
- 12024年计算机网络与互联网技术国际会议(ICCNIT 2024)_iccnit官网
- 2Mybatis的特性详解——四大操作标签_mybatis insert select
- 3【RK3568】编译error记录_rk3568 error:no found parameter!
- 4Python桌面应用程序的布局和设计_python桌面系统
- 5docker拉取镜像的时候超时_docker拉取镜像超时
- 6Python 安装 Selenium 报错解决方案:全方位排错指南_安装selenium报错
- 7python每日一题——16除自身以外数组的乘积_python 除自身以外数组的乘积
- 8rsa加密算法详解_rsa加密算法详细步骤
- 9能把进程和线程讲的这么透彻的,没有20年功夫还真不行【0基础也能看懂】
- 10软件测试工程师面试——接口测试话术_测试工程师常用话术
大数据图书数据分析
赞
踩
1.项目简介
1.1项目背景
随着人们生活水平的提高和消费观念的更新,图书市场需求不断发生变化,出现了需求多样化的趋势。近年来,我国网民网上读书率正在迅速增长,上网阅读率平均每年增长10%。纸质阅读力虽然在下降,但是传统的纸质图书阅读在相当长的时间内仍将占据重要地位。纸质阅读面临许多挑战,如新媒体对传统纸质媒体市场进行瓜分、中国出版业创新不足和纸质图书价格过高等问题。针对如下现象,本文主要针对主要文学类纸质图书价格、销量、折扣等研究其之间的相互关系,旨在找到一个合适的价格区间,让商家和读者都能接受的纸质图书价格,以此来提高商家的销量和读者的购买量,让二者均从此获益。
1.2项目功能
(1)后裔采集器获取当当网图书数据
(2) Python数据预处理
(3)数据上传Hive
(4)Hive数据分析
(5)MapperReduce数据分析
(6)Python数据可视化分析
1.3运行环境
(1)操作系统:Linux(Ubuntu16.04);
(2) MySQL版本:5.7.16;
(3)Hadoop版本:2.7.1;
(4)HBase版本:1.1.5;
(5)Hive版本:1.2.1;
(6)Sqoop版本:1.4.6;
(7)Eclipse版本:3.8。
2.数据集与数据预处理
2.1数据集
(1)数据来源
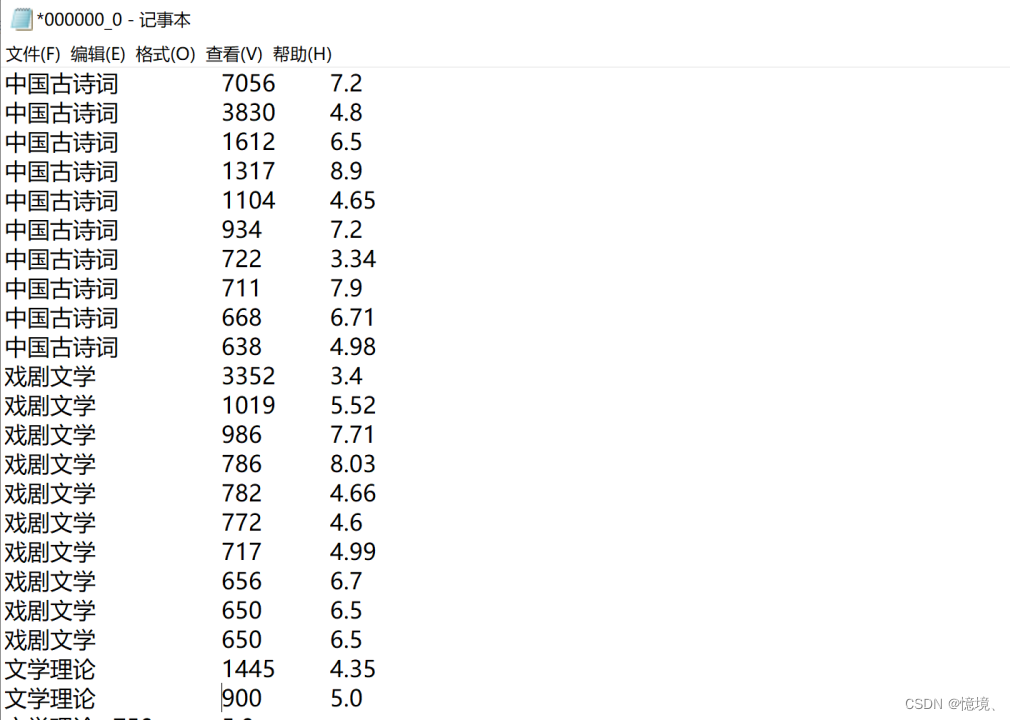
本项目数据收集文学类图书中戏剧文学、文学理论、纪实文学、中国古诗词、民间文学共5中类型的书籍,每类6000行数据,一共30000万行数据。
(2)采集数据包涵数据类型
| 字段名称 | 字段说明 | 字段类型 |
| name | 书名 | String |
| price | 价格 | Int |
| author | 作者 | String |
| evaluate | 评价数量 | Int |
| publish_time | 出版时间 | String |
| discount | 折扣 | Float |
| publish | 出版社 | String |
| type | 类型 | String |
(3)前20行数据查询(由于书名太长,所以这里暂不显示)

