
- 101.SpringBoot商城项目之前后端界面搭建
- 22024年计算机视觉、设计与算法国际会议( ICCVDA 2024)_iccv 2024
- 3直播app源码,流媒体自建好还是用第三方好_app中实现直播功能是自己搭建直播平台还是用其他平台
- 4python从原始代码(matplotlib)到加图形界面(tkinter),最后到制作软件(一元二次方程软件)(如何做一个python软件)_一元二次方程python代码有界面
- 5什么是软件外包_什么是计算机应用基础软件外包
- 6数据结构与算法 经典题库练习_数据结构与算法题库
- 7【追梦少年】互联网产品如何引爆_互联网产品 引爆
- 8在python中使用Queue获得多进程处理结果_python多进程queue
- 9Leetcode - 周赛394_list
- 10【Python】统计文本中单词的出现次数前十的单词_python统计出现频率最高的10个单词
Python_vperfect.meidd.xyz
赞
踩
预备知识:
Python还提供了列表、字典等多种数据类型,还允许创建自定义数据类型。Python的注释以 # 开头,后面的文字直到行
尾都算注释# 这一行全部都是注释...print 'hello' # 这也是注释 会输出hello如果一个字符串包含很多需要转义
的字符,对每一个字符都进行转义会很麻烦。为了避免这种情况,我们可以在字符串前面加个前缀 r ,表示这是一个 raw 字符串,里面的字符就不需要转义了。例如:r'\(~_~)/ \(~_~)/'
但是r'...'表示法不能表示多行字符串,也不能表示包含'和 "的字符串(为什么?)
如果要表示多行字符串,可以用'''...'''表示:
'''Line 1
Line 2
Line 3'''
上面这个字符串的表示方法和下面的是完全一样的:
'Line 1\nLine 2\nLine 3'
还可以在多行字符串前面添加 r ,把这个多行字符串也变成一个raw字符串:
r'''Python is created by "Guido".
It is free and easy to learn.
Let's start learn Python in imooc!'''
----------------------------------------------------------------------------------------------------------------------------------------------------------
a = True
print a and 'a=T' or 'a=F'
计算结果不是布尔类型,而是字符串 'a=T',这是为什么呢?因为Python把0、空字符串''和None看成 False,其他数
值和非空字符串都看成 True,所以:True and 'a=T' 计算结果是 'a=T'
继续计算 'a=T' or 'a=F' 计算结果还是 'a=T'要解释上述结果,又涉及到 and 和 or 运算的一条重要法则:短路计
算。1. 在计算 a and b 时,如果 a 是 False,则根据与运算法则,整个结果必定为 False,因此返回 a;如果 a 是 True,则整个计算结果必定取决与 b,因此返回 b。2. 在计算 a or b 时,如果 a 是 True,则根据或运算法则,整个计算结果必定为 True,因此返回 a;如果 a 是 False,则整个计算结果必定取决于 b,因此返回 b。所以Python解释器在做布尔运算时,只要能提前确定计算结果,它就不会往后算了,直接返回结果。
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。list是数学意义上的有序集合,也就是说,list中的元素是按照顺序排列的。构造list非常简单,按照上面的代码,直接用 [ ] 把list的所有元素都括起来,就是一个list对象。通常,我们会把list赋值给一个变量,这样,就可以通过变量来引用
list:classmates = ['Michael', 'Bob', 'Tracy']
print classmates
由于Python是动态语言,所以list中包含的元素并不要求都必须是同一种数据类型,我们完全可以在list中包含各种:
L = ['Michael', 100, True]
索引从 0 开始,也就是说,第一个元素的索引是0,第二个元素的索引是1,以此类推。我们可以用 -1 这个索引来表示最后一个元素,类似的,倒数第二用 -2 表示,倒数第三用 -3 表示,倒数第四用 -4 表示
append()总是把新的元素添加到 list 的尾部。list的 insert()方法,它接受两个参数,第一个参数是索引号,第二个参数是待添加的新元素
pop()方法总是删掉list的最后一个元素,并且它还返回这个元素,所以我们执行 L.pop() 后,会打印出这个元素。可以用 pop(2)把索引为2的元素删除
替换: L = ['Adam', 'Lisa', 'Bart'] L[2] = 'Paul'
tuple是另一种有序的列表,中文翻译为“ 元组 ”。tuple 和 list 非常类似,但是,tuple一旦创建完毕,就不能修
改了。创建tuple和创建list唯一不同之处是用( )替代了[ ]。获取 tuple 元素的方式和 list 是一模一样的
t = (1) print t结果为1,因为()既可以表示tuple,又可以作为括号表示运算时的优先级,结果 (1) 被Python解释
器计算出结果 1,导致我们得到的不是tuple,而是整数 1。
正是因为用()定义单元素的tuple有歧义,所以 Python 规定,单元素 tuple 要多加一个逗号“,”,这样就避免了歧义:t = (1,) print t 结果为(1,)
tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。
即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
注意: Python代码的缩进规则。具有相同缩进的代码被视为代码块,上面的3,4行 print 语句就构成一个代码块(但不包括第5行的print)。如果 if 语句判断为 True,就会执行这个代码块。
缩进请严格按照Python的习惯写法:4个空格,不要使用Tab,更不要混合Tab和空格,否则很容易造成因为缩进引起的语法错误。
注意: if 语句后接表达式,然后用:表示代码块开始。
如果你在Python交互环境下敲代码,还要特别留意缩进,并且退出缩进需要多敲一行回车 练习:
score=55
if score >= 60:
score=bytes(score)
print 'passed:'+score
else:
print 'nopass'
age = 8
if age >= 6:
print 'teenager'
elif age >= 18:
print 'adult'
else:
print 'kid'
Python的 for 循环就可以依次把list或tuple的每个元素迭代出来:L = ['Adam', 'Lisa', 'Bart']
for name in L:
print name
注意: name 这个变量是在 for 循环中定义的,意思是,依次取出list中的每一个元素,并把元素赋值给 name,然后执行for循环体,这样,遍历一个list或tuple就非常容易了
花括号 {} 表示这是一个dict,然后按照 key: value, 写出来即可。最后一个 key: value 的逗号可以省略。由于
dict也是集合,len() 函数可以计算任意集合的大小:
可以简单地使用 d[key] 的形式来查找对应的 value
通过 key 访问 dict 的value,如果key不存在,会直接报错:KeyError。要避免 KeyError 发生,有两个办法:一是先判断一下 key 是否存在,用 in 操作符:
if 'Paul' in d:
print d['Paul']
二是使用dict本身提供的一个 get 方法,在Key不存在的时候,返回None
dict的第一个特点是查找速度快,无论dict有10个元素还是10万个元素,查找速度都一样。而list的查找速度随着元素增加而逐渐下降。
不过dict的查找速度快不是没有代价的,dict的缺点是占用内存大,还会浪费很多内容,list正好相反,占用内存小,但是查找速度慢。由于dict是按 key 查找,所以,在一个dict中,key不能重复。
dict的第二个特点就是存储的key-value序对是没有顺序的!这和list不一样
dict的第三个特点是作为 key 的元素必须不可变,Python的基本类型如字符串、整数、浮点数都是不可变的,都可以作为 key。但是list是可变的,就不能作为 key。
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}要把新同学'Paul'的成绩 72 加进去,用赋值语句 d['Paul'] = 72如果 key 已经存在,则赋值会用新的 value 替
换掉原来的 value
练习:
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
for key in d:
print key
print d[key]
print d.get(key)
set 持有一系列元素,这一点和 list 很像,但是set的元素没有重复,而且是无序的,这点和 dict 的 key很像。创建 set 的方式是调用 set() 并传入一个 list,list的元素将作为set的元素:s = set(['A', 'B', 'C'])添加重复元素,重复元素最后只存在一个
由于set存储的是无序集合,所以我们没法通过索引来访问。
访问 set中的某个元素实际上就是判断一个元素是否在set中。
s = set(['Adam', 'Lisa', 'Bart', 'Paul'])
Bart是该班的同学吗?'Bart' in s输出True
遍历:
s = set([('Adam', 95), ('Lisa', 85), ('Bart', 59)])
for name in s:
print name
输出('Lisa', 85)
('Adam', 95)
('Bart', 59)
添加元素时,用set的add()方法,删除set中的元素时,用set的remove()方法,不存在会报错
在Python中,定义一个函数要使用 def 语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用 return 语句返回。return None可以简写为return。
在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值,所以,Python的函数返回多值其实就是返回一个tuple
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
Python自带的 int() 函数,其实就有两个参数,int()函数的第二个参数是转换进制,如果不传,默认是十进制
(base=10),如果传了,就用传入的参数。
可变参数的名字前面有个 * 号,我们可以传入0个、1个或多个参数给可变参数
input函数支持表达式、数字类型、字符串类型,接受为表达式时,只返回其执行结果。
在python3中对input和raw_input函数进行了整合,仅保留了input函数(认为raw_input函数是冗余的)。
同时改变了input的用法——将所有的输入按照字符串进行处理,并返回一个字符串。
sqrt()方法返回x的平方根(x>0)。
语法
以下是sqrt()方法的语法:
import math
math.sqrt( x )
注意:此函数是无法直接访问的,所以我们需要导入math模块,然后需要用math的静态对象来调用这个函数。参数
1. x -- 这是一个数值表达式。返回值
此方法返回x的平方根,对于x>0。例子下面的例子显示了sqrt()方法的使用。
#!/usr/bin/python
import math # This will import math module
print "math.sqrt(100) : ", math.sqrt(100)
print "math.sqrt(7) : ", math.sqrt(7)
print "math.sqrt(math.pi) : ", math.sqrt(math.pi)
当我们运行上面的程序,它会产生以下结果:
math.sqrt(100) : 10.0
math.sqrt(7) : 2.64575131106
math.sqrt(math.pi) : 1.77245385091
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上
,得到一个新的 list 并返回。注意:map()函数不改变原有的 list,而是返回一个新的 list。
在使用Python编译的时候出现如下错误:
SyntaxError: Non-ASCII character '\xe5' in file Test1.py on line 8, but no encoding declared; see
http://www.python.org/peps/pep-0263.html for details
解决方法
python的默认编码文件是用的ASCII码,将文件存成了UTF-8,编译就可以通过。或在在py文件开头(必须是第一行)加入
[python] view plain copy
#coding=utf-8
或者
[python] view plain copy
# -*- coding:utf-8 -*-
原因
如果要在python2的py文件里面写中文,则必须要添加一行声明文件编码的注释,否则python2会默认使用ASCII编码。
可以使用unicode函数
print u'你好';
print (unicode("请输入销售额", encoding="utf-8"))
将utf-8编码转换为unicode就可以输出中文了。
将ASCII字符转换为对应的数值即‘a’-->65,使用ord函数,ord('a')
反正,使用chr函数,将数值转换为对应的ASCII字符,chr(65)
reduce()函数也是Python内置的一个高阶函数。reduce()函数接收的参数和 map()类似,一个函数 f,一个list,但行为和 map()不同,reduce()传入的函数 f 必须接收两个参数,reduce()对list的每个元素反复调用函数f,并返回最终结果值。reduce()还可以接收第3个可选参数,作为计算的初始值。
例如,编写一个f函数,接收x和y,返回x和y的和:
def f(x, y):
return x + y
调用 reduce(f, [1, 3, 5, 7, 9])时,reduce函数将做如下计算:
先计算头两个元素:f(1, 3),结果为4;
再把结果和第3个元素计算:f(4, 5),结果为9;
再把结果和第4个元素计算:f(9, 7),结果为16;
再把结果和第5个元素计算:f(16, 9),结果为25;
由于没有更多的元素了,计算结束,返回结果25。
filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter
()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。
注意: s.strip(rm) 删除 s 字符串中开头、结尾处的 rm 序列的字符。
当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' ')
Python内置的 sorted()函数可对list进行升序排序
但 sorted()也是一个高阶函数,它可以接收一个比较函数来实现自定义排序,比较函数的定义是,传入两个待比较的元
素 x, y,如果 x 应该排在 y 的前面,返回 -1,如果 x 应该排在 y 的后面,返回 1。如果 x 和 y 相等,返回 0。
定义一个函数 f(),我们让它返回一个函数 g,可以这样写:
def f():
print 'call f()...'
# 定义函数g:
def g():
print 'call g()...'
# 返回函数g:
return g
调用函数 f,我们会得到 f 返回的一个函数:
>>> x = f() # 调用f()
call f()...
>>> x # 变量x是f()返回的函数:
<function g at 0x1037bf320>
>>> x() # x指向函数,因此可以调用
call g()... # 调用x()就是执行g()函数定义的代码
内层函数引用了外层函数的变量(参数也算变量),然后返回内层函数的情况,称为闭包(Closure)。
闭包的特点是返回的函数还引用了外层函数的局部变量,所以,要正确使用闭包,就要确保引用的局部变量在函数返回后不能变。举例如下:
# 希望一次返回3个函数,分别计算1x1,2x2,3x3:
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
你可能认为调用f1(),f2()和f3()结果应该是1,4,9,但实际结果全部都是 9(请自己动手验证)。
原因就是当count()函数返回了3个函数时,这3个函数所引用的变量 i 的值已经变成了3。由于f1、f2、f3并没有被调用,所以,此时他们并未计算 i*i,当 f1 被调用时:
>>> f1()
9 # 因为f1现在才计算i*i,但现在i的值已经变为3
因此,返回函数不要引用任何循环变量,或者后续会发生变化的变量。
def count():
fs = []
for i in range(1, 4):
def f(j):
def g():
return j*j
return g
r = f(i)
fs.append(r)
return fs
f1, f2, f3 = count()
print f1(), f2(), f3()
输出1 4 9
关键字lambda 表示匿名函数,冒号前面的 x 表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不写return,返回值就是该表达式的结果。
使用 decorator 用Python提供的 @ 语法,这样可以避免手动编写 f = decorate(f) 这样的代码。要让 @log 自适应任何参数定义的函数,可以利用Python的 *args 和 **kw,保证任意个数的参数总是能正常调用。
在定义 Person 类时,可以为Person类添加一个特殊的__init__()方法,当创建实例时,__init__()方法被自动调用,我们就能在此为每个实例都统一加上以下属性:
class Person(object):
def __init__(self, name, gender, birth):
self.name = name
self.gender = gender
self.birth = birth
__init__() 方法的第一个参数必须是 self(也可以用别的名字,但建议使用习惯用法),后续参数则可以自由指定,和定义函数没有任何区别。
相应地,创建实例时,就必须要提供除 self 以外的参数:
xiaoming = Person('Xiao Ming', 'Male', '1991-1-1')
xiaohong = Person('Xiao Hong', 'Female', '1992-2-2')
只有以双下划线开头的"__job"不能直接被外部访问。
但是,如果一个属性以"__xxx__"的形式定义,那它又可以被外部访问了,以"__xxx__"定义的属性在Python的类中被称
为特殊属性,有很多预定义的特殊属性可以使用,通常我们不要把普通属性用"__xxx__"定义。
以单下划线开头的属性"_xxx"虽然也可以被外部访问,但是,按照习惯,他们不应该被外部访问。
在class中定义的全部是实例方法,实例方法第一个参数 self 是实例本身。
要在class中定义类方法,需要这么写:
class Person(object):
count = 0
@classmethod
def how_many(cls):
return cls.count
def __init__(self, name):
self.name = name
Person.count = Person.count + 1
print Person.how_many()
p1 = Person('Bob')
print Person.how_many()
通过标记一个 @classmethod,该方法将绑定到 Person 类上,而非类的实例。类方法的第一个参数将传入类本身,通
常将参数名命名为 cls,上面的 cls.count 实际上相当于 Person.count。
因为是在类上调用,而非实例上调用,因此类方法无法获得任何实例变量,只能获得类的引用。
如果已经定义了Person类,需要定义新的Student和Teacher类时,可以直接从Person类继承:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
定义Student类时,只需要把额外的属性加上,例如score:
class Student(Person):
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
一定要用 super(Student, self).__init__(name, gender) 去初始化父类,否则,继承自 Person 的 Student 将没有 name 和 gender。
函数super(Student, self)将返回当前类继承的父类,即 Person ,然后调用__init__()方法,注意self参数已在
super()中传入,在__init__()中将隐式传递,不需要写出(也不能写)。
当我们拿到变量 p、s、t 时,可以使用 isinstance 判断类型:
>>> isinstance(p, Person)
True # p是Person类型
>>> isinstance(p, Student)
False # p不是Student类型
>>> isinstance(p, Teacher)
False # p不是Teacher类型
对于实例变量,dir()返回所有实例属性,包括`__class__`这类有特殊意义的属性。注意到方法`whoAmI`也是 s 的一个属性。
如何去掉`__xxx__`这类的特殊属性,只保留我们自己定义的属性?回顾一下filter()函数的用法。
dir()返回的属性是字符串列表,如果已知一个属性名称,要获取或者设置对象的属性,就需要用 getattr() 和 setattr( )函数了:
>>> getattr(s, 'name') # 获取name属性
'Bob'
>>> setattr(s, 'name', 'Adam') # 设置新的name属性
>>> s.name
'Adam'
>>> getattr(s, 'age') # 获取age属性,但是属性不存在,报错:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Student' object has no attribute 'age'
>>> getattr(s, 'age', 20) # 获取age属性,如果属性不存在,就返回默认值20:
20
如果要把一个类的实例变成 str,就需要实现特殊方法__str__(),Python 定义了__str__()和__repr__()两种方法,
__str__()用于显示给用户,而__repr__()用于显示给开发人员。
有一个偷懒的定义__repr__的方法:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def __str__(self):
return '(Person: %s, %s)' % (self.name, self.gender)
__repr__ = __str__
要让 len() 函数工作正常,类必须提供一个特殊方法__len__(),它返回元素的个数。例如,我们写一个 Students 类,把名字传进去:
class Students(object):
def __init__(self, *args):
self.names = args
def __len__(self):
return len(self.names)
对 int、str 等内置数据类型排序时,Python的 sorted() 按照默认的比较函数 cmp 排序,但是,如果对一组
Student 类的实例排序时,就必须提供我们自己的特殊方法 __cmp__():
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def __str__(self):
return '(%s: %s)' % (self.name, self.score)
__repr__ = __str__
def __cmp__(self, s):
if self.name < s.name:
return -1
elif self.name > s.name:
return 1
else:
return 0
上述 Student 类实现了__cmp__()方法,__cmp__用实例自身self和传入的实例 s 进行比较,如果 self 应该排在前
面,就返回 -1,如果 s 应该排在前面,就返回1,如果两者相当,返回 0。所有的函数都是可调用对象。
一个类实例也可以变成一个可调用对象,只需要实现一个特殊方法__call__()。
我们把 Person 类变成一个可调用对象:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def __call__(self, friend):
print 'My name is %s...' % self.name
print 'My friend is %s...' % friend
现在可以对 Person 实例直接调用:
>>> p = Person('Bob', 'male')
>>> p('Tim')
My name is Bob...
My friend is Tim...

Python进阶(二十一)-Python学习进阶资料
学习Python已经将近2周了,掌握了基本的语法,并学习了简单的爬虫操作,现将相关学习资料整理如下。大部分资料均取材于慕课网,感觉一路学下来受益匪浅。
1.Python入门
2.Python进阶
3.Python装饰器
4.Python-面向对象
5.Python-走进Requests库
6.Python操作MySQL数据库
7.Python遇见数据采集
8.Python开发简单爬虫
9. 多线程爬虫
10. Django初体检
11.Django入门与实战
12.Flask 开发基础与入门
13.在 Flask 应用中使用 MySQL
14.Flask 与 BootStrap 搭建网页
当然,这其中也不乏收费的教学视频。不过,Maybe可以在别的地方找到该资源~(窃喜)
15. Python分布式爬虫打造搜索引擎 Scrapy精讲
16. 强力django+杀手级xadmin 打造上线标准的在线教育平台
注
Python进阶(一)-初识Python数据元素:列表&元组
Python不像JS或者PHP这种弱类型语言里在字符串连接时会自动转换类型,而是直接报错。要解决这个方法只有提前把int转成string,然后再拼接字符串即可。
如代码:
|
1
2
3
4
5
|
# coding=utf8
str='你的分数是:'
num=82
text=str+num+'分 | 琼台博客'
printtext
|
执行结果

直接报错:TypeError: cannot concatenate 'str' and 'int' objects
解决这个方法只有提前把num转换为字符串类型,可以使用bytes函数把int型转换为string型。
代码:
|
1
2
3
4
5
6
|
# coding=utf8
str='你的分数是:'
num=82
num=bytes(num)
text=str+num+'分 | 琼台博客'
printtext
|
结果搞定:

毕业论文已完成,下面就是等待盲审结果了。在此期间,已感觉论文无从看起。就学习一下Python吧,听说这是一门很神奇的语言。下面言归正传~
在线文档查询:点击查看
IDE:IntelJ。
有关IntelJ的安装与注册详见博文《IntelliJ IDEA 2016注册方法和注册码》。
下面介绍一下Python中几种不熟悉的数据元素:列表、元组、字典、时间。
1列表
1.1初始化列表
list=['physics', 'chemistry', 1997, 2000];
- 1
1.2访问列表中的值
list[0]
- 1
1.3更新列表
nums[0]="ljq";
- 1
1.4删除列表元素
del nums[0];
- 1
1.5列表脚本操作符
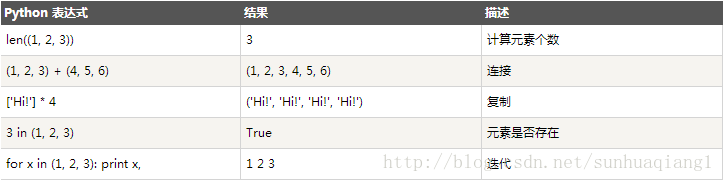
列表对+和的操作符与字符串相似。+号用于组合列表,号用于重复列表,例如:
- print len([1, 2, 3]); #3
- print [1, 2, 3] + [4, 5, 6]; #[1, 2, 3, 4, 5, 6]
- print ['Hi!'] * 4; #['Hi!', 'Hi!', 'Hi!', 'Hi!']
- print 3 in [1, 2, 3] #True
- for x in [1, 2, 3]: print x, #1 2 3
- 1
- 2
- 3
- 4
- 5
1.6列表截取
- L=['spam', 'Spam', 'SPAM!'];
- print L[2]; #'SPAM!'
- print L[-2]; #'Spam'
- print L[1:]; #['Spam', 'SPAM!']
- 1
- 2
- 3
- 4
1.7列表函数&方法
- list.append(obj) #在列表末尾添加新的对象
- list.count(obj) #统计某个元素在列表中出现的次数
- list.extend(seq) #在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
- list.index(obj) #从列表中找出某个值第一个匹配项的索引位置,索引从0开始
- list.insert(index, obj) #将对象插入列表
- list.pop(obj=list[-1]) #移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
- list.remove(obj) #移除列表中某个值的第一个匹配项
- list.reverse() #反向列表中元素,倒转
- list.sort([func]) #对原列表进行排序
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2元组(tuple)
Python的元组与列表类似,不同之处在于元组的元素不能修改;元组使用小括号(),列表使用方括号[];元组创建很简单,只需要在括号中添加元素,并使用逗号(,)隔开即可,
tup1 = ('physics', 'chemistry', 1997, 2000);
- 1
创建空元组,例如:
tup = ();
- 1
元组中只有一个元素时,需要在元素后面添加逗号,例如:
tup1 = (50,);
- 1
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
2.1访问元组
- tup1 = ('physics', 'chemistry', 1997, 2000);
- tup1[0]#physics
- 1
- 2
2.2修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,例如:
- tup1 = (12, 34.56);
- tup2 = ('abc', 'xyz');
- 1
- 2
- #以下修改元组元素操作是非法的。
- tup1[0] = 100;
- #创建一个新的元组
- tup3 = tup1 + tup2;
- print tup3; #(12, 34.56, 'abc', 'xyz')
- 1
- 2
- 3
- 4
- 5
2.3删除元组
元组中的元素值是不允许删除的,可以使用del语句来删除整个元组,例如:
- tup = ('physics', 'chemistry', 1997, 2000);
- print tup;
- del tup;
- 1
- 2
- 3
2.4元组运算符
与字符串一样,元组之间可以使用+号和*号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
2.5元组索引&截取
- L = ('spam', 'Spam', 'SPAM!');
- print L[2]; #'SPAM!'
- print L[-2]; #'Spam'
- print L[1:]; #['Spam', 'SPAM!']
- 1
- 2
- 3
- 4
2.6元组内置函数
- cmp(tuple1, tuple2) 比较两个元组元素。
- len(tuple) 计算元组元素个数。
- max(tuple) 返回元组中元素最大值。
- min(tuple) 返回元组中元素最小值。
tuple(seq) 将列表转换为元组。
Python进阶(二)-初识Python数据元素:字典&时间
3字典
3.1字典简介
字典(dic dictionary)是除列表之外python中最灵活的内置数据结构类型。 列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典由键和对应的值组成。字典也被称作关联数组或哈希表。基本语法如下:
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'};
- 1
也可如此创建字典:
- dict1 = { 'abc': 456 };
- dict2 = { 'abc': 123, 98.6: 37 };
- 1
- 2
每个键与值必须用冒号隔开(:),每对用逗号分割,整体放在花括号中({})。键必须独一无二,但值则不必;值可以取任何数据类型,但必须是不可变的,如字符串,数或元组。
3.2访问字典里的值
- dict = {'name': 'Zara', 'age': 7, 'class': 'First'};
- print "dict['name']: ", dict['name'];
- print "dict['age']: ", dict['age'];
- 1
- 2
- 3
3.3修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对。
如下实例:
- dict = {'name': 'Zara', 'age': 7, 'class': 'First'};
- dict["age"]=27; #修改已有键的值
- dict["school"]="wutong"; #增加新的键/值对
- print "dict['age']: ", dict['age'];
- print "dict['school']: ", dict['school'];
- 1
- 2
- 3
- 4
- 5
3.4删除字典
- del dict['name']; # 删除键是'name'的条目
- dict.clear(); # 清空词典所有条目
- del dict ; # 删除词典
- 1
- 2
- 3
- 注意:字典不存在,del会引发一个异常
3.5字典内置函数&方法
- cmp(dict1, dict2) #比较两个字典元素。
- len(dict) #计算字典元素个数,即键的总数。
- str(dict) #输出字典可打印的字符串表示。
- type(variable) #返回输入的变量类型,如果变量是字典就返回字典类型。
- clear() #删除字典内所有元素
- copy() #返回一个字典的浅复制
- fromkeys() #创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值
- get(key, default=None) #返回指定键的值,如果值不在字典中返回default值
- has_key(key) #如果键在字典dict里返回true,否则返回false
- items() #以列表返回可遍历的(键, 值) 元组数组
- keys() #以列表返回一个字典所有的键
- setdefault(key, default=None) #和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
- update(dict2) #把字典dict2的键/值对更新到dict里
- values() #以列表返回字典中的所有值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4日期和时间
4.1获取当前时间
- import time, datetime;
- localtime = time.localtime(time.time())
- print "Local current time :", localtime
- 1
- 2
- 3
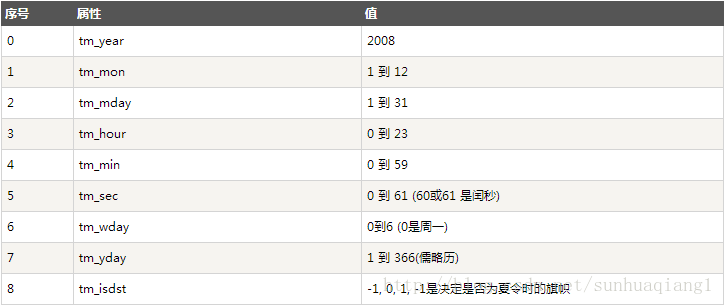
说明:time.struct_time(tm_year=2014, tm_mon=3, tm_mday=21, tm_hour=15, tm_min=13, tm_sec=56, tm_wday=4, tm_yday=80, tm_isdst=0)属于struct_time元组,struct_time元组具有如下属性:
4.2获取格式化的时间
可以根据需求选取各种格式,但是最简单的获取可读的时间模式的函数是asctime():
4.2.1日期转换为字符串
首选:print time.strftime(‘%Y-%m-%d %H:%M:%S’);
其次:print datetime.datetime.strftime(datetime.datetime.now(), ‘%Y-%m-%d %H:%M:%S’)
最后:print str(datetime.datetime.now())[:19]
4.2.2字符串转换为日期
- expire_time = "2013-05-21 09:50:35"
- d = datetime.datetime.strptime(expire_time,"%Y-%m-%d %H:%M:%S")
- print d;
- 1
- 2
- 3
4.2.3获取日期差
- oneday = datetime.timedelta(days=1)
- #今天,2014-03-21
- today = datetime.date.today()
- #昨天,2014-03-20
- yesterday = datetime.date.today() - oneday
- #明天,2014-03-22
- tomorrow = datetime.date.today() + oneday
- #获取今天零点的时间,2014-03-21 00:00:00
- today_zero_time=datetime.datetime.strftime(today, '%Y-%m-%d %H:%M:%S')
- #0:00:00.001000
- print datetime.timedelta(milliseconds=1), #1毫秒
- #0:00:01
- print datetime.timedelta(seconds=1), #1秒
- #0:01:00
- print datetime.timedelta(minutes=1), #1分钟
- #1:00:00
- print datetime.timedelta(hours=1), #1小时
- #1 day, 0:00:00
- print datetime.timedelta(days=1), #1天
- #7 days, 0:00:00
- print datetime.timedelta(weeks=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

4.2.4获取时间差
- #1 day, 0:00:00
- oneday = datetime.timedelta(days=1)
- #今天,2014-03-21 16:07:23.943000
- today_time = datetime.datetime.now()
- #昨天,2014-03-20 16:07:23.943000
- yesterday_time = datetime.datetime.now() - oneday
- #明天,2014-03-22 16:07:23.943000
- tomorrow_time = datetime.datetime.now() + oneday
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意时间是浮点数,带毫秒。
那么要获取当前时间,需要格式化一下:
- print datetime.datetime.strftime(today_time, '%Y-%m-%d %H:%M:%S')
- print datetime.datetime.strftime(yesterday_time, '%Y-%m-%d %H:%M:%S')
- print datetime.datetime.strftime(tomorrow_time, '%Y-%m-%d %H:%M:%S')
- 1
- 2
- 3
4.2.5获取上个月最后一天
last_month_last_day = datetime.date(datetime.date.today().year,datetime.date.today().month,1)-datetime.timedelta(1)
- 1
4.2.6字符串日期格式化为秒数
返回浮点类型
- expire_time = "2013-05-21 09:50:35"
- d = datetime.datetime.strptime(expire_time,"%Y-%m-%d %H:%M:%S")
- time_sec_float = time.mktime(d.timetuple())
- print time_sec_float
- 1
- 2
- 3
- 4
4.2.7日期格式化为秒数
返回浮点类型
- d = datetime.date.today()
- time_sec_float = time.mktime(d.timetuple())
- print time_sec_float
- 1
- 2
- 3
4.2.8秒数转字符串
- time_sec = time.time()
- print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time_sec))
Python进阶(三)-函数式编程之reduce()
官方解释如下:
Apply function of two arguments cumulatively to the items of sequence, from left to right, so as to reduce the sequence to a single value. For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates ((((1+2)+3)+4)+5). The left argument, x, is the accumulated
value and the right argument, y, is the update value from the sequence. If the optional initializer is present, it is placed before the items of the sequence in the calculation, and serves as a default when the sequence is empty. If initializer is not given
and sequence contains only one item, the first item is returned.
