
- 1Git 常用命令汇总大全_git send-email --annotate
- 2分享74个Python管理系统源代码总有一个是你想要的_python管理系统代码
- 3API工具--Apifox和Postman对比(区别)
- 4测试(绿盟)_绿盟dlp测试记录表
- 5linux安装docker
- 6深入理解Seata的四种解决方案_seata 解决什么问题
- 7哈希表、哈希桶数据结构以及刨析HashMap源码中哈希桶的使用_hash bucket
- 8韩国与日本历年GDP总量和人均GDP的对比(1953-2020年)_1960年朝鲜gdp总量
- 9活动报名|揭秘Bengio团队最新评测工作:视觉字幕恢复VCR,现有大模型能否过关?...
- 10云原生敏捷基础设施学习笔记
最新Flink实时数仓同步:快照表实战详解,2024年最新腾讯T3大牛亲自教你_快照和数据合并
赞
踩
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
二、技术选型
在实时同步领域,要实现背景中的需求通常有两种常见的解决方式:
- 实时同步 + 拉链表:
- 拉链表完整记录了整个 binlog 的数据流向,并通过
start_date和end_date字段进行天粒度筛选。 - 可以采用此方式,实现细节可以参考笔者另一篇文章:Flink实时数仓同步:拉链表实战详解。
- 拉链表完整记录了整个 binlog 的数据流向,并通过
- 实时同步 + 快照表:
- 本文主要内容。
- 快照表适用于对数据的历史状态感兴趣,通过实时同步捕获变更事件,并将精确数据写入快照表。
本文主要介绍第二种实现方式:实时同步 + 快照表。
三、技术架构
鉴于业务数据通常存储在关系型数据库中,这里选择采用Flink-CDC持续读取binlog日志进行实时同步。为了保证实时数据能够高效写入下游并支持用户OLAP查询分析,这里选择了企业中常见的MMP库Doris作为实时数仓的存储层。整体架构如下图所示:
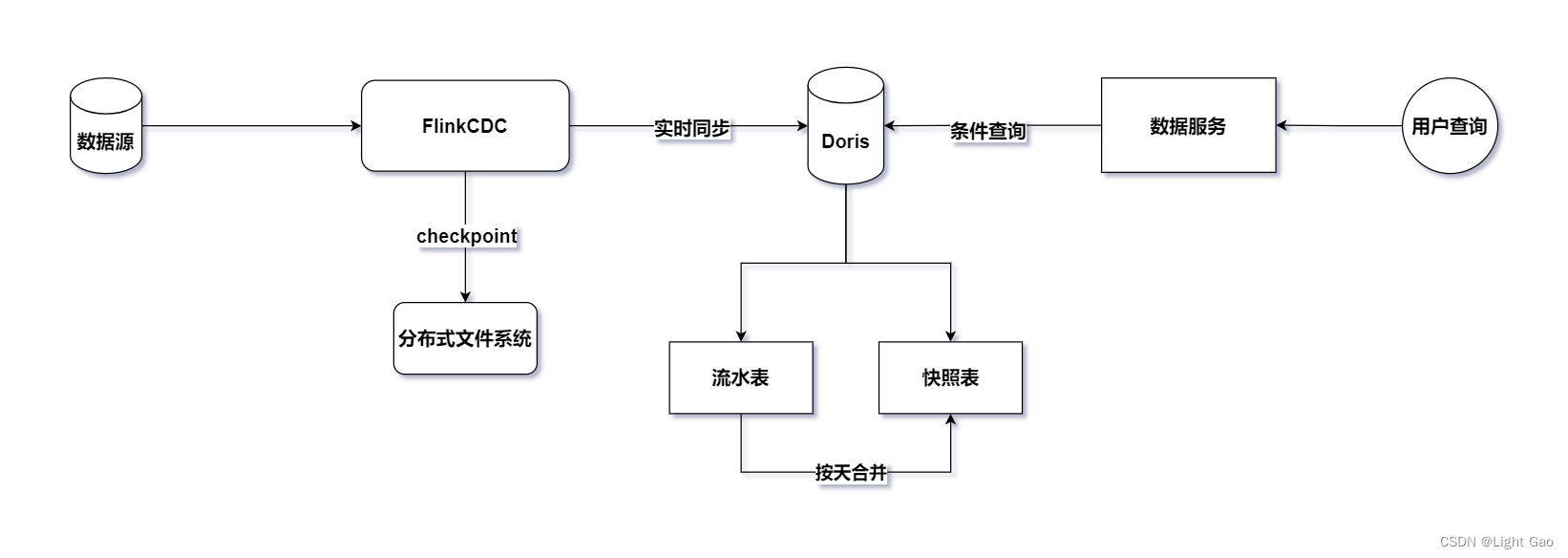
基于上图的设计,引入了一张额外的流水表到 Doris 中。这个设计的目的是为了实现业务的解耦,建立一张专门存储业务数据表的历史变更记录的流水表。这种结构不仅有助于满足当前需求,而且在后续可能出现的其他需求中也更加灵活可扩展。
在实际实现中,可以通过一个 Flink 程序来构建这两张表:流水表和快照表。这种设计模式使得系统更为模块化,同时也方便了后期其他需求的使用。
因此建议读者先阅读笔者另一篇文章:Flink实时数仓同步:流水表实战详解;再回到本文。这样能够更好地理解整个系统设计的背景和实际应用。
四、数据流转过程
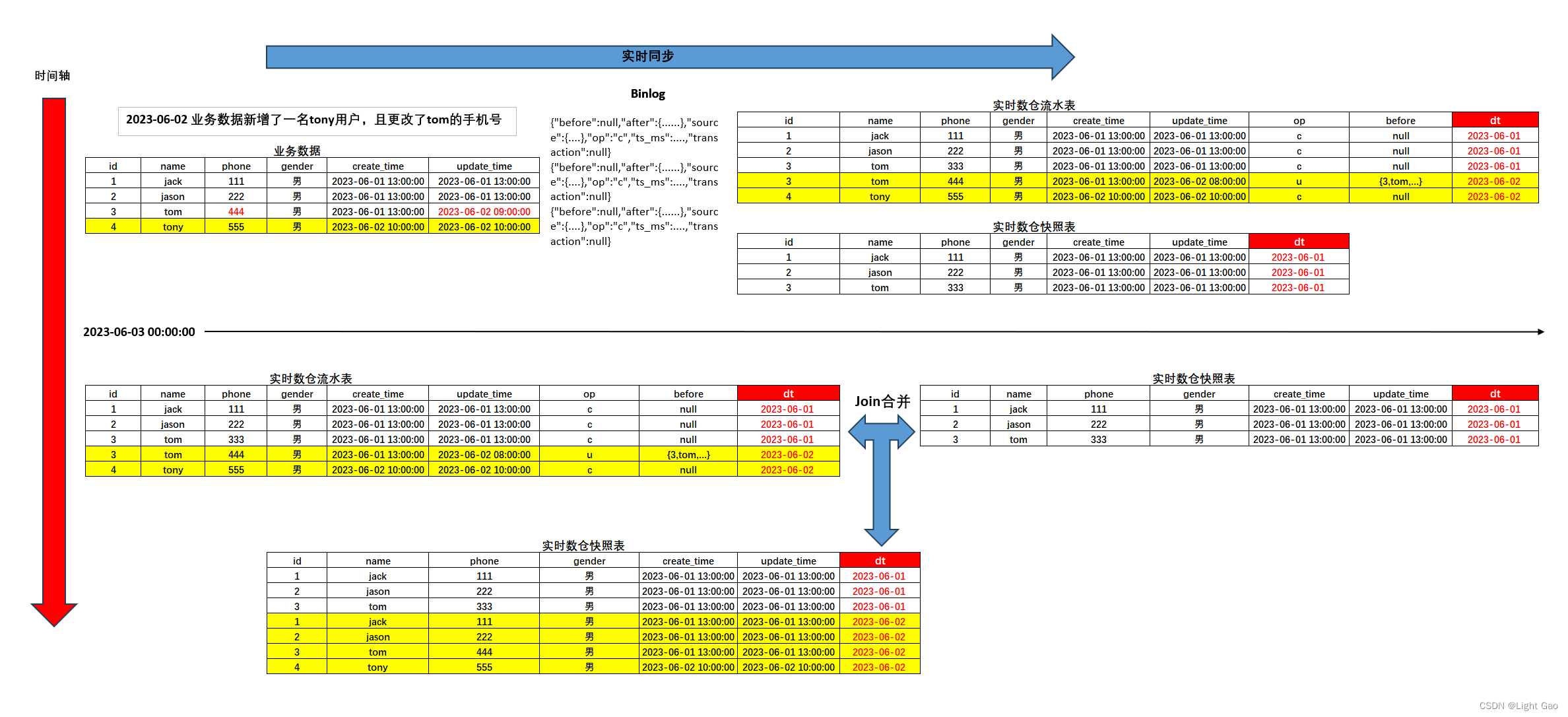
Flink实时同步程序负责处理捕获到的MySQL数据变更事件。在处理流程中,首先将全量数据存储到快照表,然后针对新增(INSERT)、修改(UPDATE)、删除(DELETE)等操作,将其同步至流水表。当符合以下任意一个条件便会触发合并任务:
- 当binlog数据中的日期为第二天。
- 凌晨过了5分钟 [自定义阈值]。
一旦触发合并任务,程序将执行JOIN操作,将流水表前一天数据与快照表中前两天的数据进行整合,最终得到前一天的全量数据,并将其写入至快照表的前一天分区中。这种设计模式既保证了数据的完整性和准确性,又有效地将全量数据存储于快照表中,数据流转过程如下图所示:
五、实时同步+快照表实现
5.1、快照表设计
- 快照表用于存储某个特定时间点的所有数据,通常以天为粒度,相当于对每天的业务数据进行一次全量快照,将当天的全部数据记录下来。举例来说,12号分区中的数据包含了从历史开始一直到11号的全部数据,而13号分区中的数据则包含了从历史一直到12号的全部数据,其余分区以此类推。
- 此处只介绍快照表的设计,关于流水表的建表语句请参考笔者另一篇文章:Flink实时数仓同步:流水表实战详解,此快照表采用了Unique数据模型,建表语句如下:
CREATE TABLE `example\_user\_snapshot` ( `id` largeint(40) NOT NULL COMMENT '用户id', `dt` date NULL COMMENT '流水日期', `name` varchar(50) NOT NULL COMMENT '用户昵称', `phone` largeint(40) NULL COMMENT '手机号', `gender` varchar(5) NULL COMMENT '用户性别', `create\_time` datetime NULL COMMENT '用户注册时间', `update\_time` datetime NULL COMMENT '用户更新时间' ) ENGINE=OLAP UNIQUE KEY(`id`, `dt`) COMMENT '用户快照表' PARTITION BY RANGE(dt)() DISTRIBUTED BY HASH(id) BUCKETS 8 PROPERTIES ( "dynamic\_partition.enable" = "true", "dynamic\_partition.time\_unit" = "DAY", "dynamic\_partition.start" = "-90", "dynamic\_partition.end" = "3", "dynamic\_partition.prefix" = "p", "dynamic\_partition.buckets" = "8" );

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
该表利用了Doris的动态分区功能,将分区粒度设置为天级,并采取了预先建立3天分区的策略,同时设定了90天的过期时间;更多信息可参考Doris动态分区介绍
5.2、实时同步逻辑
5.2.1、前提介绍
-
首先,由于实时流水表同步使用Flink-cdc读取关系型数据库,flink-cdc提供了四种模式: “initial”,“earliest-offset”,“latest-offset”,“specific-offset” 和 “timestamp”。本文使用的Flink-connector-mysq是2.3版本,这里简单介绍一下这四种模式:
initial(默认):在第一次启动时对受监视的数据库表执行初始快照,并继续读取最新的 binlog。earliest-offset:跳过快照阶段,从可读取的最早 binlog 位点开始读取latest-offset:首次启动时,从不对受监视的数据库表执行快照, 连接器仅从 binlog 的结尾处开始读取,这意味着连接器只能读取在连接器启动之后的数据更改。specific-offset:跳过快照阶段,从指定的 binlog 位点开始读取。位点可通过 binlog 文件名和位置指定,或者在 GTID 在集群上启用时通过 GTID 集合指定。timestamp:跳过快照阶段,从指定的时间戳开始读取 binlog 事件。
-
这里采用
initial模式作为实时同步方式,先全量后增量,此外由于实时流水表同步需要对 binlog 数据进行解析及判断更新操作类型,因此,Flink CDC SQL 方式的表建立不再满足我们的要求。为了更好地实现这一功能,我们需要采用 API 方式来构建解决方案,代码如下:
import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema; import com.ververica.cdc.connectors.mysql.source.MySqlSource; public class MySqlSourceExample { public static void main(String[] args) throws Exception { MySqlSource<String> mySqlSource = MySqlSource.<String>builder() .hostname("yourHostname") .port(yourPort) .databaseList("yourDatabaseName") // 设置捕获的数据库, 如果需要同步整个数据库,请将 tableList 设置为 ".\*". .tableList("yourDatabaseName.yourTableName") // 设置捕获的表 .username("yourUsername") .password("yourPassword") .startupOptions(StartupOptions.timestamp(1685548800000L)) // 从2023-06-01零点处读取binlog .deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串 .build(); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置 3s 的 checkpoint 间隔 env.enableCheckpointing(3000); env .fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source") // 设置 source 节点的并行度为 4 .setParallelism(4) .print().setParallelism(1); // 设置 sink 节点并行度为 1 env.execute("Print MySQL Snapshot + Binlog"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
