
- 1小白 笔记---------------------------hadoop出现hadoop2.X部署警告: Unable to load native-hadoop library 总结_unable to load native-hadoop library是什么问题
- 2新开发的应用做ASO服务有必要吗
- 3我用AI实现了我的插画梦
- 4python—爬虫爬取视频样例
- 5java基础八股文_java面值基础知识八股文
- 6基于Python实现的人像卡通化_人物头像的卡通化算法设计与实现
- 7hadoop-hdfs配置 + HA(高可用)配置(学习)_hadoop ha配置
- 8python 海龟交易法则_【手把手教你】用Python量化海龟交易法则
- 9开源协议的对比和商业上的安全使用_sspl
- 10李沐动手学深度学习V2-bert预训练数据集和代码实现_bert训练自己的数据集
深入思考redis面经
赞
踩
1 redission分布式锁
1.1 为了保证数据一致性,引入了redission的锁,你是为了抗住高并发而去为了引入这个锁还是说为了保证数据一致性去引入的
答:主要是为了抗住高并发问题,解决redis的缓存击穿问题,但是也能解决一定的数据一致性问题。
是的,当我们谈到“击穿”问题时,通常指的是缓存击穿,即当某个热点缓存失效时,大量的请求直接涌向底层存储系统(如数据库),可能导致该系统过载。
在这种情况下,引入 Redission 的分布式锁主要是为了抗住这种高并发,即防止大量请求直接涌向底层系统。具体做法是,当缓存失效时,第一个到达的请求获取锁并重新加载数据到缓存,而其他并发请求则需要等待该请求完成数据加载和缓存更新。一旦数据被加载回缓存,那么后续的请求就可以直接从缓存中获取,而不必再次访问底层系统。这样,即使有大量的并发请求,也只有少数请求真正访问底层系统,从而避免了系统过载的问题。
所以,确实,对于缓存击穿问题,引入 Redission 的分布式锁主要是为了应对高并发,保护底层存储系统不被过度访问。
1.2 为了应对缓存击穿,使用redission分布式锁,这里redission有对一致性上起作用吗
为了应对缓存击穿,使用 Redission 分布式锁是为了确保在缓存失效时,只有一个请求去加载数据并更新缓存,防止底层数据库被大量并发请求压垮。但这里的一致性问题也是相关的,尤其是确保正确的数据被加载到缓存中。
在这种场景下,Redission 的作用在一致性上体现在:
-
单点加载:分布式锁确保在某一时刻只有一个请求(或一个服务实例)能够去加载数据。这避免了不同的请求可能在微小时间差异内加载到不同版本的数据,并都尝试去更新缓存的情况。例如,考虑一个场景,在某个请求加载数据的过程中,数据在数据库中被修改,紧随其后的另一个请求可能会加载到新版本的数据。如果没有分布式锁,两个请求可能都会尝试更新缓存,导致缓存中的数据在短时间内频繁切换。
-
减少竞态条件:没有分布式锁的情况下,多个请求可能会并发地检测到缓存失效,并尝试从数据库加载数据并更新缓存。这可能会导致竞态条件,从而导致不可预测的结果。引入锁后,请求会按照顺序执行,消除了竞态条件,确保数据加载和缓存更新的操作是原子的。
综上所述,Redission 分布式锁在处理缓存击穿的问题时,不仅帮助我们抗住高并发,还确保了数据的一致性。
2 美团二面:Redis与MySQL双写一致性如何保证
2.1 你引入缓存后,可以预减库存,那现在引入了一个新的问题,mysql和redis数据的一致性,你是如何保证的