格式: reduce (func, seq[, init()])
reduce()函数即为化简函数,它的执行过程为:每一次迭代,都将上一次的迭代结果(注:第一次为init元素,如果没有指定init则为seq的第一个元素)与下一个元素一同传入二元func函数中去执行。在reduce()函数中,init是可选的,如果指定,则作为第一次迭代的第一个元素使用,如果没有指定,就取seq中的第一个元素。
举例
有一个序列集合,例如[1,1,2,3,2,3,3,5,6,7,7,6,5,5,5],统计这个集合所有键的重复个数,例如1出现了两次,2出现了两次等。大致的思路就是用字典存储,元素就是字典的key,出现的次数就是字典的value。方法依然很多
第一种:for循环判断
- def statistics(lst):
- dic = {}
- for k in lst:
- if not k in dic:
- dic[k] = 1
- else:
- dic[k] +=1
- return dic
- lst = [1,1,2,3,2,3,3,5,6,7,7,6,5,5,5]
- print(statistics(lst))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
第二种:比较取巧的,先把列表用set方式去重,然后用列表的count方法
- def statistics2(lst):
- m = set(lst)
- dic = {}
- for x in m:
- dic[x] = lst.count(x)
- return dic
- lst = [1,1,2,3,2,3,3,5,6,7,7,6,5,5,5]
- print statistics2(lst)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
第三种:用reduce方式
- def statistics(dic,k):
- if not k in dic:
- dic[k] = 1
- else:
- dic[k] +=1
- return dic
- lst = [1,1,2,3,2,3,3,5,6,7,7,6,5,5,5]
- print reduce(statistics,lst,{})
- #提供第三个参数,第一次,初始字典为空,作为statistics的第一个参数,然后遍历lst,作为第二个参数,然后将返回的字典集合作为下一次的第一个参数
- 或者
- d = {}
- d.extend(lst)
- print reduce(statistics,d)
- #不提供第三个参数,但是要在保证集合的第一个元素是一个字典对象,作为statistics的第一个参数,遍历集合依次作为第二个参数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
通过上面的例子发现,凡是要对一个集合进行操作的,并且要有一个统计结果的,能够用循环或者递归方式解决的问题,一般情况下都可以用reduce方式实现。
Python进阶(四)-浅谈Python闭包
在函数内部定义的函数和外部定义的函数是一样的,只是他们无法被外部访问:
- def g():
- print 'g()...'
- def f():
- print 'f()...'
- return g
- 1
- 2
- 3
- 4
- 5
将 g 的定义移入函数 f 内部,防止其他代码调用 g:
- def f():
- print 'f()...'
- def g():
- print 'g()...'
- return g
- 1
- 2
- 3
- 4
- 5
但是,考察定义的 calc_sum 函数:
- def calc_sum(lst):
- def lazy_sum():
- return sum(lst)
- return lazy_sum
- 1
- 2
- 3
- 4
注意: 发现没法把 lazy_sum 移到 calc_sum 的外部,因为它引用了 calc_sum 的参数 lst。
- 像这种内层函数引用了外层函数的变量(参数也算变量),然后返回内层函数的情况,称为闭包(Closure)。
闭包的特点是返回的函数还引用了外层函数的局部变量,所以,要正确使用闭包,就要确保引用的局部变量在函数返回后不能变。举例如下:
- # 希望一次返回3个函数,分别计算1x1,2x2,3x3:
- def count():
- fs = [ ]
- for i in range(1, 4):
- def f():
- return i*i
- fs.append(f)
- return fs
- f1, f2, f3 = count()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
你可能认为调用f1(),f2()和f3()结果应该是1,4,9,但实际结果全部都是 9(请自己动手验证)。
原因就是当count()函数返回了3个函数时,这3个函数所引用的变量 i 的值已经变成了3。由于f1、f2、f3并没有被调用,所以,此时他们并未计算 i*i,当 f1 被调用时:
- >>> f1()
- 9 # 因为f1现在才计算i*i,但现在i的值已经变为3
- 1
- 2
因此,返回函数不要引用任何循环变量,或者后续会发生变化的变量。
举例
返回闭包不能引用循环变量,请改写count()函数,让它正确返回能计算1x1、2x2、3x3的函数。
考察下面的函数 f:
- def f(j):
- def g():
- return j*j
- return g
- 1
- 2
- 3
- 4
它可以正确地返回一个闭包g,g所引用的变量j不是循环变量,因此将正常执行。
在count函数的循环内部,如果借助f函数,就可以避免引用循环变量i。
参考代码:
- def count():
- fs = []
- for i in range(1, 4):
- def f(j):
- def g():
- return j*j
- return g
- r = f(i)
- fs.append(r)
- return fs
- f1, f2, f3 = count()
- print f1(), f2(), f3()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
程序实例
Python进阶(五)-浅谈python匿名函数
高阶函数可以接收函数做参数,有些时候,我们不需要显式地定义函数,直接传入匿名函数更方便。
在Python中,对匿名函数提供了有限支持。还是以map()函数为例,计算 f(x)=x2 时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
- >>> map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9])
- [1, 4, 9, 16, 25, 36, 49, 64, 81]
- 1
- 2
通过对比可以看出,匿名函数 lambda x: x * x 实际上就是:
- def f(x):
- return x * x
- 1
- 2
- 关键字lambda 表示匿名函数,冒号前面的 x 表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不写return,返回值就是该表达式的结果。
使用匿名函数,可以不必定义函数名,直接创建一个函数对象,很多时候可以简化代码:
- >>> sorted([1, 3, 9, 5, 0], lambda x,y: -cmp(x,y))
- [9, 5, 3, 1, 0]
- 1
- 2
返回函数的时候,也可以返回匿名函数:
- >>> myabs = lambda x: -x if x < 0 else x
- >>> myabs(-1)
- 1
- >>> myabs(1)
- 1
- 1
- 2
- 3
- 4
- 5
举例
利用匿名函数简化以下代码:
- def is_not_empty(s):
- return s and len(s.strip()) > 0
- filter(is_not_empty, ['test', None, '', 'str', ' ', 'END'])
- 1
- 2
- 3
定义匿名函数时,没有return关键字,且表达式的值就是函数返回值。
参考代码:
print filter(lambda s: s and len(s.strip())>0, ['test', None, '', 'str', ' ', 'END'])Python进阶(六)-python编写无参数decorator
Python的 decorator 本质上就是一个高阶函数,它接收一个函数作为参数,然后,返回一个新函数。
使用 decorator 用Python提供的 @ 语法,这样可以避免手动编写 f = decorate(f) 这样的代码。
考察一个@log的定义:
- def log(f):
- def fn(x):
- print 'call ' + f.__name__ + '()...'
- return f(x)
- return fn
- 1
- 2
- 3
- 4
- 5
对于阶乘函数,@log工作得很好:
- @log
- def factorial(n):
- return reduce(lambda x,y: x*y, range(1, n+1))
- print factorial(10)
- 1
- 2
- 3
- 4
结果:
call factorial()…
3628800
但是,对于参数不是一个的函数,调用将报错:
- @log
- def add(x, y):
- return x + y
- print add(1, 2)
- 1
- 2
- 3
- 4
结果:
Traceback (most recent call last):
File “test.py”, line 15, in
print add(1,2)
TypeError: fn() takes exactly 1 argument (2 given)
因为 add() 函数需要传入两个参数,但是 @log 写死了只含一个参数的返回函数。
要让 @log 自适应任何参数定义的函数,可以利用Python的 *args 和 **kw,保证任意个数的参数总是能正常调用:
- def log(f):
- def fn(*args, **kw):
- print 'call ' + f.__name__ + '()...'
- return f(*args, **kw)
- return fn
- 1
- 2
- 3
- 4
- 5
现在,对于任意函数,@log 都能正常工作。
举例
请编写一个@performance,它可以打印出函数调用的时间。
计算函数调用的时间可以记录调用前后的当前时间戳,然后计算两个时间戳的差。
参考代码:
- import time
- def performance(f):
- def fn(*args, **kw):
- t1 = time.time()
- r = f(*args, **kw)
- t2 = time.time()
- print 'call %s() in %fs' % (f.__name__, (t2 - t1))
- return r
- return fn
-
- @performance
- def factorial(n):
- return reduce(lambda x,y: x*y, range(1, n+1))
- print factorial(10)
Python进阶(七)-浅谈python3和Python2的区别
不管使用何种版本的Python语言,都需要遵循编程规范,不该有的缩进一定不能有。否则会出现莫名其妙的错误,如下图所示:
在应用Python编程时,首先要明确所使用Python版本,因为版本2与3之间存在着很多细节性的差异。稍有不慎就会入坑~下面介绍一下具体应用中的细节性差异。
具体参照:https://docs.python.org/3/whatsnew/3.0.html

print函数
Python3中print为一个函数,必须用括号括起来;Python2中print为class)。Python 2 的 print 声明已经被 print() 函数取代了,这意味着我们必须包装我们想打印在小括号中的对象。
举例
在Python 2中:
print 'Hello, World!'
- 1
在Python 3中:
print( 'Hello, World!')
- 1
reduce()函数
在Python 3里,reduce()函数已经被从全局名字空间里移除了,它现在被放置在fucntools模块里。使用时要先引入from functools import reduce
try except
try:
except Exception, e :
- try:
- except Exception as e :
- 1
- 2
打开文件
原: file( ….. )
或 open(…..)
改为:
只能用 open(…..)
从键盘录入一个字符串
原: raw_input( “提示信息” )
改为: input( “提示信息” )
整形除法自动转为float
python2:
1/2
2/2
1//2
0
1
0
python3:
1/2
2/2
1//2
0.5
1.0
0
新的字符串格式化方法format取代%5.
xrange重命名为range.
!=取代 < >
long重命名为int.
exec变成函数
Py3.X源码文件默认使用utf-8编码,这就使得以下代码是合法的:
- >>> 中国 = 'china'
- >>>print(中国)
- china
- 1
- 2
- 3
python3中替换python2中cmp函数
Python 3.4.3 的版本中已经没有cmp函数,被operator模块代替,在交互模式下使用时,需要导入模块。在没有导入模块情况下,会出现下面的错误:
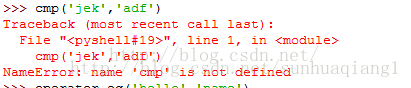
提示找不到cmp函数了,那么在python3中该如何使用这个函数呢?
所以要导入模块

看下面给的内置函数
- operator.lt(a, b) #相当于 a<b 从第一个数字或字母(ASCII)比大小
- operator.le(a, b) #相当于a<=b
- operator.eq(a, b) #相当于a==b 字母完全一样,返回True
- operator.ne(a, b) #相当于a!=b
- operator.ge(a, b) #相当于 a>=b
- operator.gt(a, b) #相当于a>b
- operator.__lt__(a, b)
- operator.__le__(a, b)
- operator.__eq__(a, b)
- operator.__ne__(a, b)
- operator.__ge__(a, b)
- operator.__gt__(a, b)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这几个函数就是用来替换之前的cmp,函数的返回值是布尔值。
除法
- 在python3.0中,/ 现在总是执行真除法,不管操作数的类型,都会返回包含任何余数的一个浮点结果。// 执行Floor除法,它截除掉余数并且针对整数操作数返回一个整数,如果有任何一个操作数是浮点数类型,则返回一个浮点数。
- 在python2.6中,/ 表示传统除法,如果两个操作数都是整数的话,执行截断的整数除法(好像是Floor除法????);否则,执行浮点除法(保留余数,好像是真除法?)。//执行Floor除法,并且像在python3.0中一样工作,对于整数执行截断除法,对于浮点数执行浮点除法。
Python进阶(八)-编写带参数decorator
继续考察@log 装饰器:
- def log(f):
- def fn(x):
- print 'call ' + f.__name__ + '()...'
- return f(x)
- return fn
- 1
- 2
- 3
- 4
- 5
发现对于被装饰的函数,log打印的语句是不能变的(除了函数名)。
如果有的函数非常重要,希望打印出’[INFO] call xxx()…’,有的函数不太重要,希望打印出’[DEBUG] call xxx()…’,这时,log函数本身就需要传入’INFO’或’DEBUG’这样的参数,类似这样:
- @log('DEBUG')
- def my_func():
- pass
- 1
- 2
- 3
把上面的定义翻译成高阶函数的调用,就是:
my_func = log('DEBUG')(my_func)
- 1
上面的语句看上去还是比较绕,再展开一下:
- log_decorator = log('DEBUG')
- my_func = log_decorator(my_func)
- 1
- 2
上面的语句又相当于:
- log_decorator = log('DEBUG')
- @log_decorator
- def my_func():
- pass
- 1
- 2
- 3
- 4
所以,带参数的log函数首先返回一个decorator函数,再让这个decorator函数接收my_func并返回新函数:
- def log(prefix):
- def log_decorator(f):
- def wrapper(*args, **kw):
- print '[%s] %s()...' % (prefix, f.__name__)
- return f(*args, **kw)
- return wrapper
- return log_decorator
-
- @log('DEBUG')
- def test():
- pass
- print test()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
执行结果:
[DEBUG] test()…
None
对于这种3层嵌套的decorator定义,你可以先把它拆开:
- # 标准decorator:
- def log_decorator(f):
- def wrapper(*args, **kw):
- print '[%s] %s()...' % (prefix, f.__name__)
- return f(*args, **kw)
- return wrapper
- return log_decorator
-
- # 返回decorator:
- def log(prefix):
- return log_decorator(f)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
拆开以后会发现,调用会失败,因为在3层嵌套的decorator定义中,最内层的wrapper引用了最外层的参数prefix,所以,把一个闭包拆成普通的函数调用会比较困难。不支持闭包的编程语言要实现同样的功能就需要更多的代码。
举例
在@performance实现打印秒的同时,请给 @performace 增加一个参数,允许传入’s’或’ms’:
- @performance('ms')
- def factorial(n):
- return reduce(lambda x,y: x*y, range(1, n+1))
- 1
- 2
- 3
要实现带参数的@performance,就需要实现:
my_func = performance('ms')(my_func)
- 1
需要3层嵌套的decorator来实现。
参考代码:
- import time
- def performance(unit):
- def perf_decorator(f):
- def wrapper(*args, **kw):
- t1 = time.time()
- r = f(*args, **kw)
- t2 = time.time()
- t = (t2 - t1) * 1000 if unit=='ms' else (t2 - t1)
- print 'call %s() in %f %s' % (f.__name__, t, unit)
- return r
- return wrapper
- return perf_decorator
-
- @performance('ms')
- def factorial(n):
- return reduce(lambda x,y: x*y, range(1, n+1))
- print factorial(10)
Python进阶(九)-Python陷阱:Nonetype
今天解决一位网友的问题,内容如下:
请教代码问题
- def calc_prod(lst):
- def ff():
- print map(lambda x:x*x,lst)
- return ff
-
- f = calc_prod([1, 2, 3, 4])
- print f()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果:
[1, 4, 9, 16]
None
这样写输出为什么有None
针对这一问题,自己在IDEA中进行了调试,发现果然多输出了一行None。出现这一现象确实很令人费解。
自己写了简单的测试语句,如下:
- b = print(5)
- print(b)
- 1
- 2
通过断点调试,内容如下:
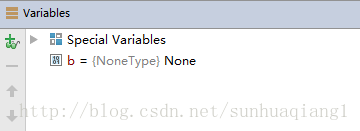
发现b的值确实为None,且其类型为NoneType。
那么什么是Nonetype?
要理解这个,首先要理解Python对象,python对象具有三个特性:身份、类型、值。
这三个特性在对象创建时被赋值。只有值可以改变,其他只读。类型本身也是对象。
Null与None是Python的特殊类型,Null对象或者是None Type,它只有一个值None.
它不支持任何运算也没有任何内建方法. None和任何其他的数据类型比较永远返回False。
None有自己的数据类型NoneType。你可以将None复制给任何变量,但是你不能创建其他NoneType对象。
一句话总结:Null对象是python对象,又叫做NoneType,None是这个对象的值。
看过了NoneType的解释,之所以出现None就很好理解了。
NoneType之所以出现是因为定义了一个变量或函数,却没有值或者返回值,因此会默认值为None。
而在上面的程序中,虽然高阶函数calc_prod()有返回值ff,但是ff()却没有返回值,则传递到外层函数calc_prod()同样没有返回值,故输出了None。 若代码改为如下所示,则可以完美实现列表的输出。
- def calc_prod(lst):
- def ff():
- return map(lambda x:x*x,lst)
- return ff
-
- f = calc_prod([1, 2, 3, 4])
- print(f())
Python进阶(十)-Python 编程规范
在学习一门新的编程语言时,掌握其良好的编程规范可避免一些细节性错误的发生。去除一些不必要的学习障碍。
分号
不要在行尾加分号, 也不要用分号将两条命令放在同一行.
行长度
每行不超过80个字符
例外:
- 1.长的导入模块语句
- 2.注释里的URL
不要使用反斜杠连接行.
Python会将圆括号, 中括号和花括号中的行隐式连接起来 , 你可以利用这个特点. 如果需要, 你可以在表达式外围增加一对额外的圆括号.
- foo_bar(self, width, height, color='black', design=None, x='foo',emphasis=None, highlight=0)
- if (width == 0 and height == 0 and
- color == 'red' and emphasis == 'strong'):
- 1
- 2
- 3
如果一个文本字符串在一行放不下, 可以使用圆括号来实现隐式行连接:
- x = ('This will build a very long long '
- 'long long long long long long string')
- 1
- 2
在注释中,如果必要,将长的URL放在一行上。
Yes:
- # See details at
- # http://www.example.com/us/developer/documentation/api/content/v2.0/csv_file_name_extension_full_specification.html
- 1
- 2
No:
- # See details at
- # http://www.example.com/us/developer/documentation/api/content/\
- # v2.0/csv_file_name_extension_full_specification.html
- 1
- 2
- 3
注意上面例子中的元素缩进; 你可以在本文的缩进部分找到解释.
括号
宁缺毋滥的使用括号
除非是用于实现行连接, 否则不要在返回语句或条件语句中使用括号. 不过在元组两边使用括号是可以的.
Yes:
- if foo:
- bar()
- while x:
- x = bar()
- if x and y:
- bar()
- if not x:
- bar()
- return foo
- for (x, y) in dict.items(): ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
No:
- if (x):
- bar()
- if not(x):
- bar()
- return (foo)
- 1
- 2
- 3
- 4
- 5
缩进
用4个空格来缩进代码
绝对不要用tab, 也不要tab和空格混用. 对于行连接的情况, 你应该要么垂直对齐换行的元素(见行长度部分的示例), 或者使用4空格的悬挂式缩进(这时第一行不应该有参数):
Yes:
- # Aligned with opening delimiter
- foo = long_function_name(var_one, var_two,
- var_three, var_four)
-
- # Aligned with opening delimiter in a dictionary
- foo = {
- long_dictionary_key: value1 +
- value2,
- ...
- }
-
- # 4-space hanging indent; nothing on first line
- foo = long_function_name(
- var_one, var_two, var_three,
- var_four)
-
- # 4-space hanging indent in a dictionary
- foo = {
- long_dictionary_key:
- long_dictionary_value,
- ...
- }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
No:
- # Stuff on first line forbidden
- foo = long_function_name(var_one, var_two,
- var_three, var_four)
-
- # 2-space hanging indent forbidden
- foo = long_function_name(
- var_one, var_two, var_three,
- var_four)
-
- # No hanging indent in a dictionary
- foo = {
- long_dictionary_key:
- long_dictionary_value,
- ...
- }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
空行
顶级定义之间空两行, 方法定义之间空一行
顶级定义之间空两行, 比如函数或者类定义. 方法定义, 类定义与第一个方法之间, 都应该空一行. 函数或方法中, 某些地方要是你觉得合适, 就空一行.
空格
按照标准的排版规范来使用标点两边的空格。
括号内不要有空格.
Yes:
spam(ham[1], {eggs: 2}, [])
- 1
No:
spam( ham[ 1 ], { eggs: 2 }, [ ] )
- 1
不要在逗号, 分号, 冒号前面加空格, 但应该在它们后面加(除了在行尾).
Yes:
- if x == 4:
- print x, y
- x, y = y, x
- ```
- No:
- 1
- 2
- 3
- 4
- 5
- 6
if x == 4 :
print x , y
x , y = y , x
- 参数列表, 索引或切片的左括号前不应加空格.
- Yes: spam(1)
- no: spam (1)
- Yes: dict['key'] = list[index]
- No: dict ['key'] = list [index]
- 在二元操作符两边都加上一个空格, 比如赋值(=), 比较(==, <, >, !=, <>, <=, >=, in, not in, is, is not), 布尔(and, or, not). 至于算术操作符两边的空格该如何使用, 需要你自己好好判断. 不过两侧务必要保持一致.
- Yes: x == 1
- No: x<1
- 当’=’用于指示关键字参数或默认参数值时, 不要在其两侧使用空格.
- Yes: def complex(real, imag=0.0): return magic(r=real, i=imag)
- No: def complex(real, imag = 0.0): return magic(r = real, i = imag)
- 不要用空格来垂直对齐多行间的标记, 因为这会成为维护的负担(适用于:, #, =等):
- Yes:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- foo = 1000 # comment
- long_name = 2 # comment that should not be aligned
- dictionary = {
- "foo": 1,
- "long_name": 2,
- }
-
- No:
- 1
- 2
- 3
- foo = 1000 # comment
- long_name = 2 # comment that should not be aligned
- dictionary = {
- "foo" : 1,
- "long_name": 2,
- }
Shebang
大部分.py文件不必以#!作为文件的开始. 根据 PEP-394 , 程序的main文件应该以 #!/usr/bin/python2或者 #!/usr/bin/python3开始.
(译者注: 在计算机科学中, Shebang (也称为Hashbang)是一个由井号和叹号构成的字符串行(#!), 其出现在文本文件的第一行的前两个字符. 在文件中存在Shebang的情况下, 类Unix操作系统的程序载入器会分析Shebang后的内容, 将这些内容作为解释器指令, 并调用该指令, 并将载有Shebang的文件路径作为该解释器的参数. 例如, 以指令#!/bin/sh开头的文件在执行时会实际调用/bin/sh程序.)
#!先用于帮助内核找到Python解释器, 但是在导入模块时, 将会被忽略. 因此只有被直接执行的文件中才有必要加入#!.
注释
确保对模块, 函数, 方法和行内注释使用正确的风格
文档字符串
Python有一种独一无二的的注释方式: 使用文档字符串. 文档字符串是包, 模块, 类或函数里的第一个语句. 这些字符串可以通过对象的doc成员被自动提取, 并且被pydoc所用. (你可以在你的模块上运行pydoc试一把, 看看它长什么样). 我们对文档字符串的惯例是使用三重双引号”“”( PEP-257 ). 一个文档字符串应该这样组织: 首先是一行以句号, 问号或惊叹号结尾的概述(或者该文档字符串单纯只有一行). 接着是一个空行. 接着是文档字符串剩下的部分, 它应该与文档字符串的第一行的第一个引号对齐. 下面有更多文档字符串的格式化规范.
模块
每个文件应该包含一个许可样板. 根据项目使用的许可(例如, Apache 2.0, BSD, LGPL, GPL), 选择合适的样板.
函数和方法
下文所指的函数,包括函数, 方法, 以及生成器.
一个函数必须要有文档字符串, 除非它满足以下条件:
外部不可见
非常短小
简单明了
文档字符串应该包含函数做什么, 以及输入和输出的详细描述. 通常, 不应该描述”怎么做”, 除非是一些复杂的算法. 文档字符串应该提供足够的信息, 当别人编写代码调用该函数时, 他不需要看一行代码, 只要看文档字符串就可以了. 对于复杂的代码, 在代码旁边加注释会比使用文档字符串更有意义.
关于函数的几个方面应该在特定的小节中进行描述记录, 这几个方面如下文所述. 每节应该以一个标题行开始. 标题行以冒号结尾. 除标题行外, 节的其他内容应被缩进2个空格.
Args:
列出每个参数的名字, 并在名字后使用一个冒号和一个空格, 分隔对该参数的描述.如果描述太长超过了单行80字符,使用2或者4个空格的悬挂缩进(与文件其他部分保持一致). 描述应该包括所需的类型和含义. 如果一个函数接受*foo(可变长度参数列表)或者**bar (任意关键字参数), 应该详细列出*foo和**bar.
Returns: (或者 Yields: 用于生成器)
描述返回值的类型和语义. 如果函数返回None, 这一部分可以省略.
Raises:
列出与接口有关的所有异常.
- def fetch_bigtable_rows(big_table, keys, other_silly_variable=None):
- """Fetches rows from a Bigtable.
- Retrieves rows pertaining to the given keys from the Table instance
- represented by big_table. Silly things may happen if
- other_silly_variable is not None.
- Args:
- big_table: An open Bigtable Table instance.
- keys: A sequence of strings representing the key of each table row
- to fetch.
- other_silly_variable: Another optional variable, that has a much
- longer name than the other args, and which does nothing.
- Returns:
- A dict mapping keys to the corresponding table row data
- fetched. Each row is represented as a tuple of strings. For
- example:
- {'Serak': ('Rigel VII', 'Preparer'),
- 'Zim': ('Irk', 'Invader'),
- 'Lrrr': ('Omicron Persei 8', 'Emperor')}
- If a key from the keys argument is missing from the dictionary,
- then that row was not found in the table.
- Raises:
- IOError: An error occurred accessing the bigtable.Table object.
- """
- pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
类
类应该在其定义下有一个用于描述该类的文档字符串. 如果你的类有公共属性(Attributes), 那么文档中应该有一个属性(Attributes)段. 并且应该遵守和函数参数相同的格式.
