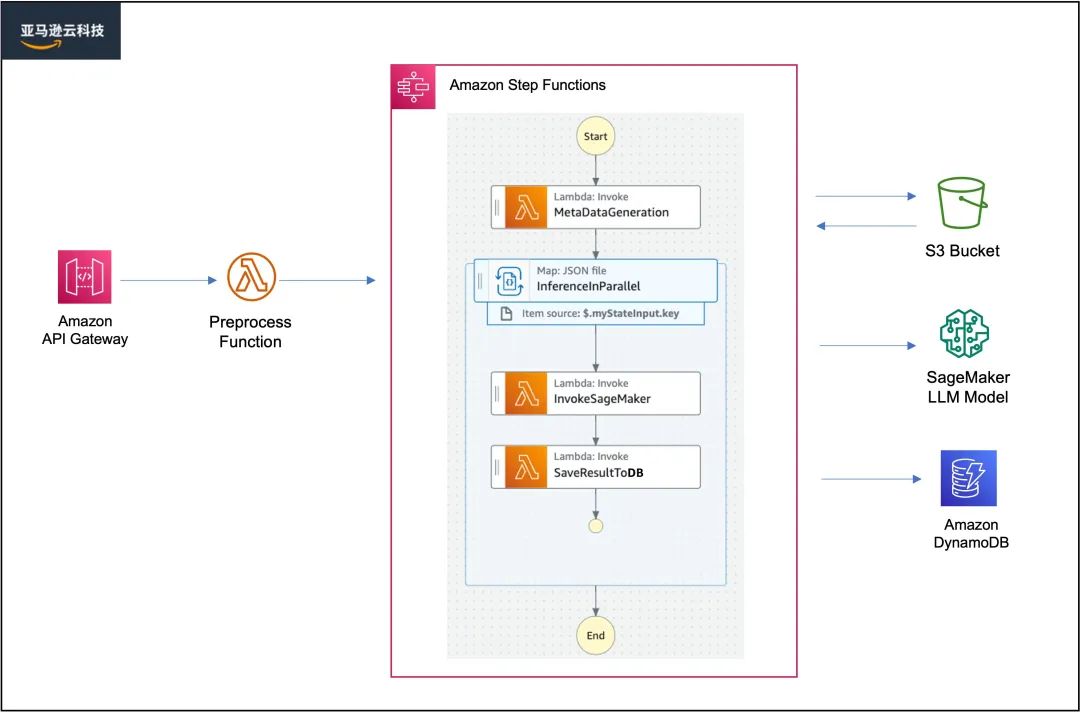
上述架构图中用到的主要云服务和承担的作用如下:
Amazon API Gateway 是一项完全托管的 API 网关服务,本身支持多种身份验证方式,用于提供安全的网关接口,可以和亚马逊云科技内部服务和外部系统进行无缝集成。在这个方案里,API Gateway 承担着对外触发访问的功能,用户可以根据这个 API 进行工作流的触发。
Amazon Lambda 是一项无服务器计算服务,用户无需配置或管理服务器即可运行基于各种开发语言代码。在此方案中,它负责了大部分的核心任务,在触发批量信息提取任务前,我们可以在 Preprocess Funcation 中自定义一些预处理逻辑或者进行调用前的状态检查等。同时在后续的任务编排中,Amazon Lambda 负责实现核心的原子化操作,如调用 LLM 进行推理,以及将推理结果保存在数据库等。
Amazon S3 是一项安全可靠且可扩展的文件存储服务,具备极高的吞吐量,本方案中,S3 用于存储待处理和推理的海量 HTML 文件。
Amazon SageMaker 是面向所有数据科学家和开发人员的托管的机器学习服务。在此方案中我们使用 Amazon SageMaker 部署 LLM 推理端点,支持弹性 GPU 扩展。后续也可以用 Amazon SageMaker 所提供的 Notebook 实例或者模型训练任务等功能进行模型的调优。本方案中 SageMaker 用于托管 LLM 模型服务。
Amazon DynamoDB 是一项快速灵活的,无服务器 NoSQL 数据库,本方案中 DDB 用于保存从 HTML 文件中提取的结构化信息。
Amazon Step Functions 是一项可视化的无服务器任务编排服务,帮助用户以声明性方式定义和协调多个任务,构建具有状态管理和错误处理的工作流,本方案使用三个 Lambda 组成 Step function 工作流,实现如下的自动化流程。构建基于 Amazon Lambda 的 Step Functions 工作流耗时短,灵活度高,减少运维,对后续流程的搭建修改都很方便。其中使用 Map state 可以帮助我们实现分布式计算,在本方案中,Map state 使用 JSON file 作为输入类型进行任务分发。
MetaDataGeneration 函数负责收集 Amazon S3 中待处理的文件对象信息,生成 JSON file,传递给 Step Function 下一步的 Map state。
Map state 负责实现并发文本信息提取任务,对于单个 HTML 文件的处理逻辑主要包括两个 Lambda 函数。
InvokeSageMaker 函数负责将 Amazon S3 上的文件下载到 Lambda 本地存储,进行数据预处理后,调用 LLM 推理端点,提取结构化信息。
SaveResultToDB 函数负责将最终的结果保存在 Amazon DynamoDB 数据库。
接下来我们将继续介绍基于上述方案进行实施的过程中,需要关注的相关技术点。
数据预处理
考虑到大语言模型一般对输入文本(token)有长度限制,同时文件中的 HTML 标签所包含的信息也会造成输入的冗余,甚至会对推理性能造成干扰。因此通常需要在推理前对网页源内容进行处理,整体思路是过滤掉和待提取内容无关的 HTML 标签和标签下所包含的信息等,如果过滤后的内容还是超过了所选用模型的 token 最大长度限制,后续还需要进行更多的工程化处理,如采用类似 MapReduce 等方法对大文本进行分片推理再进行合并等。
我们还以上面提到的博客为例,这里我们简单用 Beautiful Soup 对原始网页进行内容过滤,其中 Beautiful Soup 是一个可以轻松从网页中抓取信息的 Python 库。

