
- 1Redis客户端之Redisson(二)Redisson组件_redissonclient
- 2Spark数据读取和创建_spark创建sc
- 3使用JMeter进行Apache Kafka负载测试_jmeter kafka
- 4[Python学习日记] 文件与文件系统(一)_python 日记文件系统
- 5华为路由器命令配置大全,看完赶快收藏_华为路由器配置常用命令
- 6前端技术岗,阿里 P7、百度 T6、腾讯 T3.1 的要求是怎样的?_t3前端啥水平
- 7【递归模板】常用递归JavaScript写法模板
- 8mysql sql执行过程_MySql一条语句执行的过程
- 9MacOS Mojave(苹果14系统) v10.14.6中文离线安装包_macos mojave下载
- 10预习 01 | 大数据技术发展史:大数据的前世今生_谷歌 最先提出 大数据
多模态(clip/ALBEF)
赞
踩
一. CLIP
1. clip的核心思想是通过海量的弱监督文本对通过对比学习,将图片和文本通过各自的预训练模型获得的编码向量在向量空间上对齐。
clip 的text encode:
在Text Encoder中,我们会对每个句子增加一个Class Token,用于整合特征,以一个固定长度向量来代表输入句子。一般的Bert会将Class Token放在第0位,也就是最前面。而在CLIP中,Class Token被放在了文本的最后。
参考:多模态模型学习1——CLIP对比学习 语言-图像预训练模型_学习_Bubbliiiing-GitCode 开源社区
二. ALBEF 先对齐,再融合