答:库存回退时,就涉及到这个mysql和redis的多级库存回退问题,库存回退涉及到用户取消订单场景,一般是先更新数据库的商品表,然后再删除缓存;另一种策略是先使用redis延时双删的方法。
2.2 有三种经典的缓存模式:Cache-Aside Pattern,Read-Through/Write through,Write behind,这三个经典的缓存模式,能给我讲出几个应用场景吗
当然可以。这三种经典的缓存模式都有其独特的应用场景,下面我将为您概述这些模式并给出各自的应用场景:
-
Cache-Aside Pattern (旁路缓存模式)
- 描述:应用程序代码负责维护缓存。当读取数据时,首先查询缓存。如果缓存中不存在所需数据,则从数据存储中加载数据,然后将数据添加到缓存中。当数据被修改时,首先在数据存储中更新数据,然后使缓存中的数据失效或删除。
- 应用场景:
- 当缓存填充成本很高时(例如,数据需要从多个源进行聚合或进行复杂的计算),这样只有真正需要的数据才被加载到缓存。
- 当系统可以容忍短暂的数据不一致性时,例如社交媒体帖子或评论的显示。
-
Read-Through/Write-Through (读穿/写穿模式)
- 描述:这是自动化的缓存模式。当应用请求某个数据项时,如果数据不在缓存中,则缓存组件会自动从数据存储中加载该数据,然后将其放入缓存。对于写操作,应用程序将数据写入缓存,缓存组件负责将数据同步写入数据存储。
- 应用场景:
- 当需要确保缓存和数据存储之间始终保持一致性时,例如,关键业务系统或金融系统。
- 当你希望为应用开发者提供透明的缓存管理,使他们无需关心缓存维护的细节。
-
Write-Behind (写后模式)
- 描述:当应用程序写入数据到缓存时,数据首先写入缓存,并且返回成功,后续由缓存组件异步地将修改的数据同步到数据存储。这可以将多个写操作合并为一个,优化数据存储的写入。
- 应用场景:
- 日志记录系统,当你希望快速响应写入请求,而真正的持久化操作可以稍后进行。
- 当对数据存储的实时性要求不高,但要求提供快速的写入响应。
- 在批处理操作中,例如,统计或分析系统中的数据聚合。
这三种模式都有其适用的场景,选择哪种模式取决于应用的需求和特点。一些现代的缓存解决方案(如 Redis、Memcached、Hazelcast 等)支持这些模式,可以根据需求进行配置使用。
2.3 那这里的读写穿透模式,为什么能保证缓存和数据库之间始终保持一致呢?
读穿/写穿模式能够保持缓存和数据库之间的一致性主要是因为它的工作方式:
-
Read-Through(读穿):
- 当应用程序请求一个数据项,并且该数据项不在缓存中时,缓存系统会自动从底层的数据存储(如数据库)加载数据。
- 加载后,该数据项被存储在缓存中,并返回给应用程序。
- 这确保了每当数据项不在缓存中时,都会从持久化的数据源中加载最新的数据。
-
Write-Through(写穿):
- 当应用程序更新一个数据项时,这个更新不仅仅应用于缓存,而且立即同步到底层的数据存储。
- 由于写操作同时影响缓存和数据存储,因此保证了两者之间的数据一致性。
这种方式的核心在于,所有的读写操作都通过缓存进行,并且缓存负责与底层数据存储的所有交互,这就确保了两者之间的数据一致性。
需要注意的是,这种一致性是在单个操作级别上的。也就是说,每一个单独的读或写操作都确保数据在缓存和数据存储之间保持一致。然而,在高并发的环境下或在分布式系统中,仍然可能会遇到其他类型的一致性挑战,例如:网络分区、数据库的事务冲突等。这就需要其他的解决方案,如分布式锁、事务控制等来进一步保证一致性。
2.4 读穿和写穿都是一个同步阻塞的过程,所以能够保证一致性是吗
