
- 1python生成excel文件的三种方式_python 生成excel_用python写excel文件
- 2拿捏面试官,高频接口自动化测试面试题总结(附答案)狂收offer..._接口自动化测试面试问题
- 3LeetCode 142.环形链表II
- 4Segment Anything Model (SAM)——分割一切,具有预测提示输入的图像分割实践
- 5斯坦福宣布前端开发要失业了!一张截图生成代码,64%优于原网页!_design2code18b 模型微调工程
- 6JS和android原生相互调用,JS传string 无限制调用android 原生工具类_android调用javascript服务
- 7MySQL - WITH...AS 创建临时表复用子查询_mysqlwithas调用二次
- 8BGP-(as-path-filter)
- 9人工智能和云计算带来的技术变革:优化业务流程
- 10【Redis快速入门】初识Redis、Redis安装、图形化界面_redis图形化界面
Midjourney基础参数详解_midjourney中style参数默认表示
赞
踩
参数是添加到提示中的选项,可更改图像的生成方式。参数可以更改图像的纵横比、在 Midjourney 模型版本之间切换、更改使用的 Upscaler 等等。
参数总是添加到提示的末尾。您可以向每个提示添加多个参数。

-
基本参数
-
纵横比(aspect ratios)
--aspect,或--ar调整图片的比例; -
混乱(chaos)
--chaos <number 0–100>改变结果的多样性。较高的值会产生更多不寻常和意外的世代; -
负面提示(no)
--no负面提示,在提示词末尾加上 --no 可以让画面中不出现某些内容; -
生成质量(quality)
--quality <.25, .5, 1, or 2>,或--q <.25, .5, 1, or 2>您要花费多少渲染质量时间。默认值为 1。值越高渲染时间越高,值越渲染时间越低。 -
种子(seed)
--seed <integer between 0–4294967295>用过 Midjourney 的同学会发现在发送提示词后,MJ 最开始的图像里会有一个非常模糊的噪点团 ,然后逐渐变得具体清晰,而这个噪点团的起点就是“Seed” 种子编号是为每个图像随机生成的,但可以使用 --seed 或 --sameseed 参数指定。使用相同的种子编号和提示将产生相似的结束图像。 -
停止(stop)
--stop <integer between 10–100>使用--stop参数在流程中途完成作业。以较早的百分比停止作业会产生更模糊、更不详细的结果。 -
平铺(tile)
--tile参数生成可用作重复拼贴的图像,以创建织物、壁纸和纹理的无缝图案; -
版本(version)用
--version或--v参数或使用/settings命令并选择型号版本来使用其他型号。不同的模型擅长处理不同类型的图像。 -
风格(style)
--style <4a, 4b or 4c>在 Midjourney 模型版本 4 的版本之间切换 -
程序化(stylize)
--stylize <number>,或--s <number>参数会影响 Midjourney 的默认美学风格应用于 Jobs 的强度。 -
聚光灯(uplight)
--uplight选择 U 按钮时使用替代的“轻型”升频器。结果更接近原始网格图像。放大后的图像细节更少,更平滑。 -
乌贝塔(upbeta)
--upbeta选择 U 按钮时使用替代的 beta 升频器。结果更接近原始网格图像。放大后的图像添加的细节明显更少。
默认值(模型版本 4)

默认值(模型版本 5)

(大于 2:1 的宽高比是实验性的,可能会产生不可预测的结果)
-
模型版本参数
-
--niji另一种模型专注于动漫风格的图像; -
--hd使用早期的替代模型来生成更大、更不一致的图像。该算法可能适用于抽象和风景图像; -
--test使用 Midjourney 特殊测试模型; -
--testp使用 Midjourney 特殊的以摄影为重点的测试模型; -
--version <1, 2, 3, 4, or 5>或者--v <1, 2, 3, 4, or 5>使用不同版本的 Midjourney 算法。当前算法 (V4) 是默认设置。
-
其他参数
-
--creative修改test和testp模型更加多样化和创造性; -
--iw设置相对于文本权重的图像提示权重。默认值为 --iw 0.25; -
--sameseed种子值创建一个大的随机噪声场,应用于初始网格中的所有图像。当指定 --sameseed 时,初始网格中的所有图像都使用相同的起始噪声,并将生成非常相似的生成图像; -
--video保存正在生成的初始图像网格的进度视频。表情符号使用 ☉️ 对完成的图像网格做出反应,以触发将视频发送到您的直接消息。--video放大图像时不起作用。
-
模型版本和参数兼容性