ALBEF 解决了多模态领域中图像和文本对齐、交互的问题。在 ALBEF 之前,多模态方法通常使用 transformer 的多模态编码器来同时编码视觉和文本特征,由于目标检测器是提前训练好的,因此视觉和文本特征并不是对齐的。图像和文本特征可能距离很远,这使得多模态编码器难以学习到它们之间的交互。为了解决这个问题,ALBEF 通过一个对比损失(也就是 CLIP 中的 ITC 损失)在进行多模态交互之前对齐图像和文本数据。
网上爬取的大量图文对通常噪声很大(图文不匹配)。ALBEF 采用动量蒸馏(momentum distillation)的自训练方法来从网络图文对数据中学习,以缓解原始数据中的噪声问题。从理论上讲,ALBEF 通过互信息最大化的角度解释了不同的多模态任务,说明不同任务实际上为图文对提供了不同的视角,类似于数据增强,使得训练得到的多模态模型能够理解不同模态下的语义,具备语义保持的能力。
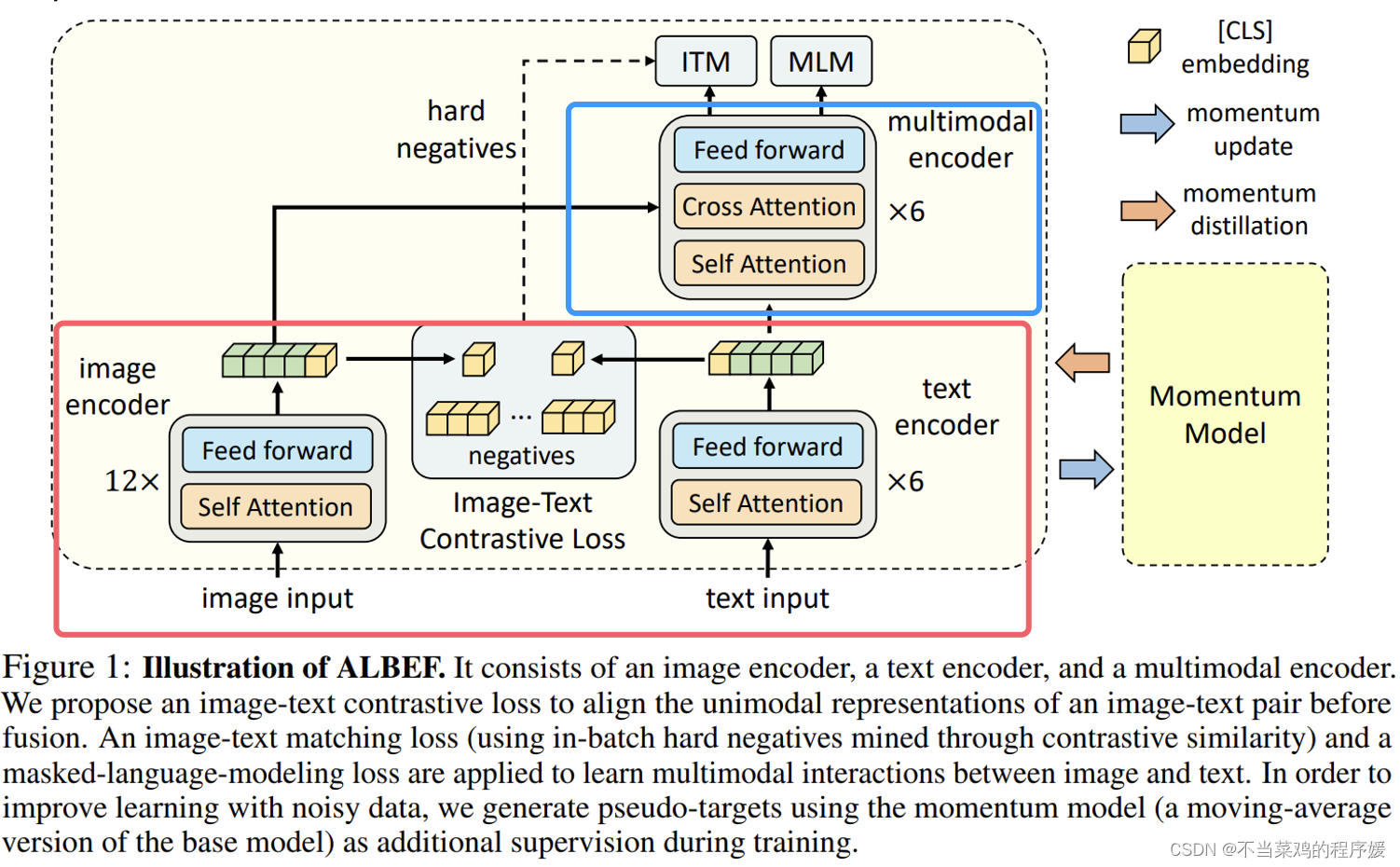
- 下面红色框其实就类似于 CLIP,双塔各自编码图像和文本,然后取 CLS 进行对比学习;
- 上面蓝色框就是为了加强不同模态交互用的编码器(前面提到过 CLIP 内积的方式太简单了,这里就是加强多模态融合以适配更难的任务);
- 图像编码器 12 层,文本编码器 6 层,多模态编码器 6 层;其实右侧是将一个 12 层的文本编码器拆成了两部分,这是因为一些研究工作发现在多模态中需要更强的图像编码器,进行这样的拆分一定程度上保证了强图像 encoder 和弱文本 encoder,且保证了模型参数不过多的情况下融合图像和文本的信息。
训练的目标函数:
ITC loss,这个跟 CLIP 是一样的:

ITM Loss,
在 ITM 任务中,模型需要判断一对图像和文本是否匹配。为了实现这一目标,论文使用多模态编码器输出的[CLS] token 的嵌入作为图像-文本对的联合表示,并通过一个全连接层和 softmax 函数来预测一个二分类的概率。由于判断 batch 内的负样本过于简单,文章提出通过 ITC loss 计算得到的各样本间的余弦相似度,取除正样本外相似度最高的作"hard negatives"。

MLM Loss ,
MLM loss,mask 掉一些文本,然后将 mask 过后的文本和图片一起通过 ALBEF 模型,预测 mask 掉的文本。因此,ALBEF 的每一轮迭代需要经过两次前向传播的过程。多模态学习的方法通常训练时长较长,就是因为需要进行多次前向传播,计算不同的损失。
总体Loss(不动量):
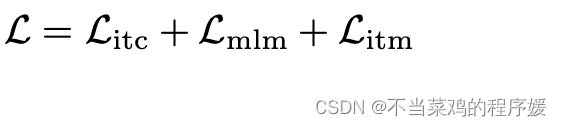
每次迭代前向传播的次数:2
- ALBEF 这里计算 ITC 和 ITM 的时候使用的是图像和原始文本,需要进行一次前向传播
- 计算 MLM loss 是使用的是图像和 mask 后的文本,还需要进行一次前向传播
- 多模态任务很多模型都需要多次的前向传播,满足各种条件,所以一般训练时间都比较长
动量蒸馏:
为什么要做动量蒸馏:
- 爬取的图像文本对通常不是很匹配,会导致计算 loss 的时候会有偏差,因为可能比所谓的 gt 匹配更优的负样本,所以 one-hot label 这种 gt 方式(就是一个图像对应一个描述,其他都是负样本描述,或者一个 mask 中只能填一个单词)对 ITC 和 MLM 都不是很好,因为有的负样本也包含了很多好的信息,一味的惩罚这些负样本也不好