Beautiful Soup
扫码了解更多
代码示例:过滤掉全部的 HTML 标签,获取网页中的纯文字内容
- from bs4 import BeautifulSoup
-
-
- with open('demo.html','r') as file:
- html_raw = file.read()
- soup = BeautifulSoup(html_raw, "html.parser")
- html_content = soup.get_text()
- html_content = html_content.replace("\n", "")
- print(html_content)
- file.close()
输出结果
全新 Amazon EC2 R7iz 实例针对高 CPU 性能、内存密集型工作负载进行了优化 | 亚马逊AWS官方博客 Skip to Main Content单击此处以返回 Amazon Web Services 主页联系我们 支持 中文(简体) 我的账户 登录 创建 AWS 账户 产品解决方案定价文档了解合作伙伴网络AWS Marketplace客户支持活动探索更多信息 关闭 日本語한국어中文 (简体)中文 (繁體) 关闭 我的配置文件注销 AWS Builder IDAWS 管理控制台账户设置账单与成本管理安全证书AWS Personal Health Dashboard 关闭 支持中心专家帮助知识中心AWS Support 概述AWS re:Post单击此处以返回 Amazon Web Services 主页 免费试用 联系我们 产品 解决方案 定价 AWS 简介 入门 文档 培训和认证 开发人员中心 客户成功案例 合作伙伴网络 AWS Marketplace 支持 AWS re:Post 登录控制台 下载移动应用 博客主页 版本 关闭 中国版日本版한국 에디션기술 블로그Edisi Bahasa IndonesiaAWS 泰语博客Édition FrançaiseDeutsche EditionEdição em PortuguêsEdición en EspañolВерсия на русскомTürkçe Sürüm亚马逊AWS官方博客全新 Amazon EC2 R7iz 实例针对高 CPU 性能、内存密集型工作负载进行了优化 by Veliswa Boya | on 11 9月 2023 | in Compute | Permalink | Share 今天,我们宣布 Amazon EC2 R7iz 实例正式上市。R7iz 实例是云中速度最快的基于第四代 Intel Xeon 可扩展(Sapphire Rapids)的实例,具有 3.9 GHz 持续全核睿频频率。R7iz 实例适用于需要更多内存来处理额外数据、需要更大的实例大小来纵向扩展、需要更高的计算和内存性能来缩短完成时间,以及需要更高的网络和 Amazon Elastic Block Store(Amazon EBS)性能来缩短延迟的工作负载。R7iz 实例的高计算性能与大量内存相结合,可提高应用程序的整体性能,包括前端电子设计自动化(EDA)、单位内核许可费用较高的关系数据库工作负载以及财务、精算和数据分析模拟工作负载。这可以帮助您加快产品开发的上市速度,同时降低许可成本。R7iz 实例R7iz 实例的规格如下...LLM部署
本方案目前采用私有化部署 LLM 的方式将模型部署至 VPC 私有环境的 Amazon SageMaker 中,模型选择的是 baichuan2-7b-chat。