-
Aspect Ratios(纵横比)
--aspect参数--ar更改生成图像的纵横比。宽高比是图像的宽高比。它通常表示为用冒号分隔的两个数字,例如 7:4 或 4:3。
正方形图像具有相等的宽度和高度,描述为 1:1 的纵横比。图片可以是 1000px × 1000px,或者 1500px × 1500px,纵横比仍然是 1:1。计算机屏幕的比例可能为 16:10。宽度是高度的 1.6 倍。所以图像可以是 1600px × 1000px、4000px × 2000px、320px x 200px 等。
默认纵横比为 1:1。
--aspect必须使用整数。使用 139:100 而不是 1.39:1。 纵横比影响生成图像的形状和组成。 放大时,某些宽高比可能会略有变化。
最大纵横比
不同的 Midjourney 版本模型具有不同的最大纵横比。

该--ar参数将接受从 1:1(正方形)到每个模型的最大纵横比的任何纵横比。但是,在图像生成或放大过程中,最终输出可能会略有修改。示例:提示使用--ar 16:9(1.78) 创建具有7:4(1.75) 纵横比的图像。
大于 2:1 的宽高比是实验性的,可能会产生不可预测的结果。

提示示例:imagine/ prompt vibrant california poppies --ar 5:4
常见的纵横比
--aspect 1:1默认纵横比。 --aspect 5:4常见的框架和打印比例。 --aspect 3:2印刷摄影中常见。 --aspect 7:4靠近高清电视屏幕和智能手机屏幕。
如何更改纵横比
添加--aspect <value>:<value>, 或--ar <value>:<value>到提示的末尾。

-
Chaos(混乱)
参数影响初始图像网格--chaos的--c变化程度。高--chaos值将产生更多不寻常和意想不到的结果和组合。较低的--chaos值具有更可靠、可重复的结果。
--chaos范围值 0–100。 默认--chaos值为 0。
chaos 的生成的效果
低值--chaos
使用较低的 --chaos值或不指定值将生成每次运行作业时略有不同的初始图像网格。
提示示例:imagine/ prompt watermelon owl hybrid

高值--chaos
--chaos每次运行作业时,使用较高的值将产生更多变化和意外的初始图像网格。
提示示例:imagine/ prompt watermelon owl hybrid --c 50

非常高的值--chaos
--chaos每次运行作业时,使用极高的值将产生不同的初始图像网格,并且具有意想不到的构图或艺术媒介。
提示示例:imagine/ prompt watermelon owl hybrid --c 100

如何改变 Chaos 值
添加--chaos <value>或--c <value>到提示的末尾。

-
Quality(质量)
参数更改生成图像所花费--quality的--q时间。更高质量的设置需要更长的时间来处理并产生更多的细节。更高的值还意味着每个作业使用更多的 GPU 分钟数。质量设置不影响分辨率。
默认
--quality值为 1。较高的值会使用更多订阅的 GPU 时间。--quality接受以下值:默认模型的 。25、.5 和 1。较大的值将向下舍入为 1。--quality仅影响初始图像生成。--quality适用于模型版本 1、2、3、4、5 和 niji。
质量设置
更高的--quality设置并不总是更好。有时较低的--quality设置可以产生更好的结果——这取决于您尝试创建的图像。较低的--quality设置可能最适合手势抽象外观。较高的--quality值可以改善受益于许多细节的建筑图像的外观。选择与您希望创建的图像类型最匹配的设置。
提示示例:/imagine prompt woodcut birch forest --q .25