- 所以,如果能找到额外的监督信号,最好是 multi-hot 或另外一个模型的输出就更好的,作者先构建一个 momentum model ,来生成一个 pesudo-label,这个 pseudo targets 其实不是一个 one-hot 向量,而是 softmax score。
- 动量模型就是在已有模型之上进行指数移动平均(EMA),希望在训练原始 model 的时候,不只希望预测结果和原始输入(one-hot)很接近,还希望预测结果从动量模型的输出很接近,在一般情况下从 gt one-hot label 中学,如果 one-hot label 是 noisy 的时候或者是错的时候,模型能从动量模型中学习到一些改进。
通过保持一个模型的动量版本来生成伪标签,作为额外的监督信号进行训练。
- 使用基础模型的参数的指数移动平均版本作为动量模型
- 使用动量模型生成的伪标签(是个分布)进行训练
- 主模型的预测既要跟 one-hot 标签尽可能接近之外,也要跟 pseudo-targets 尽可能接近(KL 散度)
三.VLMO: 灵活才是王道
VLMo 模型通过使用混合模态专家(MoME)Transformer 实现了统一的视觉-语言预训练。MoME Transformer 的结构设计允许根据输入信号的不同使用对应的 FFN 层参数进行计算。具体来说,VLMo 模型包括了视觉专家(V-FFN)、文本专家(L-FFN)和图文专家(VL-FFN),它们分别用于处理图像、文本和图像-文本输入。这种灵活的设计使得VLMo 模型能够根据任务的不同使用不同的结构进行训练和推理。
四.BLIP:理解、生成我都要