- class SampleClass(object):
- """Summary of class here.
- Longer class information....
- Longer class information....
- Attributes:
- likes_spam: A boolean indicating if we like SPAM or not.
- eggs: An integer count of the eggs we have laid.
- """
-
- def __init__(self, likes_spam=False):
- """Inits SampleClass with blah."""
- self.likes_spam = likes_spam
- self.eggs = 0
-
- def public_method(self):
- """Performs operation blah."""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
块注释和行注释
最需要写注释的是代码中那些技巧性的部分. 如果你在下次代码审查的时候必须解释一下, 那么你应该现在就给它写注释. 对于复杂的操作, 应该在其操作开始前写上若干行注释. 对于不是一目了然的代码, 应在其行尾添加注释.
‘# We use a weighted dictionary search to find out where i is in
‘# the array. We extrapolate position based on the largest num
‘# in the array and the array size and then do binary search to
‘# get the exact number.’
if i & (i-1) == 0: # true iff i is a power of 2
为了提高可读性, 注释应该至少离开代码2个空格.
另一方面, 绝不要描述代码. 假设阅读代码的人比你更懂Python, 他只是不知道你的代码要做什么.
‘# BAD COMMENT: Now go through the b array and make sure whenever i occurs
‘# the next element is i+1
类
如果一个类不继承自其它类, 就显式的从object继承. 嵌套类也一样.
Yes: class SampleClass(object):
pass
class OuterClass(object):
class InnerClass(object):
pass
class ChildClass(ParentClass):
“”“Explicitly inherits from another class already.”“”
No: class SampleClass:
pass
class OuterClass:
class InnerClass:
pass
继承自 object 是为了使属性(properties)正常工作, 并且这样可以保护你的代码, 使其不受Python 3的一个特殊的潜在不兼容性影响. 这样做也定义了一些特殊的方法, 这些方法实现了对象的默认语义, 包括 new, init, delattr, getattribute, setattr, hash, repr, and str .
字符串
即使参数都是字符串, 使用%操作符或者格式化方法格式化字符串. 不过也不能一概而论, 你需要在+和%之间好好判定.
Yes: x = a + b
x = ‘%s, %s!’ % (imperative, expletive)
x = ‘{}, {}!’.format(imperative, expletive)
x = ‘name: %s; score: %d’ % (name, n)
x = ‘name: {}; score: {}’.format(name, n)
No: x = ‘%s%s’ % (a, b) # use + in this case
x = ‘{}{}’.format(a, b) # use + in this case
x = imperative + ‘, ’ + expletive + ‘!’
x = ‘name: ’ + name + ‘; score: ’ + str(n)
避免在循环中用+和+=操作符来累加字符串. 由于字符串是不可变的, 这样做会创建不必要的临时对象, 并且导致二次方而不是线性的运行时间. 作为替代方案, 你可以将每个子串加入列表, 然后在循环结束后用 .join 连接列表. (也可以将每个子串写入一个 cStringIO.StringIO 缓存中.)
Yes: items = [‘
for last_name, first_name in employee_list:
items.append(‘’ % (last_name, first_name))
items.append(‘
| %s, %s |
employee_table = ”.join(items)
No: employee_table = ‘’
for last_name, first_name in employee_list:
employee_table += ‘’ % (last_name, first_name)
employee_table += ‘
| %s, %s |
在同一个文件中, 保持使用字符串引号的一致性. 使用单引号’或者双引号”之一用以引用字符串, 并在同一文件中沿用. 在字符串内可以使用另外一种引号, 以避免在字符串中使用. GPyLint已经加入了这一检查.
(译者注:GPyLint疑为笔误, 应为PyLint.)
Yes:
Python(‘Why are you hiding your eyes?’)
Gollum(“I’m scared of lint errors.”)
Narrator(‘“Good!” thought a happy Python reviewer.’)
No:
Python(“Why are you hiding your eyes?”)
Gollum(‘The lint. It burns. It burns us.’)
Gollum(“Always the great lint. Watching. Watching.”)
为多行字符串使用三重双引号”“”而非三重单引号’‘’. 当且仅当项目中使用单引号’来引用字符串时, 才可能会使用三重’‘’为非文档字符串的多行字符串来标识引用. 文档字符串必须使用三重双引号”“”. 不过要注意, 通常用隐式行连接更清晰, 因为多行字符串与程序其他部分的缩进方式不一致.
Yes:
print (“This is much nicer.\n”
“Do it this way.\n”)
No:
print “”“This is pretty ugly.
Don’t do this.
“”“
文件和sockets
在文件和sockets结束时, 显式的关闭它.
除文件外, sockets或其他类似文件的对象在没有必要的情况下打开, 会有许多副作用, 例如:
- 1.它们可能会消耗有限的系统资源, 如文件描述符. 如果这些资源在使用后没有及时归还系统, 那么用于处理这些对象的代码会将资源消耗殆尽.
- 2.持有文件将会阻止对于文件的其他诸如移动、删除之类的操作.
3.仅仅是从逻辑上关闭文件和sockets, 那么它们仍然可能会被其共享的程序在无意中进行读或者写操作. 只有当它们真正被关闭后, 对于它们尝试进行读或者写操作将会抛出异常, 并使得问题快速显现出来.
- 1
而且, 幻想当文件对象析构时, 文件和sockets会自动关闭, 试图将文件对象的生命周期和文件的状态绑定在一起的想法, 都是不现实的. 因为有如下原因:
- 1.没有任何方法可以确保运行环境会真正的执行文件的析构.不同的Python实现采用不同的内存管理技术, 比如延时垃圾处理机制. 延时垃圾处理机制可能会导致对象生命周期被任意无限制的延长.
- 2.对于文件意外的引用,会导致对于文件的持有时间超出预期(比如对于异常的跟踪, 包含有全局变量等).
推荐使用 “with”语句 以管理文件:
- with open("hello.txt") as hello_file:
- for line in hello_file:
- print line
- 1
- 2
- 3
对于不支持使用”with”语句的类似文件的对象,使用
- contextlib.closing():
- import contextlib
- with contextlib.closing(urllib.urlopen("http://www.python.org/")) as front_page:
- for line in front_page:
- print line
- Legacy AppEngine 中Python 2.5的代码如使用”with”语句, 需要添加 “from __future__ import with_statement”.
- 1
- 2
- 3
- 4
- 5
- 6
TODO注释
为临时代码使用TODO注释, 它是一种短期解决方案. 不算完美, 但够好了.
TODO注释应该在所有开头处包含”TODO”字符串, 紧跟着是用括号括起来的你的名字, email地址或其它标识符. 然后是一个可选的冒号. 接着必须有一行注释, 解释要做什么. 主要目的是为了有一个统一的TODO格式, 这样添加注释的人就可以搜索到(并可以按需提供更多细节). 写了TODO注释并不保证写的人会亲自解决问题. 当你写了一个TODO, 请注上你的名字.
‘# TODO(kl@gmail.com): Use a “*” here for string repetition.
‘# TODO(Zeke) Change this to use relations.
“`
如果你的TODO是”将来做某事”的形式, 那么请确保你包含了一个指定的日期(“2009年11月解决”)或者一个特定的事件(“等到所有的客户都可以处理XML请求就移除这些代码”).
导入格式
每个导入应该独占一行
Yes: import os
import sys
No: import os, sys
导入总应该放在文件顶部, 位于模块注释和文档字符串之后, 模块全局变量和常量之前. 导入应该按照从最通用到最不通用的顺序分组:
标准库导入
第三方库导入
应用程序指定导入
每种分组中, 应该根据每个模块的完整包路径按字典序排序, 忽略大小写.
import foo
from foo import bar
from foo.bar import baz
from foo.bar import Quux
from Foob import ar
语句
通常每个语句应该独占一行
不过, 如果测试结果与测试语句在一行放得下, 你也可以将它们放在同一行. 如果是if语句, 只有在没有else时才能这样做. 特别地, 绝不要对 try/except 这样做, 因为try和except不能放在同一行.
Yes:
if foo: bar(foo)
No:
if foo: bar(foo)
else: baz(foo)
try: bar(foo)
except ValueError: baz(foo)
try:
bar(foo)
except ValueError: baz(foo)
访问控制
在Python中, 对于琐碎又不太重要的访问函数, 你应该直接使用公有变量来取代它们, 这样可以避免额外的函数调用开销. 当添加更多功能时, 你可以用属性(property)来保持语法的一致性.
(译者注: 重视封装的面向对象程序员看到这个可能会很反感, 因为他们一直被教育: 所有成员变量都必须是私有的! 其实, 那真的是有点麻烦啊. 试着去接受Pythonic哲学吧)
另一方面, 如果访问更复杂, 或者变量的访问开销很显著, 那么你应该使用像 get_foo() 和 set_foo() 这样的函数调用. 如果之前的代码行为允许通过属性(property)访问 , 那么就不要将新的访问函数与属性绑定. 这样, 任何试图通过老方法访问变量的代码就没法运行, 使用者也就会意识到复杂性发生了变化.
命名
module_name, package_name, ClassName, method_name, ExceptionName, function_name, GLOBAL_VAR_NAME, instance_var_name, function_parameter_name, local_var_name.
应该避免的名称
单字符名称, 除了计数器和迭代器.
包/模块名中的连字符(-)
双下划线开头并结尾的名称(Python保留, 例如init)
命名约定
所谓”内部(Internal)”表示仅模块内可用, 或者, 在类内是保护或私有的.
用单下划线(_)开头表示模块变量或函数是protected的(使用import * from时不会包含).
用双下划线(__)开头的实例变量或方法表示类内私有.
将相关的类和顶级函数放在同一个模块里. 不像Java, 没必要限制一个类一个模块.
对类名使用大写字母开头的单词(如CapWords, 即Pascal风格), 但是模块名应该用小写加下划线的方式(如lower_with_under.py). 尽管已经有很多现存的模块使用类似于CapWords.py这样的命名, 但现在已经不鼓励这样做, 因为如果模块名碰巧和类名一致, 这会让人困扰.
Python之父Guido推荐的规范
Type Public Internal
Modules lower_with_under _lower_with_under
Packages lower_with_under
Classes CapWords _CapWords
Exceptions CapWords
Functions lower_with_under() _lower_with_under()
Global/Class Constants CAPS_WITH_UNDER _CAPS_WITH_UNDER
Global/Class Variables lower_with_under _lower_with_under
Instance Variables lower_with_under _lower_with_under (protected) or __lower_with_under (private)
Method Names lower_with_under() _lower_with_under() (protected) or __lower_with_under() (private)
Function/Method Parameters lower_with_under
Local Variables lower_with_under
Main
即使是一个打算被用作脚本的文件, 也应该是可导入的. 并且简单的导入不应该导致这个脚本的主功能(main functionality)被执行, 这是一种副作用. 主功能应该放在一个main()函数中.
在Python中, pydoc以及单元测试要求模块必须是可导入的. 你的代码应该在执行主程序前总是检查 if name == ‘main’ , 这样当模块被导入时主程序就不会被执行.
def main():
…
if name == ‘main‘:
main()
所有的顶级代码在模块导入时都会被执行. 要小心不要去调用函数, 创建对象, 或者执行那些不应该在使用pydoc时执行的操作.
Python进阶(十一)-定义实例方法
一个实例的私有属性就是以__开头的属性,无法被外部访问。那这些属性定义有什么用?
虽然私有属性无法从外部访问,但是,从类的内部是可以访问的。除了可以定义实例的属性外,还可以定义实例的方法。
实例的方法就是在类中定义的函数,它的第一个参数永远是 self,指向调用该方法的实例本身,其他参数和一个普通函数是完全一样的。
- class Person(object):
- def __init__(self, name):
- self.__name = name
-
- def get_name(self):
- return self.__name
- 1
- 2
- 3
- 4
- 5
- 6
get_name(self) 就是一个实例方法,它的第一个参数是self。init(self, name)其实也可看做是一个特殊的实例方法。
调用实例方法必须在实例上调用:
- p1 = Person('Bob')
- print p1.get_name() # self不需要显式传入
- # => Bob
- 1
- 2
- 3
在实例方法内部,可以访问所有实例属性,这样,如果外部需要访问私有属性,可以通过方法调用获得,这种数据封装的形式除了能保护内部数据一致性外,还可以简化外部调用的难度。
举例
请给 Person 类增加一个私有属性 __score,表示分数,再增加一个实例方法 get_grade(),能根据 __score 的值分别返回 A-优秀, B-及格, C-不及格三档。
注意get_grade()是实例方法,第一个参数为self。
参考代码:
- class Person(object):
-
- def __init__(self, name, score):
- self.__name = name
- self.__score = score
-
- def get_grade(self):
- if self.__score >= 80:
- return 'A'
- if self.__score >= 60:
- return 'B'
- return 'C'
-
- p1 = Person('Bob', 90)
- p2 = Person('Alice', 65)
- p3 = Person('Tim', 48)
-
- print p1.get_grade()
- print p2.get_grade()
- print p3.get_grade()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
运行结果
Python进阶(十二)-浅谈python中的方法
我们在 class 中定义的实例方法其实也是属性,它实际上是一个函数对象:
- class Person(object):
- def __init__(self, name, score):
- self.name = name
- self.score = score
- def get_grade(self):
- return 'A'
-
- p1 = Person('Bob', 90)
- print p1.get_grade
- # => <bound method Person.get_grade of <__main__.Person object at 0x109e58510>>
- print p1.get_grade()
- # => A
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
也就是说,p1.get_grade 返回的是一个函数对象,但这个函数是一个绑定到实例的函数,p1.get_grade() 才是方法调用。
因为方法也是一个属性,所以,它也可以动态地添加到实例上,只是需要用 types.MethodType() 把一个函数变为一个方法:
- import types
- def fn_get_grade(self):
- if self.score >= 80:
- return 'A'
- if self.score >= 60:
- return 'B'
- return 'C'
-
- class Person(object):
- def __init__(self, name, score):
- self.name = name
- self.score = score
-
- p1 = Person('Bob', 90)
- p1.get_grade = types.MethodType(fn_get_grade, p1, Person)
- print p1.get_grade()
- # => A
- p2 = Person('Alice', 65)
- print p2.get_grade()
- # ERROR: AttributeError: 'Person' object has no attribute 'get_grade'
- # 因为p2实例并没有绑定get_grade
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
给一个实例动态添加方法并不常见,直接在class中定义要更直观。
举例
由于属性可以是普通的值对象,如 str,int 等,也可以是方法,还可以是函数,大家看看下面代码的运行结果,请想一想 p1.get_grade 为什么是函数而不是方法:
- class Person(object):
- def __init__(self, name, score):
- self.name = name
- self.score = score
- self.get_grade = lambda: 'A'
-
- p1 = Person('Bob', 90)
- print p1.get_grade
- print p1.get_grade()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
直接把 lambda 函数赋值给 self.get_grade 和绑定方法有所不同,函数调用不需要传入 self,但是方法调用需要传入 self。
Python进阶(十三)-浅谈sorted 函数应用
众所周知,def cmp 作为方法存在,用sort对实例进行排序时,会用到class 中的cmp。但是,在python3中,取消了 sorted对cmp的支持。
python3 中有关排序的sorted方法如下:
sorted(iterable,key=None,reverse=False)
- 1
其中,key接受一个函数,这个函数只接受一个元素,默认为None。
reverse是一个布尔值。如果设置为True,列表元素将被倒序排列,默认为False。
下面着重介绍key的作用原理:
key指定一个接收一个参数的函数,这个函数用于从每个元素中提取一个用于比较的关键字。默认值为None 。
例1
- students = [('john', 'A', 15), ('jane', 'B', 12), ('dave','B', 10)]
- sorted(students,key=lambda s: x[2]) #按照年龄来排序
- 1
- 2
结果:[(‘dave’,’B’, 10), (‘jane’, ‘B’, 12), (‘john’, ‘A’, 15)]
例2
这是一个字符串排序,排序规则:小写<大写<奇数<偶数
s = ‘asdf234GDSdsf23’ #排序:小写-大写-奇数-偶数
print("".join(sorted(s, key=lambda x: (x.isdigit(),x.isdigit() and int(x) % 2 == 0,x.isupper(),x))))
- 1
原理:先比较元组的第一个值,如果相等就比较元组的下一个值,以此类推。
先看一下Boolean value 的排序:
print(sorted([True,Flase]))===>结果[False,True]
Boolean 的排序会将 False 排在前,True排在后 .
- 1.x.isdigit()的作用是把数字放在前边,字母放在后边.
- 2.x.isdigit() and int(x) % 2 == 0的作用是保证奇数在前,偶数在后。
- 3.x.isupper()的作用是在前面基础上,保证字母小写在前大写在后.
- 4.最后的x表示在前面基础上,对所有类别数字或字母排序。
最后结果:addffssDGS33224
例3
一道面试题:
- list1=[7, -8, 5, 4, 0, -2, -5]
- #要求1.正数在前负数在后 2.正数从小到大 3.负数从大到小
- sorted(list1,key=lambda x:(x<0,abs(x)))
- 1
- 2
- 3
解题思路:先按照正负排先后,再按照大小排先后。
Python进阶(十四)- 基础课程结课总结:高阶函数
在慕课网完成了廖雪峰老师的《Python入门》与《Python进阶》两门基础课程。在此做一下简单的知识点小结。
函数式编程
Python特点:
- 不是纯函数式编程(允许变量存在);
- 支持高阶函数(可以传入函数作为变量);
- 支持闭包(可以返回函数);
- 有限度的支持匿名函数;
高阶函数:
- 变量可以指向函数;
- 函数的参数可以接收变量;
- 一个函数可以接收另一个函数作为参数;
- def add(x,y,f):
- return f(x)+f(y)
- #14
- add(-5,9,abs)
- 1
- 2
- 3
- 4
内置高阶函数map()
map函数有两个参数,一个是函数,另一个是列表,返回值为对传入的列表中每一个元素执行传入的函数操作之后得到的列表;
- def format_name(s):
- return s.title()
-
- print map(format_name, ['adam', 'LISA', 'barT'])
- 1
- 2
- 3
- 4
内置高阶函数reduce()
reduce函数也有两个参数,一个是函数,另一个是列表,返回值为对list的每一个元素反复调用函数f,得到最终结果,以下函数为连乘;
- def prod(x, y):
- return x*y;
-
- print reduce(prod, [2, 4, 5, 7, 12])
- 1
- 2
- 3
- 4
内置高阶函数filter()
filter函数接受函数参数f和列表参数lst,f对lst元素进行判断,返回lst元素中调用f函数结果为true的元素组成的列表(将不满足f函数条件的元素过滤掉);
- import math
-
- def is_sqr(x):
- return int(math.sqrt(x))*int(math.sqrt(x))==x
-
- print filter(is_sqr, range(1, 101))
- 1
- 2
- 3
- 4
- 5
- 6
自定义排序函数sorted()
sorted函数接受一个列表lst和一个函数参数f,f为自定义的比较lst元素大小的函数,返回值为lst中元素按f函数排列的列表;
- def cmp_ignore_case(s1, s2):
- return cmp(s1.lower(),s2.lower())
-
- print sorted(['bob', 'about', 'Zoo', 'Credit'], cmp_ignore_case)
- 1
- 2
- 3
- 4
返回函数:
- def calc_prod(lst):
- def prod(x,y):
- return x*y;
- def g():
- return reduce(prod,lst)
- return g;
-
- f = calc_prod([1, 2, 3, 4])
- print f()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
闭包
内层函数使用外层函数的参数,然后返回内层函数;
- def count():
- fs = []
- for i in range(1, 4):
- def f(j):
- def g():
- return j*j;
- return g
- fs.append(f(i))
- return fs
-
- f1, f2, f3 = count()
- print f1(), f2(), f3()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
匿名函数
传入函数参数不需要显式定义函数,可以用lambda x:statement x为参数,statement为对参数执行的语句;
- def is_not_empty(s):
- return s and len(s.strip()) > 0
-
- print filter(lambda s:s and len(s.strip())>0, ['test', None, '', 'str', ' ', 'END'])
- 1
- 2
- 3
- 4
装饰器
给函数添加新功能,并简化该函数调用;
无参数装饰器
- def log(f):
- def fn(*args, **kw): #*args,**kw保证对任意个数参数都能正常调用
- print 'call ' + f.__name__ + '()...'
- return f(*args, **kw)
- return fn
-
- @log #调用日志装饰器
- def factorial(n):
- return reduce(lambda x,y: x*y, range(1, n+1))
- #call factorial()...
- #3628800
- print factorial(10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
带参数装饰器
- def log(prefix):
- def log_decorator(f):
- def wrapper(*args, **kw):
- print '[%s] %s()...' % (prefix, f.__name__)
- return f(*args, **kw)
- return wrapper
- return log_decorator
-
- @log('DEBUG') #DEBUG为给装饰器传入的参数
- def test():
- pass
- #[DEBUG] test()...
- #None
- print test()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
利用functool.wraps作用在返回的新函数上,使得调用装饰器以后不改变原函数的信息
- import time, functools
- def performance(unit):
- def perf_decorator(f):
- @functools.wraps(f)
- def wrapper(*args, **kw):
- t1 = time.time()
- r = f(*args, **kw)
- t2 = time.time()
- t = (t2 - t1) * 1000 if unit=='ms' else (t2 - t1)
- print 'call %s() in %f %s' % (f.__name__, t, unit)
- return r
- return wrapper
- return perf_decorator
-
- @performance('ms')
- def factorial(n):
- return reduce(lambda x,y: x*y, range(1, n+1))
- print factorial.__name__
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
偏函数
functools.partial(f,f的默认参数) 减少需要提供给f的参数
- import functools
- int2 = functools.partial(int, base=2)
- int2('1000000') #64
Python进阶(十五)-file文件操作
Python下文件操作与Java差不多。打开文件的模式有三种:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;因为会清空原有文件的内容,一定要慎用】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
注意最后要记得关闭文件:f.close()
python只能将字符串写入到文本文件。要将数值数据存储到文本本件中,必须先试用函数str()将其转换为字符串格式。
- #r模式(只读模式)
- f = open('yesterday',encoding='utf-8')
- data = f.read()
- f.close()
- print(data)
- #只读文件的前5行:
- f = open('yesterday','r',encoding='utf-8')
- for i in range(5):
- print(f.readline())
- #以列表的方式读取这个文件
- f = open('yesterday','r',encoding='utf-8')
- for line in f.readlines():
- print(line)
- #对文件的第3行,做一个特殊的打印(这种方式比较低效,因为它会先把文件全部读取到内存中,文件较大时会很影响性能)
- f = open('yesterday','r',encoding='utf-8')
- for index,line in enumerate(f.readlines()):
- if index == 2:
- print('-----测试线----',line)
- continue
- print(line)
- #比较高效的,逐行读取文件内容,因为它是一行一行的去读取文件,不会先把文件一次性全部读取到内存中
- f = open('yesterday','r',encoding='utf-8')
- for line in f:
- print(line)
- #比较高效的,对文件的3三行进行过特殊打印
- f = open('yesterday','r',encoding='utf-8')
- count = 0
- for line in f:
- if count == 2:
- print('------测试线----:',line)
- count += 1
- print(line)
-
- #w模式(如果没有就创建文件,如果有就清空文件,一定要慎用)
- f = open('yesterday','w',encoding='utf-8')
- f.write("这就是一行测试\n")
- f.write("测试2\n")
- f.write("测试3")
-
- #a模式(追加模式,如果没有就创建文件,如果有就把内容追加进去)
- f = open('yesterday','a',encoding='utf-8')
- f.write("test1\n")
-
- #文件光标的操作
- f = open('yesterday','r',encoding='utf-8')
- #获得文件的光标
- print(f.tell())
- print(f.readline())
- print(f.tell())
- #回到最开始的位置(也可以指定一个位置,前提是你得知道你去往的字符具体在哪个位置才行)
- f.seek(0)
-
- #显示文件的编码
- print(f.encoding)
- #显示文件句柄的编号(我并不确定这个说法是否正确,用到时请仔细去查一下)
- print(f.fileno())
- #测试是否是一个终端设备文件
- print(f.isatty())
- #把缓存的内容刷新到硬盘(进度条那个脚本里有写一个示例)
- f.flush()
- #指定文件从哪里开始截断,如果没有参数,默认从0开始等于清空了这个文件
- #f.truncate()
-
- #r+ 模式(读,追加模式)
- f = open('yesterday','r+',encoding='utf-8')
- data = f.read()
- print(data)
- f.write("test...\n")
-
- #还有 w+写读模式, a+追加读模式,这一般不用,真用到了再去了解下吧
- #rb 模式,以二进制的方式读取这个文件
- #wb 模式,二进制写
- '''
- '''
- #with语句(很实用,记得要经常用哟~,在《Python编程从入门到实战》那本书里的文件与异常那一章有详细用法)
- #为了避免打开文件后忘记关闭,可以通过管理上下文,即:
- with open('log','r') as f:
-
- ...
- #如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
- #在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
- with open('log1') as obj1, open('log2') as obj2:
- pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
参考资料
http://www.yiibai.com/python3/file_methods.html
Python进阶(十六)-正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
在python中使用正则表达式,需要引入re模块;下面介绍下该模块中的一些方法;
compile和match
re模块中compile用于生成pattern的对象,再通过调用pattern实例的match方法处理文本最终获得match实例;通过使用match获得信息;
- import re
-
- # 将正则表达式编译成Pattern对象
- pattern = re.compile(r'rlovep')
- # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
- m = pattern.match('rlovep.com')
- if m:
- # 使用Match获得分组信息
- print(m.group())
- ### 输出 ###
- # rlovep
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。第二个参数flag是匹配模式,取值可以使用按位或运算符’|’表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile(‘pattern’, re.I | re.M)与re.compile(‘(?im)pattern’)是等价的。
可选值有:
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- M(MULTILINE): 多行模式,改变’^’和’$’的行为
- S(DOTALL): 点任意匹配模式,改变’.’的行为
- L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
group([group1, …])
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
groupdict([default])
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
start([group])
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
end([group])
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
span([group])
返回(start(group), end(group))。
expand(template)
将匹配到的分组代入template中然后返回。template中可以使用\id或\g、 \g引用分组,但不能使用编号0。\id与\g是等价的;但\10将被认为是第10个分组,如果你想表达 \1之后是字符’0’,只能使用\g<1>0。
pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
- pattern: 编译时用的表达式字符串。
- flags: 编译时用的匹配模式。数字形式。
- groups: 表达式中分组的数量。
- groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
实例方法[ | re模块方法]:
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags])
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符’$’。
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags])
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。 pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit])
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags])
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count])
使用repl替换string中每一个匹配的子串后返回替换后的字符串。 当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。 当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。 count用于指定最多替换次数,不指定时全部替换。
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count])
返回 (sub(repl, string[, count]), 替换次数)。
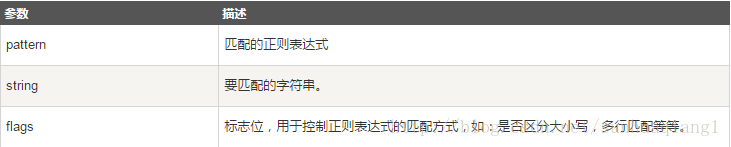
re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。

实例 1
- #!/usr/bin/python
- # -*- coding: UTF-8 -*-
-
- import re
- print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
- print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
- 1
- 2
- 3
- 4
- 5
- 6
以上实例运行输出结果为:
(0, 3)
None
实例 2
- #!/usr/bin/python3
- import re
-
- line = "Cats are smarter than dogs"
-
- matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
-
- if matchObj:
- print ("matchObj.group() : ", matchObj.group())
- print ("matchObj.group(1) : ", matchObj.group(1))
- print ("matchObj.group(2) : ", matchObj.group(2))
- else:
- print ("No match!!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
以上实例执行结果如下:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
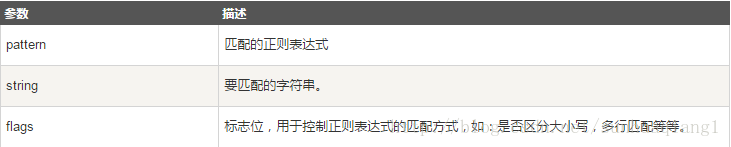
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。

实例一
- import re
- print(re.search("rlovep","rlovep.com").span())
- print(re.search("com","http://rlovep.com").span())
- 1
- 2
- 3
实例二
- import re
- line = "This is my blog"
- #匹配含有is的字符串
- matchObj = re.search( r'(.*) is (.*?) .*', line, re.M|re.I)
- #使用了组输出:当group不带参数是将整个匹配成功的输出
- #当带参数为1时匹配的是最外层左边包括的第一个括号,一次类推;
- if matchObj:
- print ("matchObj.group() : ", matchObj.group())#匹配整个
- print ("matchObj.group(1) : ", matchObj.group(1))#匹配的第一个括号
- print ("matchObj.group(2) : ", matchObj.group(2))#匹配的第二个括号
- else:
- print ("No match!!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出:
matchObj.group() : This is my blog
matchObj.group(1) : This
matchObj.group(2) : my
search和match区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
实例
- #!/usr/bin/python3
-
- import re
-
- line = "Cats are smarter than dogs";
-
- matchObj = re.match( r'dogs', line, re.M|re.I)
- if matchObj:
- print ("match --> matchObj.group() : ", matchObj.group())
- else:
- print ("No match!!")