2.2数据预处理
2.2.1 Python数据预处理
对出版时间(publish_time)和出版社(publish)字符串进行提取,删除特殊字符“/”;在书名(name)因为太长,不适合观察数据,所以只截取了前面5个字符;在末尾增加1列数量(number),均赋值为1,表示每种图书被出版了1次;对评价数量(evaluate)在采集数据时通过观察发现,当该书籍没有评价时,采集到对书籍为空值,所以对所有评价数量为空值的赋值为0;最后对所有存在空值所在的行进行删除操作。Python预处理之后的数据一共有24028行,前20行数据
Python预处理之后数据类型
| 字段名称 | 字段说明 | 字段类型 |
| name | 书名 | String |
| price | 价格 | Int |
| author | 作者 | String |
| evaluate | 评价数量 | Int |
| publish_time | 出版时间 | String |
| discount | 折扣 | Float |
| publish | 出版社 | String |
| type | 类型 | String |
| number | 数量 | Int |
2.2.2 AWK数据预处理
(1)删除列名
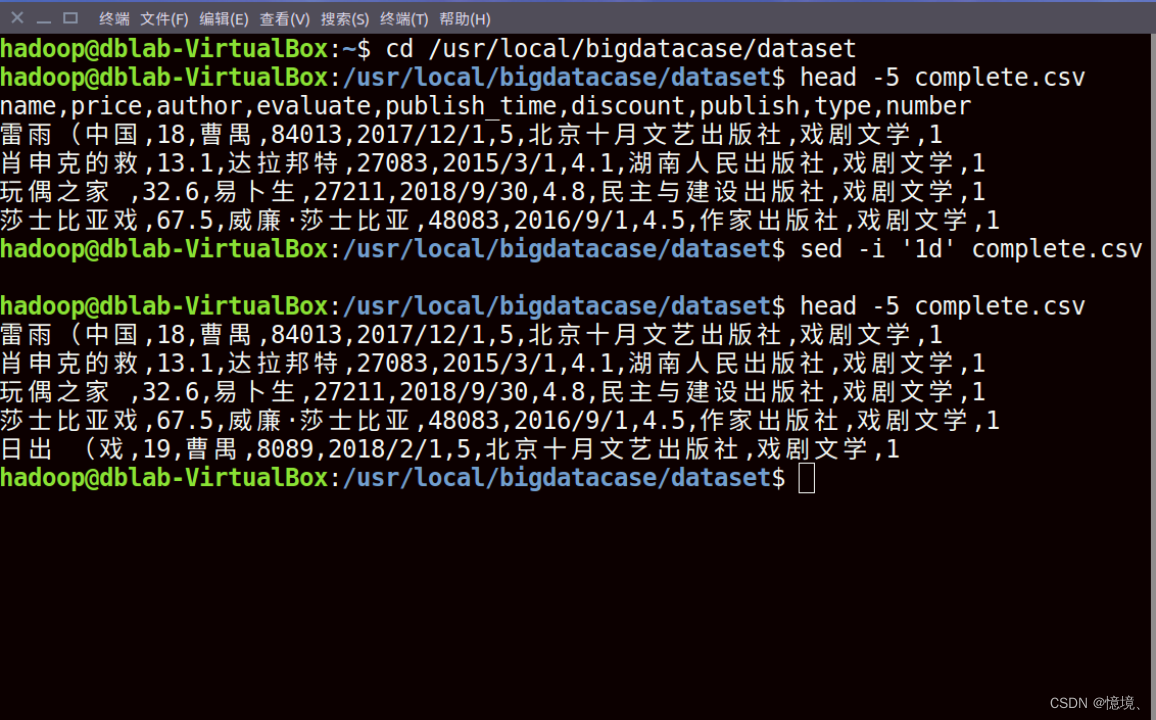
(2)对字段预处理
对每一行数据从1到n自增一个id值,便于区分数据 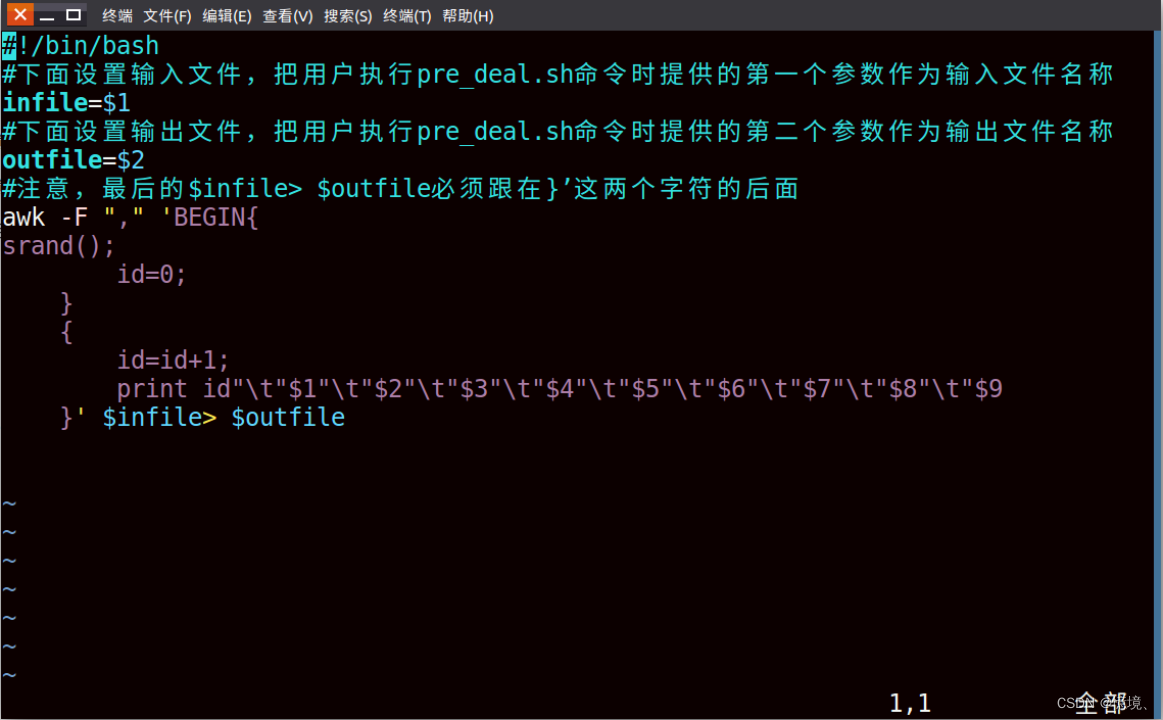
(3)预处理结果
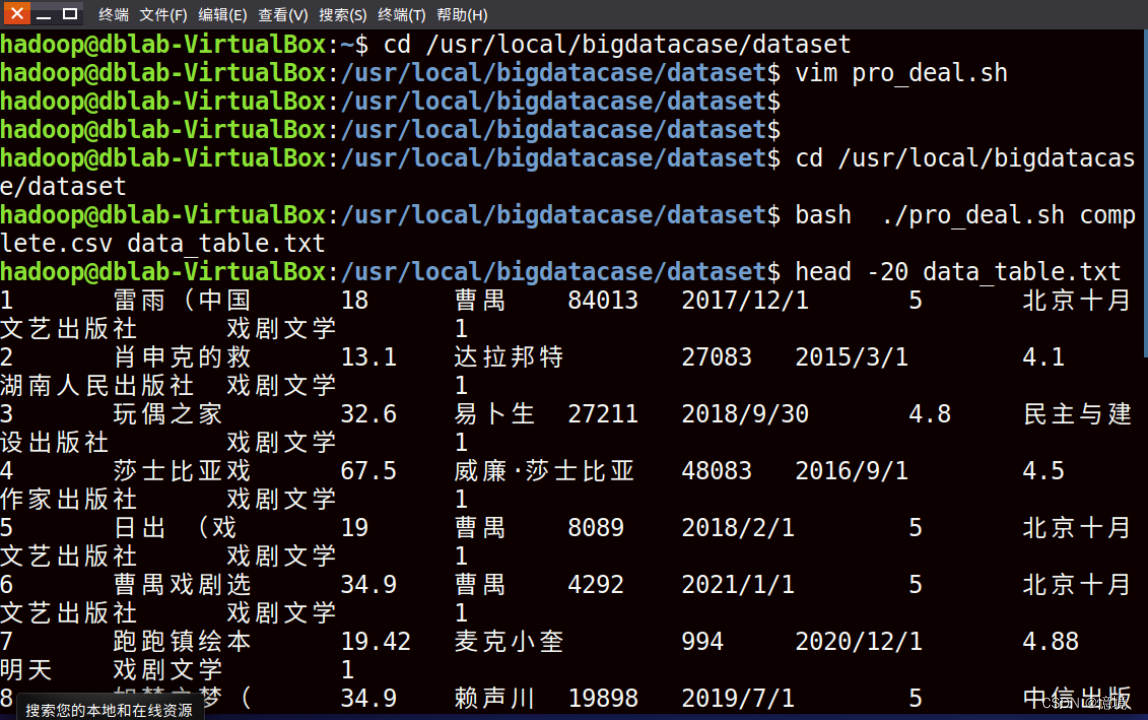
(4)Hive预处理之后数据类型为
| 字段名称 | 字段说明 | 字段类型 |
| id | 编号 | Int |
| name | 书名 | String |
| price | 价格 | Int |
| author | 作者 | String |
| evaluate | 评价数量 | Int |
| publish_time | 出版时间 | String |
| discount | 折扣 | Float |
| publish | 出版社 | String |
| type | 类型 | String |
| number | 数量 | Int |
2.3数据上传
(1)数据上传HDFS并查看前10行数据