是的,读穿和写穿都是同步阻塞的过程。这意味着当你执行一个操作时,它会等待直到操作完成,才返回结果。因为它是同步的,所以在单次操作中,缓存和数据库之间可以保持数据一致性。
2.5 写穿场景下,是先更新缓存再更新数据库吗还是相反
在写穿模式下,当应用程序更新数据时,通常的流程是先更新数据库,然后更新缓存。这样做的原因是:数据库是数据的持久存储,首先确保数据被成功保存在数据库中是很重要的。一旦数据成功写入数据库,缓存才会被更新。这种策略可以确保如果在更新过程中发生任何错误(例如,由于网络问题),数据至少已经被保存在数据库中,而缓存可能仍然保持旧值。如果缓存首先被更新,然后在尝试更新数据库时出现错误,你会面临缓存和数据库之间的不一致性问题。
2.6 因为写穿是通过一个抽象层来完成的,所以对于“先更新数据库后更新缓存”导致的数据不一致问题,这个抽象层是如何解决的
在写穿模式中,确实有一个抽象层(通常是缓存中间件或框架)来协助处理缓存与数据存储之间的交互。这个抽象层的设计是为了最大程度地确保数据一致性。
以下是如何处理“先更新数据库后更新缓存”中可能出现的数据不一致性问题:
-
原子性:这个抽象层会尝试将更新数据库和更新缓存的操作视为一个原子操作。也就是说,两个操作要么都成功,要么都失败。如果更新数据库成功,但更新缓存失败,通常会有重试机制来确保缓存最终得到更新。
-
错误处理:如果在更新数据库后、更新缓存之前发生错误(例如由于网络问题),抽象层会有错误处理机制。这可能包括重试、回滚数据库操作、记录错误以供后续处理等。
-
失效策略:在某些情况下,如果缓存更新失败,抽象层可能选择简单地使该缓存条目失效。这样,下次当应用程序请求这个数据时,因为它不在缓存中,系统会采用读穿策略,从数据库中加载最新的数据并更新缓存。
-
延迟写入:在某些实现中,可能会有一种延迟写入策略,允许先更新缓存,然后异步地更新数据库。但这种方法不是严格的写穿策略,它更接近写后模式,并带有其自身的一致性挑战。
-
日志和监控:这个抽象层通常会有详细的日志和监控功能,以便于跟踪所有操作,包括成功和失败的操作。这对于后续的问题诊断和数据修复都很有帮助。
尽管有上述策略,但没有一个系统可以保证100%的数据一致性,特别是在分布式环境中。因此,设计时应考虑到这些挑战,并尽量确保系统的韧性和恢复能力。
2.7 针对下面这个“先更新数据库后更新缓存导致不一致”例子,抽象层是如何解决的
此外,你这个还存在一个问题是脏数据问题:
线程A先发起一个写操作,第一步先更新数据库
线程B再发起一个写操作,第二步更新了数据库
由于网络等原因,线程B先更新了缓存
线程A更新缓存。
这时候,缓存保存的是A的数据(老数据),数据库保存的是B的数据(新数据),数据不一致了,脏数据出现啦。如果是删除缓存取代更新缓存则不会出现这个脏数据问题。
- 1
- 2
- 3
- 4
- 5
- 6
您描述的确实是一个经典的脏数据问题。为了解决这类问题,通常需要采取以下策略或结合使用这些策略:
-
分布式锁:通过使用分布式锁,可以确保在任何时候都只有一个线程能够执行写操作。在上述情境中,如果线程A获取了锁并开始执行写操作,那么线程B会等待,直到线程A完成所有的操作(包括更新数据库和缓存)并释放锁。
-
版本号或时间戳:为数据添加版本号或时间戳可以帮助确定写操作的顺序。例如,当线程A和线程B都试图更新缓存时,它们会检查自己手头上的数据版本号或时间戳与缓存中的数据进行比较。只有具有最新版本号或时间戳的线程才能更新缓存。
-