-
- matchObj = re.search( r'dogs', line, re.M|re.I)
- if matchObj:
- print ("search --> matchObj.group() : ", matchObj.group())
- else:
- print ("No match!!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
以上实例运行结果如下:
No match!!
search –> matchObj.group() : dogs
检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
实例
- #!/usr/bin/python3
- import re
-
- phone = "2004-959-559 # 这是一个电话号码"
-
- # 删除注释
- num = re.sub(r'#.*$', "", phone)
- print ("电话号码 : ", num)
-
- # 移除非数字的内容
- num = re.sub(r'\D', "", phone)
- print ("电话号码 : ", num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
以上实例执行结果如下:
电话号码 : 2004-959-559
电话号码 : 2004959559
repl 参数是一个函数
以下实例中将字符串中的匹配的数字乘于 2:
- #!/usr/bin/python
-
- import re
-
- # 将匹配的数字乘于 2
- def double(matched):
- value = int(matched.group('value'))
- return str(value * 2)
-
- s = 'A23G4HFD567'
- print(re.sub('(?P<value>\d+)', double, s))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
执行输出结果为:
A46G8HFD1134
正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:

正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
- 字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
- 多数字母和数字前加一个反斜杠时会拥有不同的含义。
- 标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
- 反斜杠本身需要使用反斜杠转义。
- 由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r’/t’,等价于’//t’)匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
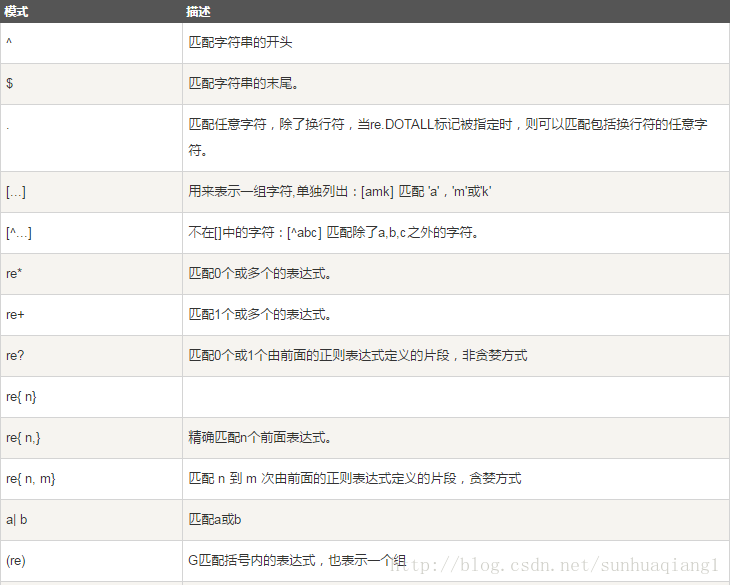
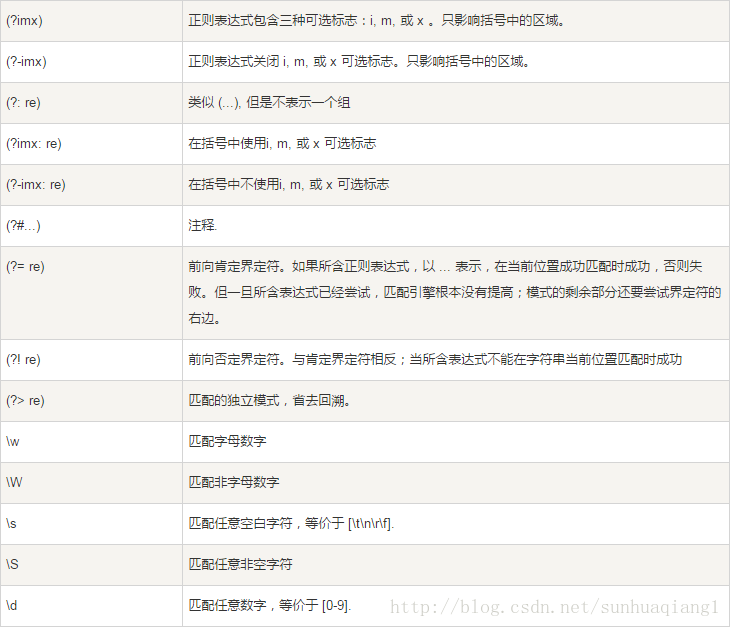
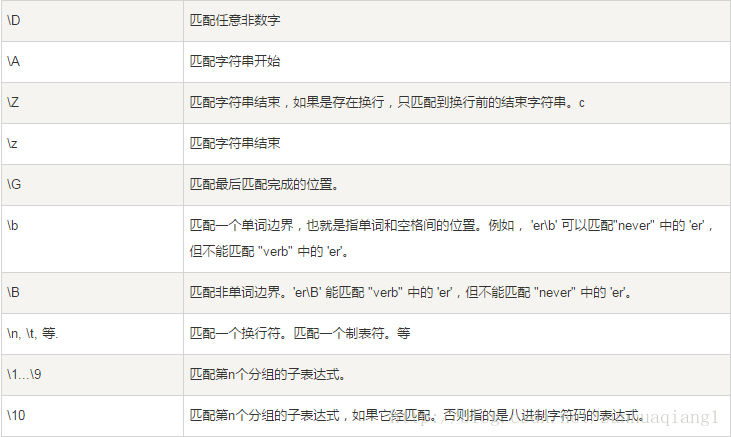
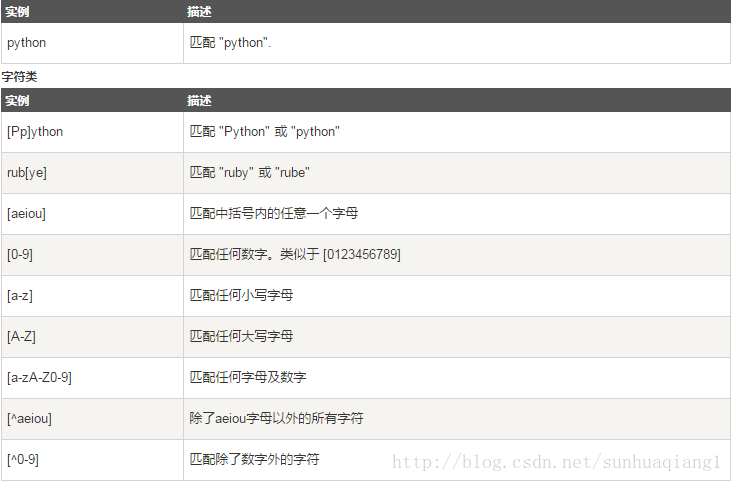
正则表达式实例
字符匹配
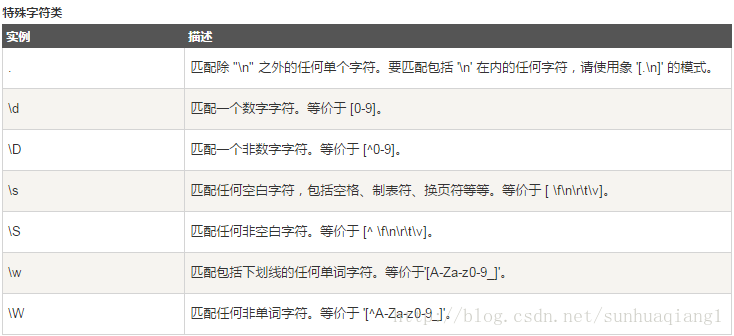
参考资料
http://www.runoob.com/python3/python3-reg-expressions.html
Python进阶(十七)-Python 字符串操作
去空格及特殊符号
s.strip().lstrip().rstrip(',')
- 1
复制字符串
- #strcpy(sStr1,sStr2)
- sStr1 = 'strcpy'
- sStr2 = sStr1
- sStr1 = 'strcpy2'
- print sStr2
- 1
- 2
- 3
- 4
- 5
连接字符串
- #strcat(sStr1,sStr2)
- sStr1 = 'strcat'
- sStr2 = 'append'
- sStr1 += sStr2
- print sStr1
- 1
- 2
- 3
- 4
- 5
查找字符
- #strchr(sStr1,sStr2)
- # < 0 为未找到
- sStr1 = 'strchr'
- sStr2 = 's'
- nPos = sStr1.index(sStr2)
- print nPos
- 1
- 2
- 3
- 4
- 5
- 6
比较字符串
- #strcmp(sStr1,sStr2)
- sStr1 = 'strchr'
- sStr2 = 'strch'
- print cmp(sStr1,sStr2)
- 1
- 2
- 3
- 4
扫描字符串是否包含指定的字符
- #strspn(sStr1,sStr2)
- sStr1 = '12345678'
- sStr2 = '456'
- #sStr1 and chars both in sStr1 and sStr2
- print len(sStr1 and sStr2)
- 1
- 2
- 3
- 4
- 5
字符串长度
- #strlen(sStr1)
- sStr1 = 'strlen'
- print len(sStr1)
- 1
- 2
- 3
将字符串中的大小写转换
- #strlwr(sStr1)
- sStr1 = 'JCstrlwr'
- sStr1 = sStr1.upper()
- #sStr1 = sStr1.lower()
- print sStr1
- 1
- 2
- 3
- 4
- 5
追加指定长度的字符串
- #strncat(sStr1,sStr2,n)
- sStr1 = '12345'
- sStr2 = 'abcdef'
- n = 3
- sStr1 += sStr2[0:n]
- print sStr1
- 1
- 2
- 3
- 4
- 5
- 6
字符串指定长度比较
- #strncmp(sStr1,sStr2,n)
- sStr1 = '12345'
- sStr2 = '123bc'
- n = 3
- print cmp(sStr1[0:n],sStr2[0:n])
- 1
- 2
- 3
- 4
- 5
复制指定长度的字符
- #strncpy(sStr1,sStr2,n)
- sStr1 = ''
- sStr2 = '12345'
- n = 3
- sStr1 = sStr2[0:n]
- print sStr1
- 1
- 2
- 3
- 4
- 5
- 6
将字符串前n个字符替换为指定的字符
- #strnset(sStr1,ch,n)
- sStr1 = '12345'
- ch = 'r'
- n = 3
- sStr1 = n * ch + sStr1[3:]
- print sStr1
- 1
- 2
- 3
- 4
- 5
- 6
扫描字符串
- #strpbrk(sStr1,sStr2)
- sStr1 = 'cekjgdklab'
- sStr2 = 'gka'
- nPos = -1
- for c in sStr1:
- if c in sStr2:
- nPos = sStr1.index(c)
- break
- print nPos
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
翻转字符串
- #strrev(sStr1)
- sStr1 = 'abcdefg'
- sStr1 = sStr1[::-1]
- print sStr1
- 1
- 2
- 3
- 4
查找字符串
- #strstr(sStr1,sStr2)
- sStr1 = 'abcdefg'
- sStr2 = 'cde'
- print sStr1.find(sStr2)
- 1
- 2
- 3
- 4
分割字符串
- #strtok(sStr1,sStr2)
- sStr1 = 'ab,cde,fgh,ijk'
- sStr2 = ','
- sStr1 = sStr1[sStr1.find(sStr2) + 1:]
- print sStr1
- #或者
- s = 'ab,cde,fgh,ijk'
- print(s.split(','))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
连接字符串
- delimiter = ','
- mylist = ['Brazil', 'Russia', 'India', 'China']
- print delimiter.join(mylist)
- 1
- 2
- 3
截取字符串
- str = ’0123456789′
- print str[0:3] #截取第一位到第三位的字符
- print str[:] #截取字符串的全部字符
- print str[6:] #截取第七个字符到结尾
- print str[:-3] #截取从头开始到倒数第三个字符之前
- print str[2] #截取第三个字符
- print str[-1] #截取倒数第一个字符
- print str[::-1] #创造一个与原字符串顺序相反的字符串
- print str[-3:-1] #截取倒数第三位与倒数第一位之前的字符
- print str[-3:] #截取倒数第三位到结尾
- print str[:-5:-3] #逆序截取,具体啥意思没搞明白?
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
python字符串跟整型互转
- print ("整型:",int(50))
- a=int(50)
- print("整型:",type(a))
- numStr = "50";
- print ("字符串:",type(numStr))
- convertedInt = int(numStr);
- print("字符串转换为整型:",convertedInt)
- convertedstr=str(a)
- print("整型转换为字符串:",convertedInt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

参考资料
http://www.runoob.com/python3/python3-string.html
Python进阶(十八)-Python3爬虫实践
这篇文章主要介绍了如何使用Python3爬取csdn博客访问量的相关资料,在Python2已实现的基础上实现Python3爬虫,对比版本之间的差异所在,需要的朋友可以参考下。
使用python来获取自己博客的访问量,也是后面将要开发项目的一部分,后边会对博客的访问量进行分析,以折线图和饼图等可视化的方式展示自己博客被访问的情况,使自己能更加清楚自己的哪些博客更受关注。其实,在较早之前博客专家本身就有这个功能,不知什么原因此功能被取消了。
一.网址分析
进入自己的博客页面,网址为:http://blog.csdn.net/sunhuaqiang1。 网址还是比较好分析的:就是csdn的网址+个人csdn登录账号,我们来看下一页的网址。
看到第二页的地址为:http://blog.csdn.net/sunhuaqiang1/article/list/2后边的数字表示现在正处于第几页,再用其他的页面验证一下,确实是这样的,那么第一页为什么不是http://blog.csdn.net/sunhuaqiang1/article/list/1呢,那么我们在浏览器中输http://blog.csdn.net/sunhuaqiang1/article/list/1试试,哎,果然是第一页啊,第一页原来是被重定向了,http://blog.csdn.net/sunhuaqiang1被重定向到http://blog.csdn.net/sunhuaqiang1/article/list/1,所以两个网址都能访问第一页,那么现在规律就非常明显了: http://blog.csdn.net/sunhuaqiang1/article/list/ +
页号
二.获取标题
右键查看网页的源代码,我们看到可以找到这样一段代码:


我们可以看到标题都是在标签
- <span class="link_title">
- <a href="/sunhuaqiang1/article/details/50651235">
- ...
- </a>
- </span>
- 1
- 2
- 3
- 4
- 5
中的。所以我们可以使用下面的正则表达式来匹配标题:
<span class="link_title"><a href=".*?">(.*?)</a></span>
- 1
三.获取访问量
拿到了标题之后,就要获得对应的访问量了,经过对源码的分析,我看到访问量的结构都是这样的:
<span class="link_view" title="阅读次数"><a href="/sunhuaqiang1/article/details/51289580" title="阅读次数">阅读</a>(12718)</span>
- 1
括号中的数字即为访问量,我们可以用下面的正则表达式来匹配:
<span class="link_view".*?><a href=".*?" title="阅读次数">阅读</a>\((.*?)\)</span>
- 1
其中,’.?’的含义是启用正则懒惰模式。必须跟在或者+后边用。
如:“< img src=”test.jpg” width=”60px” height=”80px”/>”
如果用正则匹配src中内容非懒惰模式匹配
src=".*"
- 1
匹配结果是:src=”test.jpg” width=”60px” height=”80px”
意思是从=”往后匹配,直到最后一个”匹配结束
懒惰模式正则:
src=".*?"
- 1
结果:src=”test.jpg”
因为匹配到第一个”就结束了一次匹配。不会继续向后匹配。因为他懒惰嘛。
- .表示除\n之外的任意字符
- *表示匹配0-无穷
- +表示匹配1-无穷
四.尾页判断
接下来我们要判断当前页是否为最后一页,否则我们就不能判断什么时候结束了,我找到了源码中‘尾页’的标签,发现是下面的结构:
<a href="/sunhuaqiang1/article/list/2">下一页</a> <a href="/sunhuaqiang1/article/list/7">尾页</a>
- 1
所以我们可以用下面的正则表达式来匹配,如果匹配成功就说明当前页不是最后一页,否则当前页就是最后一页。
<a href=".*?">尾页</a>
- 1
五.编程实现
下面是摘自的Python2版完整的代码实现:
- #!usr/bin/python
- # -*- coding: utf-8 -*-
- '''
- Created on 2016年2月13日
- @author: ***
- 使用python爬取csdn个人博客的访问量,主要用来练手
- '''
- import urllib2
- import re
- #当前的博客列表页号
- page_num = 1
- #不是最后列表的一页
- notLast = 1
- account = str(raw_input('输入csdn的登录账号:'))
- while notLast:
- #首页地址
- baseUrl = 'http://blog.csdn.net/'+account
- #连接页号,组成爬取的页面网址
- myUrl = baseUrl+'/article/list/'+str(page_num)
- #伪装成浏览器访问,直接访问的话csdn会拒绝
- user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
- headers = {'User-Agent':user_agent}
- #构造请求
- req = urllib2.Request(myUrl,headers=headers)
- #访问页面
- myResponse = urllib2.urlopen(req)
- myPage = myResponse.read()
- #在页面中查找是否存在‘尾页'这一个标签来判断是否为最后一页
- notLast = re.findall('<a href=".*?">尾页</a>',myPage,re.S)
- print '---------------第%d页-------------' % (page_num,)
- #利用正则表达式来获取博客的标题
- title = re.findall('<span class="link_title"><a href=".*?">(.*?)</a></span>',myPage,re.S)
- titleList=[]
- for items in title:
- titleList.append(str(items).lstrip().rstrip())
- #利用正则表达式获取博客的访问量
- view = re.findall('<span class="link_view".*?><a href=".*?" title="阅读次数">阅读</a>\((.*?)\)</span>',myPage,re.S)
- viewList=[]
- for items in view:
- viewList.append(str(items).lstrip().rstrip())
- #将结果输出
- for n in range(len(titleList)):
- print '访问量:%s 标题:%s' % (viewList[n].zfill(4),titleList[n])
- #页号加1
- page_num = page_num + 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
由于自己现在的IDE为Python3,且自己在学习Python3。故在此基础上实现Python2项目的升级改造,并在改造过程中发现版本之间的差异性。以下为Python3版本下的爬虫代码。
- #!usr/bin/python
- # -*- coding: utf-8 -*-
- '''
- Created on 2017年3月19日
- @author: SUN HuaQiang
- 目的:使用python爬取csdn个人博客的访问量,主要用来练手Python爬虫
- 收获:1.了解Python爬虫的基本过程
- 2.在Python2的基础上实现Python3,通过对比发现版本之间的差异
- '''
- import urllib.request
- import urllib
- import re
-
- #当前的博客列表页号
- page_num = 1
- #初始化最后列表的页码
- notLast = 1
- account = str(input('请输入csdn的登录账号:'))
- while notLast:
- #首页地址
- baseUrl = 'http://blog.csdn.net/' + account
- #连接页号,组成爬取的页面网址
- myUrl = baseUrl+'/article/list/' + str(page_num)
- #伪装成浏览器访问,直接访问的话csdn会拒绝
- user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
- headers = {'User-Agent':user_agent}
- #构造请求
- req = urllib.request.Request(myUrl,headers=headers)
- #访问页面
- myResponse = urllib.request.urlopen(req)
- #python3中urllib.read返回的是bytes对象,不是string,得把它转换成string对象,用bytes.decode方法
- myPage = myResponse.read().decode()
- #在页面中查找是否存在‘尾页'这一个标签来判断是否为最后一页
- notLast = re.findall('<a href=".*?">尾页</a>', myPage, re.S)
- print ('-----------第%d页--------------' % (page_num,))
- #利用正则表达式来获取博客的标题
- title = re.findall('<span class="link_title"><a href=".*?">(.*?)</a></span>',myPage,re.S)
- titleList=[]
- for items in title:
- titleList.append(str(items).lstrip().rstrip())
- #利用正则表达式获取博客的访问量
- view = re.findall('<span class="link_view".*?><a href=".*?" title="阅读次数">阅读</a>\((.*?)\)</span>',myPage,re.S)
- viewList=[]
- for items in view:
- viewList.append(str(items).lstrip().rstrip())
- #将结果输出
- for n in range(len(titleList)):
- print ('访问量:%s 标题:%s' % (viewList[n].zfill(4),titleList[n]))
- #页号加1
- page_num = page_num + 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
下面是部分结果:
瑕疵:通过爬虫结果可以发现,在CSDN中,对于设置为指定的文章,爬取结果存在一定的问题,还包含部分css代码。
改善:通过更改获取博文标题的正则表达式,即可解决此问题。

想法是好的,但是直接利用正则实现标题获取时遇到了困难,暂时并未实现理想结果。
遂改变思路,将利用正则获取后的字符串再进行二次正则,即替换操作,语句如下:
- for items in title:
- titleList.append(re.sub('<font color="red">.*?</font>', '', str(items).lstrip().rstrip()))
- 1
- 2
更改后的结果如下。并同时为每篇博文进行了编号。
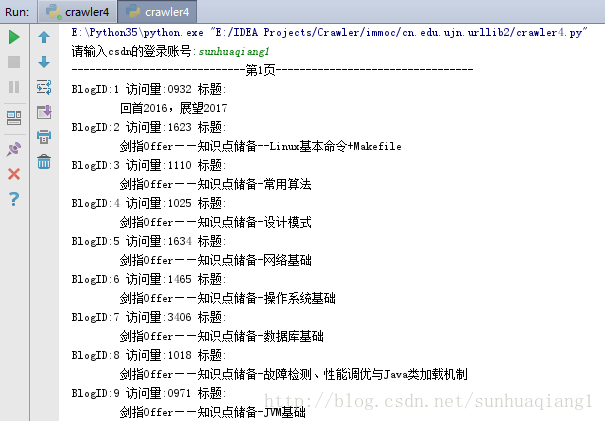
同时,自己还希望获取到的信息包括:访问总量、积分、等级、排名、粉丝、原创、转载、译文、评论等数据信息。
以上信息在网页源码中如下所示。
- <ul id="blog_rank">
- <li>访问:<span>459285次</span></li>
- <li>积分:<span>9214</span> </li>
- <li >等级: <span style="position:relative;display:inline-block;z-index:1" >
- <img src="http://c.csdnimg.cn/jifen/images/xunzhang/jianzhang/blog6.png" alt="" style="vertical-align: middle;" id="leveImg">
- <div id="smallTittle" style=" position: absolute; left: -24px; top: 25px; text-align: center; width: 101px; height: 32px; background-color: #fff; line-height: 32px; border: 2px #DDDDDD solid; box-shadow: 0px 2px 2px rgba (0,0,0,0.1); display: none; z-index: 999;">
- <div style="left: 42%; top: -8px; position: absolute; width: 0; height: 0; border-left: 10px solid transparent; border-right: 10px solid transparent; border-bottom: 8px solid #EAEAEA;"></div>
- 积分:9214 </div>
- </span> </li>
- <li>排名:<span>第1639名</span></li>
- </ul>
- <ul id="blog_statistics">
- <li>原创:<span>425篇</span></li>
- <li>转载:<span>44篇</span></li>
- <li>译文:<span>2篇</span></li>
- <li>评论:<span>108条</span></li>
- </ul>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
则获取访问信息的正则表达式为:
- #利用正则表达式获取博客信息
- sumVisit = re.findall('<li>访问:<span>(.*?)</span></li>', myPage, re.S)
- credit = re.findall('<li>积分:<span>(.*?)</span> </li>', myPage, re.S)
- rank = re.findall('<li>排名:<span>(.*?)</span></li>', myPage, re.S)
- grade = re.findall('<li >.*?<img src=.*?/blog(.*?).png.*?>.*?</li>', test3, re.S)
- original = re.findall('<li>原创:<span>(.*?)</span></li>', myPage, re.S)
- reprint = re.findall('<li>转载:<span>(.*?)</span></li>', myPage, re.S)
- trans = re.findall('<li>译文:<span>(.*?)</span></li>', myPage, re.S)
- comment = re.findall('<li>评论:<span>(.*?)</span></li>', myPage, re.S)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
根据网页源码,可得出其正则表达式为

- staData = re.findall('<li><a href=.*?>(.*?)</a><span>(.*?)</span></li>', myPage, re.S)
-
- for i in staData:
- print(i[0] + ':' + i[1].lstrip('(').rstrip(')')+'篇')
- 1
- 2
- 3
- 4
经过以上操作,得到的用户Blog信息如下图所示:
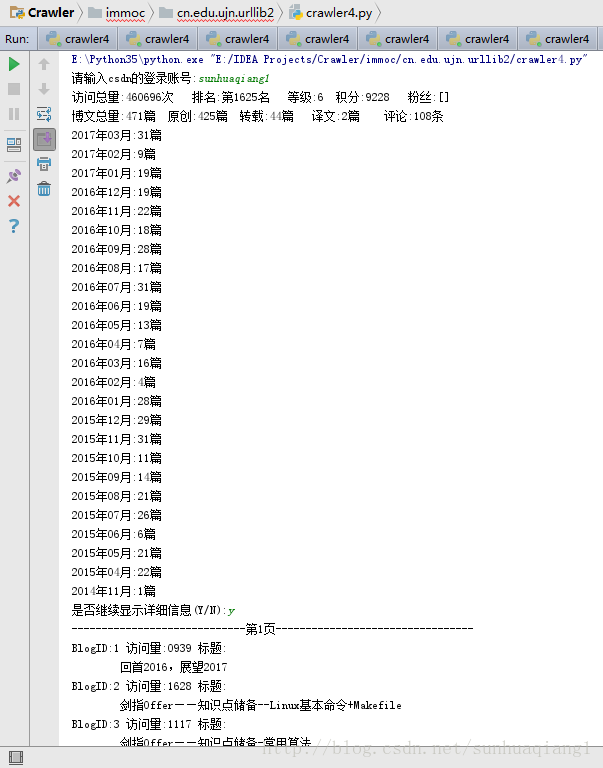
最终遇到的问题是:有关粉丝数的爬取遇到了问题,因为前面数据信息的获取不需要用户登录,而用户粉丝数是在用户已登录情景下获取的,故需要将用户登录信息添加进去。犯愁~
PS:论文盲审送回来了,自己这段时间要用来修改论文了,后面的博客后面再说吧~
注意事项
- urllib2在3.5中为urllib.request;
- raw_input()在3.5中为input();
- python3中urllib.read()返回的是bytes对象,不是string,得把它转换成string对象,用bytes.decode()方法;
- re.S意在使.匹配包括换行在内的所有字符;
- python3对urllib和urllib2进行了重构,拆分成了urllib.request, urllib.response,urllib.parse,urllib.error等几个子模块,这样的架构从逻辑和结构上说更加合理。urljoin现在对应的函数是urllib.parse.urljoin
注:Python2部分的爬虫代码为网络获取,在此向匿名人士表示感谢。
Python进阶(十九)-Python3安装第三方爬虫库BeautifulSoup4
在做Python3爬虫练习时,从网上找到了一段代码如下:
- #使用第三方库BeautifulSoup,用于从html或xml中提取数据
- from bs4 import BeautifulSoup
- 1
- 2
自己实践后,发现出现了错误,如下所示:
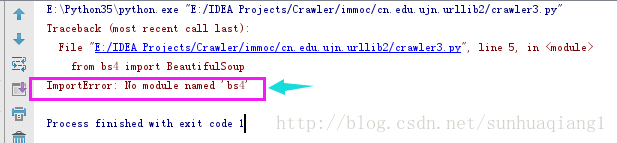
以上错误提示是说没有发现名为“bs4”的模块。即“bs4”模块未安装。
进入Python安装目录,以作者IDE为例,
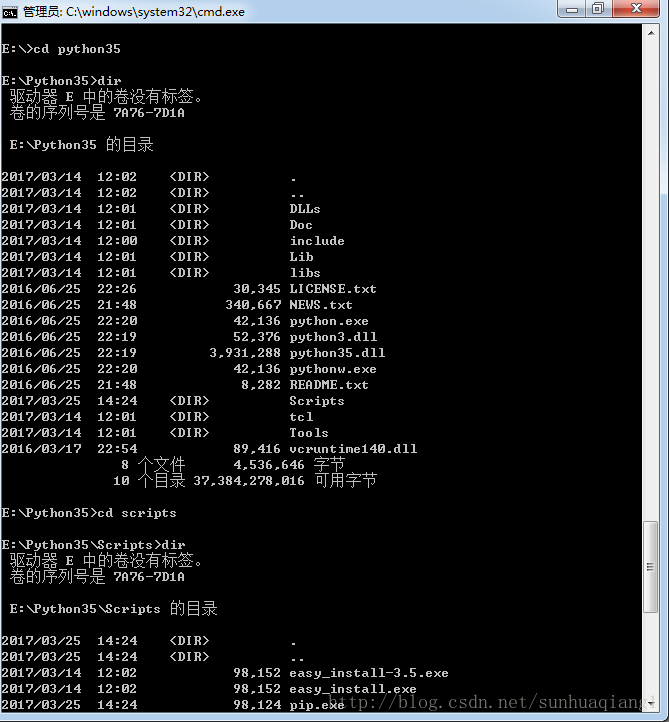
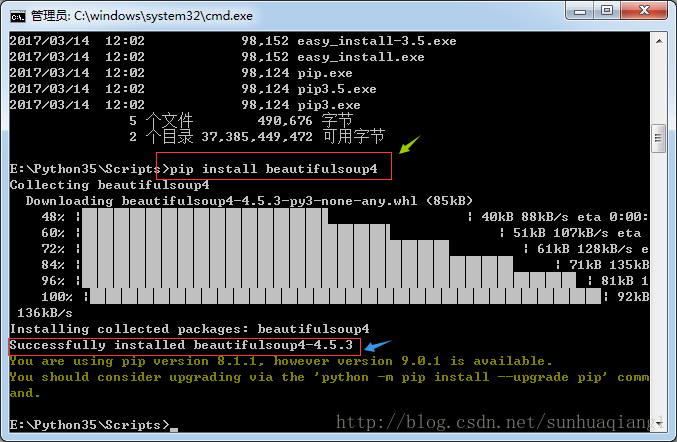
控制台提示第三方库BeautifulSoup4安装成功!回到之前的程序中,会发现IntelJ已经检测到第三方库BS4的安装,已自更新项目,此时项目恢复正常,无错误提示。
常见问题
在做BS4爬虫练习时,新建的文件名为bs4.py,结果出现如下错误提示:
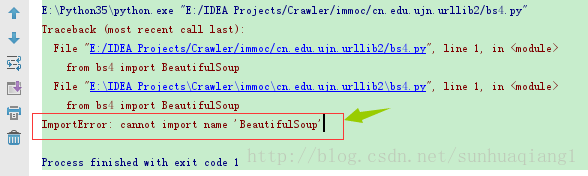
即ImportError: cannot import name BeautifulSoup一般有一下几种情况:
1. 在python2.x下安装的BeautifulSoup在python3.x下运行会报这种错,可用pip3 install Beautifulsoup4 .