(2)Hive新建数据库和外部表
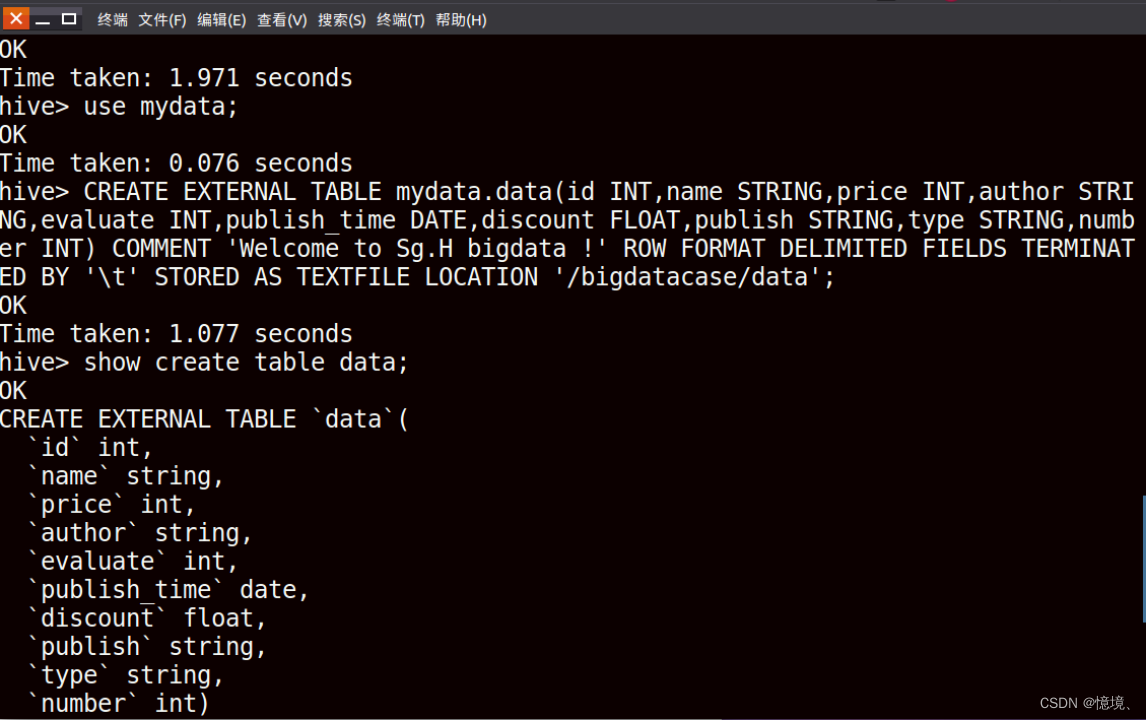
(3)查看Hive外部表中前10行数据

3.MapperReduce数据分析
本章节所有MapperReduce文件均存放在MapperReduce工程文件夹下,包ch3_1 - ch3_10分别是下面3.1-3.10MapperReduce数据分析的源代码
3.1 五种类型图书的数据量
(1)分析
统计收集的5类数据,观察这5类数据分别有多少行,因为我们是要对比这5种不同类型的图书,所以我们最终预处理后的各种类型书籍的数量如果数量相差太多,会对我们的结果有较大的影响,当然最好的情况下5中类型书籍的数据量刚好相对,这样使我们的分析更加准确。
(2)重要代码代码和运行情况

(3)文件输出结果
3.2 五种类型图书的比例
(1)分析
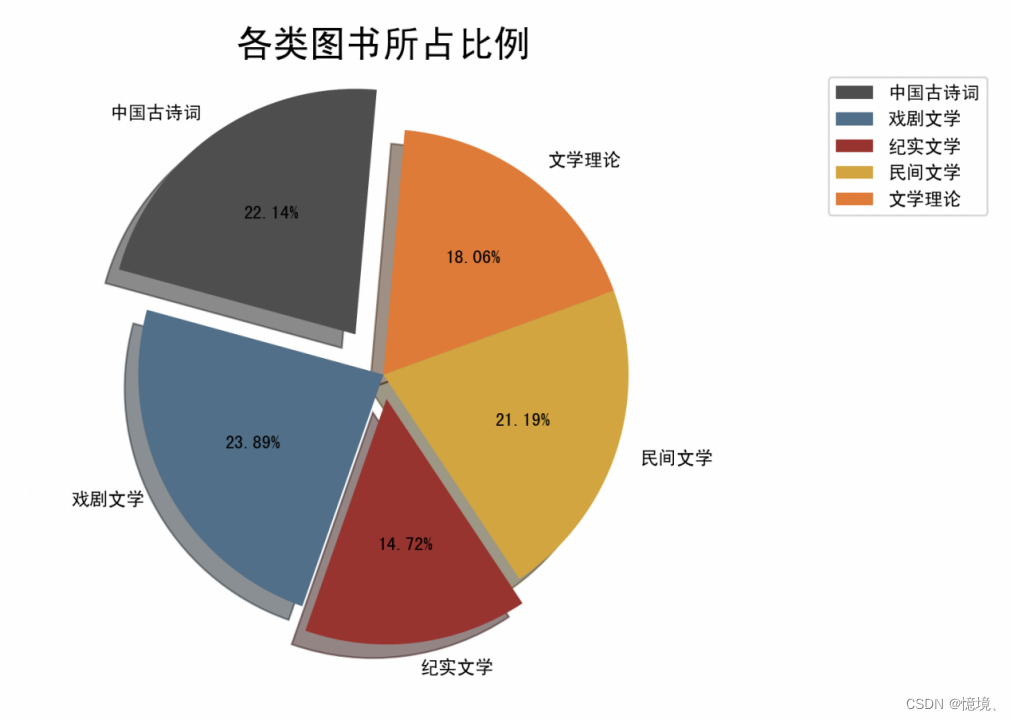
统计5种类型数据相对的比例,通过对比,发现5中类型的数据比例基本均为20%左右,说明收集的各种类型收集的数据量基本相同,在后续的分析过程中,我们的分析结果将会更为准确。
(2)重要代码和运行情况

