
- 1英伟达、Mistral AI 开源企业级大模型,120亿参数、可商用
- 2MongoDB中remove与deleteMany的区别?
- 3GIT-FORK项目后与原项目进行同步_github fork 同步release
- 4招标 | 近期隐私计算项目招标13(抗量子、区块链)_抗量子隐私计算一体机”
- 5[python] 基于词云的关键词提取:wordcloud的使用、源码分析、中文词云生成和代码重写...
- 6git提交代码报错husky > pre-commit_git: husky > pre-commit (node v14.21.3)
- 7groupby函数_干货分享|达梦数据库常用集函数与分析函数_达梦 group by用法
- 8极狐GitLab 如何和Mailgun 进行集成配置?
- 9lisp不是函授型语言_2020年人工智能的5种最佳编程语言
- 10TSDF算法原理及源码解析
数仓项目建设------思路及架构_数仓项目空间
赞
踩
离线数仓架构方案
经典传统数仓架构
阶段一: 1991年 比尔-恩门(bill inmon)出版第一版数据仓库的书, 标志数据仓库概念的确立, 称为恩门模型
主张自上而下的建设企业级数据仓库, 建设过程中需要满足三范式要求
从分散异构的数据源 -> 数据仓库 -> 数据集市
存在问题:
由于三范式的建模,导致在数据分析中数据易访问性和系统的性能均收到影响
阶段二: 拉尔夫·金博尔(ralph kimball)提出自下而上的建立数据仓库,整个过程中信息存储采用维度建模而非三范式
从数据集市-> 数据仓库 -> 分散异构的数据源
优点:
提出了维度建模新思路, 完全以数据分析便利性为前提建设, 推出了事实-维度模型
以最终任务为导向, 需要什么, 我们就建立什么
弊端:
随着业务的发展, 导致数据集市越来越多, 出现多个数据集的数据混乱和不一致的情况
阶段三: 1998年比尔-恩门(bill inmon)推出全新的CIF架构, 核心将数仓架构划分为不同的层次以满足不同场景的需求
如: ODS DW DA层等
从而明确各个层次的任务分工, 避免原有数据混乱和不一致的问题
而这种思想已经成为截止到今天的建设数据仓库的指南
离线大数据数仓架构
大数据中的数据仓库构建就是基于经典数仓架构而来,使用大数据中的工具来替代经典数仓中的传统工具,架构建设上没有根本区别
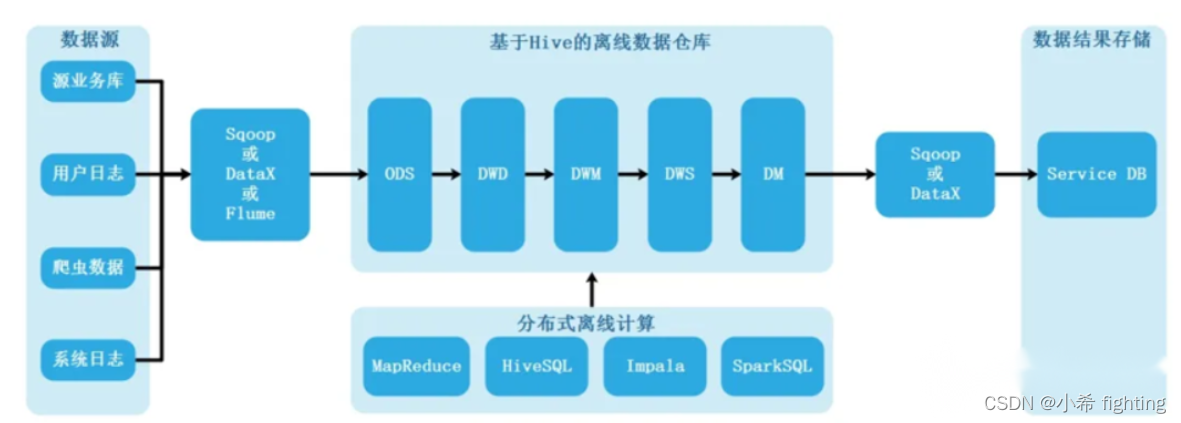
数据导入应该注意的问题
建模设计:需要考虑的问题
1.数据同步方式
2.表为内部表还是外部表
3.表为分区还是分桶
4.表存储和压缩方案
5.表字段选择
1- 数据的同步方式是什么? 全量覆盖同步: 在建表的时候, 不需要构建分区表, 每一次都是将之前的数据全部删除, 然后全部都重新导入一遍 适合于: 数据量比较少, 而且不需要维护历史变化行为 仅新增同步: 在建表的时候, 需要构建分区表, 分区字段是以更新的周期一致即可, 比如 更新的周期为天, 分区字段也应该为天, 每一次导入上一天的新增的数据 适合于: 数据量比较大, 而且不需要维护历史变化行为(并不代表表不存在变化, 只不过这个变化对分析没有影响) 新增及更新同步: 处理逻辑: 在建表的时候, 需要构建分区表, 分区字段是以更新的周期一致, 比如 更新的周期为天, 分区字段也应该为天,每一次导入上一天的新增及更新的数据 适合于: 数据量比较大, 而且需要后期维护历史变化 全量同步: 在建表的时候, 需要构建分区表, 分区字段以更新的周期一致即可, 比如 更新的周期为天, 分区字段也应该为天,每一次导入的时候, 都是将整个数据集全部导入到一个新的分区中, 后期定期删除老的历史数据(比如: 仅保留最近一周) 适合于: 数据量比较少, 而且还需要维护历史变化, 同时维度周期不需要特别长 注意: 此种同步方式相对较少 2- 表是否选择为内部表 还是 外部表? 