2. 导入时指定bs4 像这样: from bs4 import BeautifulSoup.
3. 太巧合,如果你测试的文件名正好命名为bs4.py,那怎么整都会报这个错,把名字改成其他的吧。
附
Python进阶(二十)-Python爬虫实例讲解
本篇博文主要讲解Python爬虫实例,重点包括爬虫技术架构,组成爬虫的关键模块:URL管理器、HTML下载器和HTML解析器。
爬虫简单架构
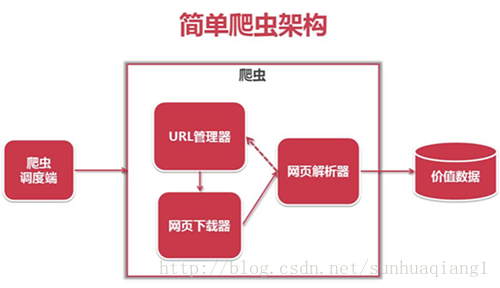
程序入口函数(爬虫调度段)
- #coding:utf8
- import time, datetime
-
- from maya_Spider import url_manager, html_downloader, html_parser, html_outputer
-
-
- class Spider_Main(object):
- #初始化操作
- def __init__(self):
- #设置url管理器
- self.urls = url_manager.UrlManager()
- #设置HTML下载器
- self.downloader = html_downloader.HtmlDownloader()
- #设置HTML解析器
- self.parser = html_parser.HtmlParser()
- #设置HTML输出器
- self.outputer = html_outputer.HtmlOutputer()
-
- #爬虫调度程序
- def craw(self, root_url):
- count = 1
- self.urls.add_new_url(root_url)
- while self.urls.has_new_url():
- try:
- new_url = self.urls.get_new_url()
- print('craw %d : %s' % (count, new_url))
- html_content = self.downloader.download(new_url)
- new_urls, new_data = self.parser.parse(new_url, html_content)
- self.urls.add_new_urls(new_urls)
- self.outputer.collect_data(new_data)
-
- if count == 10:
- break
-
- count = count + 1
- except:
- print('craw failed')
-
- self.outputer.output_html()
-
- if __name__ == '__main__':
- #设置爬虫入口
- root_url = 'http://baike.baidu.com/view/21087.htm'
- #开始时间
- print('开始计时..............')
- start_time = datetime.datetime.now()
- obj_spider = Spider_Main()
- obj_spider.craw(root_url)
- #结束时间
- end_time = datetime.datetime.now()
- print('总用时:%ds'% (end_time - start_time).seconds)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
URL管理器
- class UrlManager(object):
- def __init__(self):
- self.new_urls = set()
- self.old_urls = set()
-
- def add_new_url(self, url):
- if url is None:
- return
- if url not in self.new_urls and url not in self.old_urls:
- self.new_urls.add(url)
-
- def add_new_urls(self, urls):
- if urls is None or len(urls) == 0:
- return
- for url in urls:
- self.add_new_url(url)
-
- def has_new_url(self):
- return len(self.new_urls) != 0
-
- def get_new_url(self):
- new_url = self.new_urls.pop()
- self.old_urls.add(new_url)
- return new_url
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
网页下载器
- import urllib
- import urllib.request
-
- class HtmlDownloader(object):
-
- def download(self, url):
- if url is None:
- return None
-
- #伪装成浏览器访问,直接访问的话csdn会拒绝
- user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
- headers = {'User-Agent':user_agent}
- #构造请求
- req = urllib.request.Request(url,headers=headers)
- #访问页面
- response = urllib.request.urlopen(req)
- #python3中urllib.read返回的是bytes对象,不是string,得把它转换成string对象,用bytes.decode方法
- return response.read().decode()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
网页解析器
- import re
- import urllib
- from urllib.parse import urlparse
-
- from bs4 import BeautifulSoup
-
- class HtmlParser(object):
-
- def _get_new_urls(self, page_url, soup):
- new_urls = set()
- #/view/123.htm
- links = soup.find_all('a', href=re.compile(r'/item/.*?'))
- for link in links:
- new_url = link['href']
- new_full_url = urllib.parse.urljoin(page_url, new_url)
- new_urls.add(new_full_url)
- return new_urls
-
- #获取标题、摘要
- def _get_new_data(self, page_url, soup):
- #新建字典
- res_data = {}
- #url
- res_data['url'] = page_url
- #<dd class="lemmaWgt-lemmaTitle-title"><h1>Python</h1>获得标题标签
- title_node = soup.find('dd', class_="lemmaWgt-lemmaTitle-title").find('h1')
- print(str(title_node.get_text()))
- res_data['title'] = str(title_node.get_text())
- #<div class="lemma-summary" label-module="lemmaSummary">
- summary_node = soup.find('div', class_="lemma-summary")
- res_data['summary'] = summary_node.get_text()
-
- return res_data
-
- def parse(self, page_url, html_content):
- if page_url is None or html_content is None:
- return None
-
- soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')
- new_urls = self._get_new_urls(page_url, soup)
- new_data = self._get_new_data(page_url, soup)
- return new_urls, new_data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
网页输出器
- class HtmlOutputer(object):
-
- def __init__(self):
- self.datas = []
-
- def collect_data(self, data):
- if data is None:
- return
- self.datas.append(data )
-
- def output_html(self):
- fout = open('maya.html', 'w', encoding='utf-8')
- fout.write("<head><meta http-equiv='content-type' content='text/html;charset=utf-8'></head>")
- fout.write('<html>')
- fout.write('<body>')
- fout.write('<table border="1">')
- # <th width="5%">Url</th>
- fout.write('''<tr style="color:red" width="90%">
- <th>Theme</th>
- <th width="80%">Content</th>
- </tr>''')
- for data in self.datas:
- fout.write('<tr>\n')
- # fout.write('\t<td>%s</td>' % data['url'])
- fout.write('\t<td align="center"><a href=\'%s\'>%s</td>' % (data['url'], data['title']))
- fout.write('\t<td>%s</td>\n' % data['summary'])
- fout.write('</tr>\n')
- fout.write('</table>')
- fout.write('</body>')
- fout.write('</html>')
- fout.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
运行结果
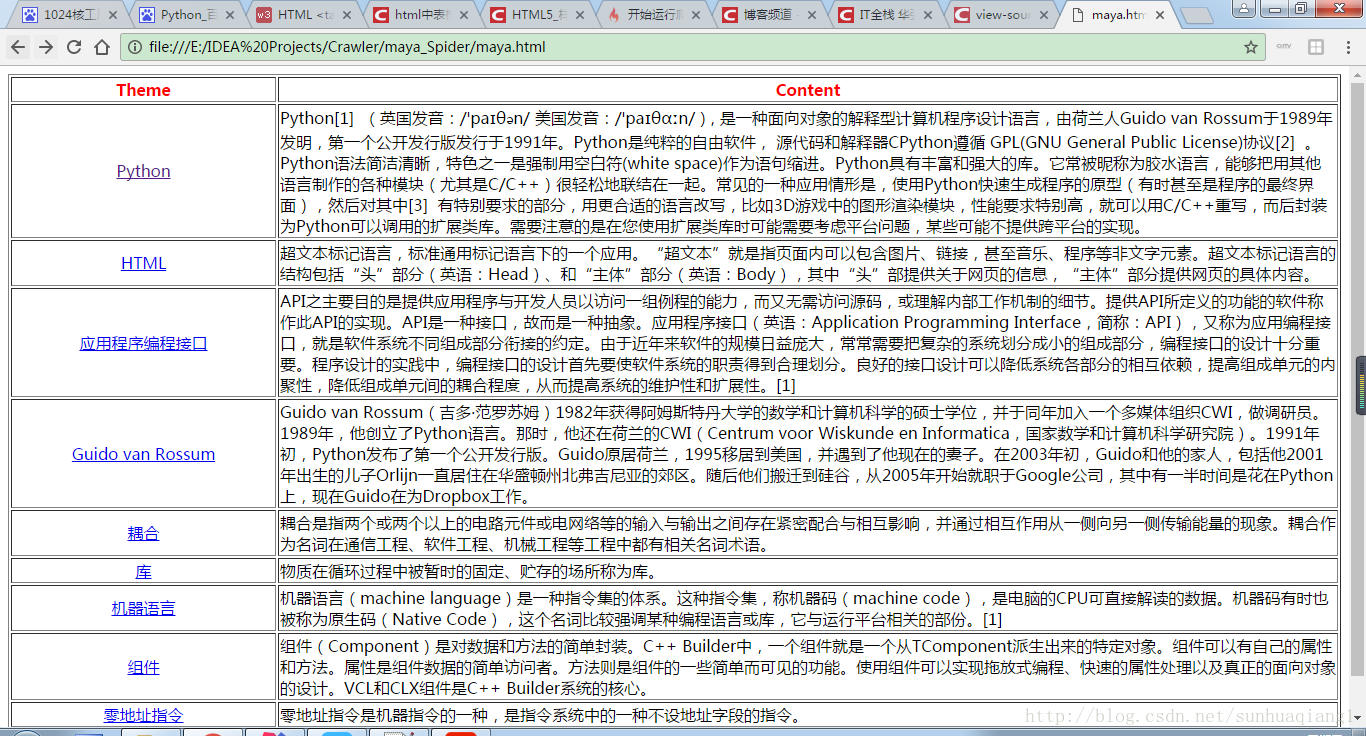
附
Python进阶(二十二)-Python3使用PyMysql连接mysql数据库
python语言的3.x完全不向前兼容,导致我们在python2.x中可以正常使用的库,到了python3就用不了.比如说mysqldb。
目前MySQLdb并不支持python3.x,Python3.x连接MySQL的方案有:oursql, PyMySQL, myconnpy 等
下面来说下python3如何安装和使用pymysql,另外两个方案我会在以后再讲。
1.pymysql安装
pymysql就是作为python3环境下mysqldb的替代物,进入命令行,使用pip安装pymysql。
pip install pymysql3
- 1
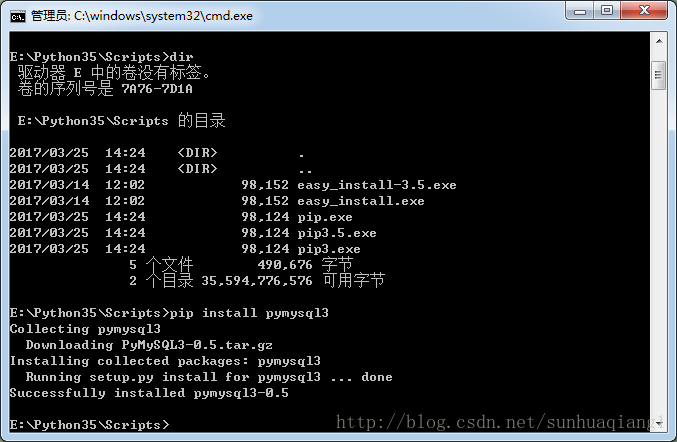
2.pymysql使用
如果想使用mysqldb的方式,那么直接在py文件的开头加入如下两行代码即可。
- #引入pymysql
- import pymysql
- #当成是mysqldb一样使用,当然也可以不写这句,那就按照pymysql的方式
- pymysql.install_as_MySQLdb()
- 1
- 2
- 3
- 4
3.安装测试示例
- import pymysql
-
- print(pymysql)
- 1
- 2
- 3
会看到控制台输出以下信息:

说明pymysql安装成功,可正常使用。
4.pymysql操作示例
- #导入pymysql的包
- import pymysql
-
- # print(pymysql)
-
- try:
- #获取一个数据库连接,注意如果是UTF-8类型的,需要制定数据库
- conn = pymysql.connect(host='localhost', port=3308, user='lmapp', passwd='lmapp', db='test', charset='utf8')
- cur = conn.cursor()#获取一个游标
-
- sql_query = "select * from user"
- sql_insert = "insert into user(uid, uname, passwd) VALUES ('18853883587', 'SHQ', 'TEST')"
- sql_update = "update user set uname='ZQY' WHERE uid='18353102061'"
- sql_delete = "delete from user WHERE uid='18353102062'"
-
- cur.execute(sql_query)
- data = cur.fetchall()
- cur.execute(sql_insert)
- print(cur.rowcount)
- cur.execute(sql_update)
- print(cur.rowcount)
- cur.execute(sql_delete)
- print(cur.rowcount)
- for d in data :
- #注意int类型需要使用str函数转义
- print(type(d[0]))
- print("UID: "+d[0]+' 用户名: '+d[1]+" 密码: "+d[2])
- #提交事务
- conn.commit()
- cur.close()#关闭游标
- conn.close()#释放数据库资源
- except Exception :
- #异常情况下,进行事务回滚
- conn.rollback()
- print("操作失败")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
5.pymysql操作示例-银行转帐
- #coding:utf8
-
- import pymysql
-
-
- class TranferMoney(object):
- def __init__(self, conn):
- self.conn = conn
-
- #检查账户有效性
- def check_acct_available(self, source_acctid):
- try:
- cursor = self.conn.cursor()
- sql_query = "select * from account where acctid='%s'"%source_acctid
- cursor.execute(sql_query)
- print('check_acct_available:', sql_query)
- rs = cursor.fetchall()
- if len(rs) != 1:
- raise Exception('帐号%s不存在'%source_acctid)
- finally:
- cursor.close()
-
- #检查账户金额
- def has_enough_money(self, source_acctid, money):
- try:
- print(type(money))
- cursor = self.conn.cursor()
- sql_query = "select * from account where acctid=%s and money >= %d"%(source_acctid, money)
- cursor.execute(sql_query)
- print('has_enough_money:', sql_query)
- rs = cursor.fetchall()
- if len(rs) != 1:
- raise Exception('帐号%s余额不足'%source_acctid)
- finally:
- cursor.close()
-
- #账户减款
- def reduce_money(self, source_acctid, money):
- try:
- cursor = self.conn.cursor()
- sql_query = "update account set money=money-%d where acctid = '%s'"%(money, source_acctid)
- cursor.execute(sql_query)
- print('reduce_money:', sql_query)
- if cursor.rowcount != 1:
- raise Exception('帐号%s减款错误'%source_acctid)
- finally:
- cursor.close()
-
- #账户加款
- def add_money(self, source_acctid, money):
- try:
- cursor = self.conn.cursor()
- sql_query = "update account set money=money+%d where acctid = '%s'"%(money, source_acctid)
- cursor.execute(sql_query)
- print('reduce_money:', sql_query)
- if cursor.rowcount != 1:
- raise Exception('帐号%s加款错误'%source_acctid)
- finally:
- cursor.close()
-
- def transfer(self, source_acctid, target_accid, money):
- try:
- self.check_acct_available(source_acctid)
- self.check_acct_available(target_accid)
- self.has_enough_money(source_acctid, money)
- self.reduce_money(source_acctid, money)
- self.add_money(target_accid, money)
- self.conn.commit()
- except Exception as e:
- print("Exception:", e)
- self.conn.rollback()
- raise e
-
- if __name__ == '__main__':
- source_acctid = input("请输入转账方帐号:")
- target_accid = input("请输入收款方帐号:")
- money = input("请输入转款金额:")
- conn = pymysql.connect(host='localhost', port=3308, user='lmapp', passwd='lmapp', db='test', charset='utf8')
- tranfer_money = TranferMoney(conn)
- try:
- tranfer_money.transfer(source_acctid, target_accid, int(money))
- print("转账成功")
- except Exception as e:
- print('Error:', e)
- finally:
- conn.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
数据库插入操作
以下实例使用执行 SQL INSERT 语句向表 EMPLOYEE 插入记录:
- #!/usr/bin/python
- # -*- coding: UTF-8 -*-
-
- import MySQLdb
-
- # 打开数据库连接
- db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
-
- # 使用cursor()方法获取操作游标
- cursor = db.cursor()
-
- # SQL 插入语句
- sql = """INSERT INTO EMPLOYEE(FIRST_NAME,
- LAST_NAME, AGE, SEX, INCOME)
- VALUES ('Mac', 'Mohan', 20, 'M', 2000)"""
- try:
- # 执行sql语句
- cursor.execute(sql)
- # 提交到数据库执行
- db.commit()
- except:
- # Rollback in case there is any error
- db.rollback()
-
- # 关闭数据库连接
- db.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
附 PEP 249 – Python Database API Specification v2.0文档
connect参数
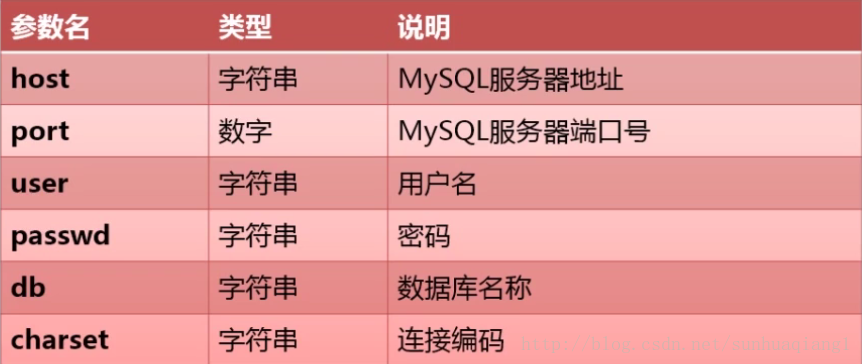
connect方法

cursor方法

fetch*方法介绍

DQL
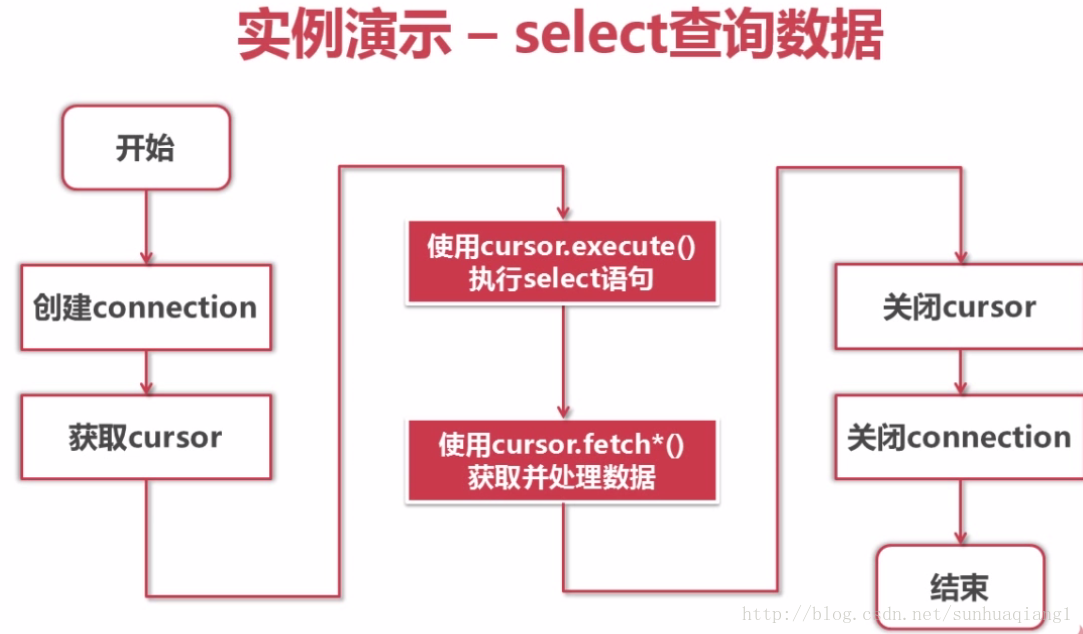
DML
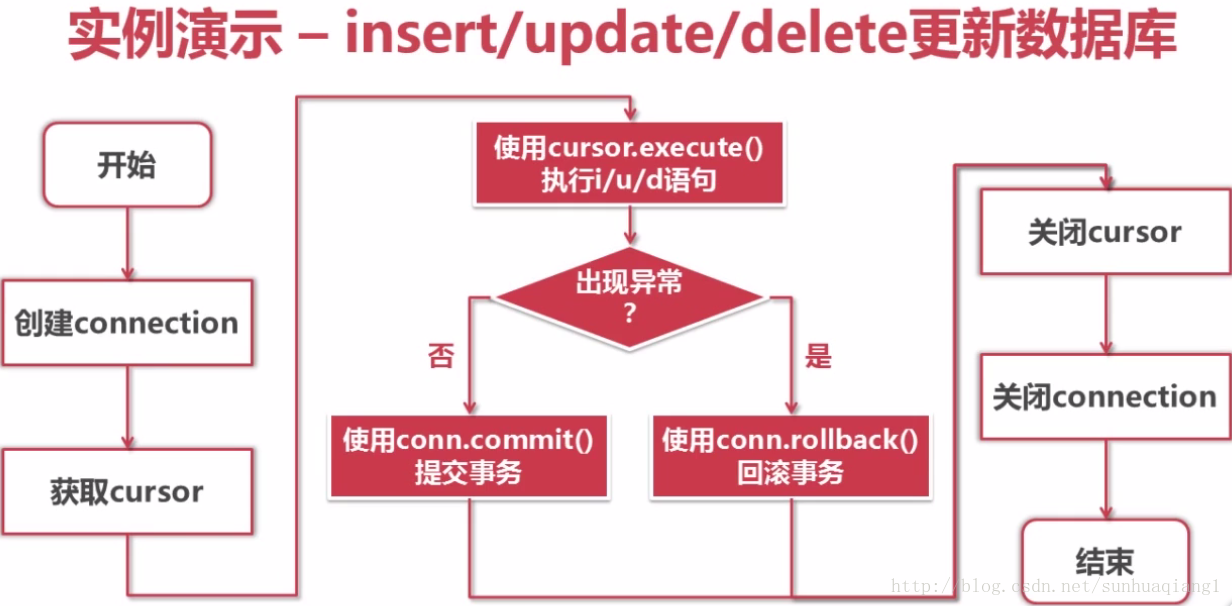
事务特性

Python进阶(二十三)-Django使用pymysql连接MySQL数据库做增删改查
IDE说明
Python:3.5
Django:1.10
Pymysql:0.7.10
Mysql:5.5
注:Django1.10默认使用的是mysqlDB模块来操作数据库,而该模块已不支持Python3,所以需要其他的方式连接数据库。
本文选择使用pymysql连接组件。
前言
在学习完Python基础之后,继续学习Python Web开发方面的知识。首先决定学习Django Web开发框架。在连接数据库一块,视频教学中使用的是django内置的sqlite数据库,之前自己使用的是mysql数据库,遂决定继续使用mysql数据库。
mysql连接配置
查看了使用mysql的settings.py项目配置文件信息,如下:
- 'default': {
- 'ENGINE': 'django.db.backends.mysql',
- 'NAME': 'mydatabaseName',
- 'USER': 'mydatabaseuser',
- 'PASSWORD': 'mypassword',
- 'HOST': '127.0.0.1',
- 'PORT': '3306',
- }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
具体含义就不再解释了,一看就懂。配置好之后,在命令行项目目录下输入服务端运行命令:
python manage.py runserver
- 1
却出现了错误提示,信息如下:
Django.core.exceptions. ImproperlyConfigured:Error loading MySqldb module:no module named ‘MySQLdb’.
看来,Django1.10默认使用的是mysqldb连接组件。但是,在python3.x中已经不支持那个组件了,取而代之的则是pymysql连接组件。遂决定使用pymysql连接组件。
采用上述配置方式的话默认会调用mysqlDB模块,由于Python3已经不支持该模块,所以需要修改该配置文件所在目录下的init.py文件
- import pymysql
- pymysql.install_as_MySQLdb()
- 1
- 2
再次执行方式一的数据库同步命令即可。但是却出现了如下错误提示:
ImportError:cannot import name “Thing2Literal”
之所以出现以上错误,是因为MySQLdb里面有一个Thing2Literal方法,在pymysql里没有,所以导致报错。还有可能就是由于pymysql的版本低,存在这个问题,建议下载最新版本的pymysql,于是我重新下载pymysql,版本是最新的0.7.10(pip install pymysql),然后进行如下操作:
1.将settings里面的DATABASES改成MySQL相关
- DATABASES = {
- # 'default': {
- # 'ENGINE': 'django.db.backends.sqlite3',
- # 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
- # },
- 'default': {
- 'ENGINE': 'django.db.backends.mysql',
- 'OPTIONS':{'read_default_file': os.path.join(BASE_DIR, 'database.cnf'),}
- #数据库名
- # 'NAME' : 'csdn',
- # 'USER' : 'lmapp',
- # 'PASSWORD' : 'lmapp',
- # 'HOST' : '127.0.0.1',
- # 'PORT' : '8088',
- }
- }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2.在settings的上一级目录中添加my.cnf 文件,内容如下:
- [client]
- database = 'csdn'
- user = 'lmapp'
- password = 'lmapp'
- default-character-set = utf8
- host = '127.0.0.1'
- port = 8088
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在项目manage.py同级目录下输入命令
- python manage.py makemigrations
- python manage.py migrate
- 1
- 2
至此,数据表关联成功,后面进行校验操作。
设想:Django是否可以读取已存在的数据库信息?必须得首先通过Django建立数据表吗?答案是NO,不过可以采用将Django生成的数据表保存于已存在数据库中,然后将原来的数据表明更改为“项目名称_数据表名”的形式,从而使用原有的数据表信息。
更新后的数据表信息如下:

创建超级管理员
- python manage.py createsuperuser
-
- # 按照提示输入用户名和对应的密码就好了邮箱可以留空,用户名和密码必填
-
- # 修改 用户密码可以用:
- python manage.py changepassword username
- 1
- 2
- 3
- 4
- 5
- 6
业务逻辑层设计
接下来实现前端显示数据表信息。
业务逻辑层信息如下:
- #业务逻辑层
- from django.http import HttpResponse
- from django.shortcuts import render, render_to_response
-
- #注:每个响应对应一个函数,函数必须返回一个响应
- from blog import models
-
- def blogs(request):
- # return HttpResponse("Hello world ! ")
- # article = models.Blog.objects.get(pk='41078855')
- # return render(request, 'blog/index.html', {"article": articles})
- #获取全部博客信息
- articles = models.Blog.objects.all()
- #返回至前端渲染
- return render_to_response("blog/index.html",locals()) #必须用这个return
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
前端显示
客户端前端显示页面信息如下:
- index.html
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>CSDN</title>
- </head>
- <body>
- <!--<h1>{{ article.title }}</h1>-->
- <!--<h3>{{ article.viewcnt }}</h3>-->
- <body>
- <p>博文信息</p>
- {% for article in articles %}
- <p>{{article.title}}   :   {{article.viewcnt}}</p>
- <br>
- {% endfor %}
- </body>
- </body>
- </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
显示效果如下所示(有点丑):
管理端设计
Django另外一个神奇的功能就是自带Admin管理端。而且做的还挺精致。登录Django管理界面之前,需要首先创建超管员,在DOS窗口输入命令
python manage.py createsuperuser
- 1
然后就是设置密码、邮箱等注册信息。创建好超管员身份之后,可在相应的auth_user数据表中查看信息。
其默认使用的英文,若更改为中文,只需修改settings.py在的语言设置,如下:
LANGUAGE_CODE = 'zh-Hans'
- 1
若要在管理端实现数据表信息的管理,只需要在admin.py中添加如下代码即可实现。真可谓言简意赅啊。
- from django.contrib import admin
-
- # Register your models here.