先失效缓存:如您所述,另一种策略是不直接更新缓存,而是简单地使其失效。这样,下一次读取该数据时,会导致缓存未命中,然后系统会从数据库加载最新数据。这种方法减少了脏数据问题,但可能会增加读取的延迟,因为需要频繁地从数据库加载数据。
-
队列或事件日志:可以使用队列或事件日志来确保按正确的顺序处理写操作。写操作首先被放入队列或日志,并且按照它们到达的顺序被处理。这可以确保即使线程B的写操作在线程A之后到达,它也不会在线程A之前被处理。
-
重试和回滚策略:在某些情况下,如果发现脏数据或不一致的数据,系统可能会采取重试或回滚策略。例如,如果线程A在试图更新缓存时发现数据已经被线程B更改,它可能会选择回滚自己在数据库中的更改。
-
监听数据变更:某些系统会使用监听器或订阅者模式来监视数据变更,当数据在数据库中发生变更时,监听器会自动更新或失效缓存。
综上所述,确保缓存和数据库之间的数据一致性是一个复杂的问题,通常需要综合使用多种策略和技术来处理。选择哪种策略取决于系统的需求、预期的工作负载以及可接受的延迟和一致性等级。
2.8 删除redis缓存,造成对业务代码入侵严重怎么办
取biglog异步删除缓存
重试删除缓存机制还可以,就是会造成好多业务代码入侵。其实,还可以通过数据库的binlog来异步淘汰key。
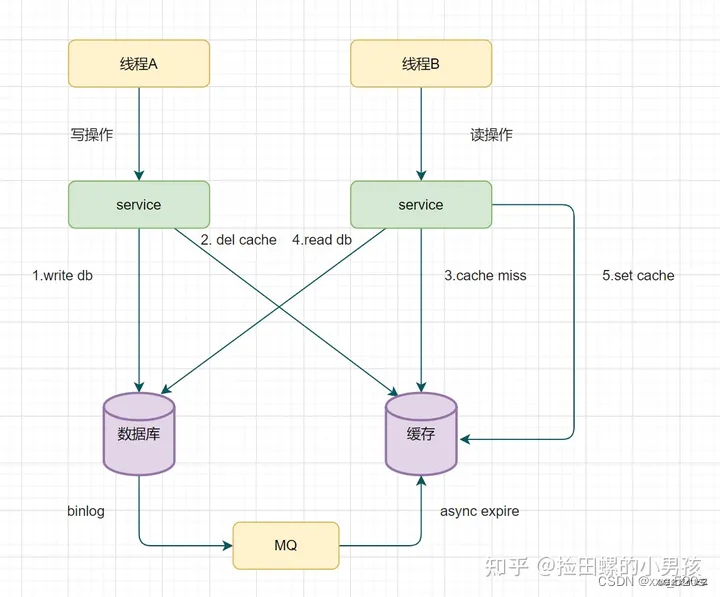
以mysql为例 可以使用阿里的canal将binlog日志采集发送到MQ队列里面,然后通过ACK机制确认处理这条更新消息,删除缓存,保证数据缓存一致性
3 redis单线程和IO多路复用
3.1 它是单线程的还是多线程的
Redis主要是单线程的,它处理命令请求是在一个主线程中顺序执行的,这也是为什么Redis可以保证原子性。但是,对于某些后台任务,如持久化、日志同步等,Redis确实使用了多线程。
3.2 redis的单线程如何结合那个IO多路复用的呢
IO多路复用是一种允许单个线程监视多个文件描述符的技术,这意味着单个线程可以同时处理多个连接。当某个连接上有数据可读或可写时,该连接会被激活,然后Redis可以对其进行处理。
Redis使用IO多路复用技术来同时处理多个客户端连接,而不需要为每个客户端启动一个新线程。这种方法使Redis能够高效地处理大量并发连接。
具体步骤如下:
- 初始化:Redis初始化所需的数据结构,并绑定到指定的端口上等待客户端连接。
- 添加文件描述符:当客户端连接到Redis时,Redis将这个连接的文件描述符添加到IO多路复用程序的监听列表中。
- 等待事件:Redis调用IO多路复用程序的API(如
select、epoll、kqueue等),等待任何文件描述符变得可读或可写。 - 处理事件:当某个文件描述符变得可读或可写时,Redis会处理与之相关的命令或响应。
- 循环:Redis继续回到第3步,等待更多的事件。
通过这种方式,Redis可以在单线程中高效地处理多个并发连接,同时保持简单的代码结构和原子性。IO多路复用技术使Redis能够在单线程中实现高并发处理能力。
3.2.1 这里的redis的IO多路复用线程和redis的执行命令的主线程是两个线程吧
- 不是的。Redis的IO多路复用和执行命令都是在同一个主线程中完成的。Redis使用IO多路复用技术来在单线程中高效地监听和处理多个客户端连接。当某个连接上有数据可读时,Redis会在这个主线程中读取数据并执行相应的命令。
IO多路复用不是多线程,而是一种允许单个线程监视多个文件描述符的技术。当某个文件描述符上有事件发生(例如,数据可读或可写)时,IO多路复用会通知应用程序,这样应用程序可以对该事件进行处理。
