
热门标签
当前位置: article > 正文
机器学习数据常见问题(文本数据)解决方法全在这了,快来学啊!_机器学习出现出错 shuzishibie (第 11 行) [xtrain,labeltrain]
作者:我家自动化 | 2024-07-20 06:04:30
赞
踩
机器学习出现出错 shuzishibie (第 11 行) [xtrain,labeltrain] = processmnistda
数据集常见问题汇总:
从网上下的机器学习代码,用别人的示例数据可以运行,自己按照格式修改的数据就是有bug,那么为什么呢?今天就带你解决!
1.数据集中存在重复值:
如果数据集中存在重复值,那么数据在进行运算的时候如果选中了两个重复数据,就会导致提取的特征被舍弃一个,从而出现bug.
可以用excel的重复值删除功能进行重复值的去除.

2.数据格式不对:
excel数据集选中所有数据,然后更改数据类型,将其改为数字,你以为就可以了.
但是其实这样改完可能还是文本数据,最可靠的方法是给所有的数据乘上一个1,会自动转为数字.
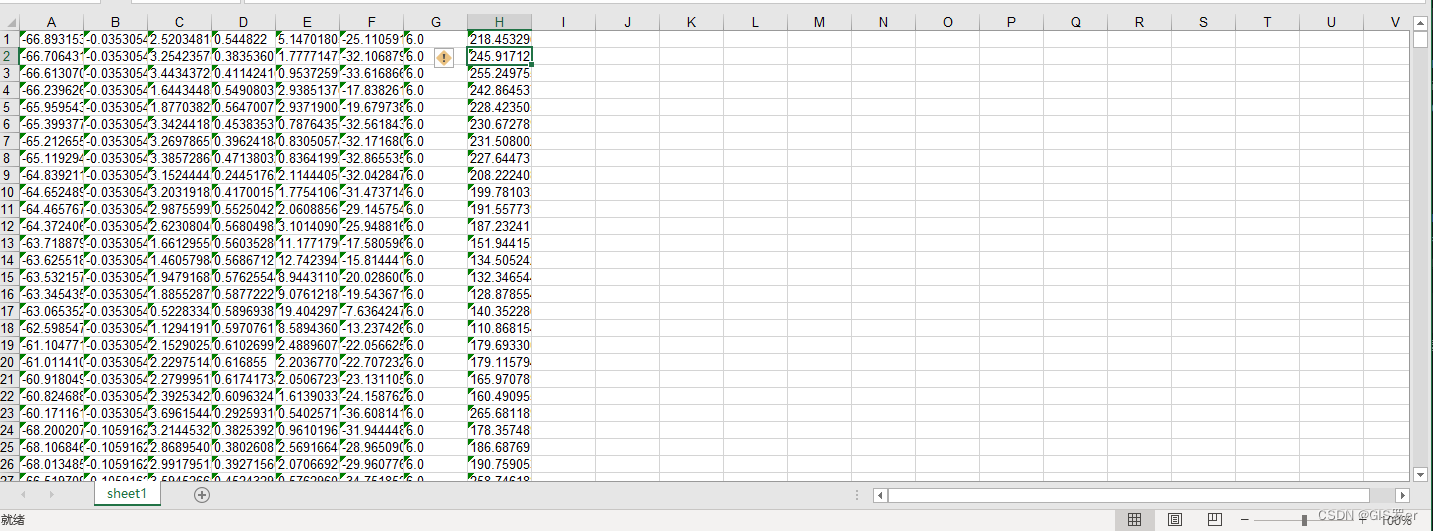
左上角有三角形证明仍然是文本.
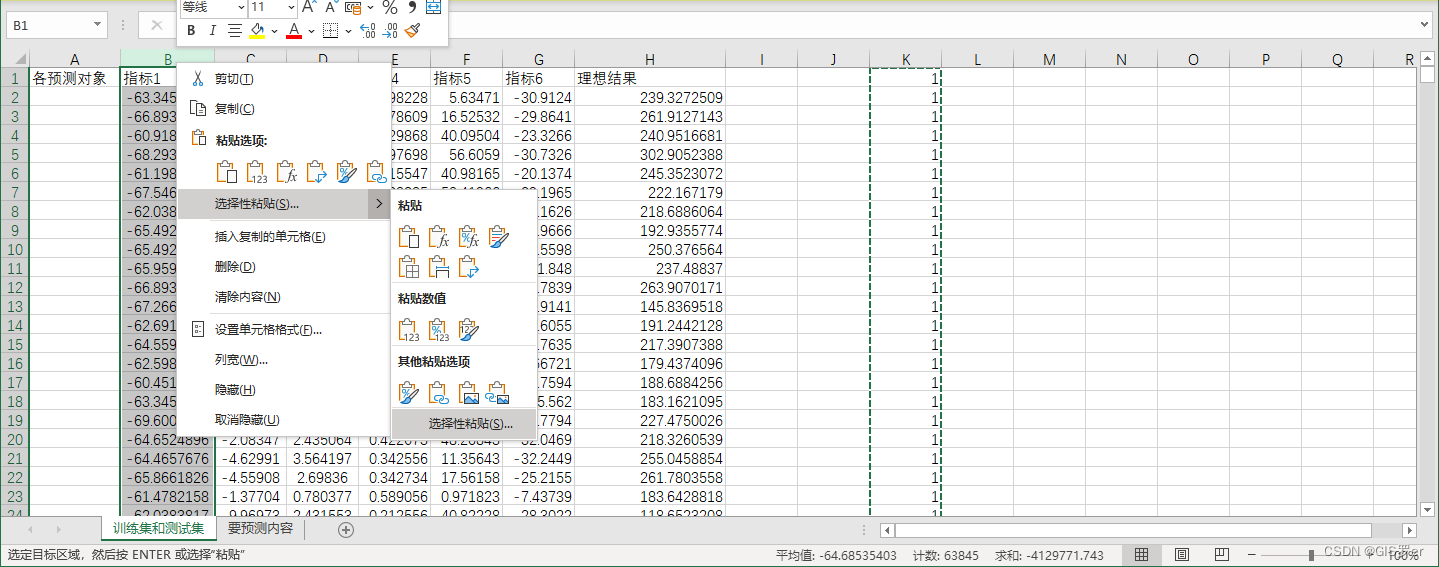
采用选择性粘贴,选择相乘,可以给每个数据乘一,从而转为数字类型.