5.2.2、全量同步阶段
- 接下来我们将从全量同步开始逐步演示同步过程,这里我们以2023-06-0日的[Mysql]业务数据为例,此时表数据如下:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
- 此时Flink应用启动获取到的数据如下:仅展示一条
{ "before": null, "after": { # 实际数据 "id": 1, "name": "jack", "phone": "111", "gender": "男", "create\_time": "2023-06-01T05:00:00Z", # 该日期是UTC时间,只需增加8小时即可转化为北京时间 "update\_time": "2023-06-01T05:00:00Z" # 该日期是UTC时间,只需增加8小时即可转化为北京时间 }, "source": { # 元数据 "version": "1.6.4.Final", "connector": "mysql", "name": "mysql\_binlog\_source", "ts\_ms": 0, "snapshot": "false", "db": "yushu\_dds", "sequence": null, "table": "user", "server\_id": 0, "gtid": null, "file": "", "pos": 0, "row": 0, "thread": null, "query": null }, "op": "r", # 记录每条数据的操作类型[重要] "ts\_ms": 1705471382867, "transaction": null }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
-
在我们使用 Flink CDC MySQL 同步数据时,默认采用
initial模式,这意味着首先进行全量同步,然后再进行增量同步。因此,在区分全量和增量同步时,关键在于观察获取到的数据中的op字段。op字段是用来记录每条数据的操作类型的标志。具体的操作类型如下:op=d代表删除操作op=u代表更新操作op=c代表新增操作op=r代表全量读取,而不是来自 binlog 的增量读取
-
在 Flink 程序中,只需要通过
op=r即可筛选出全量数据。在全量数据同步阶段只需将op=r的业务数据直接同步至快照表(之所以全量数据同步至快照表是为了次日凌晨与流水表变更数据合并成完整数据),流水表在全量阶段无需同步,导入语句如下:
INSERT INTO example_user_snapshot (id, dt, name, phone, gender, create_time, update_time)
VALUES
(1, '2023-06-01', 'jack', 111, '男', '2023-06-01 13:00:00', '2023-06-01 13:00:00'),
(2, '2023-06-01', 'jason', 222, '男', '2023-06-01 13:00:00', '2023-06-01 13:00:00'),
(3, '2023-06-01', 'tom', 333, '男', '2023-06-01 13:00:00', '2023-06-01 13:00:00');
- 1
- 2
- 3
- 4
- 5
- 6
- 此时doris快照表数据如下所示:
| id | dt | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|---|
| 1 | 2023-06-01 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | 2023-06-01 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | 2023-06-01 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
