
- 1一个心塞的手忙脚乱的项目结束后的总结_项目结束各奔天涯
- 2解决:IDEA无法下载源码,Cannot download sources, sources not found for: xxxx_idea sources not found for: cn.newgrand.sup:sup-co
- 3对java技术提升的定级总结_java提升技术的级别
- 4正则表达式-限定位数的正数_正则表达式限制位数
- 5SpringBoot 简单开发流程(详解)_springboot开发
- 6mitmdump 脚本使用python第三方包方法(报错:in script xxx.py: No module named ‘xxx‘)_mitmdump in script e:\work_code\appnium_frame\util
- 7CMake错误: Imported targets not available for * version, Could NOT find *, ... 解决_调试时target not available
- 8⭐算法入门⭐《二叉树》简单04 —— LeetCode 104. 二叉树的最大深度
- 9centos文件和目录权限(umask)_centos umask
- 10LLM微调过程中灾难性遗忘问题解决方法_大模型lora微调如何避免灾难性遗忘
【Redis】非关系型数据库之Redis的主从复制、哨兵和集群高可用
赞
踩
目录
一、主从复制、哨兵、集群的区别
- 主从复制:
主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复(手动恢复)。
缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
- 哨兵:
在主从复制的基础上,哨兵实现了自动化的故障恢复。
缺陷:写操作无法负载均衡;存储能力受到单机的限制;哨兵无法对从节点进行自动故障转移,在读写分离场景下,从节点故障会导致读服务不可用,需要对从节点做额外的监控、切换操作(脚本)。
- 集群:
通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
但是,成本比较高,通常至少三主三从,六台起步,成本比较高!!
二、主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master),后者称为从节点(Slave);数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
2.1主从复制的作用
- 数据备份
主从复制实现了数据的热备份,是持久化之外的一种数据备份方式。
- 故障恢复
当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡
在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基础
除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础
2.2主从复制的原理
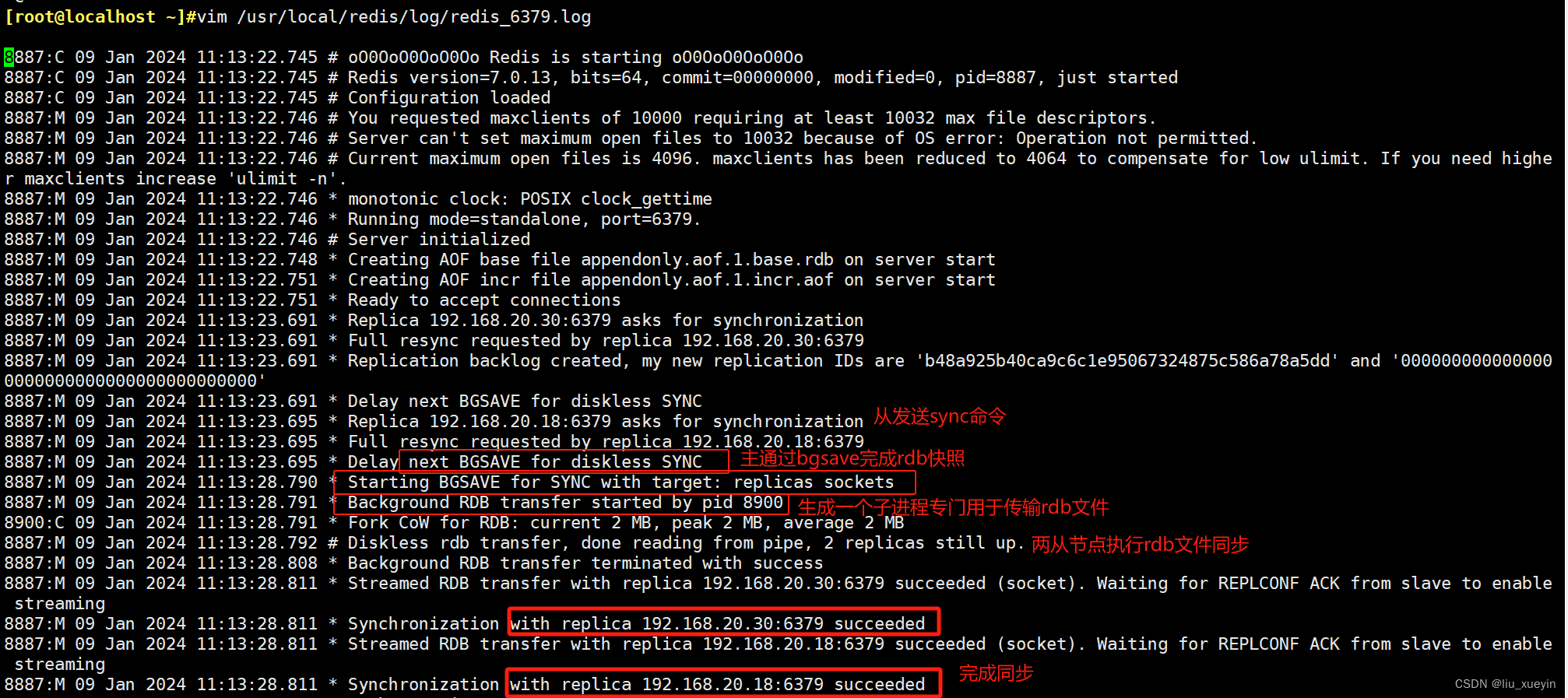
(1)若启动一个Slave机器进程,则它会向Master机器发送一个“sync command”命令,请求同步连接。