判断的依据: 是否对数据有绝对的控制权, 如果没有 必须是外部表, 如果有 随意 3- 表是否为分区表还是分桶表? 分区表: 分文件夹, 将数据划分到不同的文件夹中, 当查询数据的时候, 通过分区字段获取对应分区下的数据, 从而减少数据扫描量, 提高查询效率 分桶表: 分文件 将数据根据指定的字段划分为N多个文件 可以通过这种方式对数据进行采样操作 以及分桶表在后续进行join优化的时候也会涉及到(bucket Map Join | SMB Join) 4- 表选择什么存储格式 和 压缩方案? 存储格式: 一般都是 ORC / Text File 压缩格式: 一般都会 SNAPPY / GZ 存储格式: 如果数据直接对接的普通文本文件的操作 只能使用textFile 否则大多数都是ORC 压缩格式: 读多写少 采用SNAPPY 写多读少 采用GZ 如果普通的文本文件对接, 一般不设置压缩 如果空间比较充足, 没有特殊要求, 建议统一采用SNAPPY 5- 表中字段应该如何选择呢? ODS层: 业务库有那些表, 表中有哪些字段, 对应在ODS层建那些表, 表中对应有相关的字段 额外根据同步方式, 选择是否添加分区字段 其他层次: 不同层次 需要单独分析, 目标: 把需求分析的结果能够完整的在表中存储起来即可

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
数仓设计和维度域开发
数据仓库基本概念
什么时数据仓库?
存储数据的仓库,主要用于存储过去历史发生过的数据,面向主题,对数据进行统计分析的操作,从而能够对未来提供决策支持
- 1
数据仓库最大的特点时什么?
数据仓库既不产生数据,也不消耗数据,数据来源于各个数据源
- 1
数据仓库的四大特征?
1-面向主题
2-集成性
3-稳定性(非易失性)
4-时变性
主题域通常是联系较为紧密的数据主题的集合。
数据域是指面向业务分析,将业务过程或者维度进 行抽象的集合。
主题域和数据域的区别:
1)主题域:面向业务过程,将业务活动事件进行抽象的集合,如下单、支付、退款都是业务过程,针对公共明细层(DWD 及 DWM)进行主题划分。
2)数据域:面向业务分析,将业务过程或者维度进行抽象的集合,针对公共汇总层(DWS)进行数据域划分。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
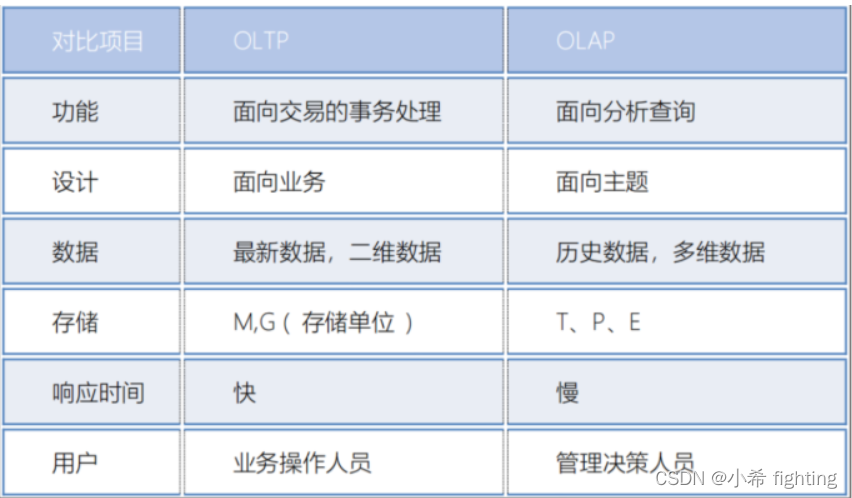
OLAP和OLTP的区别:
什么是ETL:
etl: 抽取 转换 加载
狭义上etl:
指的是数据从ODS层抽取出来,对ODS层的数据进行清洗转换处理操作,将清洗转换后的数据加载到DW层过程
广义上etl:
指的是数仓的全过程
- 1
- 2
- 3
- 4
- 5
- 6
什么是数据仓库和数据集市:
数据仓库是包含数据集市的,在一个数据仓库中可以有多个数据集市
数据仓库:一般指的构建集团数据中心,基于业务形成各种业务的宽表或者统计宽表
数据集市:基于部门或者基于主题,形成主题或者部门相关的统计宽表
- 1
- 2
- 3
- 4
数仓分层介绍
ODS:源数据层(临时存储层)贴源层
作用:对接数据源,用于将数据源的数据完整导入到ODS层中,一般ODS层的数据和数据源的数据保持一致,类似于一种数据迁移的操作,一般在ODS层建表的时候,会额外增加一个日期的分区,用于标记何时进行数据采集
DW:数据仓库层
作用:用于进行数据统计分析的操作,数据来源于ODS层
APP(DA|ADS|RPT|ST):数据应用层(数据展示层)
作用:存储分析的结果信息,用于对接相关的应用,比如:可视化报表