(3)文件输出结果

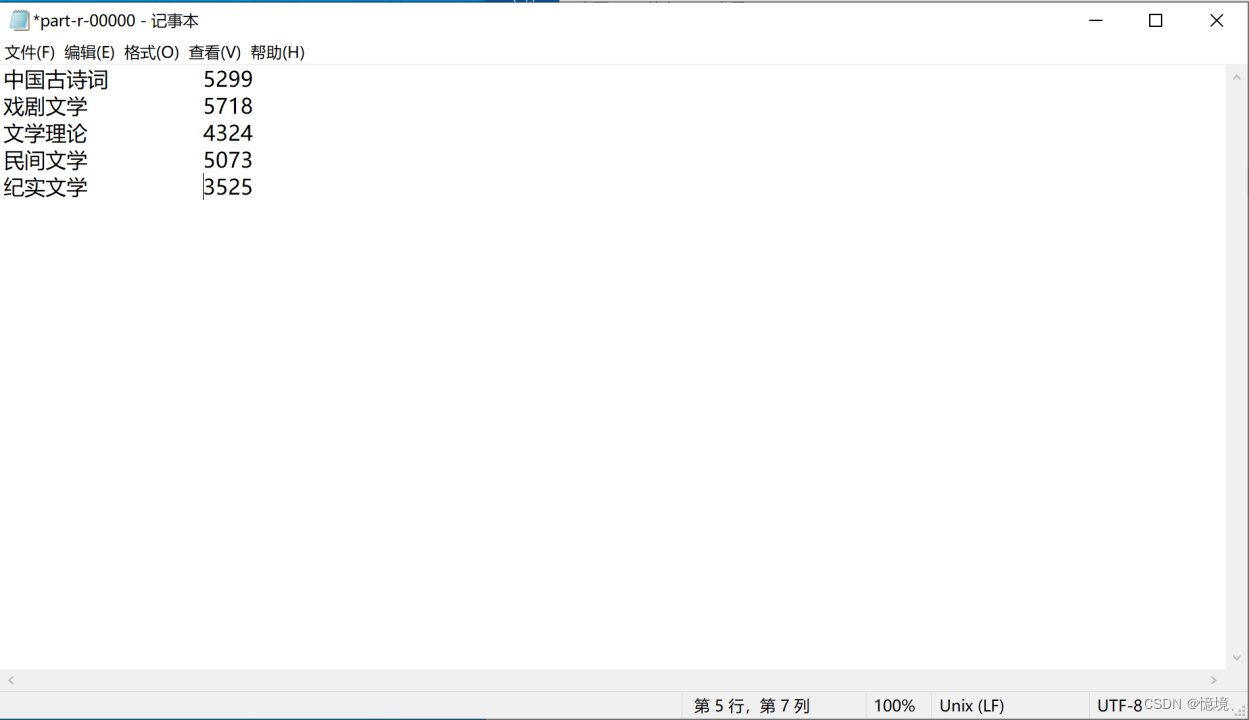
3.3 五种类型的书籍被多少家出版社出版
(1)分析
对每一类书籍,可能同时被多家出版社出版;一家出版社,可能也出版了大量同类型书籍。一类书籍被更少的出版社出版,说明同有较多出版社出版了大量同类型书籍,说明这类书籍的读者和作者会比较多。所以,可以稍微提高文学理论类书籍出版量,而戏剧文学则应该少量出版。
(2)重要代码和运行情况
(3)文件输出结果
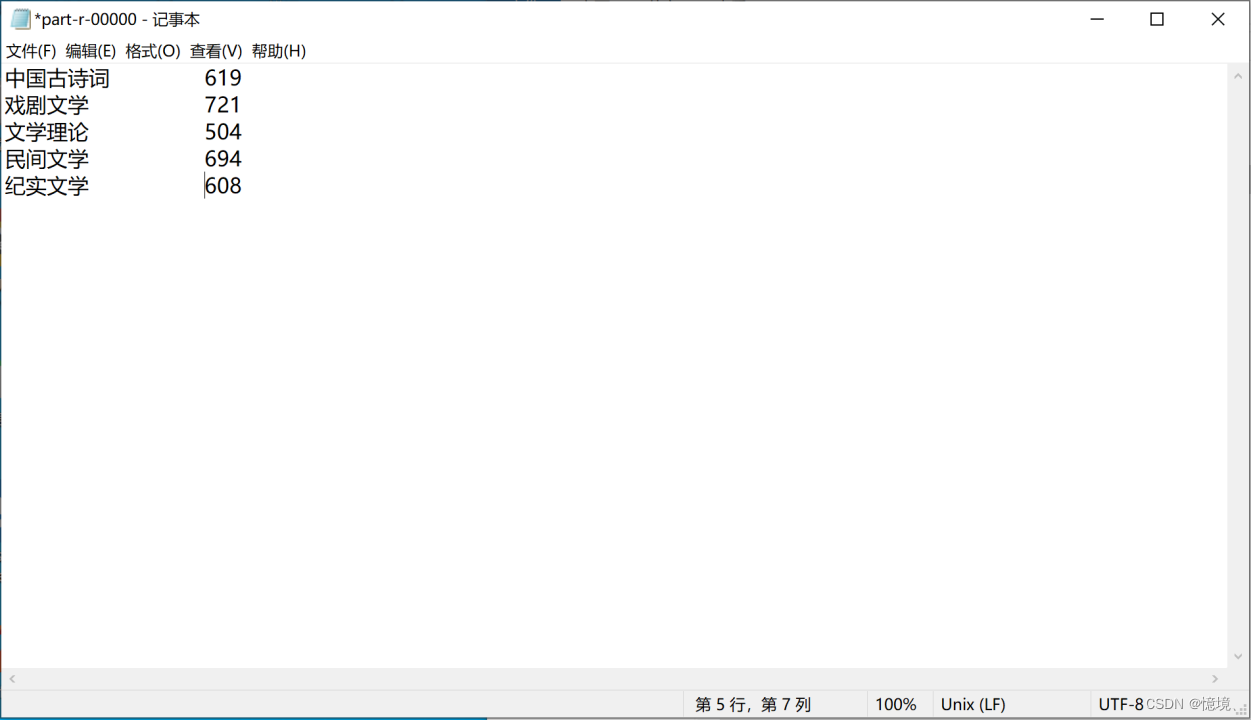
3.4 不同类型的书籍的出版年份和出版社
(1)分析
对于不同书籍,被出版的时间不一样,通过MapperReduce输出结果,不难发现,大多数出版社大多在2000年以后开始大量出版书籍,而在2000年以前,出版社出版书籍数量非常少,说明当今社会文化教育事业非常繁荣,教育发展相对于20年前有了巨大的进步,文化事业的发展欣欣向荣。
(2)重要代码和运行情况