版本质量兼容性
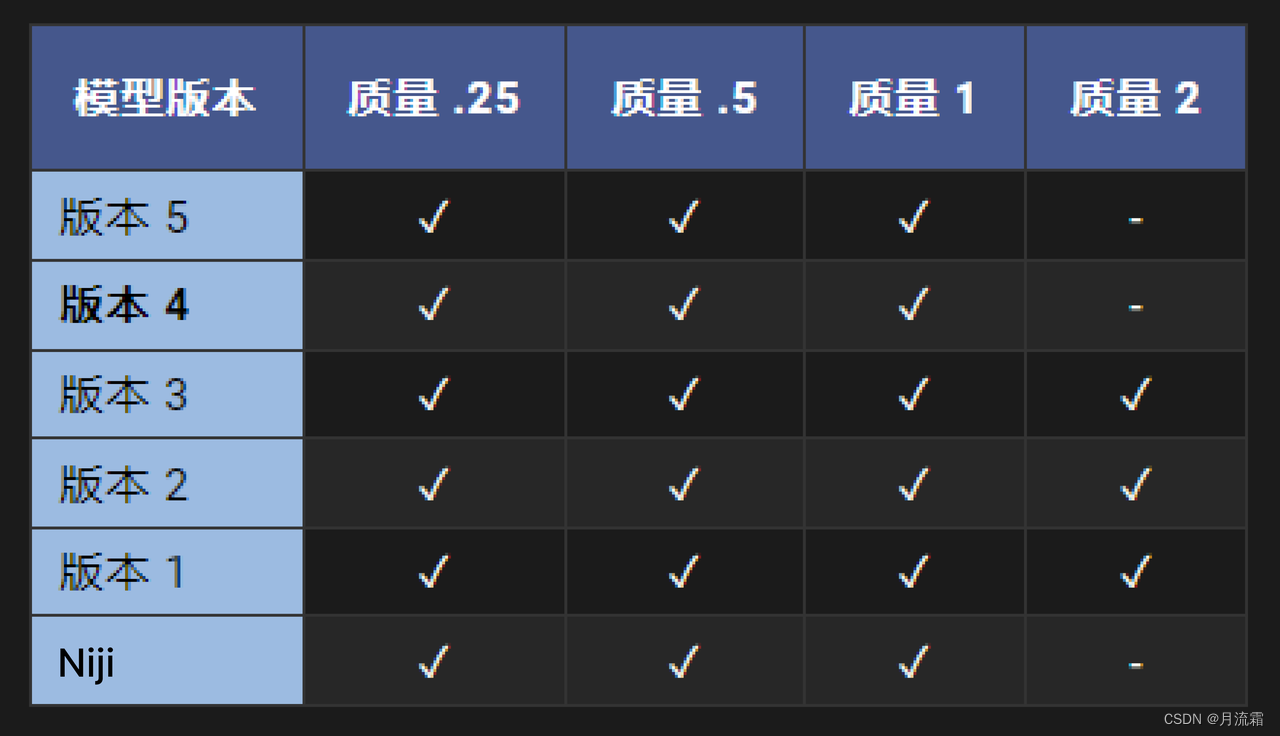
使用--quality或--q参数
添加--quality <value>或--q <value>到提示的末尾。
使用设置命令
从菜单中/settings选择您的首选值。quality

-
Seed(种子)
用过 Midjourney 的同学会发现在发送提示词后,MJ 最开始的图像里会有一个非常模糊的噪点团 ,然后逐渐变得具体清晰,而这个噪点团的起点就是“Seed” 种子编号是为每个图像随机生成的,但可以使用 --seed 或 --sameseed 参数指定。使用相同的种子编号和提示将产生相似的结束图像。
--seed接受整数 0–4294967295。--seed值仅影响初始图像网格。--seed值模型版本1、2、3、test和testp是不确定的,将产生相似但不相同的图像。在模型版本 中使用相同的提示+种子+参数 ,将产生相同的图像。45niji
seed 参数
如果未指定种子,Midjourney 将使用随机生成的种子编号,每次使用提示时都会生成多种选项。
使用随机种子运行 3 次
提示示例:/imagine prompt celadon owl pitcher