- from blog.models import User,Blog
-
- admin.site.register(User)
- admin.site.register(Blog)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
登录管理端之后即可看到数据表中的信息。
列表项设置
其中,Blogs与Users分别对应数据库中的blog_blog与blog_user数据表。点击其中一个项目,例如点击Blogs,显示如下页面:
这就有问题了,可以看到在管理段博客列表中显示的博客列表名称均为“Blog Object”即所获取到的Blog对象。可否实现博客名称显示呢?答案是肯定的。修改一下blog中的models.py。
- # coding:utf-8
- from django.db import models
-
- # Create your models here.
- class User(models.Model):
- uid = models.CharField(primary_key=True, max_length=30)
- homeurl = models.CharField(max_length=45)
- sumvisit = models.IntegerField()
- credit = models.IntegerField()
- grade = models.IntegerField()
- rank = models.IntegerField()
- fans = models.IntegerField()
- original = models.IntegerField()
- reprint = models.IntegerField()
- trans = models.IntegerField()
- comment = models.IntegerField()
- blogcnt = models.IntegerField()
- # 在Python2中用__unicode__代替__str__
- def __str__(self):
- return self.uid
-
- class Blog(models.Model):
- uid = models.CharField(max_length=30)
- title = models.CharField(max_length=200)
- url = models.CharField(primary_key=True, max_length=30, null=False)
- viewcnt = models.IntegerField()
-
- # 在Python2中用__unicode__代替__str__
- def __str__(self):
- return self.title
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
添加的重点就是在定义每一个类时同时定义一个python内置的序列化函数str,这样就可以实现列表项目的显示定制功能了。
点击每一个列表项可进入博文编辑页面。
单页显示条数设置
在博客列表中,发现单页显示条目为100,未免有点多,可否实现单页显示条数定制化操作呢。在admin.py中输入以下代码即可。
- #设置每页显示条目数
- list_per_page = 30
- 1
- 2
另外,可实现在列表显示与字段相关的其它内容。例如在博客列表中,可附加显示每篇博文的访问量等信息。
具体的操作方法是在admin.py中修改代码如下:
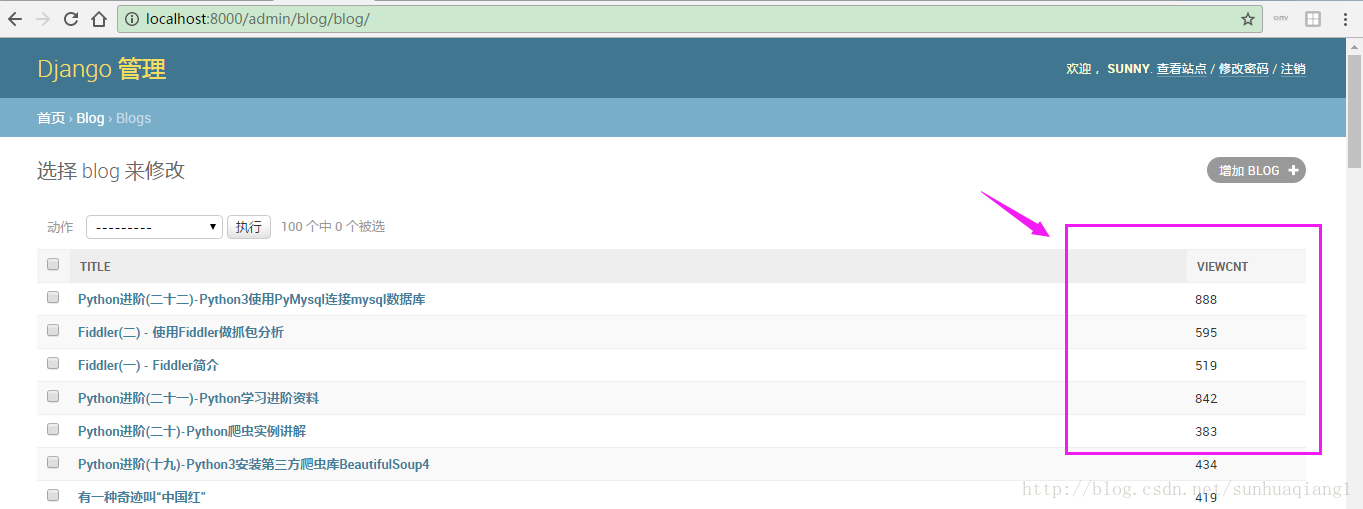
- from django.contrib import admin
-
- # Register your models here.
- from blog.models import User,Blog
- class ArticleAdmin(admin.ModelAdmin):
- list_display = ('title', 'viewcnt',)
- admin.site.register(Blog,ArticleAdmin)
- admin.site.register(User)
- # admin.site.register(Blog)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
其中,list_display 就是来配置要显示的字段的,当然也可以显示非字段内容,或者字段相关的内容,list_display中的参数就是待显示的数据属性。
搜索功能
在博客列表页面需要实现搜索功能,同样需要修改admin.py文件。
- from django.contrib import admin
-
- # Register your models here.
- from blog.models import User,Blog
-
- class ArticleAdmin(admin.ModelAdmin):
- list_display = ('title', 'viewcnt',)
- search_fields = ('title',)
-
- #queryset 是默认的结果,search_term 是在后台搜索的关键词
- def get_search_results(self, request, queryset, search_term):
- queryset, use_distinct = super(ArticleAdmin, self).get_search_results(request, queryset, search_term)
- try:
- search_term_as_int = int(search_term)
- queryset |= self.model.objects.filter(age=search_term_as_int)
- except:
- pass
- return queryset, use_distinct
-
- admin.site.register(Blog,ArticleAdmin)
- admin.site.register(User)
- # admin.site.register(Blog)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
实现效果如下:
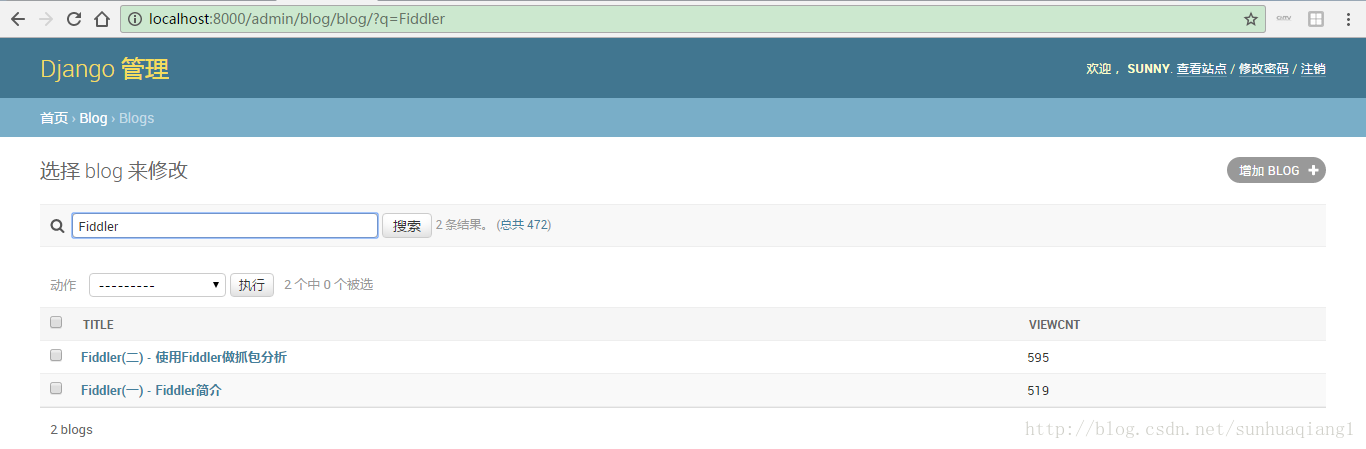
数据属性名称设置
在查看博主信息时,看到博主属性名称均为英文,可否实现别名替换?
原来在建立数据类时通过verbose_name属性即可设置别名,models.py中代码如下:
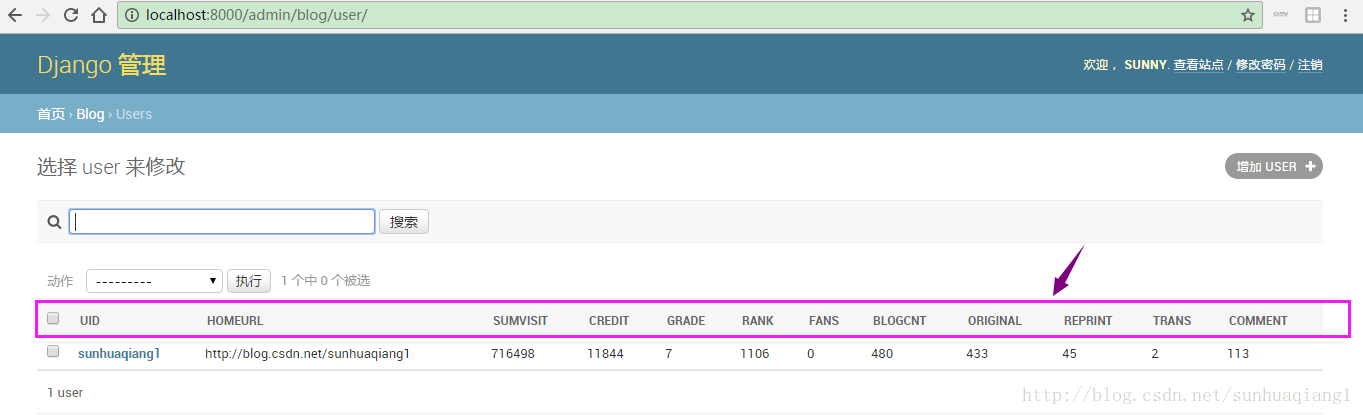
fans = models.IntegerField(verbose_name="粉丝")
- 1
替换后的博主信息页面如下:
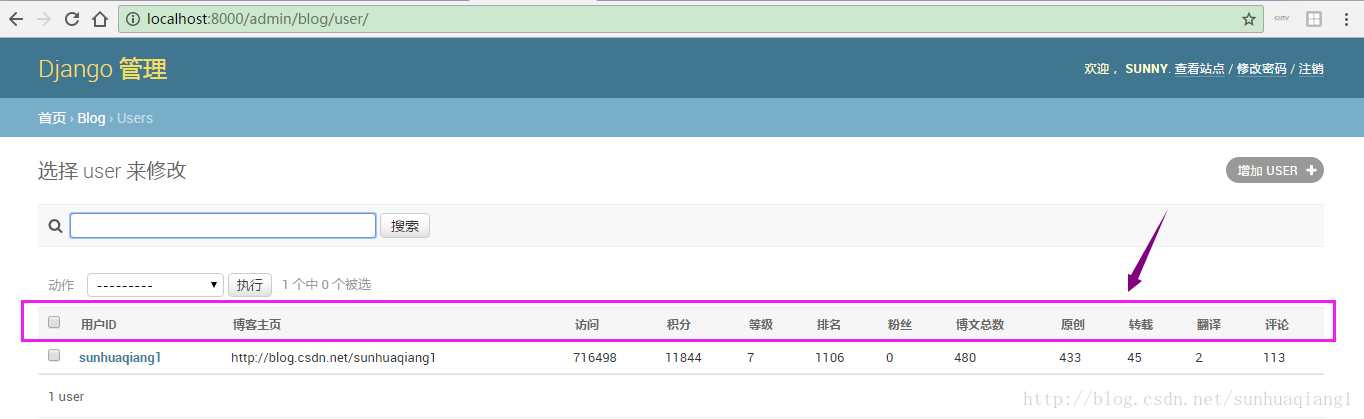
数据类别名设置
同时,可取数据类的别名。例如,将“User”取别名为“博主”。同样需要在models.py中相应的数据类中添加如下代码:
- class Meta:
- verbose_name = "博文"
- #更改复数显示方式
- verbose_name_plural = "博文"
- 1
- 2
- 3
- 4
注:凡是涉及到管理端操作的功能均需在admin.py文件中添加即可。
在学习过程中,发觉Django的后台功能实在是太强大了,由于models模块实现了ORM框架。经过一系列操作,可以发现管理端的数据CRUD操作已经完全实现,无需用户书写任何数据库操作代码。省心省力啊!
附 Django学习资料
pymysql版本查看命令(请告知我,谢谢~)
Django基础教程
Django官网
菜鸟教程
Python进阶(二十四)-Python中函数的参数定义和可变参数
刚学用Python的时候,特别是看一些库的源码时,经常会看到func(*args, **kwargs)这样的函数定义,这个和*让人有点费解。其实只要把函数参数定义搞清楚了,就不难理解了。
先说说函数定义,我们都知道,下面的代码定义了一个函数funcA
- def funcA():
- pass
- 1
- 2
显然,函数funcA没有参数。
下面这个函数funcB就有两个参数了,
- def funcB(a, b):
- print a
- print b
- 1
- 2
- 3
调用的时候,我们需要使用函数名,加上圆括号扩起来的参数列表,比如 funcB(100, 99),执行结果是:
100
99
很明显,参数的顺序和个数要和函数定义中一致,如果执行funcB(100),Python会报错的:
TypeError: funcB() takes exactly 2 arguments (1 given)
我们可以在函数定义中使用参数默认值,比如
- def funcC(a, b=0):
- print a
- print b
- 1
- 2
- 3
在函数funcC的定义中,参数b有默认值,是一个可选参数,如果我们调用funcC(100),b会自动赋值为0。
OK,目前为止,我们要定义一个函数的时候,必须要预先定义这个函数需要多少个参数(或者说可以接受多少个参数)。一般情况下这是没问题的,但是也有在定义函数的时候,不能知道参数个数的情况(想一想C语言里的printf函数),在Python里,带*的参数就是用来接受可变数量参数的。看一个例子
- def funcD(a, b, *c):
- print a
- print b
- print "length of c is: %d " % len(c)
- print c
- 1
- 2
- 3
- 4
- 5
调用funcD(1, 2, 3, 4, 5, 6)结果是
1
2
length of c is: 4
(3, 4, 5, 6)
我们看到,前面两个参数被a、b接受了,剩下的4个参数,全部被c接受了,c在这里是一个tuple。我们在调用funcD的时候,至少要传递2个参数,2个以上的参数,都放到c里了,如果只有两个参数,那么c就是一个empty tuple。
好了,一颗星我们弄清楚了,下面轮到两颗星。
上面的例子里,调用函数的时候,传递的参数都是根据位置来跟函数定义里的参数表匹配的,比如funcB(100, 99)和funcB(99, 100)的执行结果是不一样的。在Python里,还支持一种用关键字参数(keyword argument)调用函数的办法,也就是在调用函数的时候,明确指定参数值赋值给哪个形参。比如还是上面的funcB(a, b),我们通过这两种方式调用
funcB(a=100, b=99)
- 1
和
funcB(b=99, a=100)
- 1
结果跟funcB(100, 99)都是一样的,因为我们在使用关键字参数调用的时候,指定了把100赋值给a,99赋值给b。也就是说,关键字参数可以让我们在调用函数的时候打乱参数传递的顺序!
另外,在函数调用中,可以混合使用基于位置匹配的参数和关键字参数,前题是先给出固定位置的参数,比如
def funcE(a, b, c):
print a
print b
print c
调用funcE(100, 99, 98)和调用funcE(100, c=98, b=99)的结果是一样的。
好了,经过以上铺垫,两颗星总算可以出场了:
如果一个函数定义中的最后一个形参有 ** (双星号)前缀,所有正常形参之外的其他的关键字参数都将被放置在一个字典中传递给函数,比如:
- def funcF(a, **b):
- print a
- for x in b:
- print x + ": " + str(b[x])
- 1
- 2
- 3
- 4
调用funcF(100, c=’你好’, b=200),执行结果
100
c: 你好
b: 200
大家可以看到,b是一个dict对象实例,它接受了关键字参数b和c。
Python进阶(二十五)-Python读写文件
打开文件
使用open打开文件后一定要记得调用文件对象的close()方法。比如可以用try/finally语句来确保最后能关闭文件。
- file_object = open('thefile.txt')
- try:
- all_the_text = file_object.read( )
- finally:
- file_object.close( )
- 1
- 2
- 3
- 4
- 5
注:不能把open语句放在try块里,因为当打开文件出现异常时,文件对象file_object无法执行close()方法。
读文件
- #读文本文件
- input = open('data', 'r')
- #第二个参数默认为r
- input = open('data')
- #读二进制文件
- input = open('data', 'rb')
- #读取所有内容
- file_object = open('thefile.txt')
- try:
- all_the_text = file_object.read( )
- finally:
- file_object.close( )
- #读固定字节
- file_object = open('abinfile', 'rb')
- try:
- while True:
- chunk = file_object.read(100)
- if not chunk:
- break
- do_something_with(chunk)
- finally:
- file_object.close( )
- #读每行
- list_of_all_the_lines = file_object.readlines( )
- #如果文件是文本文件,还可以直接遍历文件对象获取每行:
- for line in file_object:
- process line
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
写文件
- #写文本文件
- output = open('data', 'w')
- #写二进制文件
- output = open('data', 'wb')
- #追加写文件
- output = open('data', 'w+')
- #写数据
- file_object = open('thefile.txt', 'w')
- file_object.write(all_the_text)
- file_object.close( )
- #写入多行
- file_object.writelines(list_of_text_strings)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意,调用writelines写入多行在性能上会比使用write一次性写入要高。
在处理日志文件的时候,常常会遇到这样的情况:日志文件巨大,不可能一次性把整个文件读入到内存中进行处理,例如需要在一台物理内存为 2GB 的机器上处理一个 2GB 的日志文件,我们可能希望每次只处理其中200MB的内容。
在Python中,内置的File对象直接提供了一个readlines(sizehint) 函数来完成这样的事情。以下面的代码为例:
- file = open('test.log', 'r')
- sizehint = 209715200 # 200M
- position = 0lines = file.readlines(sizehint)
- while not file.tell() - position < 0:
- position = file.tell()
- lines = file.readlines(sizehint)
- 1
- 2
- 3
- 4
- 5
- 6
每次调用 readlines(sizehint) 函数,会返回大约200MB的数据,而且所返回的必然都是完整的行数据,大多数情况下,返回的数据的字节数会稍微比 sizehint 指定的值大一点(除最后一次调用 readlines(sizehint) 函数的时候)。通常情况下,Python 会自动将用户指定的 sizehint 的值调整成内部缓存大小的整数倍。
file在python是一个特殊的类型,它用于在python程序中对外部的文件进行操作。在python中一切都是对象,file也不例外,file有file的方法和属性。下面先来看如何创建一个file对象:
file(name[, mode[, buffering]])
- 1
file()函数用于创建一个file对象,它有一个别名叫open(),可能更形象一些,它们是内置函数。来看看它的参数。它参数都是以字符串的形式传递的。
name是文件的名字。
mode是打开的模式,可选的值为rwaU,分别代表读(默认)写添加支持各种换行符的模式。用w或a模式打开文件的话,如果文件不存在,那么就自动创建。此外,用w模式打开一个已经存在的文件时,原有文件的内容会被清空,因为一开始文件的操作的标记是在文件的开头的,这时候进行写操作,无疑会把原有的内容给抹掉。由于历史的原因,换行符在不同的系统中有不同模式,比如在unix中是一个\n,而在windows中是‘\r\n’,用U模式打开文件,就是支持所有的换行模式,也就说‘\r’ ‘\n’ ‘\r\n’都可表示换行,会有一个tuple用来存贮这个文件中用到过的换行符。不过,虽说换行有多种模式,读到python中统一用\n代替。在模式字符的后面,还可以加上+
b t这两种标识,分别表示可以对文件同时进行读写操作和用二进制模式、文本模式(默认)打开文件。
buffering如果为0表示不进行缓冲;如果为1表示进行“行缓冲“;如果是一个大于1的数表示缓冲区的大小,应该是以字节为单位的。
file对象有自己的属性和方法。先来看看file的属性。
- closed #标记文件是否已经关闭,由close()改写
- encoding #文件编码
- mode #打开模式
- name #文件名
- newlines #文件中用到的换行模式,是一个tuple
- softspace #boolean型,一般为0,据说用于print
file的读写方法:
- F.read([size]) #size为读取的长度,以byte为单位
- F.readline([size])
- 1
- 2
- #读一行,如果定义了size,有可能返回的只是一行的一部分
- F.readlines([size])
- #把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
- F.write(str)
- #把str写到文件中,write()并不会在str后加上一个换行符
- F.writelines(seq)
- #把seq的内容全部写到文件中。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
- file的其他方法:
- F.close()
- #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。如果一个文件在关闭后还对其进行操作会产生ValueError。
- F.flush()
- #把缓冲区的内容写入硬盘
- F.fileno()
- #返回一个长整型的”文件标签“
- F.isatty()
- #文件是否是一个终端设备文件(unix系统中的)
- F.tell()
- #返回文件操作标记的当前位置,以文件的开头为原点
- F.next()
- #返回下一行,并将文件操作标记位移到下一行。把一个file用于for ... in file这样的语句时,就是调用next()函数来实现遍历的。
- F.seek(offset[,whence])
- #将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
- F.truncate([size])
- #把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
代码演示
-
- #! /usr/bin/python
- import os,sys
-
- try:
- fsock = open("D:/SVNtest/test.py", "r")
- except IOError:
- print "The file don't exist, Please double check!"
- exit()
- print 'The file mode is ',fsock.mode
- print 'The file name is ',fsock.name
- P = fsock.tell()
- print 'the postion is %d' %(P)
- fsock.close()
-
- #Read file
- fsock = open("D:/SVNtest/test.py", "r")
- AllLines = fsock.readlines()
- #Method 1
- for EachLine in fsock:
- print EachLine
-
- #Method 2
- print 'Star'+'='*30
- for EachLine in AllLines:
- print EachLine
- print 'End'+'='*30
- fsock.close()
-
- #write this file
- fsock = open("D:/SVNtest/test.py", "a")
- fsock.write("""
- #Line 1 Just for test purpose
- #Line 2 Just for test purpose
- #Line 3 Just for test purpose""")
- fsock.close()
-
-
- #check the file status
- S1 = fsock.closed
- if True == S1:
- print 'the file is closed'
- else:
- print 'The file donot close'
- 附 Python读取TXT文档
- #直接在访问文档时指定编码方式
- myText = open(r"C:/Users/SHQ/Desktop/maya.txt", "r", encoding='UTF-8')
- try:
- print(myText.read())
- finally:
- myText.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
附 Python读取PDF文档
-
- #!/usr/bin/env python
- # encoding: utf-8
-
- """
- @author: Sunny
- @software: IntelliJ IDEA
- @file: prase_pdf.py
- @time: 2017/4/4
- """
- import sys
- import importlib
- importlib.reload(sys)
-
- from pdfminer.pdfparser import PDFParser,PDFDocument
- from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
- from pdfminer.converter import PDFPageAggregator
- from pdfminer.layout import LTTextBoxHorizontal,LAParams
- from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
-
- '''
- 解析pdf 文本,保存到txt文件中
- '''
- path = r'C:/Users/SHQ/Desktop/当前工作/基于Petri网的APP用户行为分析及应用(最终版-定稿-打印).pdf'
- def parse():
- #以二进制读模式打开
- fp = open(path, 'rb')
- #用文件对象来创建一个pdf文档分析器
- praser = PDFParser(fp)
- # 创建一个PDF文档
- doc = PDFDocument()
- # 连接分析器与文档对象
- praser.set_document(doc)
- doc.set_parser(praser)
-
- # 提供初始化密码
- # 如果没有密码 就创建一个空的字符串
- doc.initialize()
-
- # 检测文档是否提供txt转换,不提供就忽略
- if not doc.is_extractable:
- raise PDFTextExtractionNotAllowed
- else:
- # 创建PDf 资源管理器 来管理共享资源
- rsrcmgr = PDFResourceManager()
- # 创建一个PDF参数分析器
- laparams = LAParams()
- # 创建一个PDF资源聚合器 用于整合资源管理器和参数分析器
- device = PDFPageAggregator(rsrcmgr, laparams=laparams)
- # 创建一个PDF解释器对象
- interpreter = PDFPageInterpreter(rsrcmgr, device)
-
- # 循环遍历列表,每次处理一个page的内容
- for page in doc.get_pages(): # doc.get_pages() 获取page列表
- interpreter.process_page(page)
- # 接受该页面的LTPage对象
- layout = device.get_result()
- # 这里layout是一个LTPage对象 里面存放着这个page解析出的各种对象,
- # 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等想要获取文本就获得对象的text属性,
- for x in layout:
- if (isinstance(x, LTTextBoxHorizontal)) and hasattr(x, "get_text"):
- with open(r'C:/Users/SHQ/Desktop/当前工作/基于Petri网的APP用户行为分析及应用(最终版-定稿-打印).txt', 'a') as f:
- results = x.get_text()
- print(results)
- f.write(results + '\n')
-
- if __name__ == '__main__':
- parse()
Python进阶(二十六)-多线程实现同步的四种方式
临界资源即那些一次只能被一个线程访问的资源,典型例子就是打印机,它一次只能被一个程序用来执行打印功能,因为不能多个线程同时操作,而访问这部分资源的代码通常称之为临界区。
锁机制
threading的Lock类,用该类的acquire函数进行加锁,用realease函数进行解锁
- import threading
- import time
-
- class Num:
- def __init__(self):
- self.num = 0
- self.lock = threading.Lock()
- def add(self):
- self.lock.acquire()#加锁,锁住相应的资源
- self.num += 1
- num = self.num
- self.lock.release()#解锁,离开该资源
- return num
-
- n = Num()
- class jdThread(threading.Thread):
- def __init__(self,item):
- threading.Thread.__init__(self)
- self.item = item
- def run(self):
- time.sleep(2)
- value = n.add()#将num加1,并输出原来的数据和+1之后的数据
- print(self.item,value)
-
- for item in range(5):
- t = jdThread(item)
- t.start()
- t.join()#使线程一个一个执行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
当一个线程调用锁的acquire()方法获得锁时,锁就进入“locked”状态。每次只有一个线程可以获得锁。如果此时另一个线程试图获得这个锁,该线程就会变为“blocked”状态,称为“同步阻塞”(参见多线程的基本概念)。
直到拥有锁的线程调用锁的release()方法释放锁之后,锁进入“unlocked”状态。线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行(running)状态。
信号量
信号量也提供acquire方法和release方法,每当调用acquire方法的时候,如果内部计数器大于0,则将其减1,如果内部计数器等于0,则会阻塞该线程,知道有线程调用了release方法将内部计数器更新到大于1位置。
- import threading
- import time
- class Num:
- def __init__(self):
- self.num = 0
- self.sem = threading.Semaphore(value = 3)
- #允许最多三个线程同时访问资源
-
- def add(self):
- self.sem.acquire()#内部计数器减1
- self.num += 1
- num = self.num
- self.sem.release()#内部计数器加1
- return num
-
- n = Num()
- class jdThread(threading.Thread):
- def __init__(self,item):
- threading.Thread.__init__(self)
- self.item = item
- def run(self):
- time.sleep(2)
- value = n.add()
- print(self.item,value)
-
- for item in range(100):
- t = jdThread(item)
- t.start()
- t.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
条件判断
所谓条件变量,即这种机制是在满足了特定的条件后,线程才可以访问相关的数据。
它使用Condition类来完成,由于它也可以像锁机制那样用,所以它也有acquire方法和release方法,而且它还有wait,notify,notifyAll方法。
- """
- 一个简单的生产消费者模型,通过条件变量的控制产品数量的增减,调用一次生产者产品就是+1,调用一次消费者产品就会-1.