(3)文件输出结果
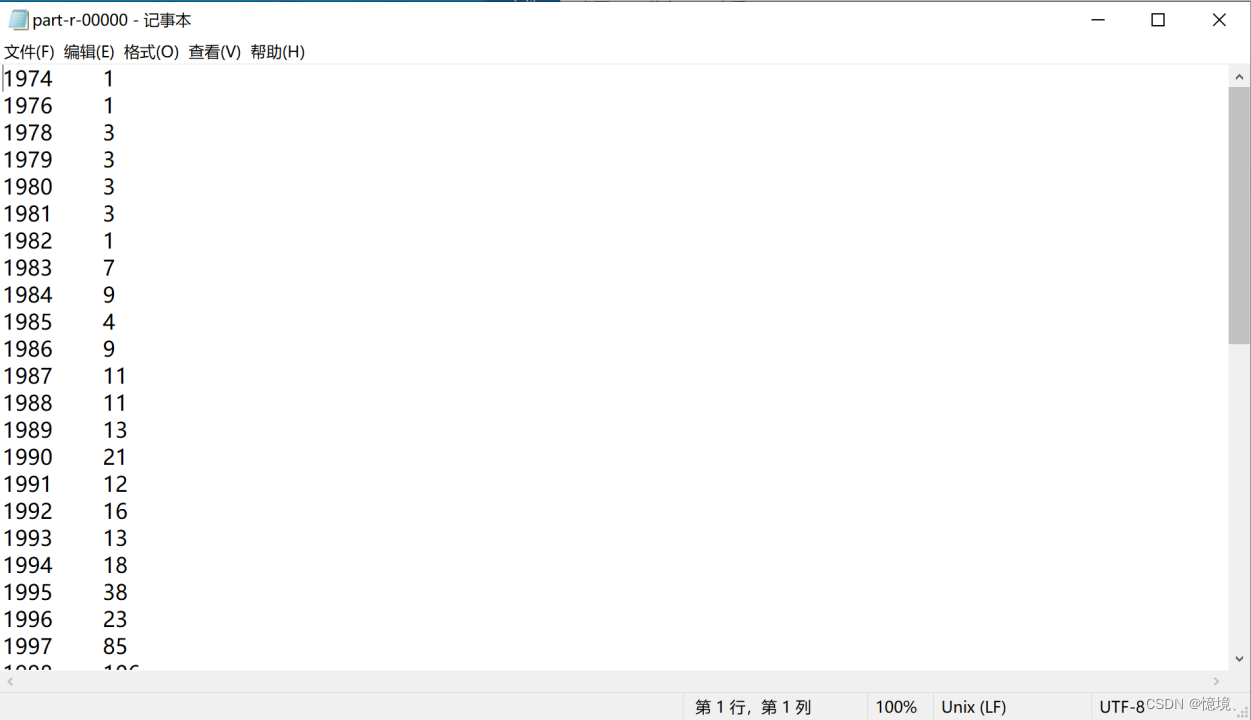
3.5 每年每种类型书籍的出版数量
(1)分析
分析自1974年以来,每年各种类型书籍出版数量的变化,通过观察对比,找出哪一种类型的书籍对读者和作者更有吸引力。
(2)重要代码和运行情况
(3)文件输出结果

3.6 每年书籍的最低和最高价格
(1)分析
通过每年书籍最低价格和最高价格的对比变化,我们可以预测未来图书价格的变化,比如。随着信息化社会的发展,教育越来越普及,人们生活越来越富裕,价格将不再会是制约知识传播的主要原因,高质量的文学作品的最高价格将会越来越高,而文学水平一般图书的最低价格将会越来越低。
(2)重要代码和运行情况
(3)文件输出结果

3.7 二次排序,年份从低到高,价格从高到低
(1)分析
通过观察,随着时间的推移,图书的价格越来越多样化,图书被出版的数量也越来越多,最高价格越来越高,最低价格越来越低。分析图书价格变化,预测未来几年出版图书的价格。
(2)重要代码和运行情况

(3)文件输出结果

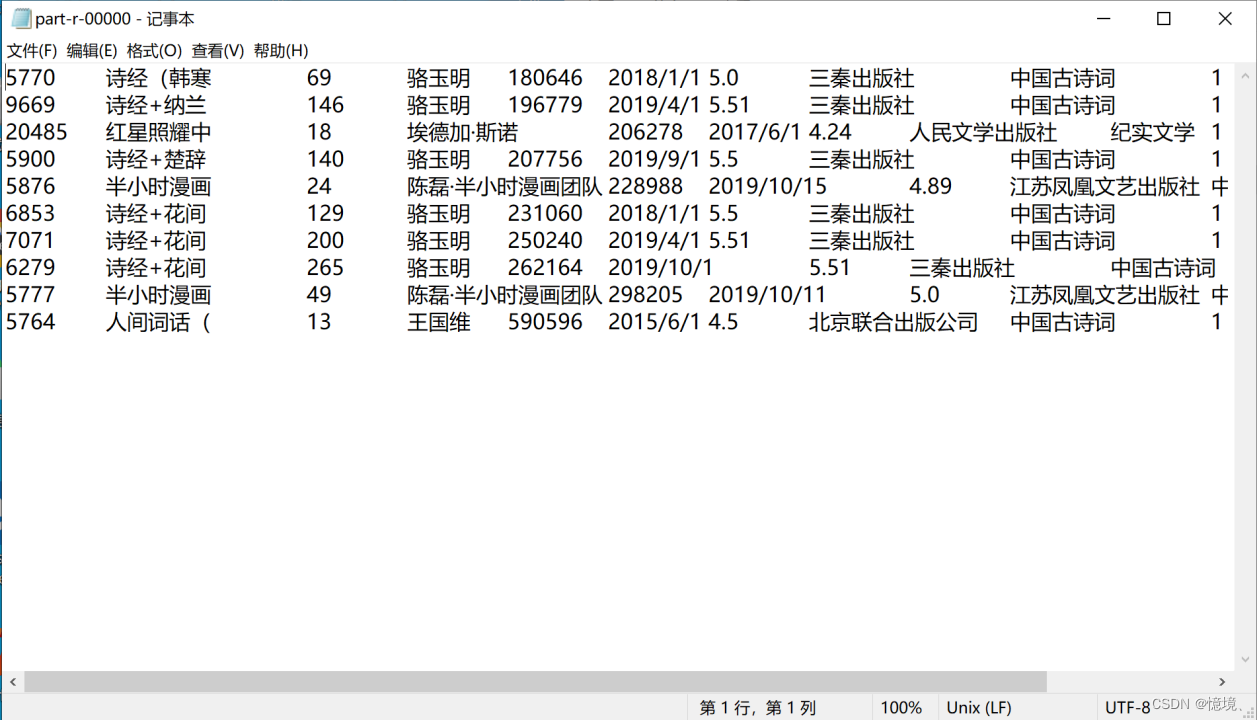
3.8 评价数量前10的书籍信息
(1)分析
在图书评价数量前10的书籍中,有6本是属于中国古诗词类图书,可见中国古诗词深受读者喜爱,同时这10本书基本是属于近三年新出版的新书,可见近些年来中国文化蓬勃发展,中国人对中国文化有了越来越多的认同。
(2)重要代码和运行情况

(3)文件输出结果
3.9 每年出版图书的数量
(1)分析
通过每年快速增长的出版图书数量,说明越来越多的作者加入了文化创作中,同时,未来中国文学的市场将会越来越广阔。
(2)重要代码和运行情况
(3)文件输出结果
3.10 对价格实现分区并进行排序
(1)分析
通过对价格分别大于1000,在500到1000之间和低于500之间书籍数量的对比我们发现,大部分图书都在500以下,500-1000之间仅仅占少部分,而1000以上则更少。
(2)重要代码和运行情况
(3)文件输出结果