(2)无论是第一次连接还是重新连接,Master机器都会启动一个后台进程,将数据快照保存到数据文件中(执行rdb操作),同时Master还会记录修改数据的所有命令并缓存在数据文件中。
(3)后台进程完成缓存操作之后,Master机器就会向Slave机器发送数据文件,Slave端机器将数据文件保存到硬盘上,然后将其加载到内存中,接着Master机器就会将修改数据的所有操作一并发送给Slave端机器。若Slave出现故障导致宕机,则恢复正常后会自动重新连接。
(4)Master机器收到Slave端机器的连接后,将其完整的数据文件发送给Slave端机器,如果Master同时收到多个Slave发来的同步请求,则Master会在后台启动一个进程以保存数据文件,然后将其发送给所有的Slave端机器,确保所有的Slave端机器都正常。
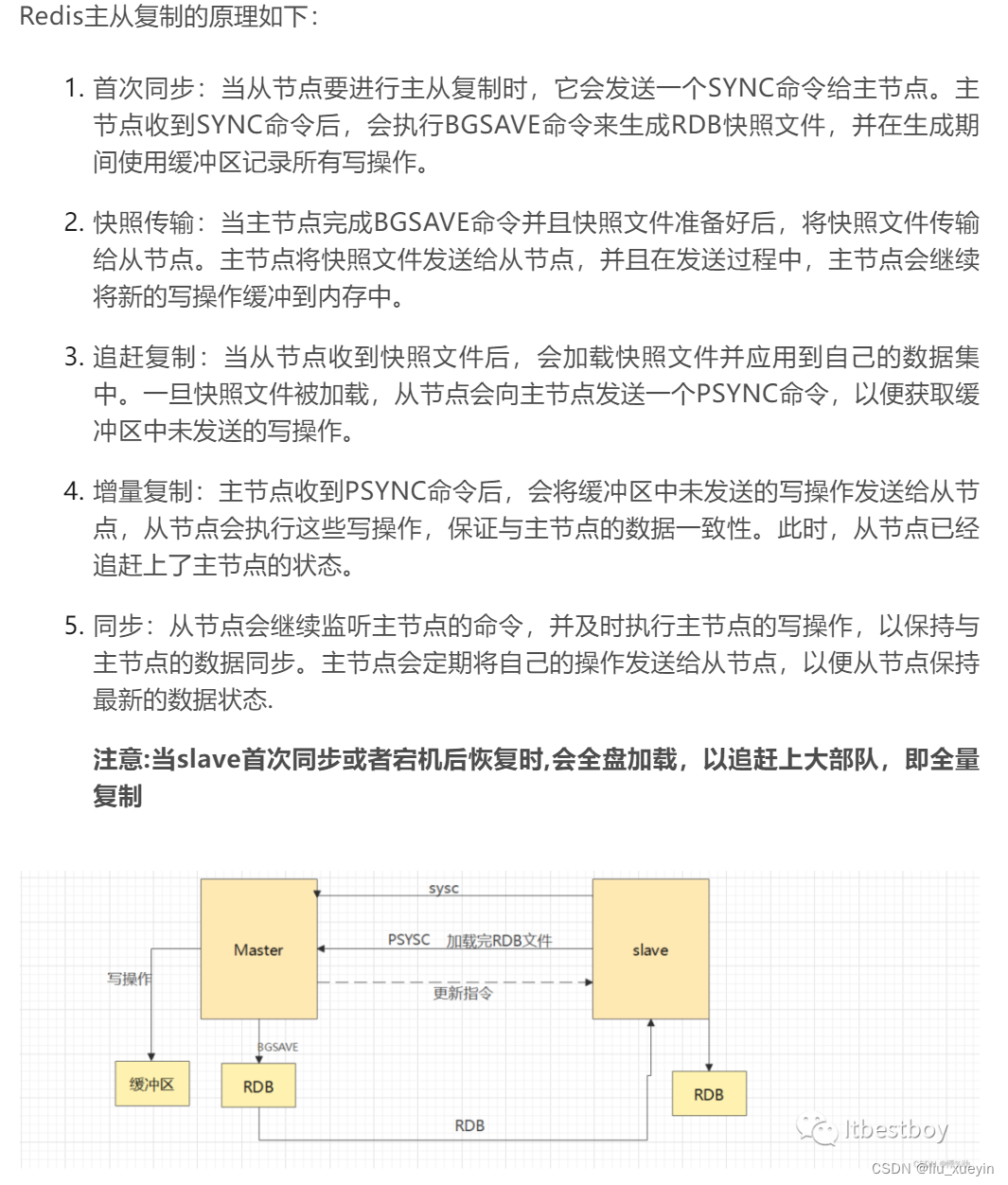
- 1、从节点给主节点发送sync命令,主节点则通过bgsave命令生成RDB快照文件,然后将其文件传给从节点,之后的写操作都记录在缓冲区;
- 2、从节点收到快照文件后执行保存到数据集中,然后再次给主发送psync命令,获取缓冲区的数据;
- 3、主节点发送缓冲区的写操作,从节点执行同步到数据集中,此时完成主从数据一致;
- 4、后续从节点会持续监测主,主节点也会定时给从节点发送写操作,从节点同步执行,实现主从数据一致;
-
- 注意:从节点首次同步以及宕机恢复都需要执行一次全量数据加载,即全量备份
2.3主从复制的实操
步骤一:环境准备
- //环境准备
- systemctl stop firewalld
- systemctl disable firewalld
- setenforce 0
- sed -i 's/enforcing/disabled/' /etc/selinux/config
-
- #修改内核参数
- vim /etc/sysctl.conf
- vm.overcommit_memory = 1
- net.core.somaxconn = 2048
-
- sysctl -p
步骤二:安装Redis以及配置文件修改
- //安装redis
- yum install -y gcc gcc-c++ make
-
- tar zxvf /opt/redis-7.0.13.tar.gz -C /opt/
- cd /opt/redis-7.0.13
- make
- make PREFIX=/usr/local/redis install
- #由于Redis源码包中直接提供了 Makefile 文件,所以在解压完软件包后,不用先执行 ./configure 进行配置,可直接执行 make 与 make install 命令进行安装。
-
- #创建redis工作目录
- mkdir /usr/local/redis/{conf,log,data}
-
- cp /opt/redis-7.0.13/redis.conf /usr/local/redis/conf/
-
- useradd -M -s /sbin/nologin redis
- chown -R redis.redis /usr/local/redis/
-
- #环境变量
- vim /etc/profile
- PATH=$PATH:/usr/local/redis/bin #增加一行
-
- source /etc/profile
-
-
- //定义systemd服务管理脚本
- vim /usr/lib/systemd/system/redis-server.service