- """
-
- """
- 使用 Condition 类来完成,由于它也可以像锁机制那样用,所以它也有 acquire 方法和 release 方法,而且它还有
- wait, notify, notifyAll 方法。
- """
-
- import threading
- import queue,time,random
-
- class Goods:#产品类
- def __init__(self):
- self.count = 0
- def add(self,num = 1):
- self.count += num
- def sub(self):
- if self.count>=0:
- self.count -= 1
- def empty(self):
- return self.count <= 0
-
- class Producer(threading.Thread):#生产者类
- def __init__(self,condition,goods,sleeptime = 1):#sleeptime=1
- threading.Thread.__init__(self)
- self.cond = condition
- self.goods = goods
- self.sleeptime = sleeptime
- def run(self):
- cond = self.cond
- goods = self.goods
- while True:
- cond.acquire()#锁住资源
- goods.add()
- print("产品数量:",goods.count,"生产者线程")
- cond.notifyAll()#唤醒所有等待的线程--》其实就是唤醒消费者进程
- cond.release()#解锁资源
- time.sleep(self.sleeptime)
-
- class Consumer(threading.Thread):#消费者类
- def __init__(self,condition,goods,sleeptime = 2):#sleeptime=2
- threading.Thread.__init__(self)
- self.cond = condition
- self.goods = goods
- self.sleeptime = sleeptime
- def run(self):
- cond = self.cond
- goods = self.goods
- while True:
- time.sleep(self.sleeptime)
- cond.acquire()#锁住资源
- while goods.empty():#如无产品则让线程等待
- cond.wait()
- goods.sub()
- print("产品数量:",goods.count,"消费者线程")
- cond.release()#解锁资源
-
- g = Goods()
- c = threading.Condition()
-
- pro = Producer(c,g)
- pro.start()
-
- con = Consumer(c,g)
- con.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
同步队列
put方法和task_done方法,queue有一个未完成任务数量num,put依次num+1,task依次num-1.任务都完成时任务结束。
- import threading
- import queue
- import time
- import random
-
- '''
- 1.创建一个 Queue.Queue() 的实例,然后使用数据对它进行填充。
- 2.将经过填充数据的实例传递给线程类,后者是通过继承 threading.Thread 的方式创建的。
- 3.每次从队列中取出一个项目,并使用该线程中的数据和 run 方法以执行相应的工作。
- 4.在完成这项工作之后,使用 queue.task_done() 函数向任务已经完成的队列发送一个信号。
- 5.对队列执行 join 操作,实际上意味着等到队列为空,再退出主程序。
- '''
-
- class jdThread(threading.Thread):
- def __init__(self,index,queue):
- threading.Thread.__init__(self)
- self.index = index
- self.queue = queue
-
- def run(self):
- while True:
- time.sleep(1)
- item = self.queue.get()
- if item is None:
- break
- print("序号:",self.index,"任务",item,"完成")
- self.queue.task_done()#task_done方法使得未完成的任务数量-1
-
- q = queue.Queue(0)
- '''
- 初始化函数接受一个数字来作为该队列的容量,如果传递的是
- 一个小于等于0的数,那么默认会认为该队列的容量是无限的.
- '''
- for i in range(2):
- jdThread(i,q).start()#两个线程同时完成任务
-
- for i in range(10):
- q.put(i)#put方法使得未完成的任务数量+1
Python进阶(二十七)-字符串大小写转换
大小写转换
和其他语言一样,Python为string对象提供了转换大小写的方法:upper() 和 lower()。还不止这些,Python还为我们提供了首字母大写,其余小写的capitalize()方法,以及所有单词首字母大写,其余小写的title()方法。函数较简单,看下面的例子:
- s = "Hello PythoN"
-
- #全部大写
- print(s.upper())
- #全部小写
- print(s.lower())
- #首字母大写,其余小写
- print(s.title())
- #每个单次首字母大写
- print(s.capitalize())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出结果:

判断大小写
Python提供了isupper(),islower(),istitle()方法用来判断字符串的大小写。注意的是:
- 1.没有提供 iscapitalize()方法,至于为什么Python没有为我们实现,就不得而知了。
- 2.如果对空字符串使用isupper(),islower(),istitle(),返回的结果都为False。
- print('A'.isupper())
- print('S'.islower())
- print("Hello Python".istitle())
- 1
- 2
- 3
输出结果:

Python进阶(二十八)-Python实现定时任务
前言
最近学习到了 python 中两种开启定时任务的方法,和大家分享一下心得。
- sched.scheduler()
- threading.Timer()
sched 定时任务
使用sched的套路如下:
- s = sched.scheduler(time.time, time.sleep)
- s.enter(delay, priority, func1, (arg1, arg2, ...))
- s.enter(delay, priority, func2, (arg1, arg2, arg3, ...))
- s.run()
- 1
- 2
- 3
- 4
步骤如下:
- 第一步新建一个调度器;
- 第二步添加任务,可以添加多个任务;
- 第三步让调度器开始运行。
第二步各参数含义:
- delay 相对于调度器添加这个任务时刻的延时,以秒为单位;
- priority 优先级,数字越小优先级越高;
- func1 任务函数
- (arg1, arg2, …) 任务函数的参数
代码演示
- import time
- import sched
-
- # 第一个工作函数
- # 第二个参数 @starttime 表示任务开始的时间
- # 很明显参数在建立这个任务的时候就已经传递过去了,至于任务何时开始执行就由调度器决定了
- def worker(msg, start_time):
- print (u"任务执行的时刻", time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())), "传达的消息是", msg, '任务建立时刻', start_time)
-
-
- # 创建一个调度器示例
- # 第一参数是获取时间的函数,第二个参数是延时函数
- print (u'---------- 两个简单的例子 -------------')
- print (u'程序启动时刻:', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
- s = sched.scheduler(time.time, time.sleep)
- s.enter(1.0, 1, worker, ('hello', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
- s.enter(3.0, 1, worker, ('world', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
- s.run() # 这一个 s.run() 启动上面的两个任务
- print (u'睡眠2秒前时刻:', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
- time.sleep(2)
- print (u'睡眠2秒结束时刻:', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
-
-
- # 重点关注下面2个任务,建立时间,启动时间
- # 2个任务的建立时间都很好计算,但有没有发现"hello world [3]"的启动时间比建立时间晚13秒,
- # 这不就是2个sleep的总延时吗?所以说启动时间并不一定就是delay能指定的,还需要看具体的程序环境,
- # 如果程序堵塞的很厉害,已经浪费了一大段的时间还没有到scheduler能调度这个任务,当scheduler能调度这个
- # 任务的时候,发现delay已经过去了,scheduler为了弥补“罪过”,会马上启动这个任务。
- # 任务 "hello world [15]" 就是一个很好的例子,正常情况下,程序没有阻塞的那么厉害,在scheduler能调度这个任务的时候
- # 发现delay还没到就等待,如果delay时间到了就可以在恰好指定的延时调用这个任务。
- print (u'\n\n---------- 两个复杂的例子 -------------')
- s.enter(3, 1, worker, ('hello world [3]', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
- print (u'睡眠7秒前时刻:', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
- time.sleep(7)
- print (u'睡眠7秒结束时刻:', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
-
- s.enter(15, 1, worker, ('hello world [15]', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
- print (u'睡眠6秒前时刻:', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
- time.sleep(6)
- print (u'睡眠6秒结束时刻:', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
-
- s.run() # 过了2秒之后,启动另外一个任务
-
- print (u'程序结束时刻', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
-
- # 计数器,一个循环任务,总共让自己执行3次
-
- total = 0
- # 第二个工作函数,自调任务,自己开启定时并启动。
- def worker2(msg, starttime):
- global total
- total += 1
- print (u'当前时刻:', time.time(), '消息是:', msg, ' 启动时间是:', starttime)
- # 只要没有让自己调用到第3次,那么继续重头开始执行本任务
- if total < 3:
- # 这里的delay 可以重新指定
- s.enter(5, 2, worker2, ('perfect world %d' % (total), time.time()))
- s.run()
-
- print (u'程序开始时刻:', time.time())
- # 开启自调任务
- s.enter(5, 2, worker2, ('perfect world %d' % (total), time.time()))
- s.run()
- print (u'程序结束时刻:', time.time())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
运行结果

循环任务
任务快结束时利用scheduler又重新调用自己让自己“活过来”。
代码演示
- import sched
- import time
- # 计数器,一个循环任务,总共让自己执行3次
- s = sched.scheduler(time.time, time.sleep)
- total = 0
- # 第二个工作函数,自调任务,自己开启定时并启动。
- def worker2(msg, starttime):
- global total
- total += 1
- print (u'当前时刻:', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())), '消息是:', msg, ' 启动时间是:', starttime)
- # 只要没有让自己调用到第3次,那么继续重头开始执行本任务
- if total < 3:
- # 这里的delay可以重新指定
- s.enter(5, 2, worker2, ('perfect world %d' % (total), time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
- s.run()
-
- print (u'程序开始时刻:', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
- # 开启自调任务
- s.enter(5, 2, worker2, ('perfect world %d' % (total), time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
- s.run()
- print (u'程序结束时刻:', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
运行结果

Threading.Timer() 实现定时任务
代码演示
- from threading import Timer
- import time
-
- def func(msg, starttime):
- print (u'程序启动时刻:', starttime, '当前时刻:', time.time(), '消息内容 --> %s' % (msg))
-
- # 下面的两个语句和上面的 scheduler 效果一样的
- Timer(5, func, ('hello', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))).start()
- Timer(3, func, ('world', time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))).start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
运行结果

Threading.Timer() 实现循环任务
代码演示
- #利用 threading.Timer() 建立的自调任务
- count = 0
- def loopfunc(msg,start_time):
- global count
- print (u'启动时刻:', start_time, ' 当前时刻:', time.time(), '消息 --> %s' % (msg))
- count += 1
- if count < 3:
- Timer(3, loopfunc, ('world %d' % (count), time.time())).start()
-
- Timer(3, loopfunc, ('world %d' % (count), time.time())).start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行结果

如何实现某一时刻执行任务
先求出目标时间和当前时间的时间戳差值,再调用sleep或设置延时参数。
有关Python中时间戳的计算详见博文《Python进阶(二十九)-Python时间&日期&时间戳处理》。
Python进阶(二十九)-Python时间&日期&时间戳处理
将字符串的时间转换为时间戳
方法:
- import time
- #将其转换为时间数组
- a = "2013-10-10 23:40:00"
- timeArray = time.strptime(a, "%Y-%m-%d %H:%M:%S")
- #转换为时间戳
- timeStamp = int(time.mktime(timeArray))
- #1381419600
- print(timeStamp)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
字符串格式更改
如a = “2013-10-10 23:40:00”,想改为 a = “2013/10/10 23:40:00”
方法:先转换为时间数组,然后转换为其他格式
- a = "2013-10-10 23:40:00"
- timeArray = time.strptime(a, "%Y-%m-%d %H:%M:%S")
- otherStyleTime = time.strftime("%Y/%m/%d %H:%M:%S", timeArray)
- #2013/10/10 23:40:00
- print(otherStyleTime)
- 1
- 2
- 3
- 4
- 5
时间戳转换为指定格式日期
方法一:
利用localtime()转换为时间数组,然后格式化为需要的格式,如
- timeStamp = 1381419600
- timeArray = time.localtime(timeStamp)
- otherStyleTime=time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
- #2013-10-10 23:40:00
- print(otherStyleTime)
- 1
- 2
- 3
- 4
- 5
方法二:
- import datetime
- timeStamp = 1381419600
- dateArray = datetime.datetime.utcfromtimestamp(timeStamp)
- otherStyleTime = dateArray.strftime("%Y-%m-%d %H:%M:%S")
- #2013-10-10 15:40:00
- print(otherStyleTime)
- 1
- 2
- 3
- 4
- 5
- 6
注意:使用此方法时必须先设置好时区,否则有时差
获取当前时间并转换为指定日期格式
方法一:
- import time
- timeStamp = 1381419600
- #获得当前时间时间戳
- now = int(time.time())
- #转换为其他日期格式,如:"%Y-%m-%d %H:%M:%S"
- timeArray = time.localtime(timeStamp)
- otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
- #2013-10-10 23:40:00
- print(otherStyleTime)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
方法二:
- import datetime
- #获得当前时间
- now = datetime.datetime.now()
- #转换为指定的格式
- otherStyleTime = now.strftime("%Y-%m-%d %H:%M:%S")
- #2017-04-06 16:13:32
- print(otherStyleTime)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
获得三天前的时间
方法:
- import time
- import datetime
- #先获得时间数组格式的日期
- threeDayAgo=(datetime.datetime.now() - datetime.timedelta(days = 3))
- #转换为时间戳
- # timeStamp = int(time.mktime(threeDayAgo.timetuple()))
- #转换为其他字符串格式
- otherStyleTime = threeDayAgo.strftime("%Y-%m-%d %H:%M:%S")
- #2017-04-03 16:15:56
- print(otherStyleTime)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
注:timedelta()的参数有:days,hours,seconds,microseconds
给定时间戳,计算该时间的几天前时间
- import datetime
- import time
- timeStamp = 1381419600
- #先转换为datetime
- dateArray = datetime.datetime.utcfromtimestamp(timeStamp)
- threeDayAgo = dateArray - datetime.timedelta(days = 3)
- #2013-10-07 15:40:00
- print(threeDayAgo)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
给定日期字符串,直接转换为datetime对象
- dateStr = '2013-10-10 23:40:00'
- datetimeObj=datetime.datetime.strptime(dateStr, "%Y-%m-%d %H:%M:%S")
- 1
- 2
注:将字符串日期转换为datetime后可以很高效的进行统计操作,因为转换为datetime后,可以通过datetime.timedelta()方法来前后移动时间,效率很高,而且可读性很强。
计算两个datetime之间的差距
- a = datetime.datetime(2014,12,4,1,59,59)
- b = datetime.datetime(2014,12,4,3,59,59)
- diffSeconds = (b-a).total_seconds()
- #7200.0
- print(diffSeconds)
- 1
- 2
- 3
- 4
- 5
注:time.strftime,time.strptime,datetime.timedelta
Python time strftime()方法
Python time strftime() 函数接收以时间元组,并返回以可读字符串表示的当地时间,格式由参数format决定。
time.strftime(format[, t])
format – 格式字符串。
t – 可选的参数t是一个struct_time对象。
返回以可读字符串表示的当地时间。
以下实例展示了 strftime() 函数的使用方法:
- #!/usr/bin/python
- import time
-
- t = (2009, 2, 17, 17, 3, 38, 1, 48, 0)
- t = time.mktime(t)
- print time.strftime("%b %d %Y %H:%M:%S", time.gmtime(t))
- 1
- 2
- 3
- 4
- 5
- 6
以上实例输出结果为:
Feb 17 2009 09:03:38
Python time strptime()方法
Python time strptime() 函数根据指定的格式把一个时间字符串解析为时间元组。
time.strptime(string[, format])
string – 时间字符串。
format – 格式化字符串。
返回struct_time对象。
以下实例展示了 strptime() 函数的使用方法:
- #!/usr/bin/python
- import time
-
- struct_time = time.strptime("30 Nov 00", "%d %b %y")
- print "returned tuple: %s " % struct_time
- 1
- 2
- 3
- 4
- 5
以上实例输出结果为:
returned tuple: (2000, 11, 30, 0, 0, 0, 3, 335, -1)
datetime.timedelta
datetime.timedelta对象代表两个时间之间的的时间差,两个date或datetime对象相减时可以返回一个timedelta对象。
构造函数:
class datetime.timedelta([days[, seconds[, microseconds[, milliseconds[, minutes[, hours[, weeks]]]]]]])
所有参数可选,且默认都是0,参数的值可以是整数,浮点数,正数或负数。
Python进阶(三十)-Python3实现随机数
- random是用于生成随机数的,我们可以利用它随机生成数字或者选择字符串。
- random.seed(x)改变随机数生成器的种子seed。
- 一般不必特别去设定seed,Python会自动选择seed。
- random.random() 用于生成一个随机浮点数n,0 <= n < 1
- random.uniform(a,b) 用于生成一个指定范围内的随机浮点数,生成的随机整数a<=n<=b;
- random.randint(a,b)
用于生成一个指定范围内的整数,a为下限,b为上限,生成的随机整数a<=n<=b;若a=b,则n=a;若a>b,报错 - random.randrange([start], stop [,step])
从指定范围[start,stop)内,按指定基数递增的集合中获取一个随机数,基数缺省值为1 - random.choice(sequence)
从序列中获取一个随机元素,参数sequence表示一个有序类型,并不是一种特定类型,泛指list,tuple,字符串等 - random.shuffle(x[,random]) 用于将一个列表中的元素打乱(洗牌),会改变原始列表
- random.sample(sequence,k) 从指定序列中随机获取k个元素作为一个片段返回,不会改变原有序列
但是,有一点需要注意:python random是伪随机数。
那么,可以借用python random实现真随机数吗?答案是No。所谓真随机数,是要求根据绝对随机事件产生的数,也就是说要求要有一个无因果关系的随机事件,那么,这玩意只存在与哲学领域……
目前的随机数产生都是统计上的随机,因为随机源都是自然事件,顶天了算是混沌变量,绝对的无因果大概是不存在的。
不过统计随机基本上都够用了吧……
还是老老实实的用random模块吧….
代码演示
- import random
- #随机整数
- import string
-
- print(random.randint(0,99))
- #随机选取0到100间的偶数
- print(random.randrange(0, 101, 2))
- #随机浮点数
- print(random.random())
- print(random.uniform(1, 10))
- #随机字符
- print(random.choice('abcdefg&#%^*f'))
- #多个字符中选取特定数量的字符
- print(random.sample('abcdefghij',3))
- #多个字符中选取特定数量的字符组成新字符串
- # print(string.join(random.sample(['a','b','c','d','e','f','g','h','i','j'], 3)).replace(" ",""))
- #随机选取字符串
- print(random.choice ( ['apple', 'pear', 'peach', 'orange', 'lemon'] ))
- #洗牌
- items = [1, 2, 3, 4, 5, 6]
- random.shuffle(items)
- print("洗牌:", items)
- #从指定序列中随机获取k个元素作为一个片段返回,不会改变原有序列
- list = []
- list = random.sample(items,2)
- print(list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
结果

Python进阶(三十一)-往MySQL数据库里添加数据,update和insert哪个效率高
在编写“Water Spider”过程中,遇到了批量更新数据的情况。自己刚开始时想使用mysql提供的cursor.executemany(operation, seq_of_params)方法执行批量更新操作,但是在写sql语句时遇到了问题,不知道如何写了。
后来换种思路,考虑在执行数据插入之前先做数据表删除操作,然后再执行写入操作。因为自己臆想的是“数据插入的效率应该优于更细的效率。”因此,决定对于该问题进行实际考察。
下面总结一下网络上针对该问题大家给出的观点
1. “不考虑主键变动,索引变动,触发器联动的情况下,update比Insert效率高。”
2. 这个很难说,相关因素太多了:存储引擎类型、是否加索引(索引结构如B+树索引或者哈希索引、索引更新、聚集索引还是非聚集索引)、约束(如唯一性约束、外键约束等)…
还有提下三种插入语句(也有可能影响插入速度,从而难以判断插入快还是更新快):
MySQL中常用的三种插入数据的语句:
-
insert into表示插入数据,数据库会检查主键,如果出现重复会报错;
-
replace into表示插入替换数据,需求表中有Primary
Key,或者唯一索引,如果表中已经存在数据,则用新数据替换,如果没有数据效果则和insert into一样; - insert ignore表示,如果表中如果已经存在相同的记录,则忽略当前新数据。
SQL中插入一个记录需要的时间由下列因素组成,其中的数字表示大约比例:
连接:(3)
发送查询给服务器:(2)
分析查询:(2)
插入记录:(1x记录大小)
插入索引:(1x索引)
关闭:(1)
如果我们每插入一条都执行一个SQL语句,那么我们需要执行除了连接和关闭之外的所有步骤N次,这样是非常耗时的,优化的方式有一下几种:
在每个insert语句中写入多行,批量插入
将所有查询语句写入事务中
利用Load Data导入数据
每种方式执行的性能如下。
Innodb引擎
InnoDB 给 MySQL 提供了具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。InnoDB 提供了行锁(locking on row level)以及外键约束(FOREIGN KEY constraints)。
InnoDB 的设计目标是处理大容量数据库系统,它的 CPU 利用率是其它基于磁盘的关系数据库引擎所不能比的。在技术上,InnoDB 是一套放在 MySQL 后台的完整数据库系统,InnoDB 在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
对于这种大数据量的更新情况,可以采用多线程的方式,每个线程更新100条数据,这样就能提高更新的速度了。
当然这里的100只是一个猜想值,哪个值合适,需要你测试才能得出。我想的话,应该能比单线要快些,至于能不能优化到2s,这个就不清楚了。
同时需要注意你的连接池大小、线程池大小(核心线程数)。这些资源也会影响到你的更新速度(即这些资源不能出现竞争)
最后,我对你需要更新这么大的数据量操作有一些疑问:
这个操作是online的吗?
这个操作的返回是实时的吗?
对于大数据量的更新一般会做成一个异步的操作,而不需要是实时的。
Python进阶(三十三)-Python获取并输出当前日期时间
取得时间相关信息的话,要用到python time模块,python time模块里面有很多非常好用的功能,可以去官方文档了解下。时间戳是1970年到现在时间相隔的时间。
你可以试下下面的方式来取得当前时间的时间戳:
- import time
- print time.time()
- 1
- 2
输出的结果是:
1357723206.31
但是这样是一连串的数字不是我们想要的结果,我们可以利用time模块的格式化时间的方法来处理:
time.localtime(time.time())
- 1
用time.localtime()方法,作用是格式化时间戳为本地的时间。
输出的结果是:
time.struct_time(tm_year=2010, tm_mon=7, tm_mday=19, tm_hour=22, tm_min=33, tm_sec=39, tm_wday=0, tm_yday=200, tm_isdst=0)
现在看起来更有希望格式成我们想要的时间了。
time.strftime('%Y-%m-%d',time.localtime(time.time()))
- 1
最后用time.strftime()方法,把刚才的一大串信息格式化成我们想要的东西,现在的结果是:
2013-01-09
输出日期和时间:
time.strftime(‘%Y-%m-%d %H:%M:%S’,time.localtime(time.time()))
time.strftime里面有很多参数,可以让你能够更随意的输出自己想要的东西:
下面是time.strftime的参数:
strftime(format[, tuple]) -> string
- 1
将指定的struct_time(默认为当前时间),根据指定的格式化字符串输出。
python中时间日期格式化符号:
- %y 两位数的年份表示(00-99)
- %Y 四位数的年份表示(000-9999)
- %m 月份(01-12)
- %d 月内中的一天(0-31)
- %H 24小时制小时数(0-23)
- %I 12小时制小时数(01-12)
- %M 分钟数(00=59)
- %S 秒(00-59)
- %a 本地简化星期名称
- %A 本地完整星期名称
- %b 本地简化的月份名称
- %B 本地完整的月份名称
- %c 本地相应的日期表示和时间表示
- %j 年内的一天(001-366)
- %p 本地A.M.或P.M.的等价符
- %U 一年中的星期数(00-53)星期天为星期的开始
- %w 星期(0-6),星期天为星期的开始
- %W 一年中的星期数(00-53)星期一为星期的开始
- %x 本地相应的日期表示
- %X 本地相应的时间表示
- %Z 当前时区的名称
- %% %号本身
Python进阶(三十四)-Python3多线程解读
线程讲解
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
- 程序的运行速度可能加快。
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程的上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
线程可以被抢占(中断)。
在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) – 这就是线程的退让。
线程可以分为:
- 内核线程:由操作系统内核创建和撤销。
- 用户线程:不需要内核支持而在用户程序中实现的线程。
Python3 线程中常用的两个模块为:
- _thread
- threading(推荐使用)
thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用”thread” 模块。为了兼容性,Python3 将 thread 重命名为 “_thread”。
开始学习Python线程
Python中使用线程有两种方式:函数或者用类来包装线程对象。
函数式:调用 _thread 模块中的start_new_thread()函数来产生新线程。语法如下:
_thread.start_new_thread ( function, args[, kwargs] )
- 1
参数说明:
- function - 线程函数。
- args - 传递给线程函数的参数,他必须是个tuple类型。
- kwargs - 可选参数。
实例:
- #!/usr/bin/python3
-
- import _thread
- import time
-
- # 为线程定义一个函数
- def print_time( threadName, delay):
- count = 0
- while count < 5:
- time.sleep(delay)
- count += 1
- print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
-
- # 创建两个线程
- try:
- _thread.start_new_thread( print_time, ("Thread-1", 2, ) )
- _thread.start_new_thread( print_time, ("Thread-2", 4, ) )
- except:
- print ("Error: 无法启动线程")
-
- while 1:
- pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
执行以上程序输出结果如下:

线程模块
Python3 通过两个标准库 _thread 和 threading 提供对线程的支持。
- _thread 提供了低级别的、原始的线程以及一个简单的锁,它相比于 threading 模块的功能还是比较有限的。
- threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate():
返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 - threading.activeCount():
返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的join()
方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。 - isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
使用 threading 模块创建线程
我们可以通过直接从 threading.Thread 继承创建一个新的子类,并实例化后调用 start() 方法启动新线程,即它调用了线程的 run() 方法:
- #!/usr/bin/python3
-
- import threading
- import time
-
- exitFlag = 0
-
- class myThread (threading.Thread):
- def __init__(self, threadID, name, counter):
- threading.Thread.__init__(self)
- self.threadID = threadID
- self.name = name
- self.counter = counter
- def run(self):
- print ("开始线程:" + self.name)
- print_time(self.name, self.counter, 5)
- print ("退出线程:" + self.name)
-
- def print_time(threadName, delay, counter):
- while counter:
- if exitFlag:
- threadName.exit()
- time.sleep(delay)
- print ("%s: %s" % (threadName, time.ctime(time.time())))
- counter -= 1
-
- # 创建新线程
- thread1 = myThread(1, "Thread-1", 1)
- thread2 = myThread(2, "Thread-2", 2)
-
- # 开启新线程
- thread1.start()
- thread2.start()
- thread1.join()
- thread2.join()
- print ("退出主线程")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
以上程序执行结果如下:

线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。
考虑这样一种情况:一个列表里所有元素都是0,线程”set”从后向前把所有元素改成1,而线程”print”负责从前往后读取列表并打印。
那么,可能线程”set”开始改的时候,线程”print”便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态——锁定和未锁定。每当一个线程比如”set”要访问共享数据时,必须先获得锁定;如果已经有别的线程比如”print”获得锁定了,那么就让线程”set”暂停,也就是同步阻塞;等到线程”print”访问完毕,释放锁以后,再让线程”set”继续。
经过这样的处理,打印列表时要么全部输出0,要么全部输出1,不会再出现一半0一半1的尴尬场面。
实例:
- #!/usr/bin/python3
-
- import threading
- import time
-
- class myThread (threading.Thread):
- def __init__(self, threadID, name, counter):
- threading.Thread.__init__(self)
- self.threadID = threadID
- self.name = name
- self.counter = counter
- def run(self):
- print ("开启线程: " + self.name)
- # 获取锁,用于线程同步
- threadLock.acquire()
- print_time(self.name, self.counter, 3)
- # 释放锁,开启下一个线程
- threadLock.release()
-
- def print_time(threadName, delay, counter):
- while counter:
- time.sleep(delay)
- print ("%s: %s" % (threadName, time.ctime(time.time())))
- counter -= 1
-
- threadLock = threading.Lock()
- threads = []
-
- # 创建新线程
- thread1 = myThread(1, "Thread-1", 1)
- thread2 = myThread(2, "Thread-2", 2)
-
- # 开启新线程
- thread1.start()
- thread2.start()
-
- # 添加线程到线程列表
- threads.append(thread1)
- threads.append(thread2)
-
- # 等待所有线程完成
- for t in threads:
- t.join()
- print ("退出主线程")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
执行以上程序,输出结果为:

线程优先级队列(Queue)
Python 的 Queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。
这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
Queue 模块中的常用方法:
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- Queue.get_nowait() 相当Queue.get(False)
- Queue.put(item) 写入队列,timeout等待时间
- Queue.put_nowait(item) 相当Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
实例:
- #!/usr/bin/python3
-
- import queue
- import threading
- import time
-
- exitFlag = 0
-
- class myThread (threading.Thread):
- def __init__(self, threadID, name, q):
- threading.Thread.__init__(self)
- self.threadID = threadID
- self.name = name
- self.q = q
- def run(self):
- print ("开启线程:" + self.name)
- process_data(self.name, self.q)
- print ("退出线程:" + self.name)
-
- def process_data(threadName, q):
- while not exitFlag:
- queueLock.acquire()
- if not workQueue.empty():
- data = q.get()
- queueLock.release()
- print ("%s processing %s" % (threadName, data))
- else:
- queueLock.release()
- time.sleep(1)
-
- threadList = ["Thread-1", "Thread-2", "Thread-3"]
- nameList = ["One", "Two", "Three", "Four", "Five"]
- queueLock = threading.Lock()
- workQueue = queue.Queue(10)
- threads = []
- threadID = 1
-
- # 创建新线程
- for tName in threadList:
- thread = myThread(threadID, tName, workQueue)
- thread.start()
- threads.append(thread)
- threadID += 1
-
- # 填充队列
- queueLock.acquire()
- for word in nameList:
- workQueue.put(word)
- queueLock.release()
-
- # 等待队列清空
- while not workQueue.empty():
- pass
-
- # 通知线程是时候退出
- exitFlag = 1
-
- # 等待所有线程完成
- for t in threads:
- t.join()
- print ("退出主线程")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
以上程序执行结果:

延伸阅读
有关线程与进程的区别、线程锁的具体内容详见博文《剑指Offer——知识点储备-Java基础》、《Java进阶(四十三)线程与进程的区别》、《Java进阶(四十四)线程与进程的特征及区别》。
学习资料
http://www.runoob.com/python/att-time-sleep.html
Python进阶(三十五)-Fiddler命令行和HTTP断点调试
一. Fiddler内置命令
上一节(使用Fiddler进行抓包分析)中,介绍到,在web session(与我们通常所说的session不是同一个概念,这里的每条HTTP请求都称为一个session)。界面中可以看到Fiddler抓取的所有HTTP请求.而为了更加方便的管理所有的session, Fiddler提供了一系列内置的函数用于筛选和操作这些session(习惯命令行操作Linux的童鞋应该可以感受到这会有多么方便).输入命令的位置在web session管理面板的下方(通过快捷键alt+q可以focus到命令行).