所以,Redis的主线程会使用IO多路复用技术来等待和检测哪些连接上有事件发生,然后在同一个线程中处理这些事件,包括读取请求、执行命令和发送响应。
3.2.2 epoll为什么这么高效
3.2.3 讲讲epoll的lt和et
epoll 是 Linux 提供的 I/O 多路复用机制,它比传统的 select 和 poll 更加高效。epoll 支持两种工作模式:LT(Level Trigger,水平触发)和 ET(Edge Trigger,边缘触发)。这两种模式决定了当事件发生时,如何通知应用程序。
-
LT (Level Triggered, 水平触发):
- 水平触发是默认的工作模式。
- 当被监控的文件描述符上有可读写事件发生时,
epoll会通知应用程序。如果应用程序没有完全处理事件(例如,只读取了部分数据,但数据仍然在缓冲区中),那么下次调用epoll_wait时,epoll仍然会通知应用程序该文件描述符上有事件发生。 - 这意味着,只要该文件描述符上的事件(如数据可读)仍然存在,
epoll就会不断地通知应用程序,即使在事件初次被通知之后没有被完全处理。
-
ET (Edge Triggered, 边缘触发):
- 边缘触发是一种更高效的工作模式,但使用起来也更加复杂。
- 当被监控的文件描述符上有可读写事件发生时,
epoll会通知应用程序。但与水平触发不同,即使该事件没有被完全处理,epoll在下次调用epoll_wait时不会再次通知应用程序,除非有新的或其他类型的 I/O 事件发生。 - 这意味着应用程序必须确保一次性处理完该事件,否则可能会错过事件通知。因此,使用边缘触发时,通常需要使用非阻塞的 I/O 操作来确保读/写操作不会被阻塞。
选择 LT 还是 ET:
- 对于简单的应用或只是开始使用
epoll的场景,水平触发(LT)可能更为合适,因为它的行为更加直观。 - 对于性能要求较高的应用,边缘触发(ET)可能更为合适,但需要确保正确处理 I/O 事件,以避免错过事件通知。
总之,选择哪种模式取决于应用程序的具体需求和开发者的经验。
4 redis的集群模式
4.1 redis有哪些集群模式
Redis 支持多种集群模式,以满足不同的可扩展性和高可用性需求。以下是 Redis 的主要集群模式:
-
主从复制 (Master-Slave Replication):
- 这是最基本的集群模式,其中一个 Redis 服务器作为主节点,而其他服务器作为从节点。
- 所有写操作都在主节点上执行,而从节点则复制主节点的数据。
- 当主节点出现故障时,可以手动或使用工具如 Sentinel 自动将一个从节点提升为新的主节点。
- 主从复制主要用于数据冗余和读取扩展。
-
Sentinel:
- Sentinel 是 Redis 的高可用性解决方案。
- 它监控主节点和从节点的健康状况,并在主节点故障时自动进行故障转移,将一个从节点提升为新的主节点。
- Sentinel 可以配置多个实例,以达到分布式和高可用性。
-
Redis Cluster:
- Redis Cluster 是 Redis 的原生集群解决方案,提供数据分片和高可用性。
- 数据被分为多个分片,每个分片存储在不同的节点上。
- Redis Cluster 支持多个主节点,每个主节点都可以有一个或多个从节点。
- 它使用一种名为“哈希槽”的机制来确定数据应存储在哪个节点上。
- 当一个主节点故障时,其对应的从节点可以被提升为新的主节点。
-
Twemproxy (Nutcracker):
- Twemproxy 是一个代理层,用于在 Redis 服务器之前进行数据分片。
