
- 1vue2后台管理项目动态加载路由_vue2动态添加路由
- 2Android进阶之路 - OkHttp的入门使用
- 3TensorFlow 的基本概念和使用场景_什么是tensorflow?tensorflow可以用于哪些领域?
- 4python自动化办公——python操作Excel、Word、PDF集合大全_python excel pdf
- 5为啥4位单片机那么LOW,还没被淘汰?
- 6【C/C++】作用域解析运算符(Scope Resolution Operator)在C++中的用法和作用
- 7Android学习笔记_public abstract map
- 8Mybatis 批量插入_mybatis 批量insert
- 9D435i、D435、D415、T265的Realsense_viewer环境搭配及安装_sudo apt-key adv --keyserver keys.gnupg.net --recv
- 10如何免费创建一个自己的网站(可通过外网访问)_做一个免费公网链接
【论文阅读笔记】InstantID : Zero-shot Identity-Preserving Generation in Seconds_instantid: zero-shot identity-preserving generatio
赞
踩
project:https://github.com/InstantID/InstantID
单位:小红书,北大

理解
很有意义的一篇文章,关注于人脸身份信息的保持来控制包含人物的图像生成;通过人脸识别网络的嵌入来保证身份一致性和细节,面部粗糙关键点过controlnet保持空间pose;支持非常丰富的下游任务
问题:
- 是否需要6千万的数据,数据小一点会怎么样呢?
摘要
- 现有的基于 ID 嵌入的方法,虽然只需要一个前向推理,但面临挑战:它们要么需要对众多模型参数进行广泛的微调,缺乏与社区预训练模型的兼容性,要么无法保持高人脸保真度
- 为了解决这些限制,我们引入了 InstantID,这是一种强大的基于扩散模型的解决方案。我们的即插即用模块擅长仅使用单个面部图像处理各种风格的图像个性化,同时确保高保真度
- 为此,我们设计了一种新的IdentityNet,通过施加强语义和弱的空间条件,将人脸和地标图像与文本提示相结合,引导图像生成
- InstantID 展示了卓越的性能和效率,证明了在身份保存至关重要的实际应用中非常有益。
Introduction
- 心有文生图大模型发展的焦点是个性化和定制的生成,试图根据一个或多个参考图像创建风格、主题或字符ID一致的图像。
- 挑战:是否准确保留了人类受试者的复杂身份细节
