
- 1Oracle数据库迁移至达梦8数据库(windows图文讲解)_oracle达梦8数据库数据迁移
- 2深度学习 --- 优化入门二(SGD、动量(Momentum)、AdaGrad、RMSProp、Adam详解)_随机统一动量
- 3万字长文,解读大模型技术原理(非常详细)零基础入门到精通,收藏这一篇就够了_本地大模型 工作原理
- 4BP神经网络代码实现
- 5Android RadioButton,定制按钮样式_android radiobutton样式
- 6Redis安装与配置_redis官网
- 7富文本编辑器插件vue-quill-editor手动插入图片_quilleditor组件图片控件
- 8西瓜书第二章总结_西瓜书第二章看不懂
- 9探索音乐创新:DDSP - 一个开源的音频生成和处理工具
- 10自动驾驶-决策规划算法七:B样条曲线(C++)_b样条曲线 c++
模型卡和解释模型的标准化文档的重要性_model cards for model reporting
赞
踩
文件被官方定义为提供官方信息或证据的材料,作为记录。从机器学习的角度来看,特别是关于在生产环境中部署的模型,文档应该作为注释和描述,以帮助我们完整地理解模型。最终,有效的文档使我们的模型能够被我们与之交互的许多利益相关者所理解。
无论我们是部署满足基本和非敏感需求的低影响模型,还是部署具有重大成果(例如贷款批准)的高影响模型,我们都有责任保持透明——不仅对我们的最终用户,而且对我们的内部利益相关者。此外,不应该只有数据科学家掌握支持模型的所有知识——它应该是开放的、可访问的和任何人都可以理解的。
一份文件来统治他们
当然,不同的团队出于不同的原因需要文档。作为一个实验,我问同事他们需要什么文档。
我的数据科学家同事说,他们需要内嵌代码文档,以便在需要接管代码库时更好地理解它。他们还表示,他们需要性能指标记录以及数据集和特征集的日志,以便他们可以重现实验、复制模型参数和超参数。
产品团队表示,他们希望了解业务用例以及如何与构建模型或应用程序的数据科学家和开发人员取得联系,因为他们需要了解有关功能敏感性的信息并能够回答客户的问题。
法律团队表示,他们想了解公平和偏见之类的东西,即在提供公平结果时,所使用的方法将确保模型是长期可持续的。记录模型中是否使用个人身份信息 (PII) 及其相应权限的能力也是必不可少的。
以用户友好的方式向技术理解和能力各不相同且对信息有不同要求的团队提供正确的信息是一项重大挑战。
在我的团队中,我们有一个与Databricks环境同步的 GitHub 存储库,其中包含用于我们的管道和工作流的脚本。我们保留了一个标准化的 README 模板,其中概述了模型的目的、开发人员信息、模型的架构、论文参考以及模型所服务的产品团队。此外,我们跟踪和记录模型开发过程中的数据科学对话,从想法到问答,再到模型验证。我们还使用MLFlow跟踪所有实验,并记录模型参数、超参数、数据集、特征集、性能指标、验证图表等。我们喜欢我们的设置,但如果我们的产品和法律团队想要出于自己的目的访问这些数据,他们会立即遇到障碍。

数据科学团队所需信息的表示
首先,团队中的任何新成员都必须请求访问我们的组织资源,例如 GitHub、Databricks 和我们的 Azure Active Directory。
其次,他们对信息过载感到震惊——他们并不总是关心查看可排序的实验日志,而且大部分数据与他们无关。
最后,他们不习惯我们使用的工具,习惯于使用易于使用的格式(例如 PDF 和 HTML)制作电子表格和报告,这些格式在视觉上很简单,并且可以轻松共享。那么,作为数据科学家,我们如何向其他团队公开我们模型所需的信息呢?