使用指定种子运行 3 次
提示示例:/imagine prompt celadon owl pitcher --seed 123

同数值参数
--seed值创建一个大的随机噪声场,应用于初始网格中的所有图像。指定时--sameseed,初始网格中的所有图像都使用相同的起始噪声,并将生成非常相似的生成图像。

如何查找工作的种子编号
使用 Discord 表情符号反应,通过对工作使用 ☉️ 信封表情符号做出反应,在不和谐中找到工作的种子编号。
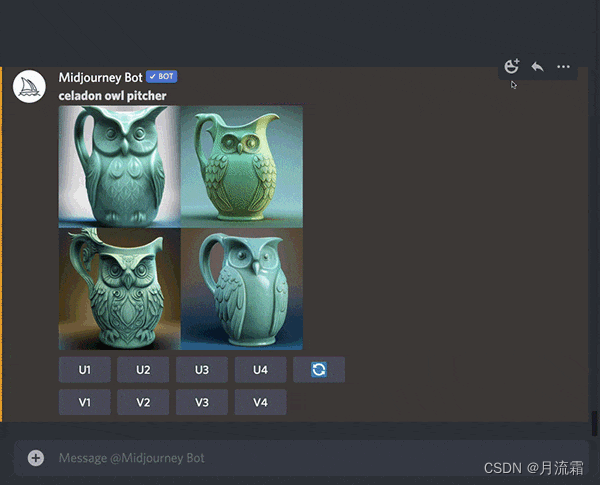
如何更改种子编号
使用 --seed或--sameseed参数,添加--seed <value>或--sameseed <value>到提示的末尾。

-
Shop(停止)
使用--stop参数在流程中途完成作业。以较早的百分比停止作业会产生更模糊、更不详细的结果。
--stop接受值:10–100。 默认--stop值为 100。--stop时不起作用。
不同 Shop 的对比

shop 和 Beta Upscale
放大时,该--stop参数不会影响作业。但是,停止会产生更柔和、细节更少的初始图像,这将影响最终放大结果的细节水平。下面的放大图像使用了 Beta Upscaler。