- [Unit]
- Description=Redis Server
- After=network.target
-
- [Service]
- User=redis
- Group=redis
- Type=forking
- TimeoutSec=0
- PIDFile=/usr/local/redis/log/redis_6379.pid
- ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
- ExecReload=/bin/kill -s HUP $MAINPID
- ExecStop=/bin/kill -s QUIT $MAINPID
- PrivateTmp=true
-
- [Install]
- WantedBy=multi-user.target

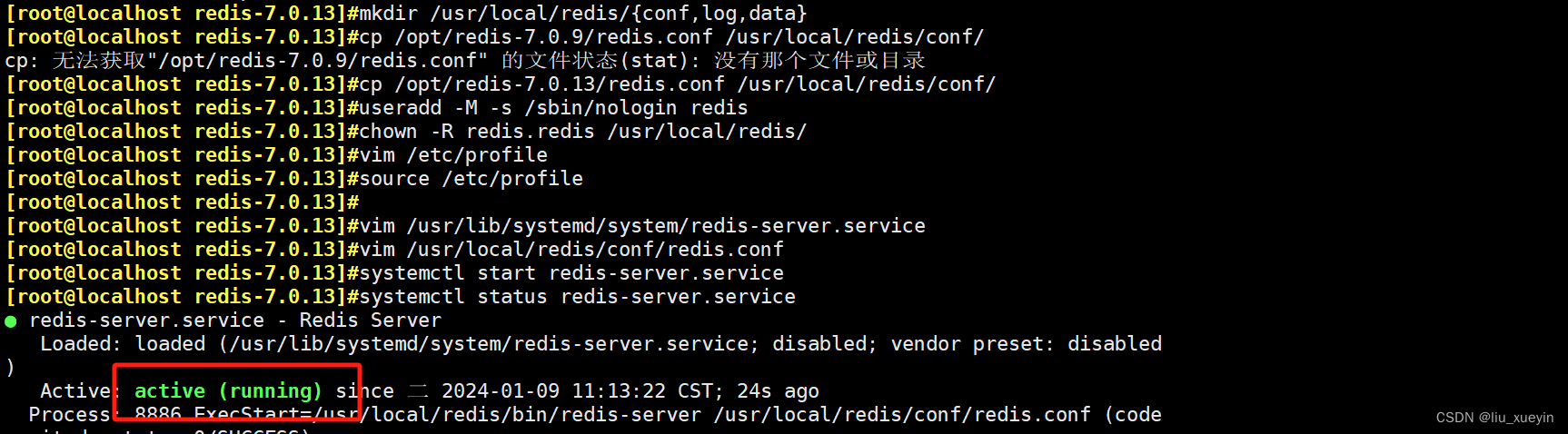
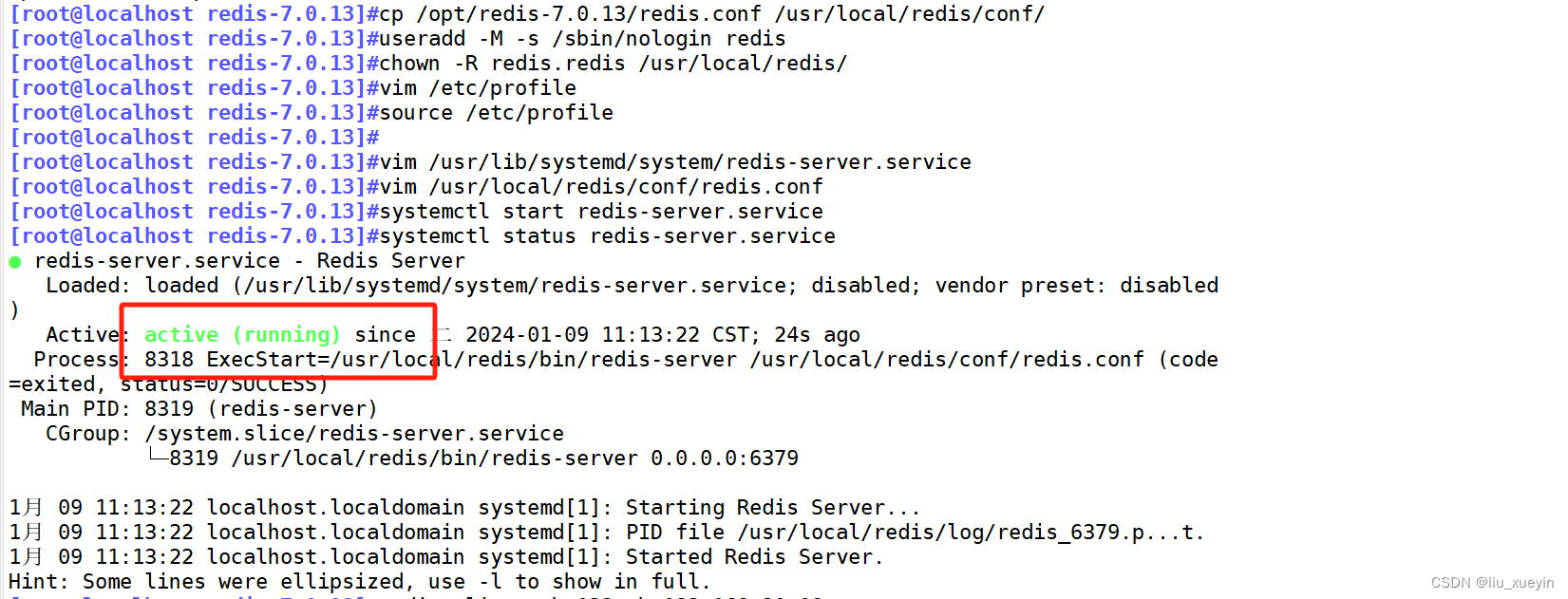
Redis的主从配置文件都一样
- -----修改 Redis 配置文件(Slave节点操作)-----
- vim /usr/local/redis/conf/redis.conf
- bind 0.0.0.0 #87行,修改监听地址为0.0.0.0
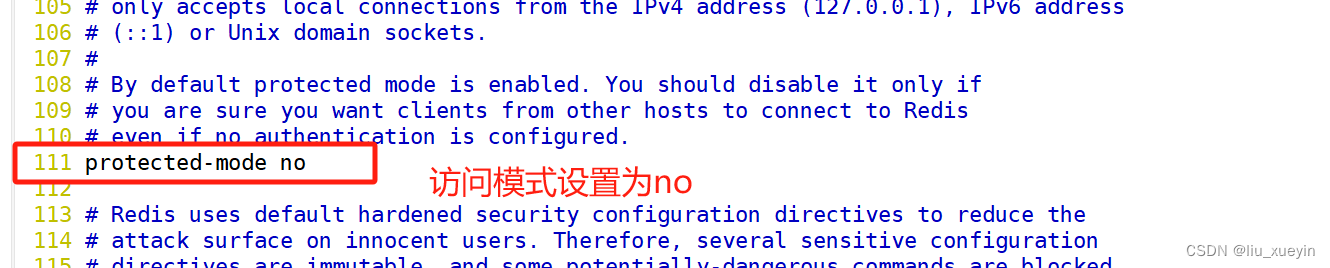
- protected-mode no #111行,将本机访问保护模式设置no
- port 6379 #138行,Redis默认的监听6379端口
- daemonize yes #309行,设置为守护进程,后台启动
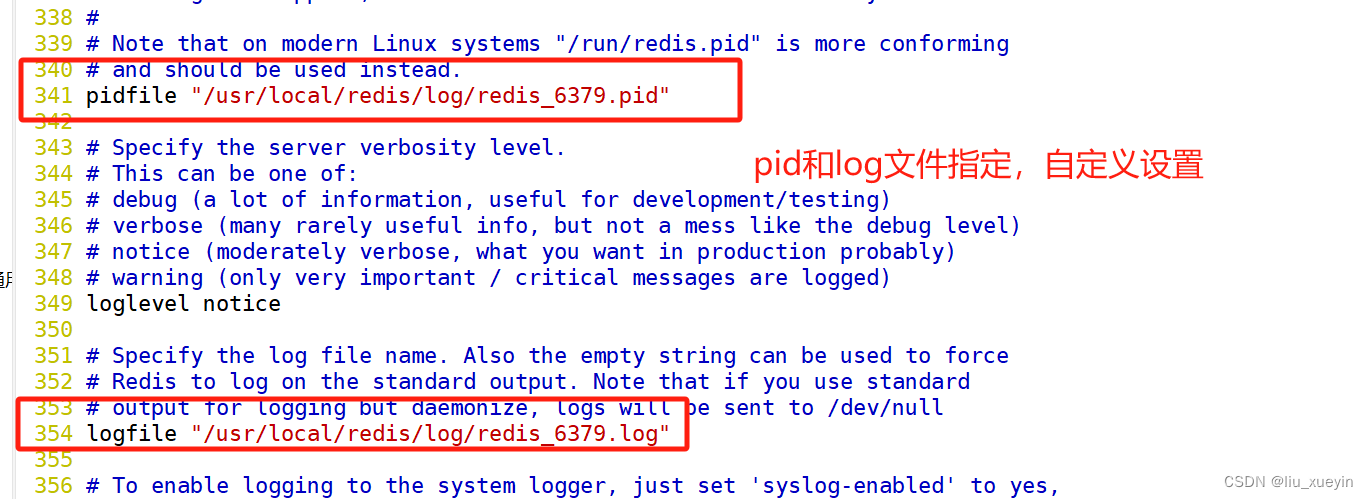
- pidfile /usr/local/redis/log/redis_6379.pid #341行,指定 PID 文件
- logfile "/usr/local/redis/log/redis_6379.log" #354行,指定日志文件
- dir /usr/local/redis/data #504行,指定持久化文件所在目录
- #requirepass abc123 #1037行,可选,设置redis密码
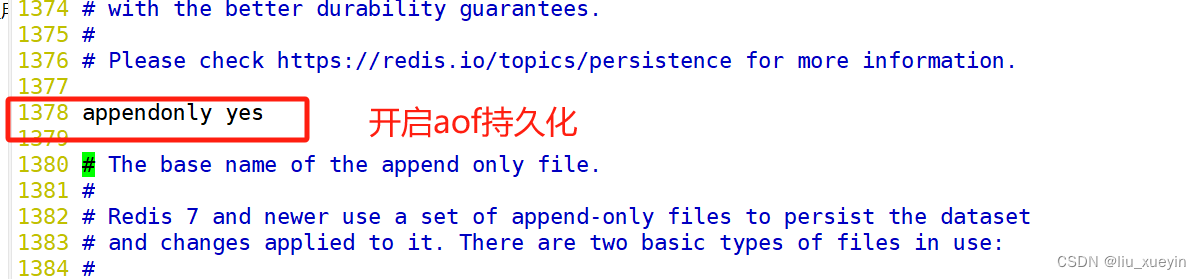
- appendonly yes #1380行,开启AOF
- replicaof 192.168.80.10 6379 #528行,指定要同步的Master节点IP和端口
- #masterauth abc123 #535行,可选,指定Master节点的密码,仅在Master节点设置了requirepass





步骤四:验证主从复制
方法一:通过日志来查看
方法二:在主上操作,验证读写分离与数据备份



三、哨兵
3.1哨兵的原理和功能
主从切换技术的方法是:当服务器宕机后,需要手动一台从机切换为主机,这需要人工干预,不仅费时费力而且还会造成一段时间内服务不可用。为了解决主从复制的缺点,就有了哨兵机制。
哨兵的核心功能:在主从复制的基础上,哨兵引入了主节点的自动故障转移。
3.2哨兵模式的作用
- 监控:哨兵会不断地检查主节点和从节点、还有哨兵节点是否运作正常。
- 自动故障转移:当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其它从节点改为复制新的主节点。
