
- 1python123循环结构_来学Python啦,大话循环结构~
- 2kmeans python自定义初始聚类中心_机器学习-KMeans聚类 K值以及初始类簇中心点的选取...
- 3知识增强版BERT:让NLP更智能,更强大
- 4测试老鸟,Python接口自动化测试框架搭建-全过程,看这篇就够了..._python接口自动化框架
- 5浏览器内核,chrominum = blink = webkit+_blink内核
- 6【Verilog HDL实践】状态机:8路彩灯控制程序
- 7oracle的merge into操作详解_merge into oracle
- 8微信小程序云开发静态网站h5跳小程序_微信云静态网页图片
- 9cnn 示意图_基于BERT+CNN及GRU语言模型的司法考试问答模型
- 10Android Studio环境搭建
ES 分布式搜索的运行机制
赞
踩
ES 分布式搜索的运行机制
ES 有两种 search_type 即搜索类型:
•query_then_fetch (默认)•dfs_query_then_fetch
query_then_fetch

query_then_fetch
1.用户发起搜索,请求到集群中的某个节点。2.query 会被发送到所有相关的 shard 分片上。3.每个 shard 分片独立执行 query 搜索文档并进行排序分页等,打分时使用的是分片本身的 Local Term/Document 频率。4.分片的 query 结果(只有元数据,例如 _id 和 _score)返回给请求节点。5.请求节点对所有分片的 query 结果进行汇总,然后根据打分排序和分页,最后选择出搜索结果文档(也只有元数据)。6.根据元数据去对应的 shard 分片拉取存储在磁盘上的文档的详细数据。7.得到详细的文档数据,组成搜索结果,将结果返回给用户。
缺点:由于每个分片独立使用自身的而不是全局的 Term/Document 频率进行相关度打分,当数据分布不均匀时可能会造成打分偏差,从而影响最终搜索结果的相关性。
dfs_query_then_fetch
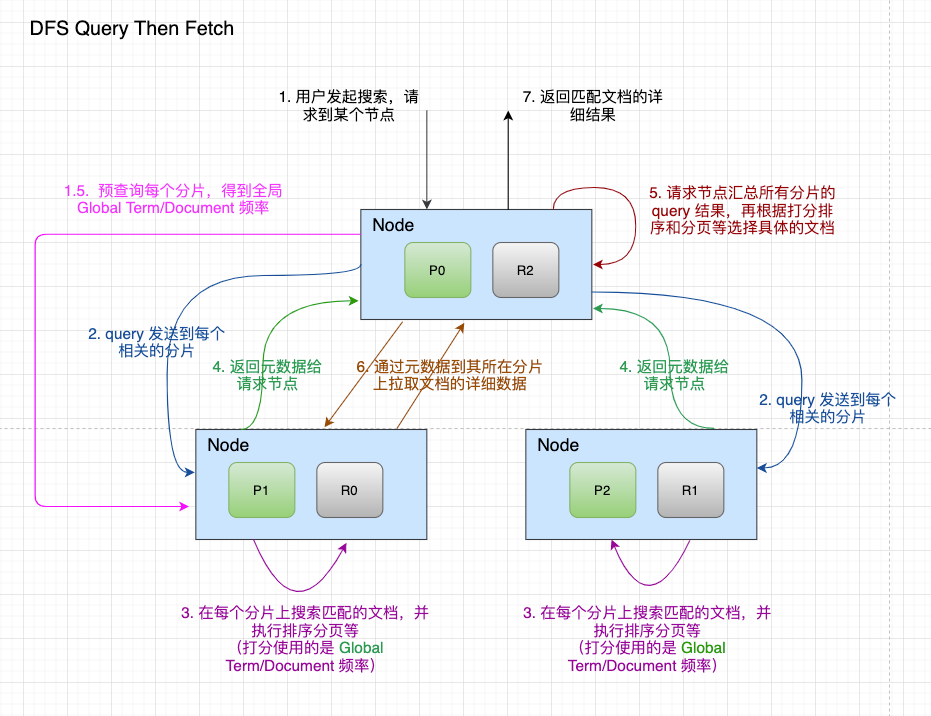
dfs_query_then_fetch
dfs_query_then_fetch 与 query_then_fetch 的运行机制非常类似,但是有两点不同。
1.用户发起搜索,请求到集群中的某个节点。2.预查询每个分片,得到全局的 Global Term/Document 频率。3.query 会被发送到所有相关的 shard 分片上。4.每个 shard 分片独立执行 query 搜索文档并进行排序分页等,打分时使用的是分片本身的 Global Term/Document 频率。5.分片的 query 结果(只有元数据,例如 _id 和 _score)返回给请求节点。6.请求节点对所有分片的 query 结果进行汇总,然后根据打分排序和分页,最后选择出搜索结果文档(也只有元数据)。7.根据元数据去对应的 shard 分片拉取存储在磁盘上的文档的详细数据。8.得到详细的文档数据,组成搜索结果,将结果返回给用户。
缺点:太耗费资源,一般还是不建议使用。
经验
•虽然 ES 有两种搜索类型,但一般还是都用默认的 query_then_fetch 。•当数据量没有足够大的情况下(比如搜索类型数据 20GB,日志类型数据 20-50GB),设置一个 shard 主分片是比较推荐的,只设置一个主分片,你会发现搜索时省掉好多事情。•不需要文档数据时,使用 _source: false 可以避免请求节点到非本机分片的网络耗时以及读取磁盘文件的耗时。•使用 from + size 分页时,假设你只需要前 10k 条数据里的最后十条,那么每个分片也会取 10k 条数据,如果你的索引有 5 个主分片,那么汇总时就有 5 * 10k = 50k 条数据,这 50k 条数据是在内存里进行排序和最后的分页的,所以深度分页也是比较吃资源的。