4.Hive统计分析
4.1 评价数量大于1000的各种类型的书籍数量和平均价格
(1)目的
研究出版书籍数量和价格的关系,价格是否会影响销售量和顾客的评价数量。
(2)运行代码
(3)运行结果
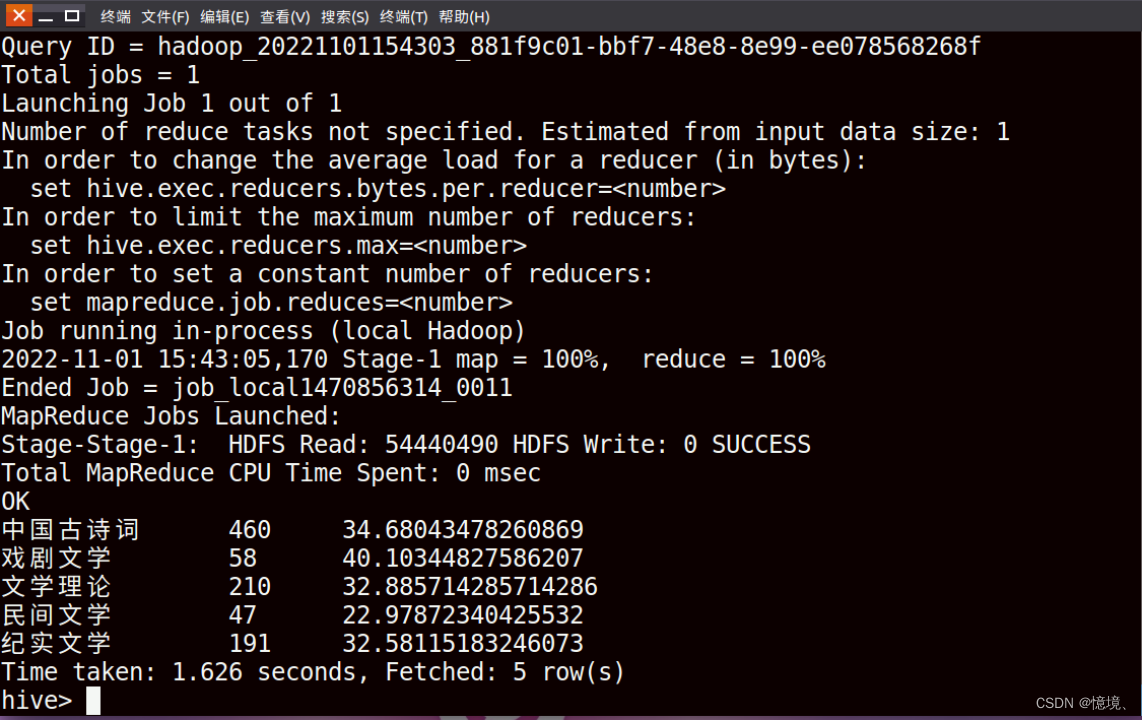
(4)文件输出结果
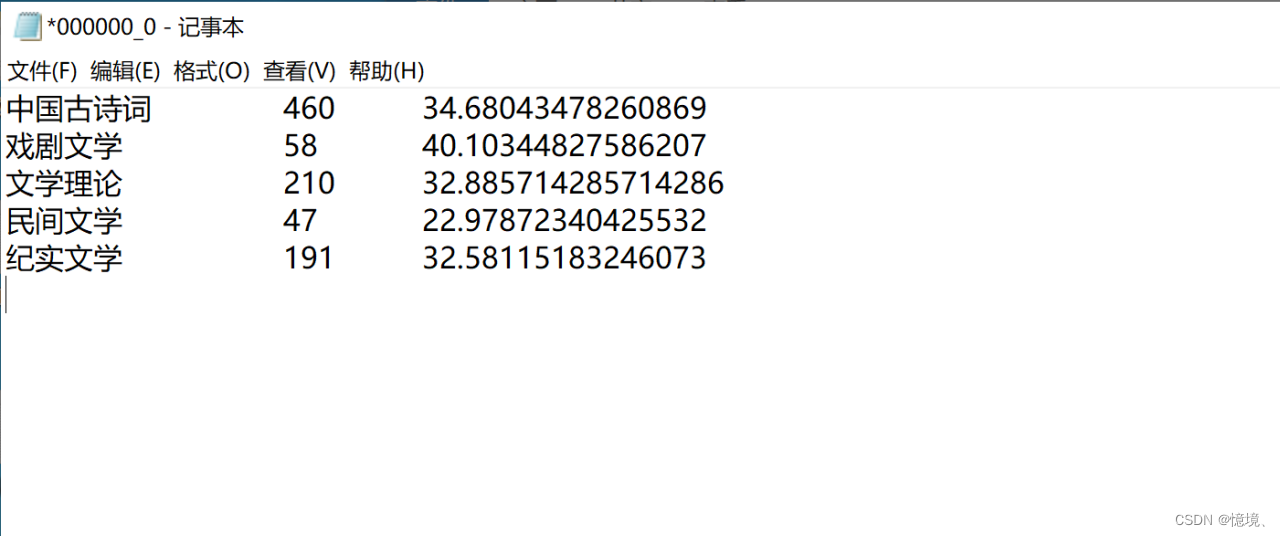
4.2 统计每种类型前10价格书籍的价格和评价数量
(1)目的
研究5类书籍前10名价格的对比,发现价格与书籍类型是否有关系,价格过高的书籍类型是否会评价数量的减少
(2)运行代码