- 通知(提醒):哨兵可以将故障转移的结果发送给客户端。
哨兵结构由两部分组成,哨兵节点和数据节点:
●哨兵节点:哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的redis节点,不存储数据。
●数据节点:主节点和从节点都是数据节点。
3.3哨兵的原理
#故障转移机制:
1.由哨兵节点定期监控发现主节点是否出现了故障
每个哨兵节点每隔1秒会向主节点、从节点及其它哨兵节点发送一次ping命令做一次心跳检测。如果主节点在一定时间范围内不回复或者是回复一个错误消息,那么这个哨兵就会认为这个主节点主观下线了(单方面的)。当超过半数哨兵节点认为该主节点主观下线了,这样就客观下线了。
2.当主节点出现故障,此时哨兵节点会通过Raft算法(选举算法)实现选举机制共同选举出一个哨兵节点为leader,来负责处理主节点的故障转移和通知。所以整个运行哨兵的集群的数量不得少于3个节点。
3.由leader哨兵节点执行故障转移,过程如下:
●将某一个从节点升级为新的主节点,让其它从节点指向新的主节点,写vip会漂移到新的master;
●若原主节点恢复也变成从节点,并指向新的主节点;
●通知客户端主节点已经更换。
需要特别注意的是,客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
#主节点的选举:
1.过滤掉不健康的(已下线的),没有回复哨兵 ping 响应的从节点。
2.选择配置文件中从节点优先级配置最高的。(replica-priority,默认值为100)
3.选择复制偏移量最大,也就是复制最完整的从节点。
哨兵的启动依赖于主从模式,所以须把主从模式安装好的情况下再去做哨兵模式
3.4哨兵的实操
步骤一:完成主从复制(接着上面主从复制继续)
步骤二:完成哨兵节点的配置文件修改
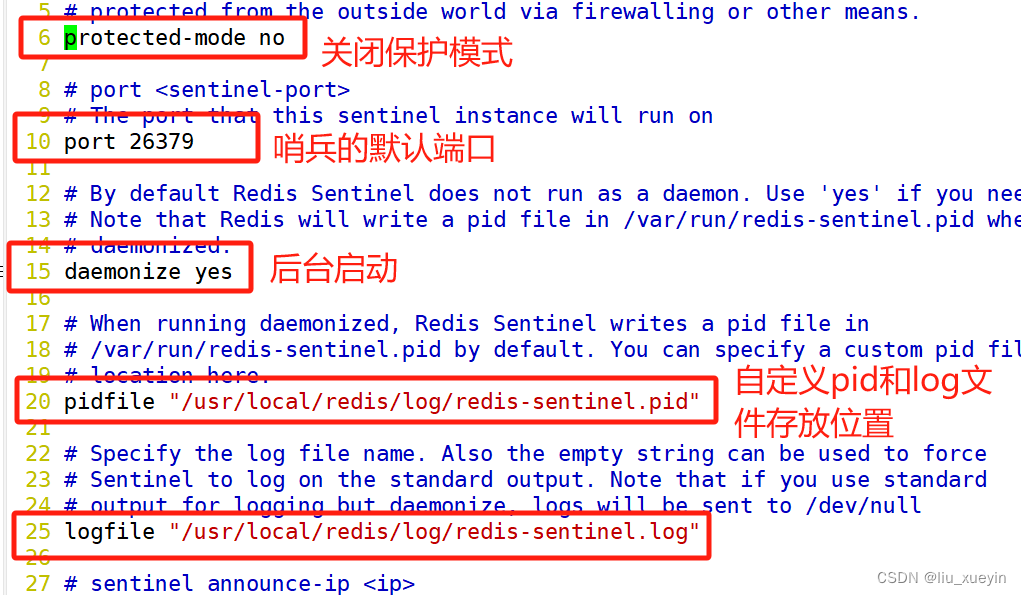
- -----修改 Redis 哨兵模式的配置文件(所有节点操作)-----
- cp /opt/redis-7.0.9/sentinel.conf /usr/local/redis/conf/
- chown redis.redis /usr/local/redis/conf/sentinel.conf
-
- vim /usr/local/redis/conf/sentinel.conf
- protected-mode no #6行,关闭保护模式
- port 26379 #10行,Redis哨兵默认的监听端口
- daemonize yes #15行,指定sentinel为后台启动
- pidfile /usr/local/redis/log/redis-sentinel.pid #20行,指定 PID 文件
- logfile "/usr/local/redis/log/sentinel.log" #25行,指定日志存放路径
- dir /usr/local/redis/data #54行,指定数据库存放路径
- sentinel monitor mymaster 192.168.80.10 6379 2 #73行,修改 指定该哨兵节点监控192.168.80.10:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移
- #sentinel auth-pass mymaster abc123 #76行,可选,指定Master节点的密码,仅在Master节点设置了requirepass
