
热门标签
热门文章
- 1“智算”雄起 | 青云科技:智算中心建设、运营两不误
- 2万界星空科技MES系统:食品加工安全的实时监控与智能管理
- 3【PyTorch】解决 No module named ‘torchvision.models.utils‘_no module named 'torchvision.models.utils
- 4如何提交代码到github仓库(2022最新最详细)_github上传代码到仓库
- 5概念:四种基于模型的嵌入式软件开发、测试与验证方法_嵌入式软件建模技术
- 6vscode找不到git
- 7springboot+mysql网上书店管理系统的设计与实现—计算机毕业设计03780
- 8SVN的使用---Windows环境:概述、安装配置、使用详解、多仓库与权限控制、服务配置与管理、扩展程序_svn配置
- 9Antd Form 表单实现单项自定义请求校验_antd form自定义校验
- 10<12>基础知识——进一步了解路由表_路由表和子网
当前位置: article > 正文
爬table数据_Python爬虫 福布斯排行榜 数据可视化
作者:我家自动化 | 2024-07-17 11:26:24
赞
踩
基于python对福布斯排行榜
来源:zuiziyoudexiao 链接:
https://blog.csdn.net/zuiziyoudexiao/article/details/108227085
使用 python requests 库爬取福布斯排行榜数据存放到本地excel文件,并通过matplotlab将数据进行分析和可视化
原网页如下所示
https://www.phb123.com/renwu/fuhao/shishi.html

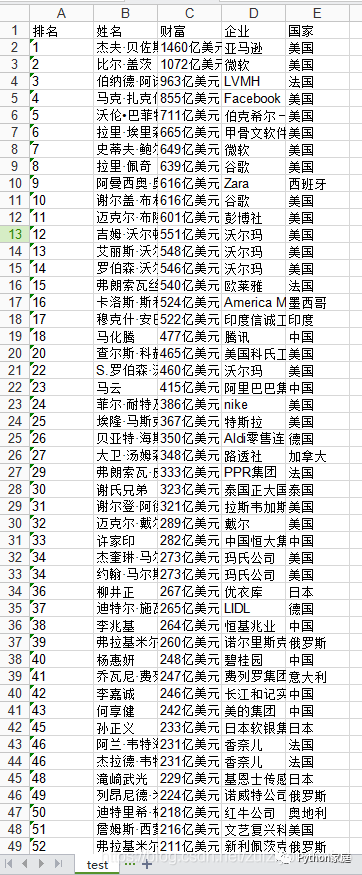
1. 保存的excel数据
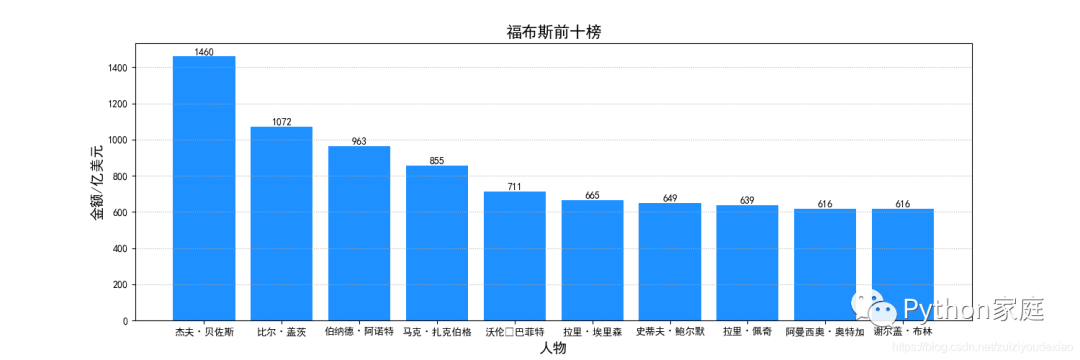
2. 福布斯前十排行的数据可视化效果
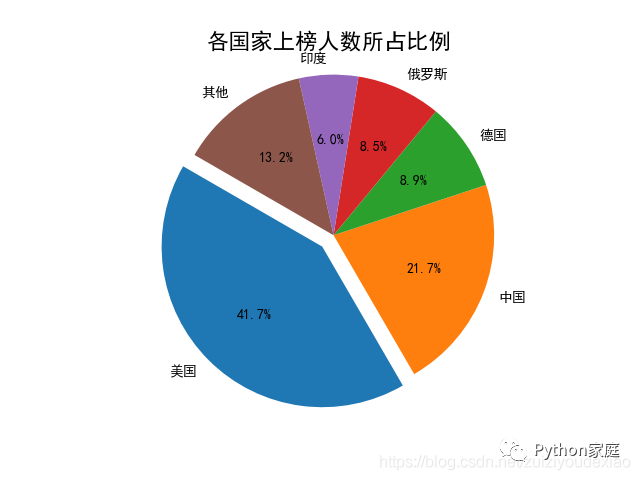
3. 各国上榜人数所占比例的统计与可视化
4. 爬取网页数据解析为一个list集合
- ## 读取一页的数据def loaddata(url):from bs4 import BeautifulSoupimport requestsheaders = {
- 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/72.0.3626.121 Safari/537.36'}f = requests.get(url,headers=headers) #Get该网页从而获取该html内容soup = BeautifulSoup(f.content, "lxml") #用lxml解析器解析该网页的内容, 好像f.text也是返回的html# print(f.content.decode()) #尝试打印出网页内容,看是否获取成功ranktable = soup.find_all('table',class_="rank-table" )[0] #获取排行榜表格trlist = ranktable.find_all('tr') #获取表格中所有tr标签trlist.pop(0) #去掉第一个元素persionlist = []for tr in trlist:persion = {}persion['num'] = tr.find_all('td')[0].string #编号persion['name'] = tr.find_all('td')[1].p.string #名称persion['money'] = tr.find_all('td')[2].string #财产persion['c
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/839623
推荐阅读
相关标签