使用--stop参数
添加--stop <value>到提示的末尾。

-
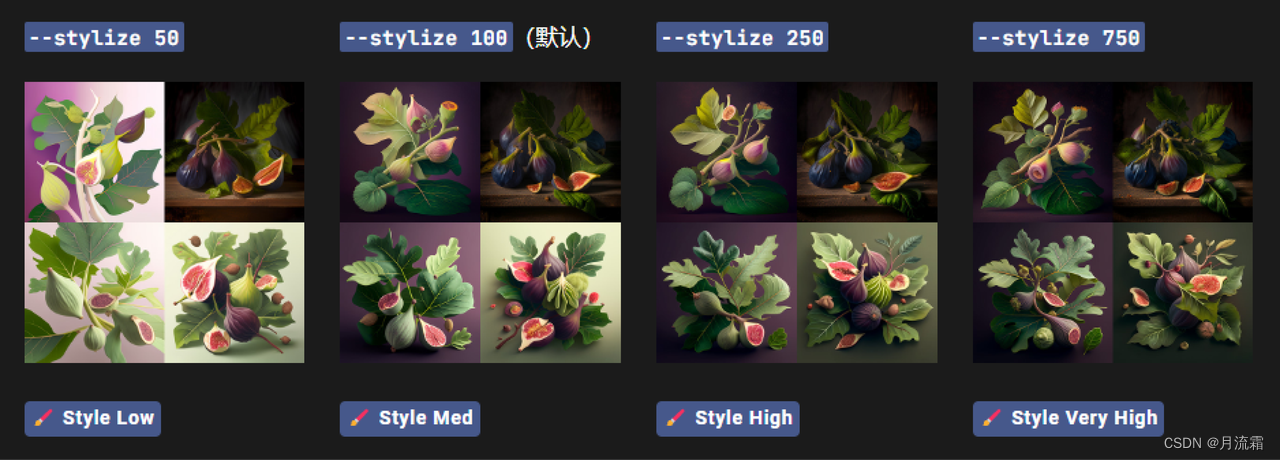
Stylize(程序化)
Midjourney Bot 经过训练可以生成有利于艺术色彩、构图和形式的图像。或参数影响该训练应用--stylize的--s强度。低程式化值生成的图像与提示非常匹配,但艺术性较差。高程式化值创建的图像非常具有艺术性,但与提示的联系较少。
--stylize的默认值为 100,并且在使用默认 [V4 模型] 时接受 0-1000 的整数值。
不同的 Midjourney 版本模型具有不同的风格化范围。
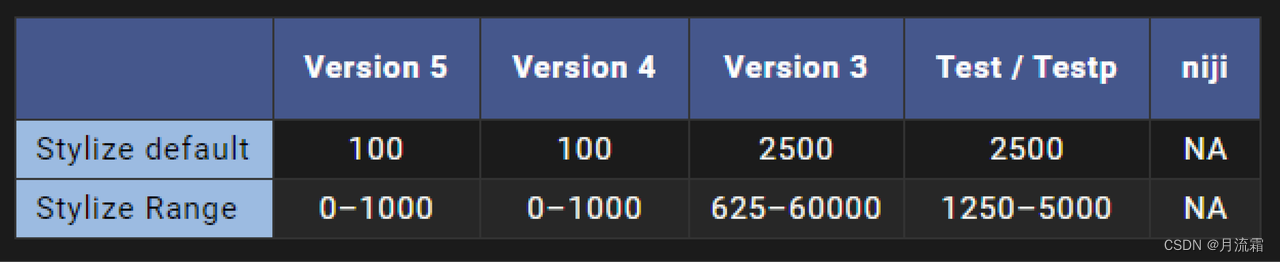
通用风格化设置
V4 模型
提示示例:/imagine prompt illustrated figs --s 100
V5 模型
提示示例:/imagine prompt colorful risograph of a fig --s 100

使用 stylize 参数
添加--stylize <value>或--s <value>到提示的末尾。
使用设置命令
/settings从菜单中键入并选择您喜欢的风格化值。

-
Tile(平铺)
--tile参数生成可用作重复拼贴的图像,以创建织物、壁纸和纹理的无缝图案。
--tile适用于模型 版本 1、2、3、5--tile只生成一个 tile。使用像这种无缝模式检查器这样的模式制作工具来查看拼贴重复。
Tile 示例
使用 Midjourney 的模型测试/Testp

使用 Midjourney 模型 5

如何使用 tile 参数
添加--tile到提示的末尾。

-
Version(版本)
Midjourney 定期发布新模型版本以提高效率、一致性和质量。默认为最新型号,但可以使用--version或--v参数或使用/settings命令并选择型号版本来使用其他型号。不同的模型擅长处理不同类型的图像。
--version接受值 1、2、3、4 和 5。--version可以缩写--v
最新模型(V5)
Midjourney V5 模型是最新最先进的模型,于 2023 年 3 月 15 日发布。要使用此模型,请将参数添加--v 5到提示末尾,或使用/settings命令并选择5️⃣ MJ Version 5
该模型具有非常高的 Coherency,擅长解释自然语言提示,分辨率更高,并支持高级功能,例如重复模式--tile

V4 模型
Midjourney V4 模型是由 Midjourney 设计并在新的 Midjourney AI 超级集群上训练的全新代码库和全新 AI 架构。最新的 Midjourney 模型拥有更多关于生物、地点、物体等的知识。它更擅长正确处理小细节,并且可以处理包含多个角色或对象的复杂提示。第 4 版模型支持图像提示和多提示等高级功能。
该模型具有非常高的 Coherency 并且在 Image Prompts 方面表现出色。