- sentinel down-after-milliseconds mymaster 3000 #114行,判定服务器down掉的时间周期,默认30000毫秒(30秒)
- sentinel failover-timeout mymaster 180000 #214行,同一个sentinel对同一个master两次failover之间的间隔时间(180秒)



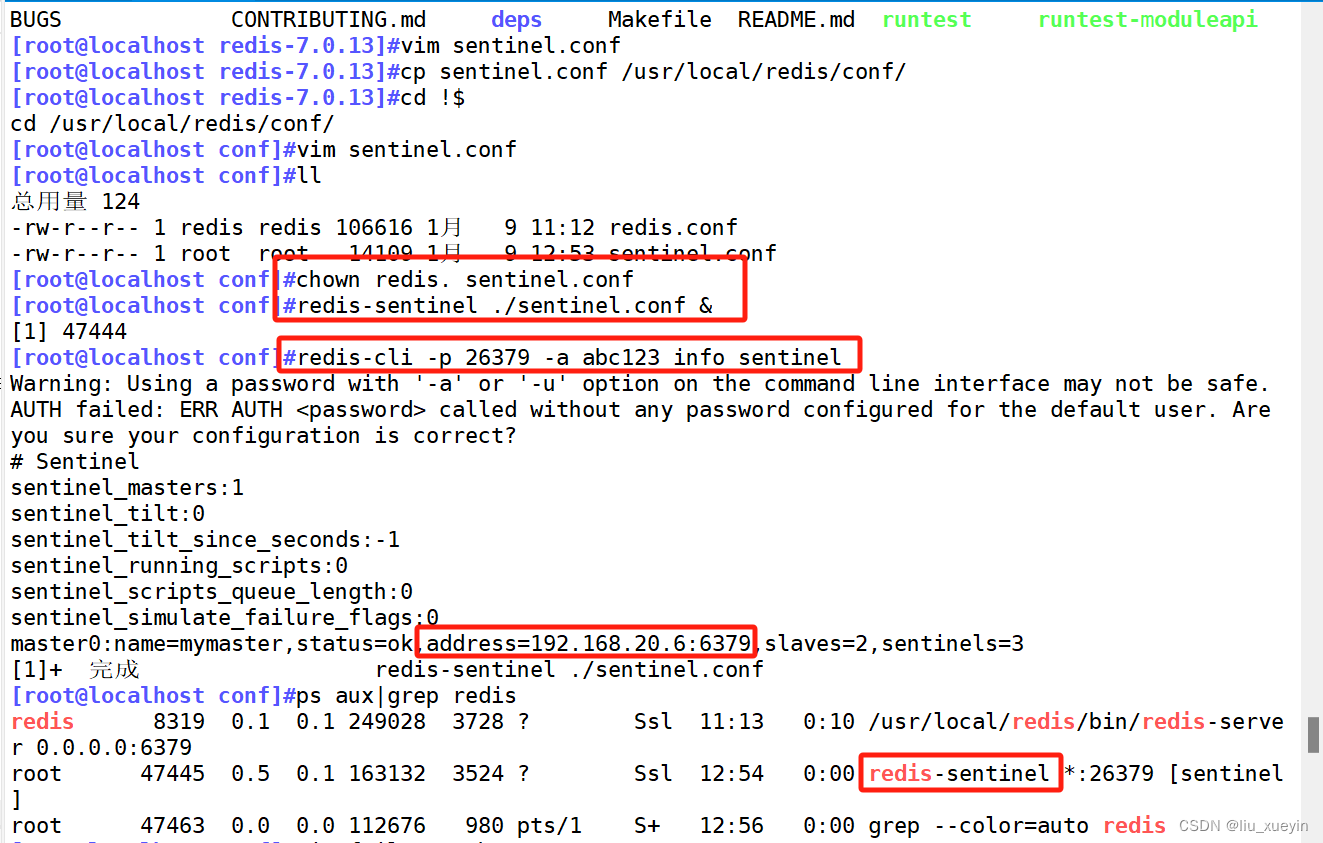
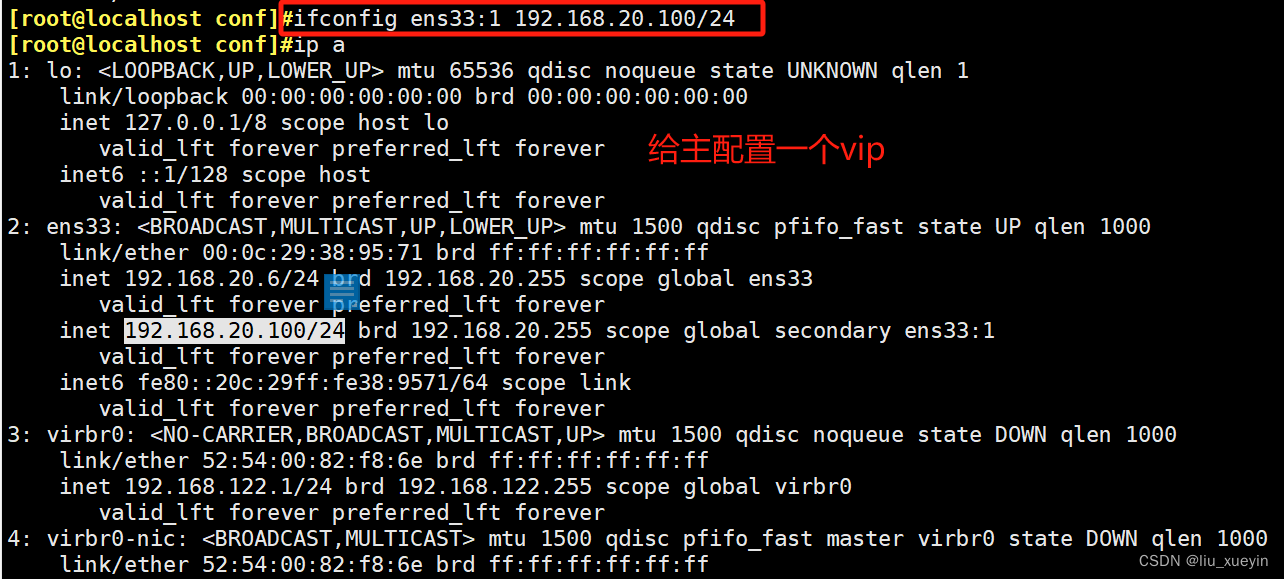
步骤三:完成故障切换时,vip漂移脚本
脚本文件需要在所有数据节点上有
255 sentinel client-reconfig-script mymaster /usr/local/redis/conf/failover.sh

- #!/bin/bash
- newmaster=$6
- oldmaster="$(ifconfig ens33|awk 'NR==2{print $2}')"
- vip="192.168.20.100"
-
- if [ $newmaster == $oldmaster ]
- then
- ifconfig ens33:1 $vip
- exit 0
- else
- ifconfig ens33:1 down
- exit 0
- fi
-
- exit 1

步骤四:重新启动哨兵

步骤五:模拟故障切换,验证自动切换以及vip漂移 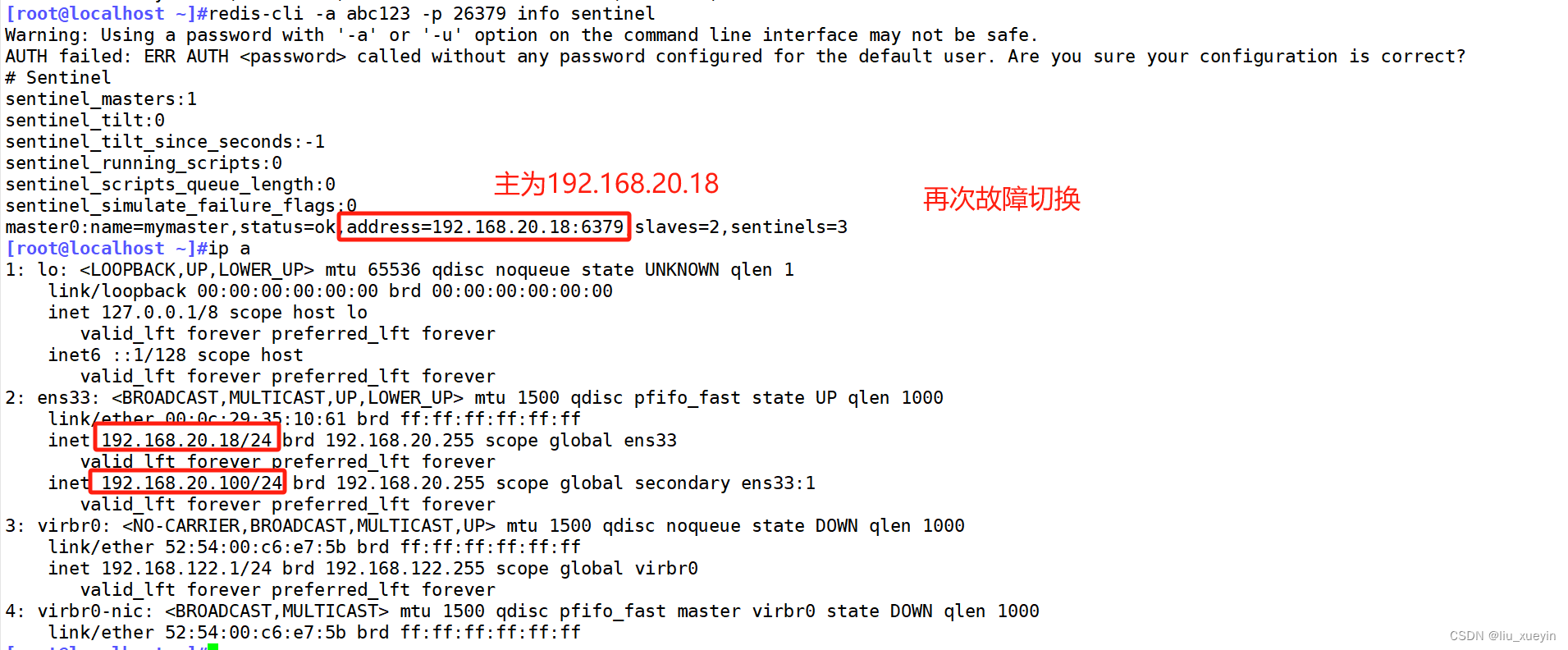
哨兵模式下两种查询主从的方式
- [root@localhost ~]#redis-cli -a abc123 -p 26379 info sentinel
-
- [root@localhost ~]#redis-cli -a abc123 -p 6379 info replication

哨兵日志查看

四、集群
4.1集群模式的特点
集群,即Redis Cluster,是Redis 3.0开始引入的分布式存储方案。
集群由多组节点(Node)组成,Redis的数据分布在这些节点中。集群中的节点分为主节点和从节点:只有主节点负责读写请求和集群信息的维护;从节点只进行主节点数据和状态信息的复制。
4.2集群模式的作用
(1)数据分区:数据分区(或称数据分片)是集群最核心的功能。
集群将数据分散到多个节点,一方面突破了Redis单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
Redis单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出。
(2)高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似);当任一节点发生故障时,集群仍然可以对外提供服务。
4.3集群模式的数据分片
Redis集群引入了哈希槽的概念
Redis集群有16384个哈希槽(编号0-16383)
集群的每组节点负责一部分哈希槽
每个Key通过CRC16校验后对16384取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
- #以3个节点组成的集群为例:
- 节点A包含0到5460号哈希槽
- 节点B包含5461到10922号哈希槽
- 节点C包含10923到16383号哈希槽
-