Fiddler内置的命令有如下几种:
1. select命令
选择所有相应类型(指content-type)为指定类型的HTTP请求,如选择图片,使用命令select image.而select css则可以选择所有相应类型为css的请求,select html则选择所有响应为HTML的请求(怎么样,是不是跟SQL语句很像?)。如图是执行select image之后的结果:
2. allbut命令
allbut命令用于选择所有响应类型不是给定类型的HTTP请求。如allbut image用于选择所有相应类型不是图片的session(HTTP请求),该命令还有一个别名keeponly.需要注意的是,keeponly和allbut命令是将不是该类型的session删除,留下的都是该类型的响应。因此,如果你执行allbut xxxx(不存在的类型),实际上类似与执行cls命令(删除所有的session, ctrl+x快捷键也是这个作用)。
3. ?text命令
选择所有 URL 匹配问号后的字符的全部 session。
4. >size 和
5. =status命令
选择响应状态等于给定状态的所有HTTP请求。
例如,选择所有状态为200的HTTP请求:=200
6. @host命令
选择包含指定 HOST 的全部 HTTP请求。
例如:@csdn.NET选择所有host包含csdn.Net的请求
7. Bpafter, Bps, bpv, bpm, bpu
这几个命令主要用于批量设置断点
- Bpafter xxx: 中断 URL 包含指定字符的全部 session 响应
- Bps xxx: 中断 HTTP 响应状态为指定字符的全部 session 响应。
- Bpv xxx: 中断指定请求方式的全部 session 响应
- Bpm xxx: 中断指定请求方式的全部 session 响应。等同于bpv xxx
- Bpu xxx:与bpafter类似。
当这些命令没有加参数时,会清空所有设置了断点的HTTP请求。
更多的其他命令可以参考Fiddler官网手册。
二.使用Fiddler进行HTTP断点调试
这是Fiddler又一强大和实用的工具之一。通过设置断点,Fiddler可以做到:
-
修改HTTP请求头信息。例如修改请求头的UA, Cookie, Referer 信息,通过“伪造”相应信息达到达到相应的目的(调试,模拟用户真实请求等)。
-
构造请求数据,突破表单的限制,随意提交数据。避免页面js和表单限制影响相关调试。
-
拦截响应数据,修改响应实体。
为什么以上方法是重要的?假设js前端程序员和服务器程序员是分工合作的,js程序员想要调试Ajax请求的功能,这样便不必等待服务器端程序员开发好所有接口之后再开始开发js端的ajax请求功能,因为通过“模拟”真实的服务器端的响应,便可以保证功能的正确性,而服务器端开发程序员,只要保证最终的响应是符合规定的即可。这大大简化了程序开发的效率,当然也降低了不同业务线程序员联调的难度。
有两种方法设置断点: -
1.fiddler菜单栏->rules->automatic Breakpoints->选择断点方式,这种方式下设定的断点会对之后的所有HTTP请求有效。 有两个断点位置:
-
a. before response。也就是发送请求之后,但是Fiddler代理中转之前,这时可以修改请求的数据。
-
b.after response。也就是服务器响应之后,但是在Fiddler将响应中转给客户端之前。这时可以修改响应的结果。
-
2.命令行下输入。Bpafter xxx或者bpv,bpu,bpm等设置断点。这种断点只针对特定类型的请求。
我们以本地的web项目为例,演示如何简单的设置HTTP断点:
1.首先设置Firefox的代理,使之可以抓取所有的HTTP请求(localhost的请求,也可以在filter中设置只抓取intranet请求),设置如下图所示:
- 这时用web打开本地的项目。页面的内容为:
- 设置响应后断点(after response breakpoint),可以通过命令行设置:bpafter localhost。键入回车之后,web再次访问文件,通过Fiddler的web session界面可以看到,请求已经被挂起来了,而web浏览器也一直处于加载的状态。观察右侧的inspector面板下,也出现了新的东西:
这时我们就可以修改响应的信息了。修改过程为:
切换到textView子面板,选择需要修改的部分,然后点击 “run to complete“,便可回送修改后的响应。假设我们修改后的内容如下:
点击执行后,打开刚刚的web界面。可以看到的页面的变化。

可见,页面的响应已经有了相应的变化。这就是响应后断点。当然实际应用中,断点的设置和响应的修改会比这复杂的多,这里只是基本的示例。
终止断点的方式有:
- 在inspector界面点击“run complete“即会终止本次HTTP请求的断点。
- 输入Go命令,也会使得当前的请求跳过断点。
- 在rules->auto breakpoint中disabled断点即可。
总之,Fiddler的断点功能非常强大,关于它的进一步学习和应用,需要一个不断积累和摸索的过程。
Python进阶(三十六)-Web框架Django项目搭建全过程
IDE说明:
- Win7系统
- Python:3.5
- Django:1.10
- Pymysql:0.7.10
- Mysql:5.5
注:可通过pip freeze查看已安装库版本信息。
Django 是由 Python 开发的一个免费的开源网站框架,可以用于快速搭建高性能,优雅的网站!
Django 特点
- 强大的数据库功能
- 用python的类继承,几行代码就可以拥有一个丰富,动态的数据库操作接口(API),如果需要你也能执行SQL语句。
- 自带的强大的后台功能
- 几行简单的代码就让你的网站拥有一个强大的后台,轻松管理你的内容! 优雅的网址
- 用正则匹配网址,传递到对应函数,随意定义,如你所想!
- 模板系统–强大,易扩展的模板系统,设计简易,代码,样式分开设计,更容易管理。
- 缓存系统–与memcached或其它的缓存系统联用,更出色的表现,更快的加载速度。
- 国际化–完全支持多语言应用,允许你定义翻译的字符,轻松翻译成不同国家的语言。
有关Python,Mysql的安装操作这里不再进行阐述,大家可在网络上自行查找解决。其中,django,pymysql的安装使用pip install *命令即可完成。
安装好Django之后, 就可以使用 django-admin.py管理工具来创建一个项目。首先我们来看下django-admin.py的命令介绍,在命令行输入django-admin.py查看可用的项目管理命令。
Django项目创建HelloWorld项目具体过程如下:
Step1: 在搭建Django项目之前,首先选择项目存放目录。然后在Dos窗口CD切换到项目存放目录。
Step2: 创建项目 执行django-admin.py startproject HelloWorld
打开IDEA,可看到创建的项目目录如下图所示:
目录说明:
- HelloWorld: 项目的容器。
- manage.py: 一个实用的命令行工具,可让你以各种方式与该 Django 项目进行交互。
- HelloWorld/init.py: 一个空文件,告诉 Python 该目录是一个 Python 包。
- HelloWorld/settings.py: 该 Django 项目的设置/配置。
- HelloWorld/urls.py: 该 Django 项目的 URL 声明; 一份由 Django 驱动的网站”目录”。
- HelloWorld/wsgi.py: 一个 WSGI 兼容的 Web 服务器的入口,以便运行你的项目。
接下来我们进入 HelloWorld 目录输入以下命令,启动服务器:
python manage.py runserver 0.0.0.0:8000
- 1
0.0.0.0 让其它电脑可连接到开发服务器,8000 为端口号。如果不说明,那么端口号默认为 8000。
在浏览器输入你服务器的ip及端口号,如果正常启动,输出结果如下:
Step3: 创建应用 在命令行输入django-admin.py startapp demo
打开IDEA,可看到创建的项目目录如下图所示:
目录说明:
- demo: 应用的容器。注:后面的页面设计文件,在此目录下创建目录templates,名为XX.html的文件放在此处。
- init.py:如上一个init.py文件
- migrations: 数据库相关目录,同步数据库之后会出现数据类。
- admin.py: admin后台管理文件
- apps.py: app应用管理文件
- models.py:主要用一个 Python 类来描述数据表,称为模型(model) 。运用这个类,你可以通过简单的 Python的代码来创建、检索、更新、删除 数据库中的记录而无需写一条又一条的SQL语句。
- tests.py:测试文件
- views.py:包含了页面的业务逻辑。
创建超级管理员
- python manage.py createsuperuser
-
- # 按照提示输入用户名和对应的密码就好了邮箱可以留空,用户名和密码必填
-
- # 修改 用户密码可以用:
- python manage.py changepassword username
- 1
- 2
- 3
- 4
- 5
- 6
附
服务端响应客户端请求过程
流程图如下:
上面的流程图可以大致描述Django处理request的流程,按照流程图2的标注,可以分为以下几个步骤:
- 1.用户通过浏览器请求一个页面。
- 2.请求到达Request Middlewares,中间件对request做一些预处理或者直接response请求。
- 3.URLConf通过urls.py文件和请求的URL找到相应的View。
- 4.View Middlewares被访问,它同样可以对request做一些处理或者直接返回response。
- 5.调用View中的函数。
- 6.View中的方法可以选择性的通过Models访问底层的数据。
- 7.所有的Model-to-DB的交互都是通过manager完成的。
- 8.如果需要,Views可以使用一个特殊的Context。
- 9.Context被传给Template用来生成页面。
- a.Template使用Filters和Tags去渲染输出
- b.输出被返回到View
- c.HTTPResponse被发送到Response Middlewares
- d.任何Response Middlewares都可以丰富response或者返回一个完全不同的response
- e.Response返回到浏览器,呈现给用户
url() 函数
Django url() 可以接收四个参数,分别是两个必选参数:regex、view 和两个可选参数:kwargs、name,接下来详细介绍这四个参数。
- regex: 正则表达式,与之匹配的 URL 会执行对应的第二个参数 view。
- view: 用于执行与正则表达式匹配的 URL 请求。
- kwargs: 视图使用的字典类型的参数。
- name: 用来反向获取 URL。
Django项目部署
在前面的介绍中我们使用 python manage.py runserver 来运行服务器。这只适用测试环境中使用。
正式发布的服务,我们需要一个可以稳定而持续的服务器,比如apache, Nginx, lighttpd等,本文后续将以 Nginx 为例。
设置用自己的iP地址访问项目
- 1.首先需要执行>manage.py runserver 0.0.0.0:8000。
- 2.在setting.py里面需要添加ALLOWED_HOSTS=”*”。
学习资料
http://www.ziqiangxuetang.com/django/django-tutorial.html
Python进阶(三十七)-Windows7使用nginx+apache部署django项目
Django的部署可以有很多方式,采用nginx+uwsgi的方式是其中比较常见的一种方式。
目前国内各大门户网站已经部署了nginx,如新浪、网易、腾讯等;国内几个重要的视频分享网站也部署了nginx,如六房间、酷6等。新近发现nginx 技术在国内日趋火热,越来越多的网站开始部署nginx。
相比apache、iis,nginx以轻量级、高性能、稳定、配置简单、资源占用少等优势广受欢迎。
在这种方式中,我们的通常做法是,将nginx作为服务器最前端,它将接收WEB的所有请求,统一管理请求。nginx把所有静态请求自己来处理(这是nginx的强项)。然后,nginx将所有非静态请求通过uwsgi传递给Django,由Django来进行处理,从而完成一次WEB请求。
可见,uwsgi的作用就类似一个桥接器。起到桥梁的作用。
Linux的强项是用来做服务器,但是自己的项目是在windows7系统下完成的,索性就在windows系统下完成项目部署。
但是,uwsgi并没有适合Windows的安装版本。因为os.uname()这个function在Windows版本中是没有的,所以Windows中uwsgi目前应该是无法安装的。
在使用pip install uwsgi命令安装uwsgi时,出现了以下错误提示。
pip install uwsgi 安装不成功 提示 ‘module’ object has no attribute ‘uname’

遂决定使用下载安装包的方式进行安装。下载地址:
https://pypi.Python.org/pypi/uWSGI/。自己下载的uwsgi版本为2.0.15。
下载完成后,进行解压。在Dos窗口切换至解压目录,然后执行python setup.py install命令。但是仍然出现了上面的错误信息,错误提示信息如下。

Python(python3.4.3)的文档中明确说明os.uname()只适用于Unix,并不适用于Windows,想安装uwsgi还是使用Linux吧。这下心塞了~
nginx安装
首先,到nginx官网(http://nginx.org)上下载相应的安装包,下载完成后进行解压。自己下载的版本为1.12.0。
然后,进入window的cmd窗口,输入如下图所示的命令,进入到nginx目录,使用“start nginx.exe ”进行nginx的启动。若启动成功的话,会在任务管理器中看到“nginx.exe”进程,如下图所示:
在浏览器地址栏输入:127.0.0.1(或localhost):8088,会看到如下图所示的nginx欢迎界面。
注意,此时,我在浏览器中输入的是localhost:8066,因为我修改了其config目录下nginx.conf配置文件内容,修改后的内容如下:
相信大家看到配置文件之后,就会明白其具体配置含义了。这里不再进行详细介绍。
其他相应的命令:

- nginx.exe -s stop //停止nginx
- nginx.exe -s reload //重新加载nginx
- nginx.exe -s quit //退出nginx
- 1
- 2
- 3
注:以上的命令中,.exe可以去掉。
至此,nginx安装完成。
继续折腾,发现nginx+fastcgi是可行的,遂决定实践。
初识fastcgi
CGI全称是“公共网关接口”(Common Gateway Interface)。它可以用任意语言编写,只要这种语言具有标准输入、输出和环境变量。如php,perl,tcl等,但它为人诟病的会在每次运行事前都要花费时间去fork-and-execute一次,所以便诞生了FastCGI组件,该组件由微软开发。FastCGI像是一个常驻(long-live)型的CGI,它可以一直执行着,只要运行后不会每次都要花费时间去fork-and-execute,还支持分布式的运算,
即 FastCGI 程序可以在网站服务器以外的主机上执行并且接受来自其它网站服务器来的请求。下载地址:http://www.iis.net/download/fastcgi很明显,使用fastcgi的话,就得使用iis的服务部署方式。似乎越来越有意思了。对于IIS的服务发布方式自己是不感兴趣的,遂决定使用Apache方式部署。
首先下载apache,下载地址:https://www.apachelounge.com/download。下载完成后,进行解压,然后打开相应解压目录下的config配置目录中的httpd.conf配置文件,这是apache服务器的配置文件。主要是将其中的文件目录修改为解压后存放的目录。
修改完成后,在Dos窗口切换至bin目录下,然后执行start httpd.exe命令,这时会打开apache的命令行窗口。

然后在浏览器访问 localhost就可以看到 It works!,证明apache正常工作。

Apche服务器配置好之后,就需要部署项目了。但是后面的过程过于复杂。
经过以上折腾之后,感觉还是在Linux上部署Django比较靠谱,遇到的坑也会比较少。
参考博文
http://blog.csdn.net/largetalk/article/details/8449782
Python进阶(三十八)-数据可视化の利用matplotlib 进行折线图,直方图和饼图的绘制
我用10个国家某年的GDP来绘图,数据如下:
labels = [‘USA’, ‘China’, ‘India’, ‘Japan’, ‘Germany’, ‘Russia’, ‘Brazil’, ‘UK’, ‘France’, ‘Italy’]
quants = [15094025.0, 11299967.0, 4457784.0, 4440376.0, 3099080.0, 2383402.0, 2293954.0, 2260803.0, 2217900.0, 1846950.0]
折线图绘制
首先绘制折线图,代码如下:
- def draw_line(labels,quants):
-
- ind = np.linspace(0,9,10)
-
- fig = plt.figure(1)
-
- ax = fig.add_subplot(111)
-
- ax.plot(ind,quants)
-
- ax.set_title('Top 10 GDP Countries', bbox={'facecolor':'0.8', 'pad':5})
-
- ax.set_xticklabels(labels)
-
- plt.grid(True)
-
- plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
效果图如下图:

柱状图绘制
再画柱状图,代码如下:
- def draw_bar(labels,quants):
-
- width = 0.4
-
- ind = np.linspace(0.5,9.5,10)
-
- # make a square figure
-
- fig = plt.figure(1)
-
- ax = fig.add_subplot(111)
-
- # Bar Plot
-
- ax.bar(ind-width/2,quants,width,color='green')
-
- # Set the ticks on x-axis
-
- ax.set_xticks(ind)
-
- ax.set_xticklabels(labels)
-
- # labels
-
- ax.set_xlabel('Country')
-
- ax.set_ylabel('GDP (Billion US dollar)')
-
- # title
-
- ax.set_title('Top 10 GDP Countries', bbox={'facecolor':'0.8', 'pad':5})
-
- plt.grid(True)
-
- plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
效果图如下图:

饼图绘制
最后画饼图,代码如下:
- def draw_pie(labels,quants):
-
- plt.figure(1, figsize=(6,6))
-
- # For China, make the piece explode a bit
-
- expl = [0,0.1,0,0,0,0,0,0,0,0]
-
- # Colors used. Recycle if not enough.
-
- colors = ["blue","red","coral","green","yellow","orange"]
-
- # autopct: format of "percent" string;
-
- plt.pie(quants, explode=expl, colors=colors, labels=labels, autopct='%1.1f%%',pctdistance=0.8, shadow=True)
-
- plt.title('Top 10 GDP Countries', bbox={'facecolor':'0.8', 'pad':5})
-
- plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
效果图如下图:

附录:完整代码:
- # -*- coding: gbk -*-
-
- import numpy as np
-
- import matplotlib.pyplot as plt
-
- import matplotlib as mpl
-
-
-
- def draw_pie(labels,quants):
-
- # make a square figure
-
- plt.figure(1, figsize=(6,6))
-
- # For China, make the piece explode a bit
-
- expl = [0,0.1,0,0,0,0,0,0,0,0]
-
- # Colors used. Recycle if not enough.
-
- colors = ["blue","red","coral","green","yellow","orange"]
-
- # Pie Plot
-
- # autopct: format of "percent" string;
-
- plt.pie(quants, explode=expl, colors=colors, labels=labels, autopct='%1.1f%%',pctdistance=0.8, shadow=True)
-
- plt.title('Top 10 GDP Countries', bbox={'facecolor':'0.8', 'pad':5})
-
- plt.show()
-
- def draw_bar(labels,quants):
-
- width = 0.4
-
- ind = np.linspace(0.5,9.5,10)
-
- # make a square figure
-
- fig = plt.figure(1)
-
- ax = fig.add_subplot(111)
-
- # Bar Plot
-
- ax.bar(ind-width/2,quants,width,color='green')
-
- # Set the ticks on x-axis
-
- ax.set_xticks(ind)
-
- ax.set_xticklabels(labels)
-
- # labels
-
- ax.set_xlabel('Country')
-
- ax.set_ylabel('GDP (Billion US dollar)')
-
- # title
-
- ax.set_title('Top 10 GDP Countries', bbox={'facecolor':'0.8', 'pad':5})
-
- plt.grid(True)
-
- plt.show()
-
- def draw_line(labels,quants):
-
- ind = np.linspace(0,9,10)
-
- fig = plt.figure(1)
-
- ax = fig.add_subplot(111)
-
- ax.plot(ind,quants)
-
- ax.set_title('Top 10 GDP Countries', bbox={'facecolor':'0.8', 'pad':5})
-
- ax.set_xticklabels(labels)
-
- plt.grid(True)
-
- plt.show()
-
- # quants: GDP
-
- # labels: country name
-
- labels = ['USA', 'China', 'India', 'Japan', 'Germany', 'Russia', 'Brazil', 'UK', 'France', 'Italy']
-
- quants = [15094025.0, 11299967.0, 4457784.0, 4440376.0, 3099080.0, 2383402.0, 2293954.0, 2260803.0, 2217900.0, 1846950.0]
-
- draw_pie(labels,quants)
-
- #draw_bar(labels,quants)
-
- #draw_line(labels,quants)
在博文《Python进阶(二十)-Python爬虫实例讲解》、《Python进阶(十八)-Python3爬虫小试牛刀之爬取CSDN博客个人信息》中讲解了利用urllib、bs4爬取网页信息。下面讲解利用requests和bs4的爬取网页信息。
数据获取
在模拟访问过程中,需要设置好请求头,已达到模拟浏览器访问的效果请求头设置如下:
- #伪装headers
- headers = {
- #伪装成浏览器访问,直接访问的话csdn会拒绝
- 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
- # 若写成'Proxy-Connection':'keep-alive',则CSDN会拒绝访问
- 'Connection': 'keep-alive',
- 'Cache-Control': 'max-age=0',
- 'Upgrade-Insecure-Requests': '1',
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
- 'Referer': 'http://write.blog.csdn.net/postlist/6788536/0/enabled/2',
- 'Accept-Encoding': 'gzip, deflate, sdch',
- 'Accept-Language': 'zh-CN,zh;q=0.8',
- }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
有关请求头的获取,可使用浏览器自带的“开发者工具获取”或利用Fiddler工具,有关Fiddler的详细使用参见博文《Fiddler(一) - Fiddler简介》、《Fiddler(二) - 使用Fiddler做抓包分析》、《Python进阶(三十五)-Fiddler命令行和HTTP断点调试》。
使用requests访问网站时语句特别简洁,如下:
- #构造请求,访问页面
- response = requests.get(myUrl,headers=headers)
- 1
- 2
其中,response即为访问返回结果。获取到结果之后requests的使用至此结束。然后就是使用bs4进行文档解析了。代码如下:
- # 创建BeautifulSoup对象
- response.encoding = 'utf-8'
- soup = BeautifulSoup(response.text, "html.parser")
- 1
- 2
- 3
下面以获取博客访问信息为例,首先参照网页源码获悉页面元素布局。
bs4解析代码如下:

- # 获取<ul id="blog_rank">
- ul = soup.find('ul', {'id': 'blog_rank'})
- # 获取所有的li
- lists = ul.find_all('li')
- # 对每个li标签中的内容进行遍历
- for li in lists:
- # 找到访问总量
- data = li.find('span').string
- # print(type(data))
- if data is None:
- # http://c.csdnimg.cn/jifen/images/xunzhang/jianzhang/blog8.png
- src = dict(li.find('img', {'id': 'leveImg'}).attrs)['src']
- # 52
- # print(src.index('blog'))
- # print(src[56])
- data = src[56]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在获取等级时,需要进行特殊处理。
模拟登录
在获取粉丝数量时,首先要模拟用户登录.
采用python模拟登录CSDN的时候分为三步走:
1.获取url=https://passport.csdn.net/account/login;
2.分析登录信息:从网页中得到username,password和hideen标签隐藏的属性,在CSDN中有三个隐藏标签,lt,execution,_eventId //注意这三个标签是动态的。同时注意到表单使用post提交方式。
3.下面使用post方式实现表单提交操作,代码如下:

- import re
- import requests
- url = "https://passport.csdn.net/account/login"
- head = {
- "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36",
- }
- Username = "***"
- PassWord = "***"
- s = requests.session()
- r = s.get(url,headers=head)
- lt_execution_id = re.findall('name="lt" value="(.*?)".*\sname="execution" value="(.*?)"', r.text, re.S)
- payload = {
- "username": Username,
- "password": PassWord,
- "lt" : lt_execution_id[0][0],
- "execution" : lt_execution_id[0][1],
- "_eventId" : "submit"
- }
- r2 = s.post(url,headers=head,data=payload)
- print(r2.text) #登录成功会返回一段loginapi.js的脚本
- print("*"*100) #分隔符
- r3 = s.get("http://my.csdn.net",headers=head)
- print(r3.text) #成功获取"我的主页"源代码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
程序运行结果如下:


bs4解析
接下来使用bs4解析出粉丝数量及个人信息。
- def craw_csdn(self, response):
- # 创建BeautifulSoup对象
- response.encoding = 'utf-8'
- soup = BeautifulSoup(response.text, "html.parser")
- # 按照标准的缩进格式的结构输出
- # print(soup.prettify())
- # 获取body部分
- body = soup.body
- # <dd class="focus_num"><b><a href='/my/follow' target=_blank>5</a></b>关注</dd>
- focus = soup.find('dd', class_='focus_num').find('a').string
- print("关注:" + str(focus))
- # <dd class="fans_num"><b><a href='/my/fans' target=_blank>1374</a></b>粉丝</dd>
- fans = soup.find('dd', class_='fans_num').find('a').string
- print("粉丝:" + str(fans))
- # <dt class="person-nick-name">
- # <span>***</span> </dt>
- nick_name = soup.find('dt', class_='person-nick-name').find('span').string
- print("昵称:" + str(nick_name))
- # <dd class="person-detail">
- # 计算机软件<span>|</span>研究生<span>|</span>***<span>|</span>中国-**省-**市<span>|</span>男<span>|</span>19**11-11 </dd>
- # <dd class="person-sign">No Silver Bullet.</dd>
- person_detail = soup.find('dd', class_='person-detail').contents
- # print(len(person_detail))
- len_person_detail = len(person_detail)
- pd = []
- #代表从0到5,间隔2(不包含5)
- for i in range(0,len_person_detail,2):
- # print(person_detail[i])
- if i == 0:
- pd.append(person_detail[i].lstrip(' \n \t\t'))
- else:
- pd.append(person_detail[i])
- print("个人信息:" + str(pd))
- return int(fans)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
爬取结果如下图所示:

总结
以上实现了利用requests结合bs4获取博客信息,同时实现了模拟用户登录获取粉丝数量,至于具体采集应用大家就请自行发挥吧。有关requests及bs4的其他具体应用详见参考资料。
附 string查找 && range
string查找
python的string对象没有contains方法,不用使用string.contains的方法判断是否包含子字符串,但是python有更简单的方法来替换contains函数。
方法1:使用 in 方法实现contains的功能:
- site = 'http://www.jb51.net/'
- if "jb51" in site:
- print('site contains jb51')
- 1
- 2
- 3
输出结果:site contains jb51
方法2:使用find函数实现contains的功能
- s = "This be a string"
- if s.find("is") == -1:
- print ("No 'is' here!")
- else:
- Print("Found 'is' in the string.")
- 1
- 2
- 3
- 4
- 5
range()
- # [1, 2, 3, 4]
- range(1,5) #代表从1到5(不包含5)
- # [1, 3]
- range(1,5,2) #代表从1到5,间隔2(不包含5)
- # [0, 1, 2, 3, 4]
- range(5) #代表从0到5(不包含5)
- 1
- 2
- 3
- 4
- 5
- 6