- 它可以将客户端请求路由到适当的 Redis 服务器,并提供连接池和故障转移功能。
- Twemproxy 使得客户端无需知道后端的 Redis 节点,从而简化了客户端的逻辑。
-
Redis Enterprise:
- Redis Labs 提供的企业级版本,提供了许多高级功能,如跨地域复制、持久化选项和安全性增强。
根据应用的需求,可以选择合适的 Redis 集群模式。例如,对于读取密集型的应用,可以使用主从复制来扩展读取能力;而对于需要高可用性和数据分片的应用,Redis Cluster 可能是更好的选择。
4.1.1 sentinel和cluster一般是绑定在一起的吧
不完全是。Sentinel 和 Redis Cluster 是两种独立的高可用性解决方案,它们各自解决了不同的问题,并且可以独立使用。但在某些配置中,它们确实可以一起使用。
-
Sentinel:
- 主要关注点是高可用性。
- 它监控主节点和从节点,当主节点故障时,Sentinel 可以自动选择一个从节点并提升为新的主节点。
- Sentinel 适用于那些不需要数据分片但需要高可用性的场景。
-
Redis Cluster:
- 主要关注点是数据分片和高可用性。
- Redis Cluster 本身就具有故障转移能力。当一个主节点故障时,其对应的从节点会被自动提升为新的主节点。
- Redis Cluster 适用于那些需要数据分片和高可用性的场景。
在实际应用中,Redis Cluster 已经具有了故障转移的能力,因此不需要与 Sentinel 一起使用。但在早期的 Redis 版本中,当用户希望在使用数据分片的同时获得额外的高可用性保障时,他们可能会考虑将 Sentinel 和 Redis Cluster 一起使用。
总的来说,Sentinel 和 Redis Cluster 是两种独立的解决方案,但在某些特定的配置和早期版本中,它们可能会一起使用。然而,随着 Redis Cluster 的成熟,这种组合使用的情况已经变得较为少见。
4.1.2 sentinel集群本身是基于ap还是cp
让我们深入探讨 Sentinel 集群的一致性模型。
Redis Sentinel 本身的目标是为 Redis 主从复制提供高可用性。当我们谈论 Sentinel 的一致性模型时,我们主要关注两个方面:如何决定 Redis 主节点的故障状态以及如何选择新的主节点。
-
Sentinel 集群的一致性模型:
- Sentinel 之间的通信是基于 Gossip 协议的。当一个 Sentinel 判断主节点可能故障时,它会询问其他 Sentinel 节点来确认这一故障。
- 当大多数 Sentinel 节点都同意主节点故障时,它们会开始故障转移过程。
- 为了决定哪个 Sentinel 节点负责执行故障转移,Sentinel 节点之间会进行一个领导者选举过程。这个过程确保在任何给定时刻只有一个 Sentinel 节点执行故障转移。
-
从 CAP 理论的角度:
- Sentinel 更偏向于 AP(可用性和分区容错性)。它的设计目标是确保 Redis 的可用性,即使在网络分区或其他故障的情况下。
- Sentinel 可能会在短时间内产生不一致的视图,例如,当网络分区时,不同的 Sentinel 节点可能会有不同的看法关于主节点的健康状况。但是,通过多数投票的机制,Sentinel 最终会达成一致,并选择一个新的主节点。
总结:Redis Sentinel 集群本身,包括从节点的故障检测和 Sentinel 领导者的选举,更偏向于 AP 模型。它的主要目标是确保 Redis 的高可用性,而不是强一致性。