3.数据按序排列:
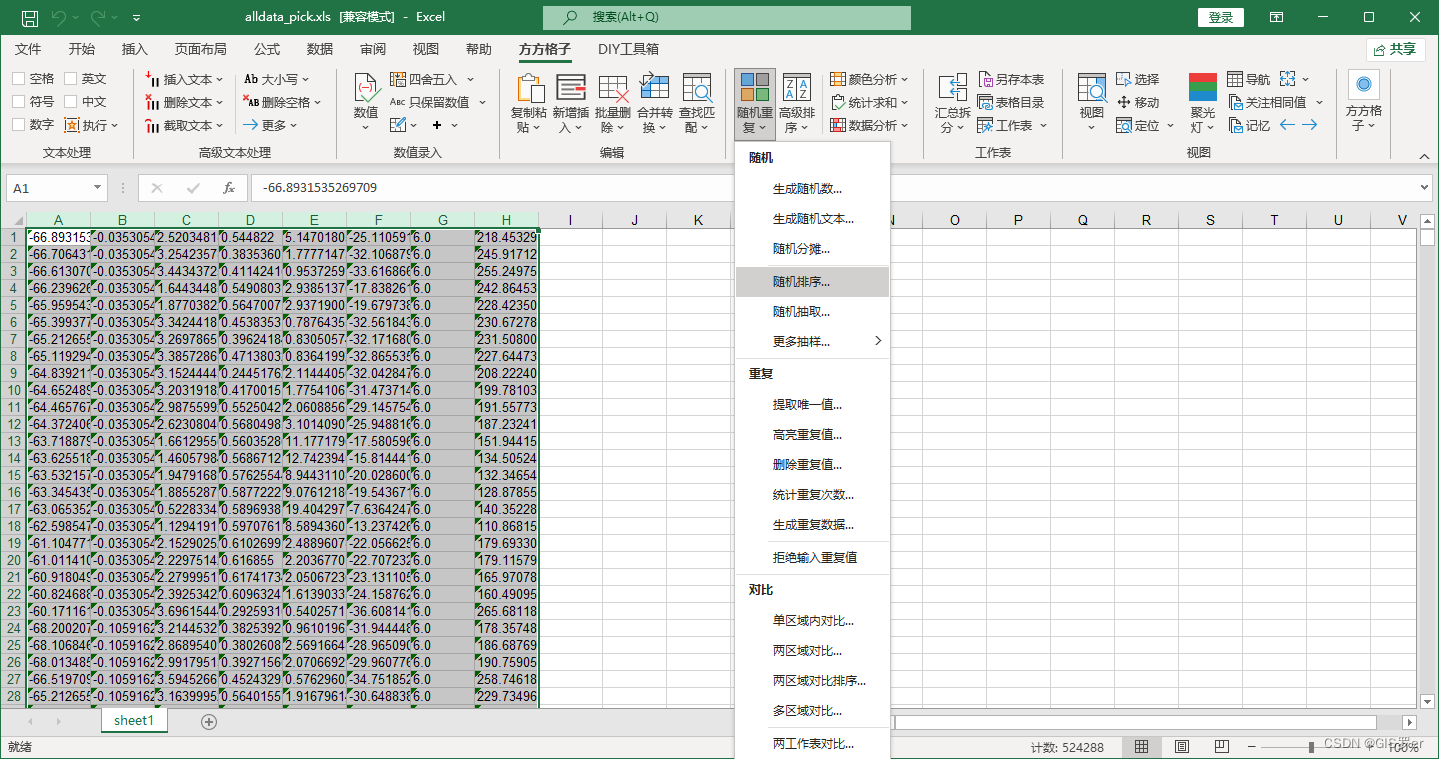
数据按顺序排列,会让上下的数据之间存在大小关系,用上部分数据训练下半部分往往会导致训练精度低,让每行数据重新随机排序会提高精度.
这个需要安装一个插件.
ps:最好用示例数据的格式来格式刷一下,以防其他隐藏bug.
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