文章的研究动机:
- 现有的预训练模型通常在理解型任务或生成型任务中表现出色,但很少有模型能够同时在这两种任务上达到优秀的性能。
- 现有的性能改进主要是通过扩大数据集规模并使用从网络收集的带有噪声的图像-文本对进行训练实现的。然而,网络数据集中的噪声会对模型的性能产生负面影响。
主要的贡献:
- 统一了图像-语言的理解与生成任务
- Bootstrap 的方式清洗网络噪声数据
在模型的设计上结合了 ALBEF 和 VLMo,看下图中红色框中就类似 ALBEF,只是画 image-grounded text encoder 的位置不同;蓝色框中类似 VLMo,虽然有三个模型,但是大部分参数都是共享的。
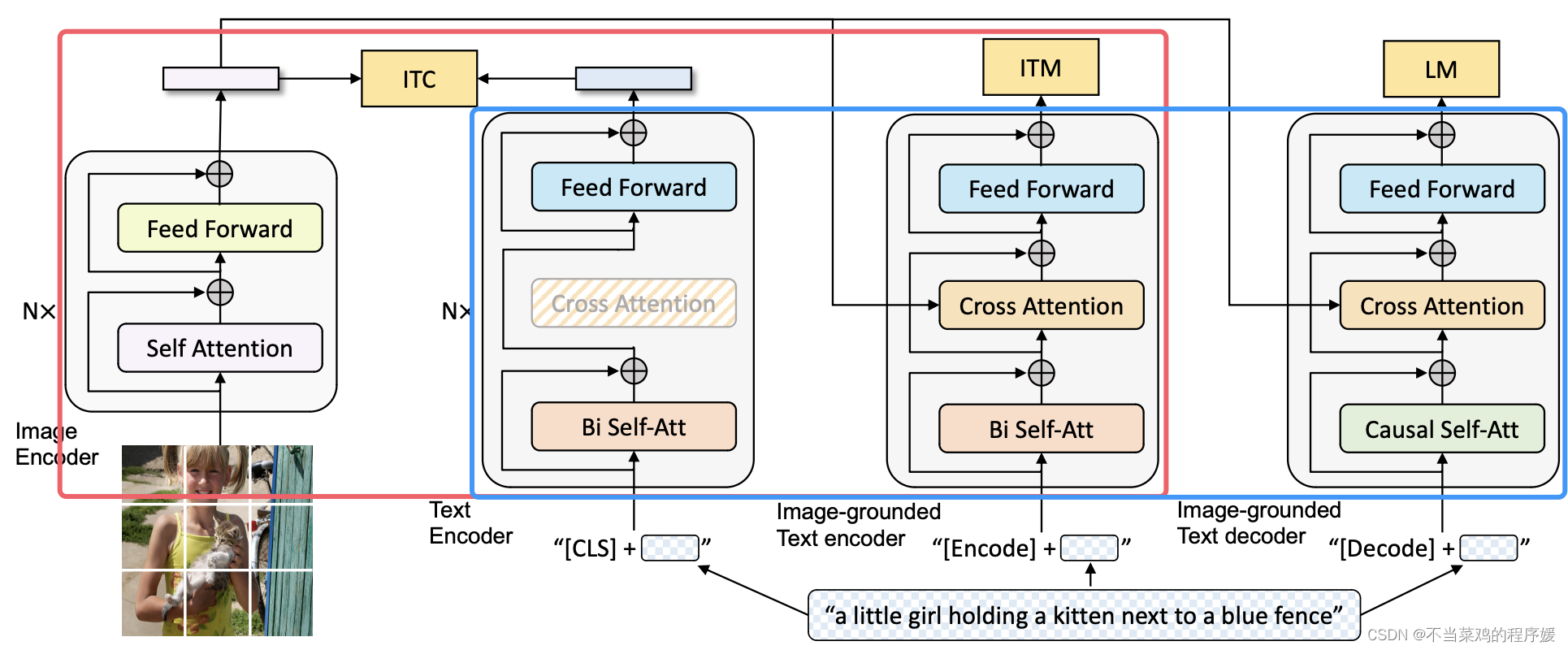
- 左一为 Image Encoder(图像编码器):该组件使用 Vision Transformer(ViT)对图像进行编码,将全局图像特征表示为一个额外的[CLS]标记。
- 左二为 Text Encoder,采用了 BERT 的结构,提取文本特征用于与视觉特征计算 ITC loss。Text Encoder 不与视觉特征计算交叉注意力。
- 左三为 Image-grounded Text Encoder(基于图像的文本编码器),该组件通过在每个 Transformer 块的自注意力(Self-Attention)层和前馈神经网络(Feed Forward Network)之间插入一个交叉注意力(Cross-Attention)层,将视觉信息注入到文本编码中,提取文本特征用于计算 ITM 损失。