V4 的 样式 4a、4b 和 4c
Midjourney Model Version 4 具有三种略有不同的“风格”,对模型的风格调整进行了细微调整。通过在 V4 提示末尾添加--style 4a、--style 4b或来试验这些版本。--style 4c
--v 4 --style 4c是当前默认值,不需要添加到提示末尾。
关于样式 4a 和 4b 的注释
--style 4a且--style 4b仅支持 1:1、2:3 和 3:2 纵横比。--style 4c支持高达 1:2 或 2:1 的纵横比。

以前的模型
您可以使用--version或--v参数或使用/settings命令并选择模型版本来访问更早的 midjourney 模型。不同的模型擅长处理不同类型的图像。
提示示例:/imagine prompt vibrant California poppies --v 1

Niji 模型
该模型是 Midjourney 和 Spellbrushniji之间的合作,经过调整可以制作动画和插图风格。该模型对动漫、动漫风格和动漫美学有更多的了解。一般来说,它在动态和动作镜头以及以角色为中心的构图方面表现出色。--niji
提示示例:/imagine prompt vibrant California poppies --niji

--niji型号 说明
Niji 不支持--stylize参数。使用/settings命令并选择Style Med重置为所有--niji提示的默认样式设置。Niji 支持多提示或图像提示。
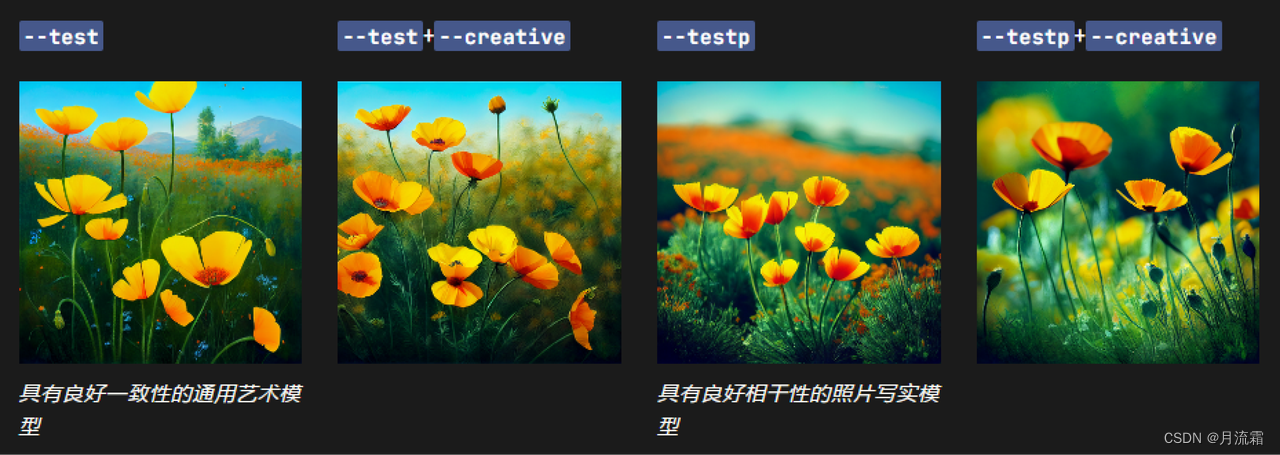
Test 模型
偶尔会临时发布新模型以供社区测试和反馈。目前有两种可用的测试模型:--test和--testp,它们可以与--creative参数结合使用以获得更多不同的成分。
提示示例:/imagine prompt vibrant California poppies --testp --creative
当前测试模型的注释
--test和--testp测试模型仅支持
--stylize1250–5000 之间的值。 测试模型不支持多提示或图像提示 测试模型的最大纵横比为 3:2 或 2:3。 当宽高比为 1:1 时,测试模型仅生成两个初始网格图像。 当纵横比不是 1:1 时,测试模型只生成一张初始网格图像。 靠近提示前面的词可能比靠近后面的词更重要。
使用版本或测试参数
将--v 1, --v 2, --v 3, --v 4, --v 4 --style 4a, --v4 --style 4b --test, --testp, --test --creative,--testp --creative或添加--niji到提示的末尾。