- 尽管增加文生图模型的方法controllnet、T2Iadapter、Uni-Controlnet等方法层出不穷,生成的图像与参考的保真度仍然只有部分
- 介绍现有方法不足,如Dreambooth、Textual Inversion、LORA等需要针对特定ID进行单独训练;或轻量级适配器用于推理,如Ipadapter使用交叉注意力注入图片信息
- 引入一种新的方法(InstantID),专注于即时身份保持图像合成。
- 引入一个简单的即插即用模块来弥合高保真度和效率之间的差距,使其能够熟练地使用单个面部图像以任何风格处理图像个性化,同时保持高保真度。
- 为了从参考图像中保留人脸身份,我们设计了一种新的人脸编码器,通过添加强语义和弱空间条件来保留复杂的细节,结合人脸图像、地标图像和文本提示来指导图像生成过程。
- 我们通过以下方式将我们的工作与以前的工作区分开来:(1)可插入性和兼容性:我们专注于训练一个轻量级适配器而不是UNet的完整参数,使我们的模块可插拔并与社区中的预训练模型兼容; (2) 无调优:我们的方法只需要一个前向传播进行推理,无需微调。此功能使 InstantID 在实际应用中非常经济和实用; (3) 卓越的性能:只有一个参考图像,InstantID 实现了最先进的结果,显示出高保真度和灵活性。值得注意的是,它可以匹配甚至超过基于多个参考图像的 LoRA 等基于训练的方法的性能。
贡献
- 我们提出了 InstantID,这是一种创新的 ID 保持适应方法,用于预训练的文本到图像扩散模型,以很好地弥合保真度和效率之间的差距。实验结果表明,与该领域其他最先进的方法相比,该方法具有良好的性能。
- InstantID是可插拔的,并与从同一基本扩散模型微调的其他自定义模型兼容,无需额外成本就可以在预训练模型中保留ID。此外,InstantID在原始稳定扩散模型中观察到的文本编辑保持了相当大的控制,使ID的平滑集成到各种样式中。
- InstantID的优异性能和效率点燃了其在一系列现实应用中的巨大潜力,如新视图合成、ID内插、多ID和多样式合成。
Related Work
Text-to-image Diffusion Models
不详细介绍了
Subject-driven Image Generation
定义:使用特定主题的有限图像集来生成基于文本描述的定制图像
ID Preserving Image Generation
ID-preserving 图像生成是主题驱动生成的一个特例,但它专注于具有强语义的人脸属性,并在现实场景中找到广泛的应用。
现有的工作主要可以分为两类, (LoRA) 是一种流行的轻量级训练技术,在定制数据集上进行训练之前,将最少数量的新权重插入到模型中。然而,LoRA 需要对每个新字符进行单独的训练,从而限制了其灵活性。