- 左四为 Imagegrounded Text Decoder(基于图像的文本解码器),用于进行 LM 语言建模训练(这里不再是用 MLM 了),生成与图像相关的文本描述。
- 三个文本编解码器分别为在文本前添加 [CLS]、[Encode]、[Decode] token
- 与 ALBEF 一样,同样采用动量模型为 ITC 生成伪标签;使用 ITC 为 ITM 进行难负例挖掘。
BLIP 的训练流程
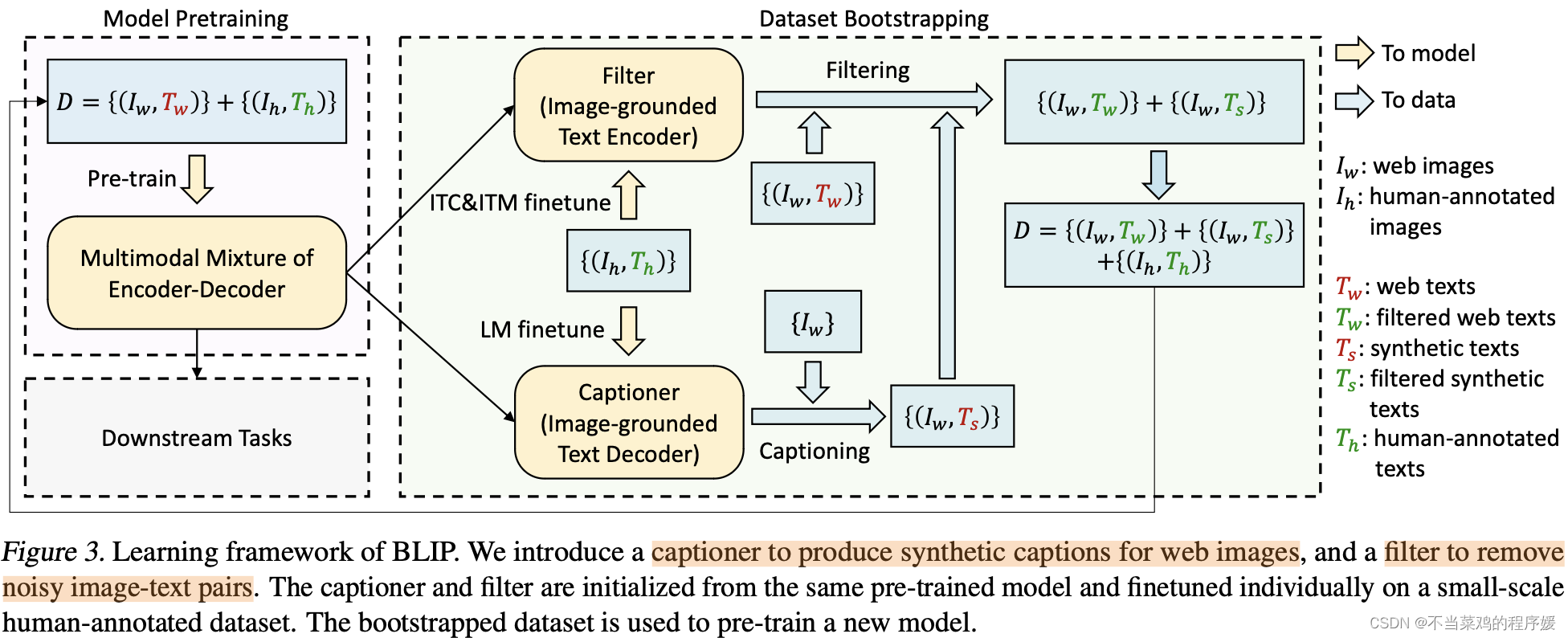
- 使用含噪声的数据训练一个 MED(Multimodal Mixture of Encoder-Decoder)模型;
- 将该模型的 Image-grounded Text Encoder 和 Image-grounded Text Decoder 在人工标注的 COCO 数据集上进行微调,分别作为 Filter 和 Captioner;
- Captioner 根据图像数据生成对应的文本描述;
- Filter 对噪声较大的网络数据和生成数据进行过滤清洗,得到较为可靠的训练数据;
- 再根据这些可靠的训练数据,训练更好的 MED 模型,从而实现 bootstraping 训练。
五.BLIP2:将图像特征对齐到预训练语言模型
BLIP-2 通过在冻结的预训练图像编码器和冻结的预训练大语言模型之间添加一个轻量级 查询 Transformer (Query Transformer, Q-Former) 来弥合视觉和语言模型之间的模态隔阂。在整个模型中,Q-Former 是唯一的可训练模块,而图像编码器和语言模型始终保持冻结状态。
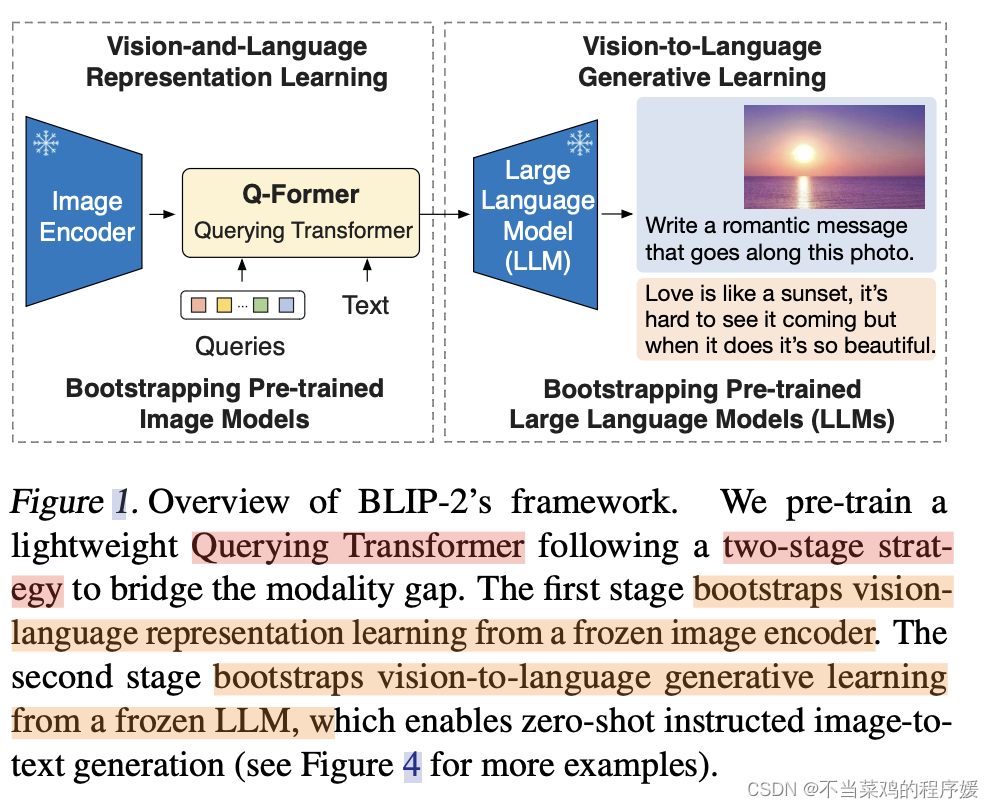