使用设置命令
输入/settings并从菜单中选择您喜欢的版本。

-
Video(视频)
使用该--video参数创建正在生成的初始图像网格的短片。使用信封 ☉️ 表情符号对完成的工作做出反应,让 Midjourney Bot 将视频链接发送到您的直接消息。
--video仅适用于图像网格,不适用于高档。--video适用于模型版本1、2、3、test和testp。
视频示例


如何获取视频链接
提示示例:/imagine prompt Vibrant California Poppies --video
1、 添加--video到提示的末尾;
2、作业完成后,单击添加反应;
3、选择 ☉️ 信封表情符号;
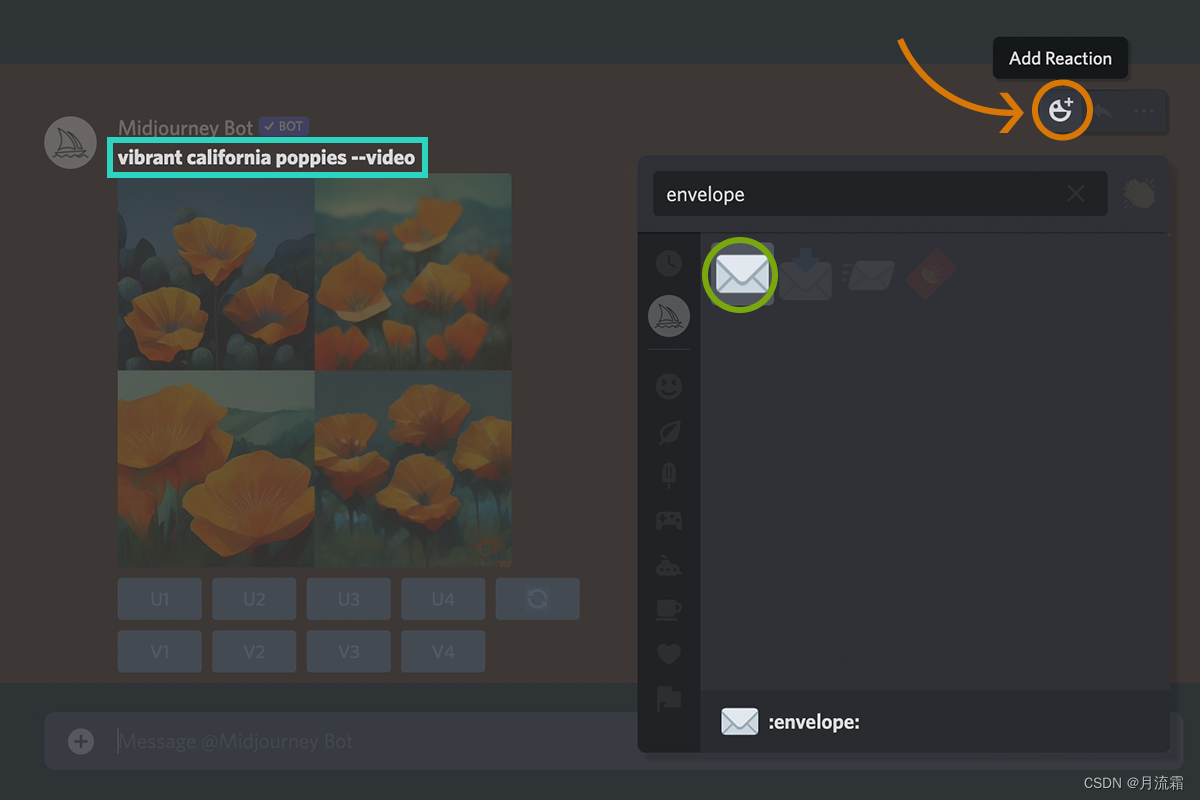
4、Midjourney 机器人会将视频链接发送到您的直接消息;
5、单击链接可在浏览器中查看您的视频。右键单击或长按以下载视频;
如何使用视频参数
添加--video到提示的末尾。