- 此时doris流水表数据如下所示:全量阶段流水表无需同步
| id | update_time | dt | create_time | name | phone | gender | op | before | binlog |
|---|---|---|---|---|---|---|---|---|---|
| NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
5.2.3、增量同步阶段
- 这里我们以2023-06-02日的[Mysql]业务数据为例,新增了一名tony用户,且更改了tom的手机号,此时表数据如下:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | tom | 444 | 男 | 2023-06-01 13:00:00 | 2023-06-02 09:00:00 |
| 4 | tony | 555 | 男 | 2023-06-02 10:00:00 | 2023-06-02 10:00:00 |
- 此时Flink应用获取到的数据如下:
# 新增tony变更数据如下 { "before": null, "after": { "id": 4, "name": "tony", "phone": "666", "gender": "男", "create\_time": "2023-06-02T02:00:00Z", "update\_time": "2023-06-02T02:00:00Z" }, "source": { # 元数据信息忽略 }, "op": "c", # 操作类型 "ts\_ms": 1706768344113, "transaction": null } # tom手机号333->444变更数据如下 { "before": { "id": 3, "name": "tom", "phone": "333", "gender": "男", "create\_time": "2023-06-01T05:00:00Z", "update\_time": "2023-06-01T05:00:00Z" }, "after": { "id": 3, "name": "tom", "phone": "444", "gender": "男", "create\_time": "2023-06-01T05:00:00Z", "update\_time": "2023-06-01T23:00:00Z" }, "source": { # 元数据信息忽略 }, "op": "u", # 操作类型 "ts\_ms": 1706768454904, "transaction": null }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 当 Flink 同步程序接收到
op=c/u/d表示增量更新数据时,提取其中的op、before和after数据。接着将这些信息拼装成 Doris 的INSERT语句后插入到流水表中,此时流水表数据如下所示:
| id | update_time | dt | create_time | name | phone | gender | op | before | binlog |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 2023-06-02 10:00:00 | 2023-06-02 | 2023-06-02 10:00:00 | tony | 555 | 男 | c | NULL | {“before”:null,“after”:{“id”:4,“name”:“tony”,“phone”:“666”,“gender”:“男”,“create_time”:“2023-06-02T02:00:00Z”,“update_time”:“2023-06-02T02:00:00Z”},“source”:{“version”:“1.6.4.Final”,“connector”:“mysql”,“name”:“mysql_binlog_source”,“ts_ms”:1706768344000,“snapshot”:“false”,“db”:“yushu_dds”,“sequence”:null,“table”:“user”,“server_id”:2307031958,“gtid”:“71221bfd-56e8-11ee-8275-fa163e4ecceb:33719321”,“file”:“3509-binlog.000191”,“pos”:643757739,“row”:0,“thread”:null,“query”:null},“op”:“c”,“ts_ms”:1706768344113,“transaction”:null} |