Q-Former 由两个子模块组成,这两个子模块共享相同的自注意力层:
- 与冻结的图像编码器交互的图像 transformer,用于视觉特征提取
- 文本 transformer,用作文本编码器和解码器
图像 transformer 从图像编码器中提取固定数量的输出特征,这里特征的个数与输入图像分辨率无关。同时,图像 transformer 接收若干查询嵌入作为输入,这些查询嵌入是可训练的。这些查询还可以通过共享的自注意力层与文本进行交互。
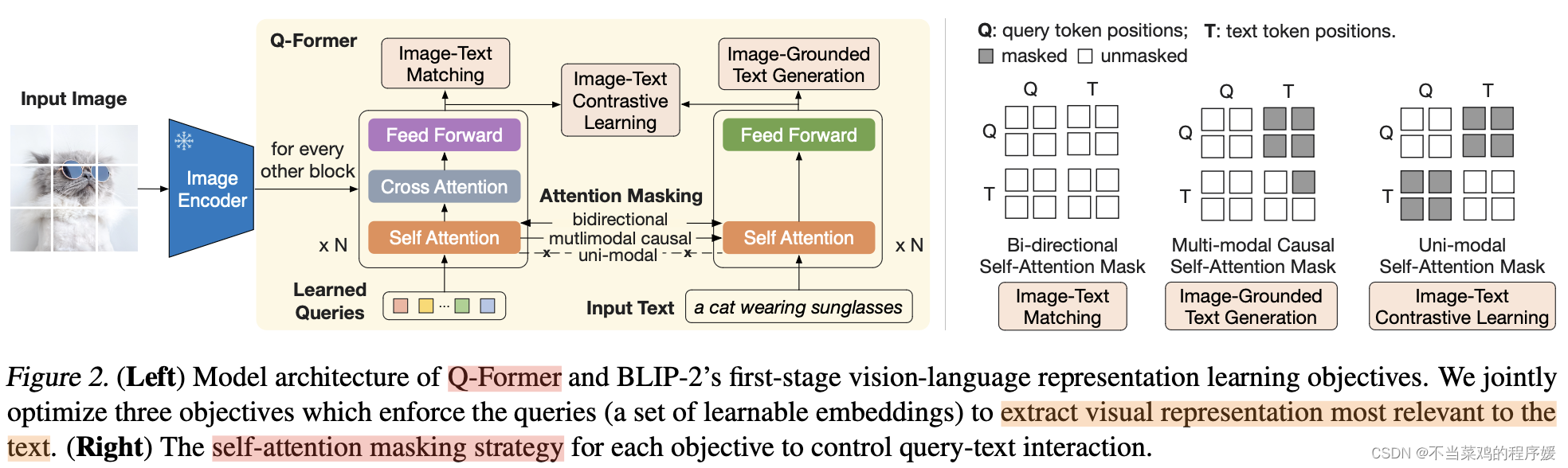
Q-Former 分两个阶段进行预训练。第一阶段,图像编码器被冻结,Q-Former 通过三个损失函数进行训练:
- ITC loss
- ITM loss
- Image-grounded Text Generation (ITG) loss:用于训练 Q-Former 模型在给定输入图像条件下生成文本。在注意力机制上,queries 之间互相可见但是不能看到文本 token,而文本 token 可以看到所有的 queries 以及它之前的文本 token。此外将 CLS token 替换为 DEC token 以便提示模型进行解码任务。
通过第一阶段的训练,Query 已经能够理解图片的含义了,接下来就是让 LLM 也能够理解图片信息,因此作者针对两类不同 LLM 设计了不同的任务:
- Decoder 类型的 LLM(如 OPT):以 Query 做输入,文本做目标;
- Encoder-Decoder 类型的 LLM(如 FlanT5):以 Query 和一句话的前半段做输入,以后半段做目标;因为不同模型的 embedding 维度不同,所以这里还加上了一个全连接层
