
MiniGPT-4:开源的可看图聊天的识图AI模型_图片识别ai模型
赞
踩
引言
ChatGPT-4的推出,展示了许多令人印象深刻的功能。例如ChatGPT-4可以产生非常详细和准确的图像描述、解释不寻常的视觉现象,甚至基于手写文本指令构建网站。尽管ChatGPT-4表现出了非凡的能力,但其卓越能力背后的方法仍然是个谜。
但现在不一样了,来自阿卜杜拉国王科技大学的人员推出了类似产品 ——MiniGPT-4,也具有识别图片功能。
MiniGPT-4介绍
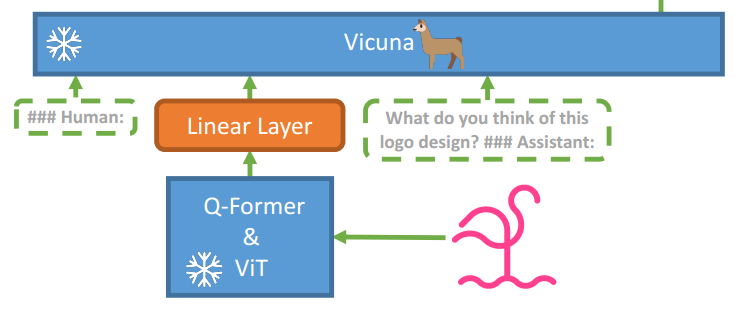
来自King Abdullah University of Science and Technology(阿卜杜拉国王科技大学)的Deyao Zhu* , Jun Chen*, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny 提出了MiniGPT-4,它只使用一个投影层将冻结的视觉编码器与冻结的LLM Vicuna对齐。
他们的研究结果表明,MiniGPT-4具有许多与GPT-4类似的功能,如通过手写草稿生成详细的图像描述和创建网站。此外,他们还观察到MiniGPT-4中的其他新兴功能,包括根据给定的图像创作故事和诗歌,为图像中显示的问题提供解决方案,教用户如何根据食物照片烹饪等。
在实验中,他们发现,只有对原始图像-文本对进行预训练,才能产生缺乏连贯性的非自然语言输出,包括重复和碎片句子。为了解决这个问题,他们在第二阶段策划了一个高质量、对齐良好的数据集,以使用对话模板微调我们的模型。事实证明,这一步骤对于增强模型的生成可靠性和整体可用性至关重要。值得注意的是,他们的模型计算效率很高,因为他们只使用大约500万对对齐的图像-文本对来训练投影层。
MiniGPT-4官方网站:Minigpt-4
MiniGPT-4 GitHub地址:GitHub - Vision-CAIR/MiniGPT-4: MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models
MiniGPT-4论文地址:MiniGPT-4/MiniGPT_4.pdf at main · Vision-CAIR/MiniGPT-4 · GitHub
MiniGPT-4中文教程:MiniGPT-4中文教程

MiniGPT-4模型
MiniGPT-4由一个带有预训练的ViT和Q-Former的视觉编码器、一个单一的线性投影层和一个高级的Vicuna大型语言模型组成。MiniGPT-4只需要训练线性层,使视觉特征与Vicuna对齐。
这个标志设计简单而简约,画了一只火烈鸟单腿站在水中的粉红色线条。该设计简洁易识别,适合在各种场合使用,如海滩度假胜地或火烈鸟主题活动的标志。使用火烈鸟作为象征为设计增添了一丝奇思妙想和乐趣,使其令人难忘和引人注目。总的来说ÿ