| 3 | 2023-06-02 08:00:00 | 2023-06-02 | 2023-06-02 13:00:00 | tom | 444 | 男 | u | {“id”:3,“name”:“tom”,“phone”:“333”,“gender”:“男”,“create_time”:“2023-06-01T05:00:00Z”,“update_time”:“2023-06-01T05:00:00Z”} | {“before”:{“id”:3,“name”:“tom”,“phone”:“333”,“gender”:“男”,“create_time”:“2023-06-01T05:00:00Z”,“update_time”:“2023-06-01T05:00:00Z”},“after”:{“id”:3,“name”:“tom”,“phone”:“444”,“gender”:“男”,“create_time”:“2023-06-01T05:00:00Z”,“update_time”:“2023-06-01T23:00:00Z”},“source”:{“version”:“1.6.4.Final”,“connector”:“mysql”,“name”:“mysql_binlog_source”,“ts_ms”:1706768454000,“snapshot”:“false”,“db”:“yushu_dds”,“sequence”:null,“table”:“user”,“server_id”:2307031958,“gtid”:“71221bfd-56e8-11ee-8275-fa163e4ecceb:33719761”,“file”:“3509-binlog.000191”,“pos”:692873739,“row”:0,“thread”:null,“query”:null},“op”:“u”,“ts_ms”:1706768454904,“transaction”:null} |
- 因增量数据无需同步至快照表,故此时快照表与之前06-01号一样保持不变,快照表数据如下:
| id | dt | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|---|
| 1 | 2023-06-01 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | 2023-06-01 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 3 | 2023-06-01 | tom | 333 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
5.2.4、合并阶段
在合并阶段,我们将流水表前一天的数据与快照表中前两天的数据进行整合,最终得到前一天的全量数据,并将其写入至快照表的前一天分区。
合并任务会在满足以下任意一个条件时触发:
- 当binlog数据中的日期为第二天。
- 当凌晨过了5分钟(这是一个自定义的时间阈值)。
第二个条件的存在是因为业务数据很可能在凌晨00:00 ~ 00:05 分之间没有增量数据。因此,即使在没有业务数据同步的情况下,我们仍然可以通过第二个条件触发合并阶段,确保数据的完整性和准确性。
- 这里我们假设2023-06-03 00:05:00 触发合并阶段为例,此时业务数据如下所示:
| id | name | phone | gender | create_time | update_time |
|---|---|---|---|---|---|
| 1 | jack | 111 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
| 2 | jason | 222 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
22 | 男 | 2023-06-01 13:00:00 | 2023-06-01 13:00:00 |
[外链图片转存中…(img-f3Ke8vW6-1715810481412)]
[外链图片转存中…(img-f3JIdadM-1715810481413)]
[外链图片转存中…(img-Ezz99Wv3-1715810481413)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