- 1
- 2
- 3
- 4
- 5
- 6
数仓分层的作用:
1-清晰数据结构
2-复杂问题简单化
3-便于维护
4-减少重复开发
5-高性能
数仓建模方案
关系建模
关系建模包含:
ER建模:实体(矩形)、关系(菱形)、属性(椭圆形)
三范式(大白话):
第一范式:表中字段不可分割
第二范式:表中有直接或间接依赖的主键
第三范式:表中没有间接依赖的主键
- 1
- 2
- 3
- 4
- 5
- 6
维度建模
维度建模将复杂的业务通过事实和维度两个概念进行呈现,事务通常对应业务过程,而维度通常对应业务过程发生时所处的环境.
事实表:指的主题,要统计的主题是什么,对应事实就是什么,而主题所对应的表,就是事实表 事实表一般是一堆主键(外键的聚集) 事实表一般是反应了用户的某种行为 事实表分类: 事务事实表 : 最初始确定的事实表 其实就是事务事实表 周期快照事实表: 指的对数据进行提前聚合后表, 比如将事实表按照天聚合统计 结果表 累计快照事实表: 每一条数据, 记录了完整的事件 从开始到结束整个流程, 一般有多个时间组成 维度表: 当对事实表进行统计分析的时候, 可能需要关联一些其他表进行辅助, 这些表其实就是维度表 维度表一般是由平台或者商家来构建的表, 与用户无关, 不会反应用户的行为 比如说: 地区表 商品表 时间表, 分类表... 维度表分类: 高基数维度表: 如果数据量达到几万 或者几十万 甚至几百万的数据量, 一般这样维度表称为高基数维度表 比如: 商品表 , 用户表 低基数维度表: 如果数据量只有几条 或者 几十条 或者几千条, 这样称为低基数维度表 比如: 地区表 时间表 分类表 配置表
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
数据三种模型
1.星型模型:
特点:只有一个事实表,也就意味着只有一个分析的主题,在事实表周围围绕多张维度表,维度表与维度表没有任何关联
数仓发展阶段:初期
2.雪花模型:
特点:只有一个事实表,也就意味着只有一个分析的主题,在事实表周围围绕着多张维度表,维度表可以接着关联其他维度表
数仓发展阶段:异常,出现畸形状态,在实际数仓中,这种模型建议越少越好,尽量避免这种模型产生
3.星座模型:
特点:有多张事实表,也就意味着有多个分析的主题,在事实表周围围绕了多张维度表,在条件吻合的情况下,事实表之间是可以共享维度表
数仓发展阶段:中期和后期
建模设计
维度建模一般按照以下四个步骤:选择业务过程—声名粒度—确认维度—确认事实
1-选择业务过程
在业务系统中,挑选业务方感兴趣的业务线,比如下单业务,支付业务,退款业务,物流业务,一条业务线对应一张事实表。
2-声名粒度
数据粒度指数据仓库的数据中保存数据的细化程度或综合程度的级别。
声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。
典型的粒度声明如下:
订单事实表中一行数据表示的是一个订单中的一个商品项。
支付事实表中一行数据表示的是一个支付记录。
3-确定维度
维度的主要作用是:描述业务的事实情况。主要表示的是“谁,何处,何时”等信息。
确定维度的原则是:后续需求中是否要分析相关维度的指标。例如,需要统计什么时间下的订单多,哪个地区下的订单多,哪个用户下的订单多。需要确定的维度就包括:时间维度、地区维度、用户维度。
4-确认事实
此处的“事实”一词,指的是业务中的度量值(次数、个数、件数、金额,可以进行累加),例如订单金额、下单次数等。
在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
事实表和维度表的关联比较灵活,但是为了应对更复杂的业务需求,可以将能关联上的表尽量关联上。