Hugging Face
扫码了解更多

baichuan2-7b-chat
参考部署脚本
扫码了解更多
同样我们也可以采用模型及服务的方式(MaaS)来使用 Amazon Bedrock。Amazon Bedrock 是一项完全托管的服务,通过单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先人工智能公司的高性能基础模型(FM),以及通过安全性、隐私性和负责任的 AI 构建生成式人工智能应用程序所需的一系列广泛功能。
LLM提示词
提示工程(Prompt Engineering)是一个较新的学科,应用于开发和优化提示词(Prompt),帮助用户有效地将语言模型用于各种应用场景和研究领域。掌握了提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。研究人员可利用提示工程来提高大语言模型处理复杂任务场景的能力,如问答和算术推理能力。开发人员可通过提示工程设计和研发出强大的技术,实现和大语言模型或其他生态工具的高效接轨。
提示词可以包含以下任意要素:
指令:想要模型执行的特定任务或指令。
上下文:包含外部信息或额外的上下文信息,引导语言模型更好地响应。
输入数据:用户输入的内容或问题。
输出指示:指定输出的类型或格式。
注意,提示词所需的格式取决于您想要语言模型完成的任务类型,并非所有以上要素都是必须的。
提示工程(Prompt Engineering)的类别包含零样本提示、单样本提示、少样本提示、链式思考提示、思维树、检索增强生成、自动推理并使用工具(ART)等等。不同 LLM 所适合的 PE 会略有不同,本场景以 baichuan2-7b-chat 为例,在信息提取场景下我们的 PE 为:
- 你是一名 Amazon EC2 的专家,请从以下内容中提取 EC2 实例,处理器,睿频这三种信息
- <网页内容>
- 将输出结果格式化成 JSON,包含以下 key
- instance_family
- processor_type
- turbo_boost_frenquency
在上述 PE 中,“你是一名 Amazon EC2 的专家,请从以下内容中提取 EC2 实例,处理器,睿频这三种信息” 为指令;<网页内容>为上下文;“将输出结果格式化成 JSON,包含以下 key”为输出提示,输出提示中明确了我们需要提取的内容和输出的格式要求。
将本文在上一步骤中过滤后的网页文字信息作为 Prompt 上下文的一部分进行输入 填充在<网页内容>中,从而得到我们想要的关键信息,并按照 JSON 的格式输出。如下是我们得到的 LLM 输出结果。
- {
- "instance_family": "R7iz",
- "processor_type": "Intel Xeon",
- "turbo_boost_frequency": 3.9
- }
模型微调
模型微调技术在一定程度上可以提升大语言模型对特定任务的推理性能,使得在特定任务下,推理结果以及模型输出格式更精确。如本文描述的信息提取类任务,可以通过对预训练模型(Foundation Model)进行微调,使得微调后的模型对此任务更加聚焦。通常进行模型微调主要包含三个主要步骤:训练数据清洗、模型训练以及模型评估。其中模型训练有非常多的方案和训练框架,这里我们用开源模型训练框架 LLaMA-Factory 举例说明如何对信息提取任务进行微调。
1.数据清洗打标,构建训练数据集
针对网页信息提取任务,对训练数据进行清洗打标,处理后的数据集需要包含以下三个条目:
instruction:用户指令,即 Prompt
input:经过处理过滤后的网页原始内容
output:期望提取的信息和输出格式,如 JSON
- [
- {
- "instruction": "traning prompt",
- "input": "html content 1",
- "output": "{'key1': 'value1', 'key2': 'value2', 'key3': 'value3'}"
- },
- {
- "instruction": "traning prompt",
- "input": "html content 2",
- "output": "{'key1': 'value4', 'key2': 'value5', 'key3': 'value6'}"
- }
- ]
2.对预训练模型进行有监督微调(SFT)
LLaMA-Factory 是开源大模型训练框架,它集成了业界最广泛使用的微调方法和优化技术,并支持业界众多的开源模型的微调和二次训练(如开源大语言模型 Baichuan、ChatGLM 等) 。本文不过多赘述各种大语言模型训练框架的原理及实现,有兴趣的读者可以参考 LLaMA-Factory 项目地址。