- #Redis集群的主从复制模型
- 集群中具有A、B、C三个节点,如果节点B失败了,整个集群就会因缺少5461-10922这个范围的槽而不可以用。
- 为每个节点添加一个从节点A1、B1、C1整个集群便有三个Master节点和三个slave节点组成,在节点B失败后,集群选举B1位为的主节点继续服务。当B和B1都失败后,集群将不可用。
4.4集群模式的原理
Redis集群的工作原理:
1、集群有多组节点,每组节点负责一部分哈希槽。
2、读写数据时,先针对key根据crc16的算法得出一个结果,然后把结果对 16384 取余。通过这个值去找到对应的哈希槽的节点,进行数据读写。
3、集群每组节点内做主从复制,当主节点宕机的时候,就会启用从节点。主节点负责读写请求和集群信息的维护;从节点负责主节点数据和状态信息的复制。
集群功能:
既可以实现高可用,又支持读写负载均衡,且可以横向扩容,更灵活。缺点成本高!
4.5集群模式的实操
- redis的集群一般需要6个节点,3主3从。方便起见,这里所有节点在同一台服务器上模拟:
- 以端口号进行区分:3个主节点端口号:6001/6002/6003,对应的从节点端口号:6004/6005/6006。
-
- cd /usr/local/redis/
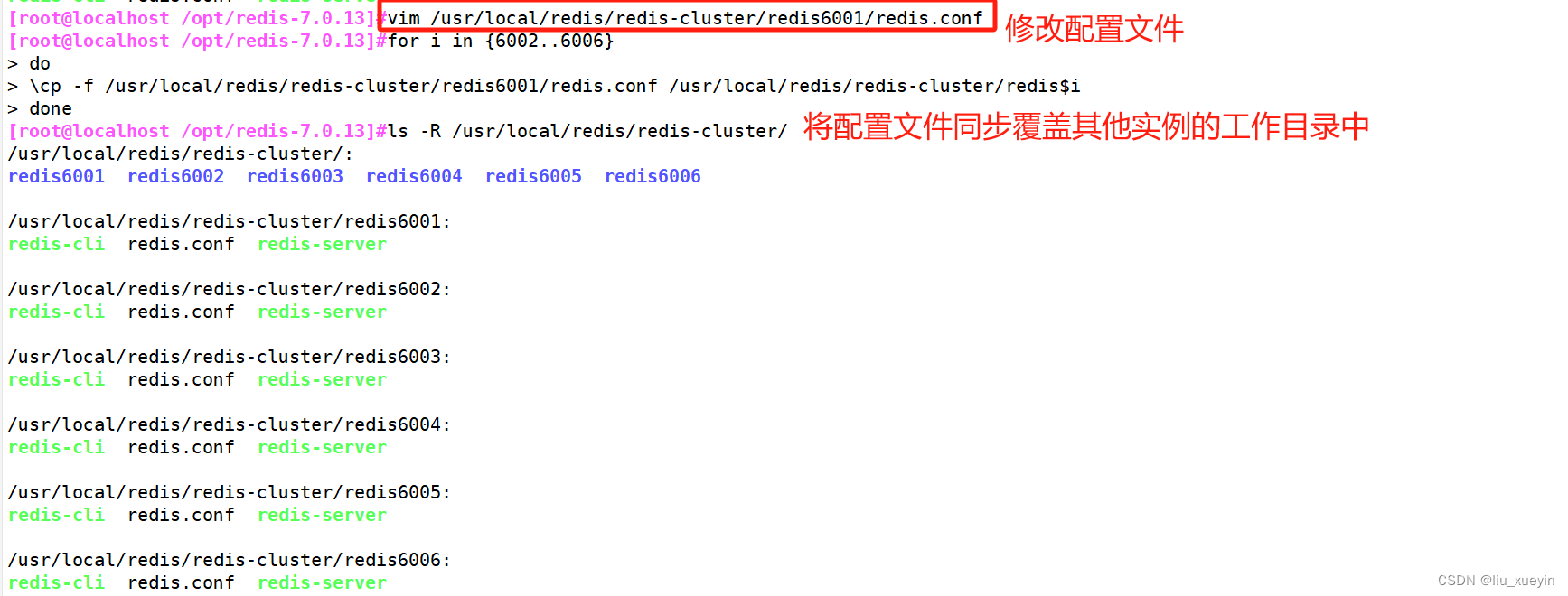
- mkdir -p redis-cluster/redis600{1..6}
-
- for i in {1..6}
- do
- cp /opt/redis-7.0.9/redis.conf /usr/local/redis/redis-cluster/redis600$i
- cp /opt/redis-7.0.9/src/redis-cli /opt/redis-7.0.9/src/redis-server /usr/local/redis/redis-cluster/redis600$i
- done
-
- #开启群集功能:
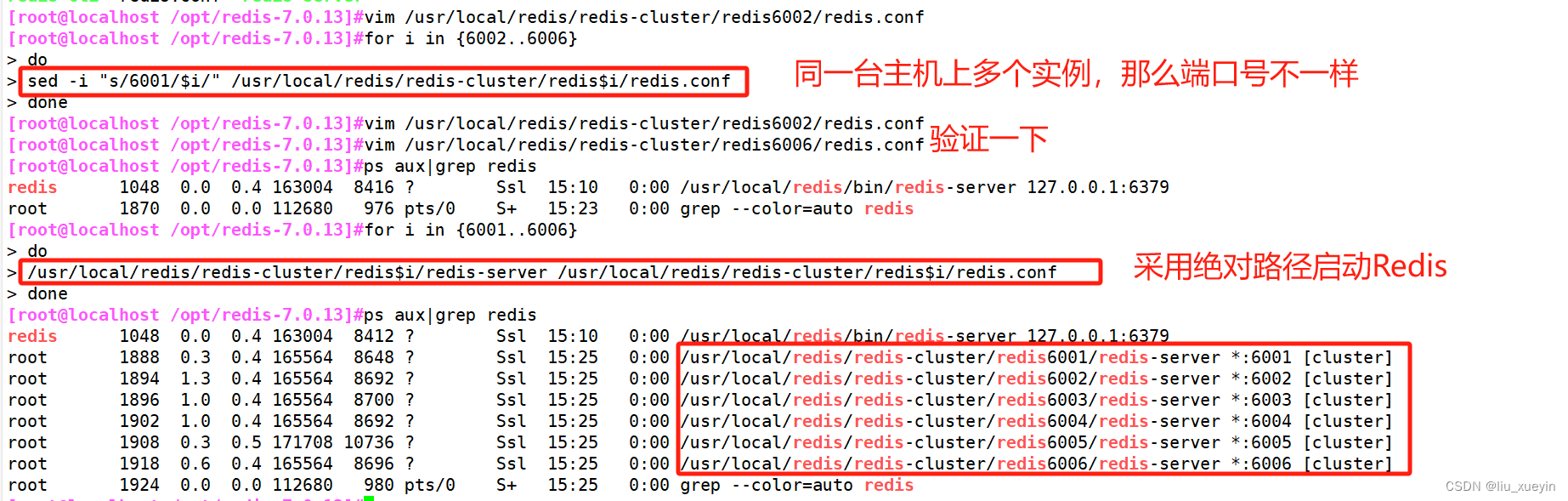
- #其他5个文件夹的配置文件以此类推修改,注意6个端口都要不一样。
- cd /usr/local/redis/redis-cluster/redis6001
- vim redis.conf
- #bind 127.0.0.1 #87行,注释掉bind项,默认监听所有网卡
- protected-mode no #111行,关闭保护模式
- port 6001 #138行,修改redis监听端口
- daemonize yes #309行,设置为守护进程,后台启动
- pidfile /usr/local/redis/log/redis_6001.pid #341行,指定 PID 文件
- logfile "/usr/local/redis/log/redis_6001.log" #354行,指定日志文件
- dir ./ #504行,指定持久化文件所在目录
- appendonly yes #1379行,开启AOF
- cluster-enabled yes #1576行,取消注释,开启群集功能
- cluster-config-file nodes-6001.conf #1584行,取消注释,群集名称文件设置
- cluster-node-timeout 15000 #1590行,取消注释群集超时时间设置
-
-
- #启动redis节点
- 分别进入那六个文件夹,执行命令:redis-server redis.conf ,来启动redis节点