(3)运行结果
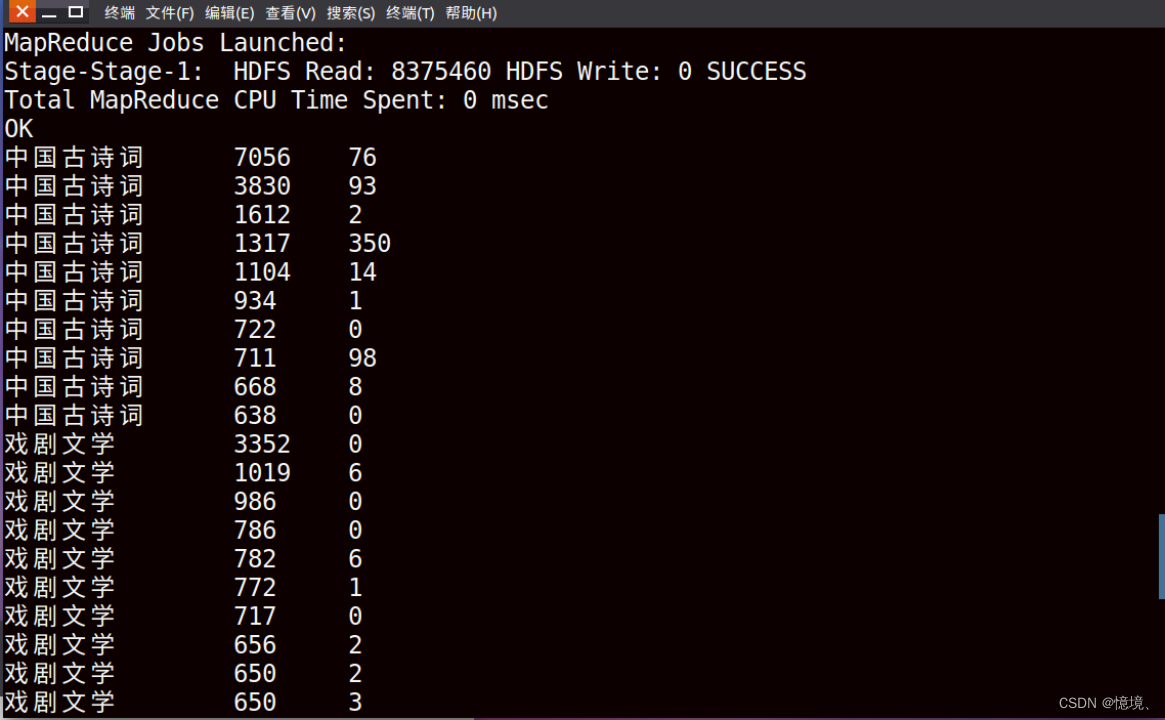
(4)文件输出结果

4.3 统计每种类型前10价格的书籍和折扣
(1)目的
研究为了吸引顾客购买高价书籍,商家是否会做更大力度折扣,一次来提高书籍的销量。
(2)运行代码

(3)运行结果
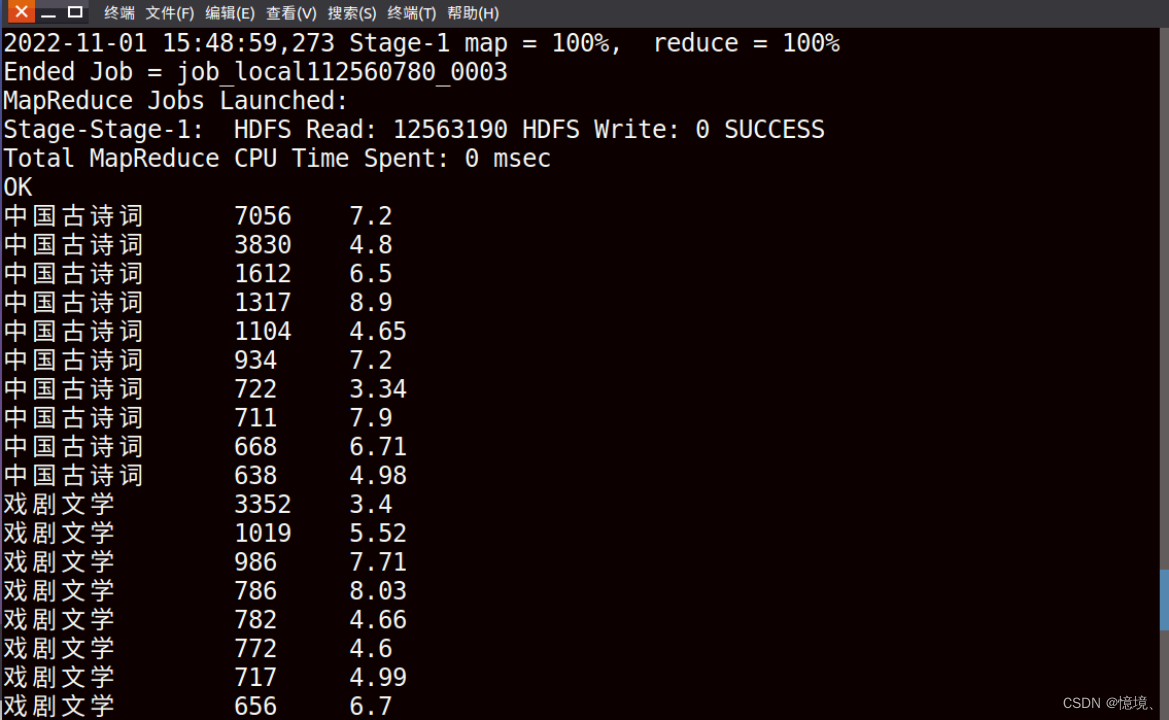
(4)文件输出结果
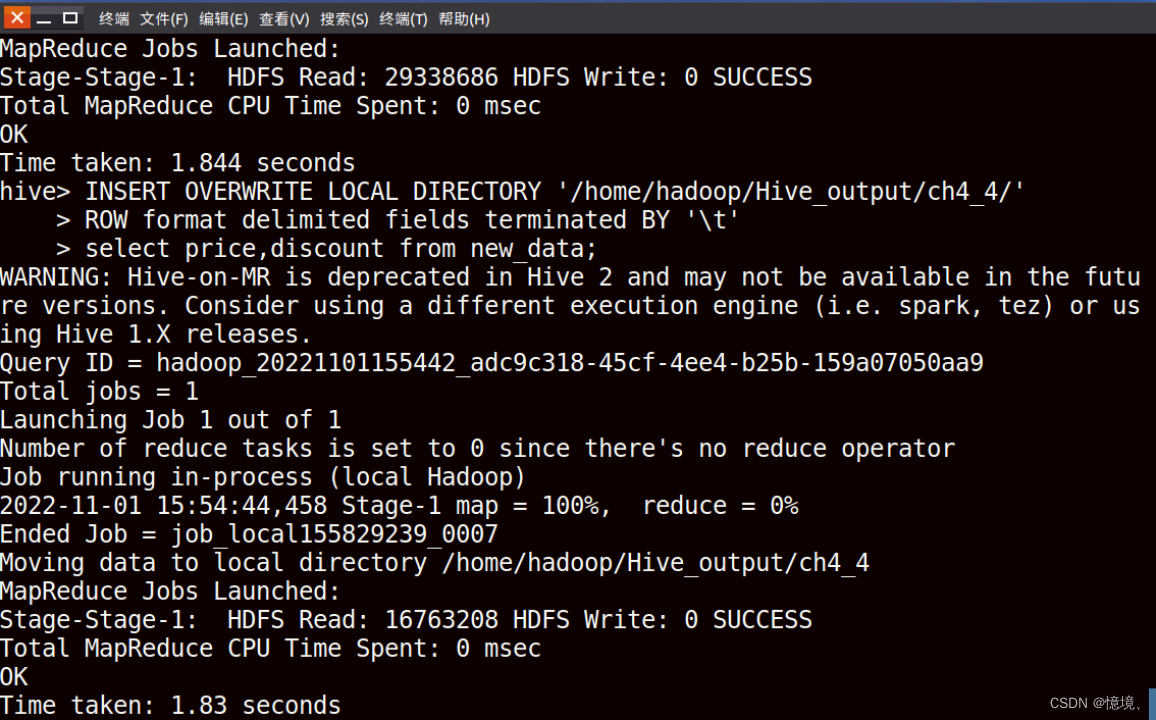
4.4 统计书籍价格和折扣
(1)目的
研究价格和折扣的关系,观察发现价格越高的书籍,折扣越大,我们可以判断,高价书籍会打较高的折扣力度,来吸引消费者,以此来提高销量。
(2)运行代码

(3)运行结果保存
 (4)文件输出结果
(4)文件输出结果
5.数据可视化
5.1 五类书籍出版的比例
(1)说明
读取3.2 五种书籍的比率MapperReduce输出文件,并对其绘制扇形图
(2)代码
(3)运行结果
5.2 2010-2020年五类书籍出版的数量
(1)说明
读取3.1 每年每种类型书籍出版数量MapperReduce输出结果,截取其中2010-2020年的数据进行绘制柱型图。
(2)代码