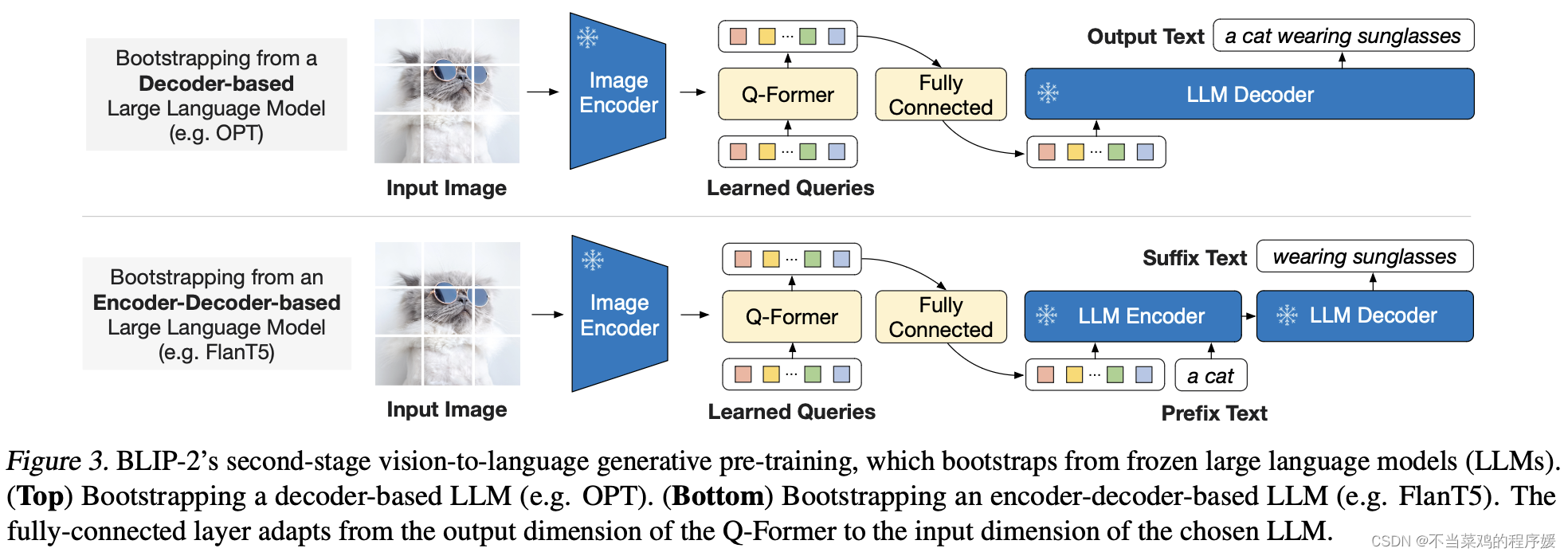
BLIP2 验证了之前的想法,直接利用已经预训练好的视觉、文本模型,通过设计参数量较少的“对齐模块”来实现多模态的对齐。
然而,注意到 BLIP2 在抽视觉特征其实是不考虑文本的;此时也正值 指令微调 在大语言模型中大杀四方,因此进一步的发展方向也就诞生了。
六 nstructBLIP:指令微调大杀四方
InstructBLIP 可以理解为是 BLIP2 + 指令微调
- 作者们收集了 26 数据集并转化指令微调的格式
- 并改进 BLIP2 中的 Query Transformer 为 指令感知的 Query Transformer,能够抽取和给定指令相关的信息
InstructBLIP 的模型结构如下所示:
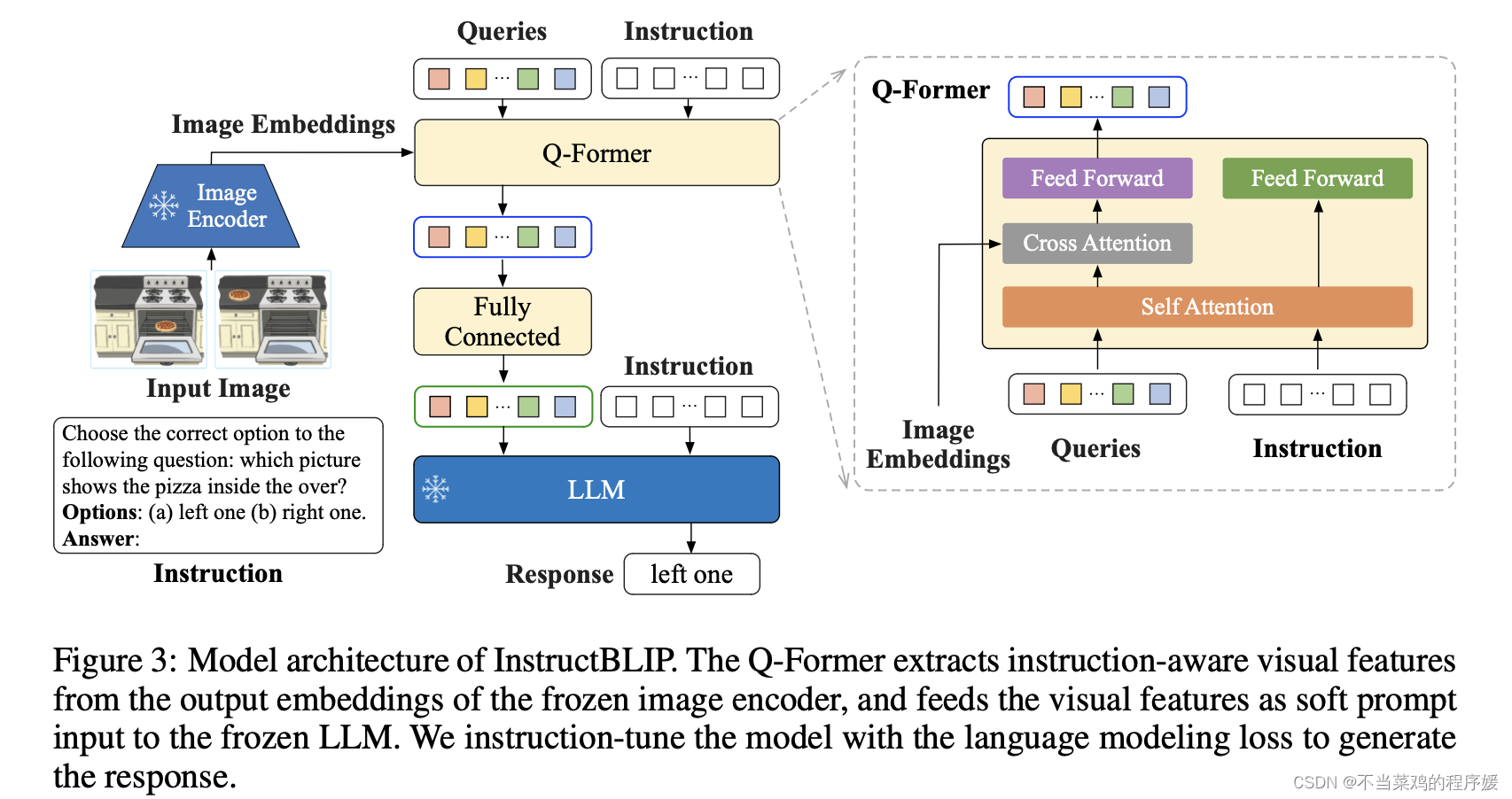
可以看到 Q-Former 的输入部分多了 Instruction,指令可以通过 Q-Former 的自注意力层与查询嵌入进行交互,并鼓励提取与任务相关的图像特征。
InstructBLIP 的架构和 BLIP-2 相似,从预训练好的 BLIP-2 模型初始化,由图像编码器、LLM 和 Q-Former 组成。在指令微调期间只训练 Q-Former,冻结图像编码器和 LLM 的参数。将26个数据集转化成指令微调的格式,把它们分成13个 held-in 数据集用于指令微调,和13个 held-out 数据集用于 Zero-Shot 能力的评估。
后续还没写完,先把前面消化完了再来补写。。。。