- cd /usr/local/redis/redis-cluster/redis6001
- redis-server redis.conf
-
- for d in {1..6}
- do
- cd /usr/local/redis/redis-cluster/redis600$d
- ./redis-server redis.conf
- done
-
- ps -ef | grep redis
-
- #启动集群
- redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 1

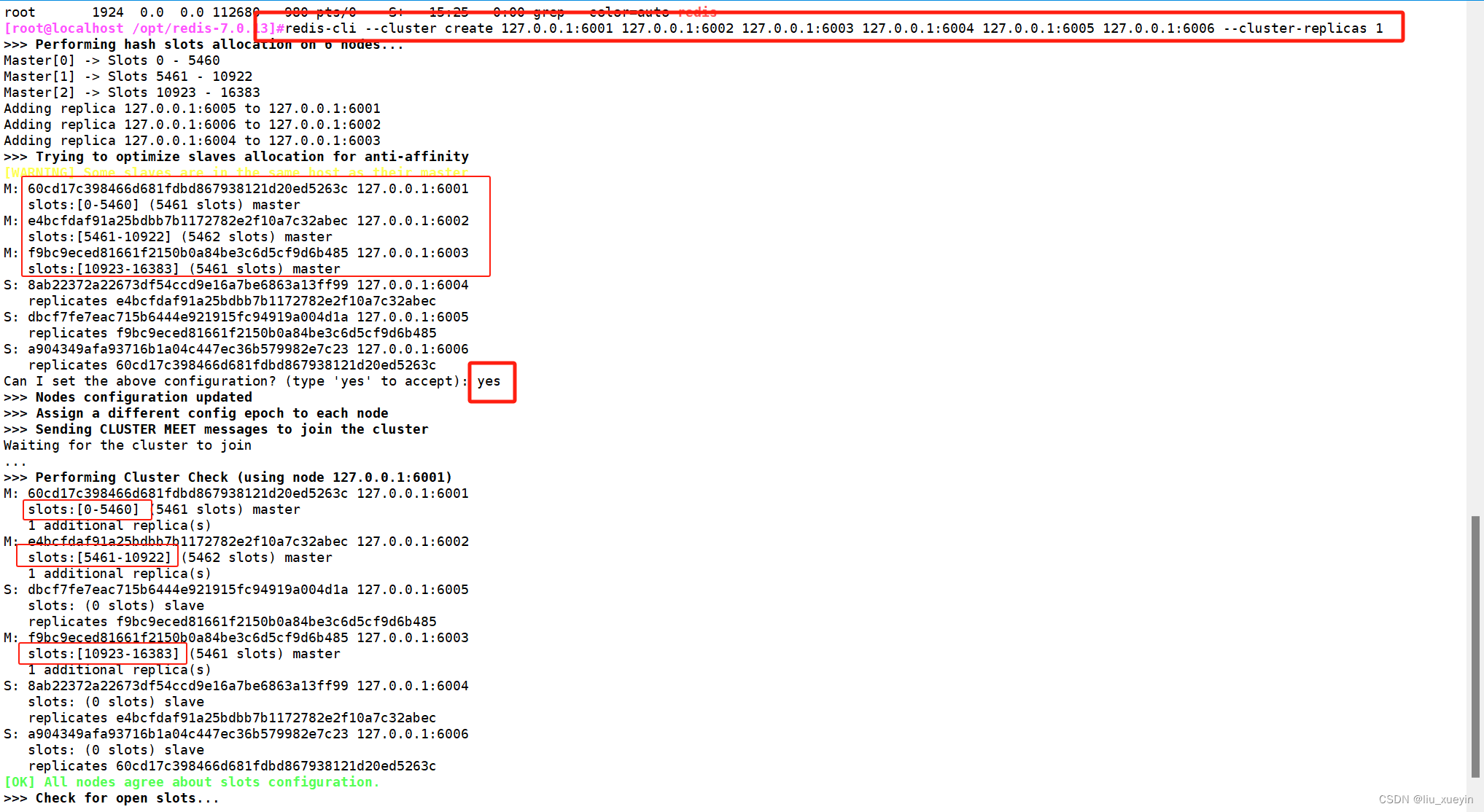
 结果验证
结果验证



4.6集群模式的扩容
- 已有集群为6个节点127.0.0.1:6001 - 127.0.0.1:6006,3组主从节点。现要增加第4组主从节点127.0.0.1:6007,127.0.0.1:6008
-
- 1.创建一个新的主节点127.0.0.1:6007。命令里需要指定一个已有节点以便于获取集群信息,本例是指定的127.0.0.1:6001
- redis-cli -p 6001 --cluster add-node 127.0.0.1:6007 127.0.0.1:6001
- 或
- redis-cli -p 6001
- cluster meet 127.0.0.1 6007
- cluster meet 127.0.0.1 6008
-
- 2.将127.0.0.1:6008创建为127.0.0.1:6007的从节点。命令里需要指定一个已有节点以便于获取集群信息和主节点的node ID
- redis-cli -p 6001 --cluster add-node 127.0.0.1:6008 127.0.0.1:6001 --cluster-slave --cluster-master-id e44678abed249e22482559136bf45280fd3ac281
- 或
- redis-cli -p 6008
- cluster replicate e44678abed249e22482559136bf45280fd3ac281
-
-
- 3.新加入的主节点是没有槽数的,只有初始化集群的时候,才会根据主的数据分配好,如新增的主节点,需要手动分配
- redis-cli -p 6007 --cluster reshard 127.0.0.1:6001 --cluster-from e1a033e07f0064e6400825b4ddbcd6680c032d10 --cluster-to e44678abed249e22482559136bf45280fd3ac281 --cluster-slots 1000 --cluster-yes
- 或
- redis-cli -p 6007 --cluster reshard 127.0.0.1:6001
- How many slots do you want to move (from 1 to 16384)? 1000 #指定转移槽的数量
- What is the receiving node ID? e44678abed249e22482559136bf45280fd3ac281 #指定接收槽数量的主节点node ID
- Please enter all the source node IDs.