LLaMA-Factory
扫码了解更多
此外为了在有限的 GPU 资源下提升训练效率,可以结合 LoRA 等高效微调技术以及分布式训练框架 DeepSpeed 实现对特定任务的微调。最后将 LoRA 的权重(Weights)合并到原始模型并导出:
参考命令:
- python src/export_model.py \
- --model_name_or_path path_to_llama_model \
- --adapter_name_or_path path_to_checkpoint \
- --template default \
- --finetuning_type lora \
- --export_dir path_to_export \
- --export_size 2 \
- --export_legacy_format False
总结
生成式 AI 技术日新月异,各行各业已经开始尝试利用大语言模型的能力,实现各种业务场景。无论是哪种场景,我们都需要合理的评估和使用各类模型。同时如本文所提到的观点,创建生成式 AI 应用所需要的不仅仅是大语言模型,我们还需要全方位地考虑各种因素,例如:
模型选择
不同的 LLM 模型针对不同的下游任务通常有性能差异,建议针对实际的业务场景进行测试,选择最优的模型至关重要,甚至在某些业务场景中我们需要选择多个模型相互配合,从而实现最优效果。
信息安全
在调用模型时,通常会将一些信息作为 Prompt 传给 LLM,需要对应用场景以及数据进行分级分类,对于敏感的数据,建议使用 Amazon SageMaker 对部署进行私有化模型,或者使用 Amazon Bedrock 保护数据的安全。
运维效率
在调用模型时,通常会将一些信息作为 Prompt 传给 LLM,需要对应用场景以及数据进行分级分类,对于敏感的数据,建议使用 Amazon SageMaker 对部署进行私有化模型,或者使用 Amazon Bedrock 保护数据的安全。
算力扩张
构建生成式 AI 应用,通常需要使用到 GPU 算力,此外以信息提取场景为例,我们还需要其他算力进行推理的前置和后置处理,当待处理的文件数据巨大时,本方案采用 Amazon Lambda 和 Amazon SageMaker 作为核心服务,能够很好的支持算力的弹性扩展。
本篇作者

孙大木
亚马逊云科技资深解决方案架构师,负责基于亚马逊云科技方案架构的咨询和设计,在国内推广亚马逊云科技云平台技术和各种解决方案。

原媛
亚马逊云科技解决方案架构师,负责基于亚马逊云科技方案的架构咨询和设计实现,具有丰富的解决客户实际问题的经验,同时热衷于时间序列数据分析的相关研究与应用。

肖冰
亚马逊云科技解决方案架构师,负责基于亚马逊云科技方案的咨询与架构设计。在应用现代化改造,Serverless,云迁移,大数据等方向具有丰富的实践经验。在加入亚马逊云科技之前,曾就职于 EMC、微软,西云数据、腾讯等科技公司,拥有丰富的公有云领域的架构优化和技术支持经验。

听说,点完下面4个按钮
就不会碰到bug了!