介绍模型卡
2019年,谷歌发布了一篇名为《Model Cards for Model Reporting 》的论文.” 谷歌面临与我们相同的挑战,因为他们看到没有设定的文档程序标准来传达有关 ML 模型的信息,并且每个人都需要共同理解。从内容到流程再到公平和隐私, 很高兴看到所有人都在考虑文档。他们甚至有一个 Python 库,但它不像我们需要的那样灵活,也没有按照我们团队的要求量身定制。作为参考,谷歌的论文建议记录模型详细信息、预期用途、指标、评估数据、道德考虑、建议等。这是一个很棒的列表,但我们自己为模型卡库提供了新外观,并为我们的数据产品和法律团队。
在 Google 所做的基础上,我们希望为每个团队创建一组包含适量信息的卡片。经过讨论,我们达成协议记录以下内容:
- 业务信息,例如业务部门、产品以及高级和详细的描述
- 存储库信息,例如我们的 Databricks 环境和 GitHub 存储库
- 开发者信息和联系方式
- 如果存在 PII,则突出显示轻量数据集信息
- 一些模型架构信息
- 一个特征表,它揭示特征是否被认为是敏感的以及它们是如何创建的
- 验证指标和图表
- 培训电力的可持续性,记录可解释性的部分,以及偏见和公平的部分
- 此外,开发人员可以在他们的卡片上添加注释,以获取他们希望其他团队知道的任何相关信息。
我们希望我们的卡片具有非常干净和扁平的外观,并且能够生成漂亮的 HTML 文档。我们围绕一些语义 UI 组件创建了一个 Python 包装器,这些组件将在文件后面生成 HTML、CSS 和 JavaScript。通过一个简单的 API 来添加信息和排序网格,它为数据科学团队提供了轻松的灵活性,可以将他们在管道中生成的信息直接集成到模型卡中。它完成了所有各方都在寻找的一组共享信息,一个漂亮的外观和感觉,一个交互式且易于共享的文件,标准化且易于我们的数据科学家集成到他们的工作流程中。
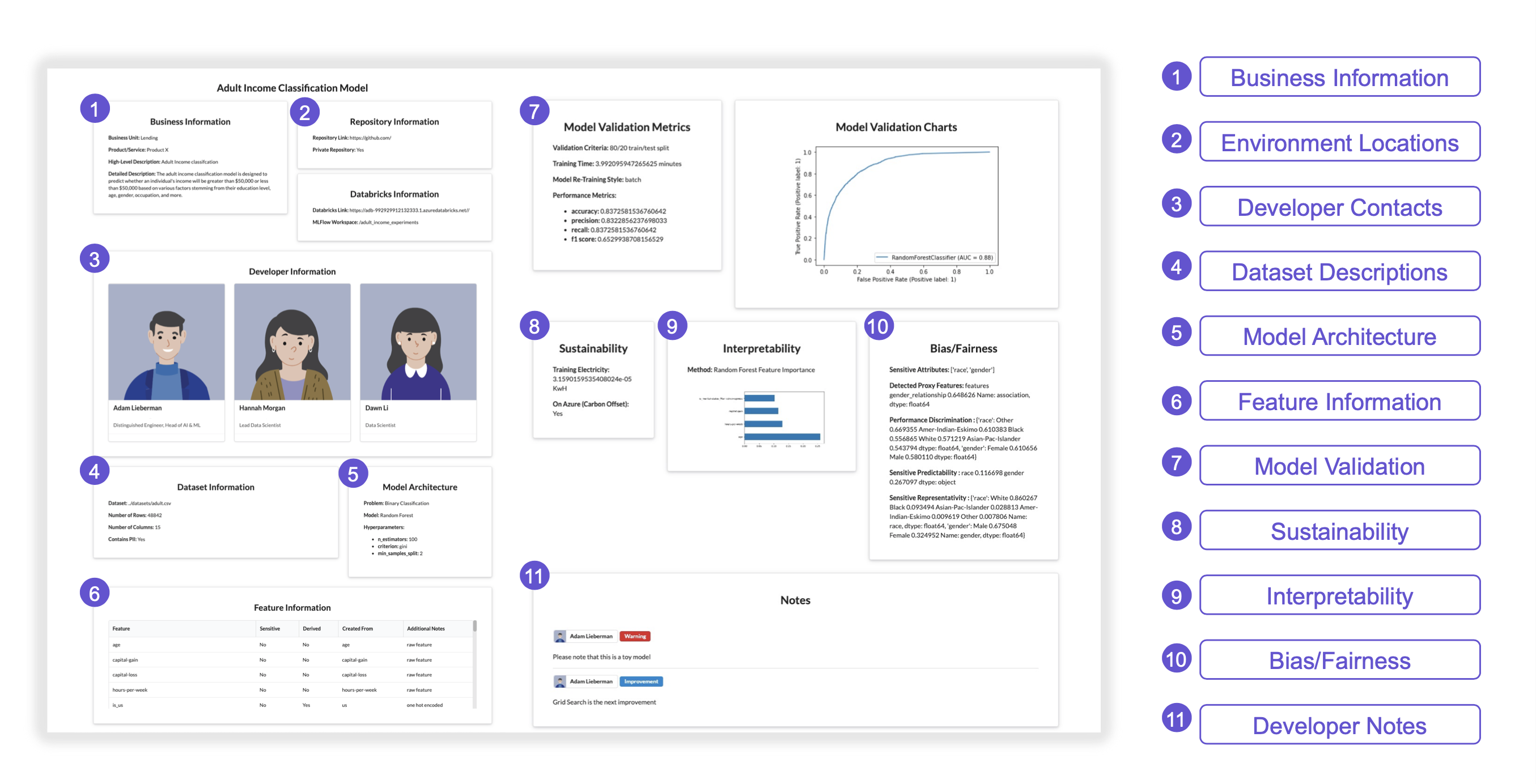
一张模型卡,让用户可以快速访问与他们相关的信息
采取量身定制的方法
对我们的团队与来自不同背景和领域的所有利益相关者合作时,对模型卡进行试验是一次有趣且有用的探索。建立我们的基础设施并为我们的数据科学家和工程师创造一个舒适流畅的环境是一个漫长的旅程。但是还有很多工作要做,并且对于建模卡甚至MLOps 基础设施的标准化方法没有一个正确的答案。
我的实施更适合我组织内部利益相关者的需求,以帮助他们与数据科学团队协作。然而,仍然需要以与行业无关的方式标准化模型卡。为了建立这个标准,我将向更广泛的数据科学社区提出以下问题:
- 从 ML 的角度来看,在您的公司/行业中记录什么是重要的?
- 谁是您的主要利益相关者?
- 我们如何才能更好地规范这个过程?
- 我们如何确保为开发模型的数据科学家提供尽可能无缝的附加文档?
- 我们如何才能最好地为我们的非技术团队分享和可视化结果?