- Type 'all' to use all the nodes as source nodes for the hash slots.
- Type 'done' once you entered all the source nodes IDs.
- Source node #1: e1a033e07f0064e6400825b4ddbcd6680c032d10 #指定分配的主节点node ID
- Source node #2: done #输入完毕,开始转移
-
-
- 4.查看集群状态
- redis-cli -p 6001 cluster nodes
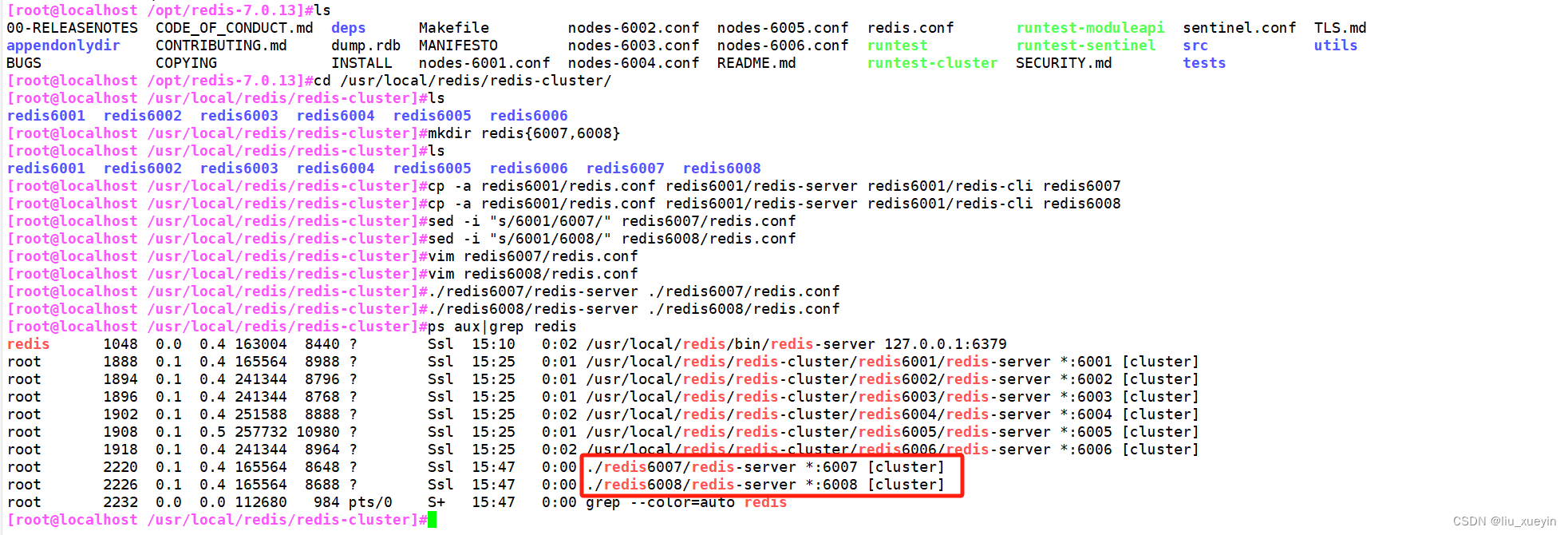
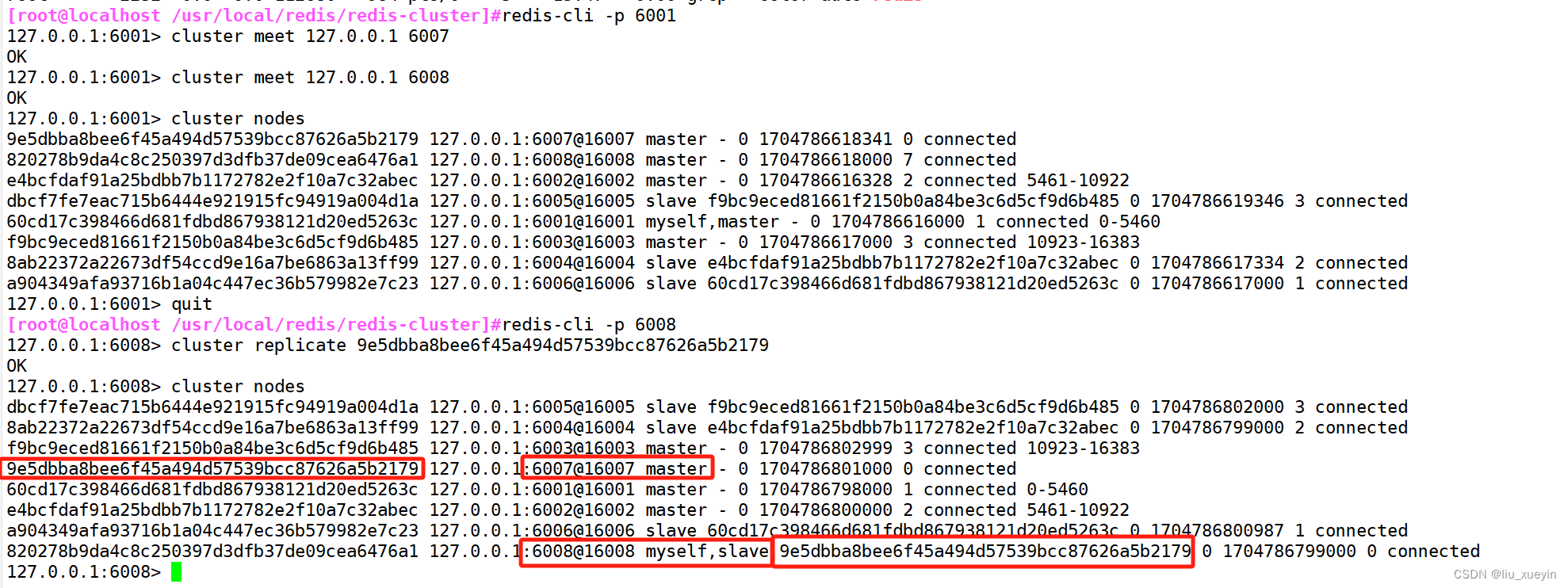


- ##查看集群信息
- redis-cli -p 6007 cluster nodes
- redis-cli -p 6007 cluster slots