(3)运行结果
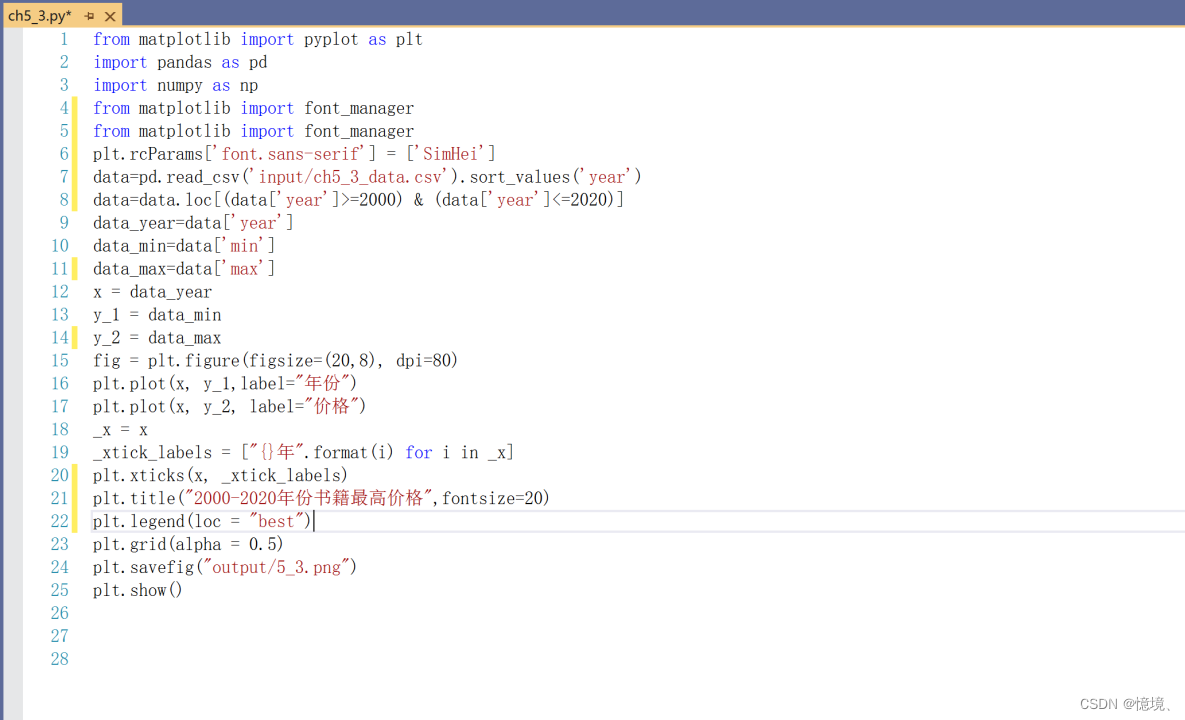
5.3 2000-2020年份书籍最高价格
(1)说明
读取 3.6 每年书籍的最低和最高价格的MapperReduce输出结果,截取其中2000-2020年份书籍的最高价格绘制折线图。
(2)代码
(3)运行结果

5.4 2000-2020年每年出版图书数量
(1)说明
读取 3.9 每年出版图书数量的MapperReduce输出结果,截取其中2000-2020年份书籍的出版数量绘制柱形图。
(2)代码
(3)运行结果

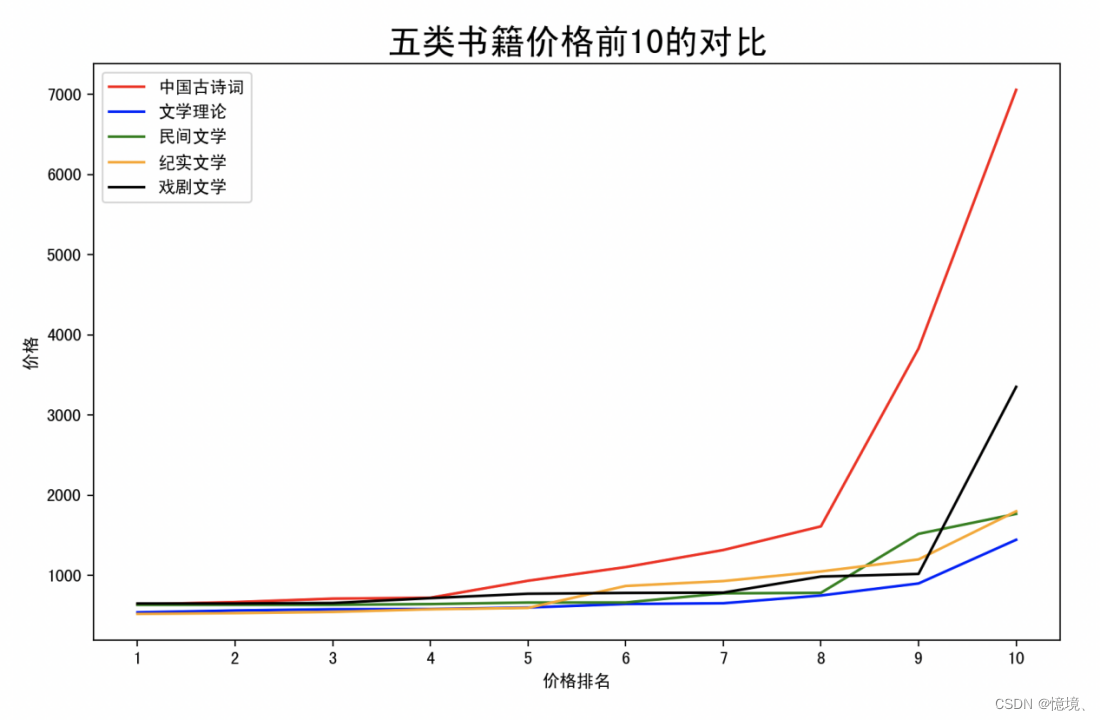
5.5 五类书籍价格前10的对比
(1)说明
读取4.2 统计每种类型前10价格书籍的价格和评价数量的Hive输出结果,截取其中书籍书籍的价格绘制折线图。
(2)代码
 (3)运行结果
(3)运行结果
6.总结
此次课程项目非常有意义,因为很好地考察了我们的实践能力。平时都是老师上课教,然后我们照着课本或老师提供的代码,基本上运行起来不会有太大的问题,只是稍微改一改输入输出文件的位置啊和自己的数据信息之类的。通过这个项目就能够综合我们本学期所学的基本所有知识点。而且老师给的代码,有一些其实不适合我们的项目需要,这时候就要我们自己改进,这就能很好地检验我们到底有没有真正学懂了,如果真的学会了就能在老师代码的基础上进行改进,不会的也能在一些其他不同的java代码里进行查找,然后修改,非常好。
中途出了很多错误,但最后还是顺利的完成。数据预处理很重要,尤其是对一些特殊字符进行处理,需要用到正则表达式之类的,这方面比较薄弱,以前不好好学,现在要用到就不会了。另外我也体会到脚本数据预处理功能的强大,因为一些数据预处理的问题,基本上把awk数据预处理学了一遍,虽然最后用了其它的办法解决我的数据问题,但收获还是非常非常大。
相比于上学期,这学期对不管是爬取数据,数据预处理,Hive数据上传分析,相对上学期有了非常大的进步。上学期还不会用Python进行数据预处理,结果只能针对1万行的数据一行一行对一些特殊字符进行整行的删除,这学期较早对pandas库有了了解,因此直接进行Python预处理,简单方便,但仍需加强。同时对matplotlib库也有了更深的了解,画出来的图明显比上学期好看很多,但仍需加强。
总之,收获满满。