相比之下,最近的发展引入了无优化方法,绕过了额外的微调或反演过程。Face0用CLIP空间中的投影人脸嵌入覆盖最后三个文本标记,并使用联合嵌入作为条件来指导扩散过程。
PhotoMaker采用类似的方法,但通过微调图像编码器中的 Transformer 层的一部分并合并类和图像嵌入来增强其提取 ID 中心嵌入的能力。
FaceStudio提出了一种混合制导身份保持图像合成框架,其中人脸嵌入通过线性投影集成到 CLIP 视觉嵌入和 CLIP 文本嵌入中,然后将合并的指导嵌入融合到具有交叉注意的 UNet 中。IP-Adapter-FaceID使用来自人脸识别模型的人脸ID嵌入,而不是CLIP图像嵌入来保持ID的一致性。
然而,这些方法要么需要训练 UNet 的完整参数,牺牲与现有预训练社区模型的兼容性,要么未能确保高人脸保真度。为了解决这些限制,我们引入了一个可插拔模块,该模块擅长弥合无训练和训练密集型方法之间的鸿沟。我们的方法在推理过程中不需要微调,与现成的预训练扩散模型(如 SD1.5 和 SDXL)无缝对齐,在人脸保存方面取得了卓越的保真度。
Method
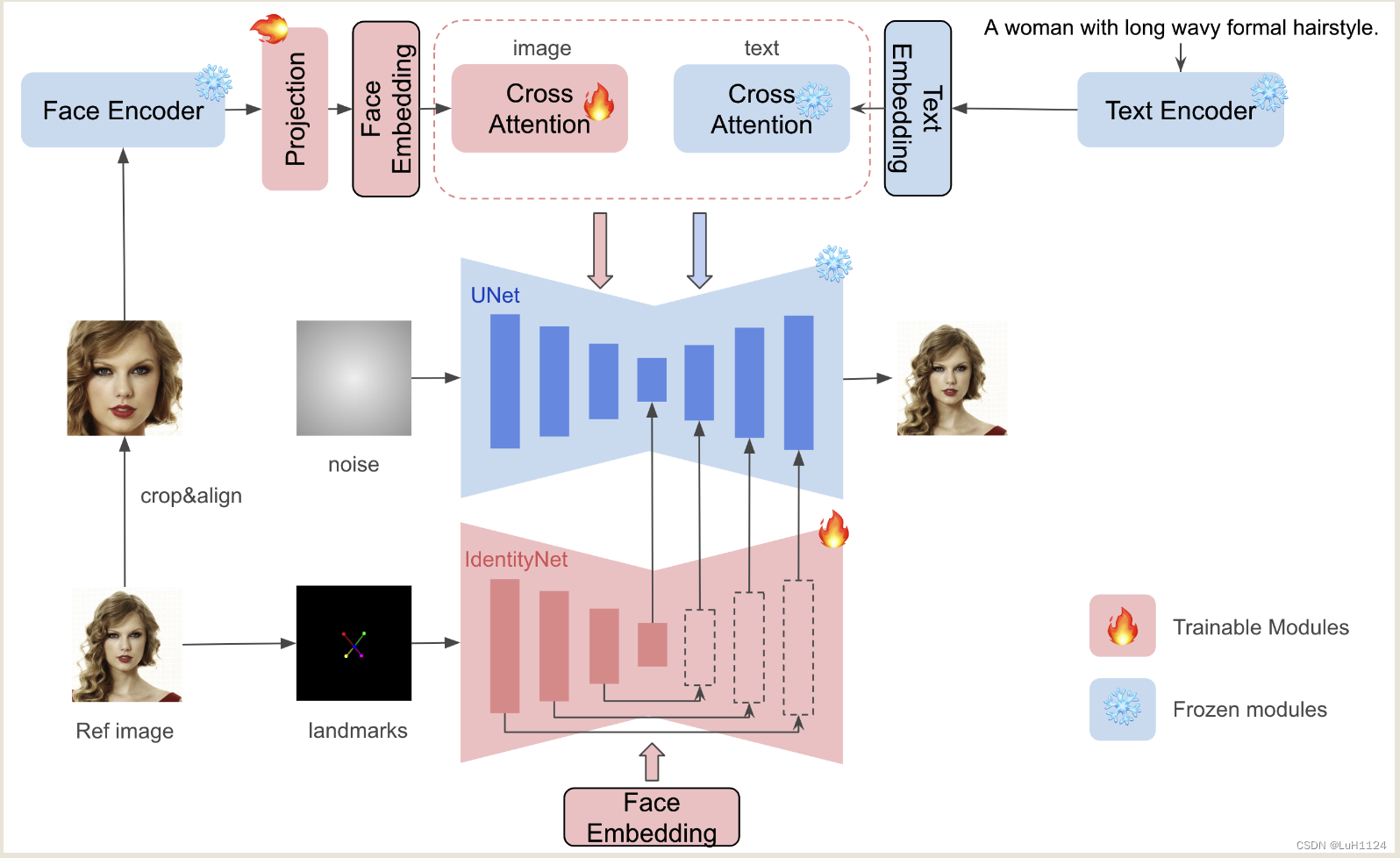
直观理解:
- 通过Face Encoder来提取身份特征向量并通过可训练的Projection Net得到最终的Face Embedding
- Face Embedding有两个去向
- 类似ipadapter使用image adapter构建doubled Cross attention注入身份ID信息,与ipadapter不同的点在于没有clip image encoder,因为clip无法关注到高层语义信息,只包含粗糙的纹理和颜色,无法进行高保证的语义保持
- 类似Controlnet,使用并行的Unet Encoder注入空间信息,具体来说使用双眼鼻子嘴五个粗略关键点引导Controlnet向unet中注入脸部的空间位置信息,并只送入Face Embedding 信息从而保留原本Unet的文本编辑能力。前者粗略关键点的映射保证了可编辑性(只提供粗略位置,确保文本还能够对表情进行修改);后者文本提示并使用 ID 嵌入作为交叉注意力层条件使网络能够只关注 ID 相关的表示,不受人脸和背景的广义描述的影响。
- 训练过程中只考虑Projection Net和Controlnet即可
实验
- 数据集
- LAION-Face 5千万对
- 1千万互联网收集图像,BLIP进行注释
- 人脸检测模型
- 网址:https://github.com/deepinsight/insightface
- 模型:antelopev2
- 资源
- 基于 SDXL-1.0 模型
- 48 个 NVIDIA H800 GPU (80GB) 上进行,每个 GPU 的批量大小为 2

定性实验

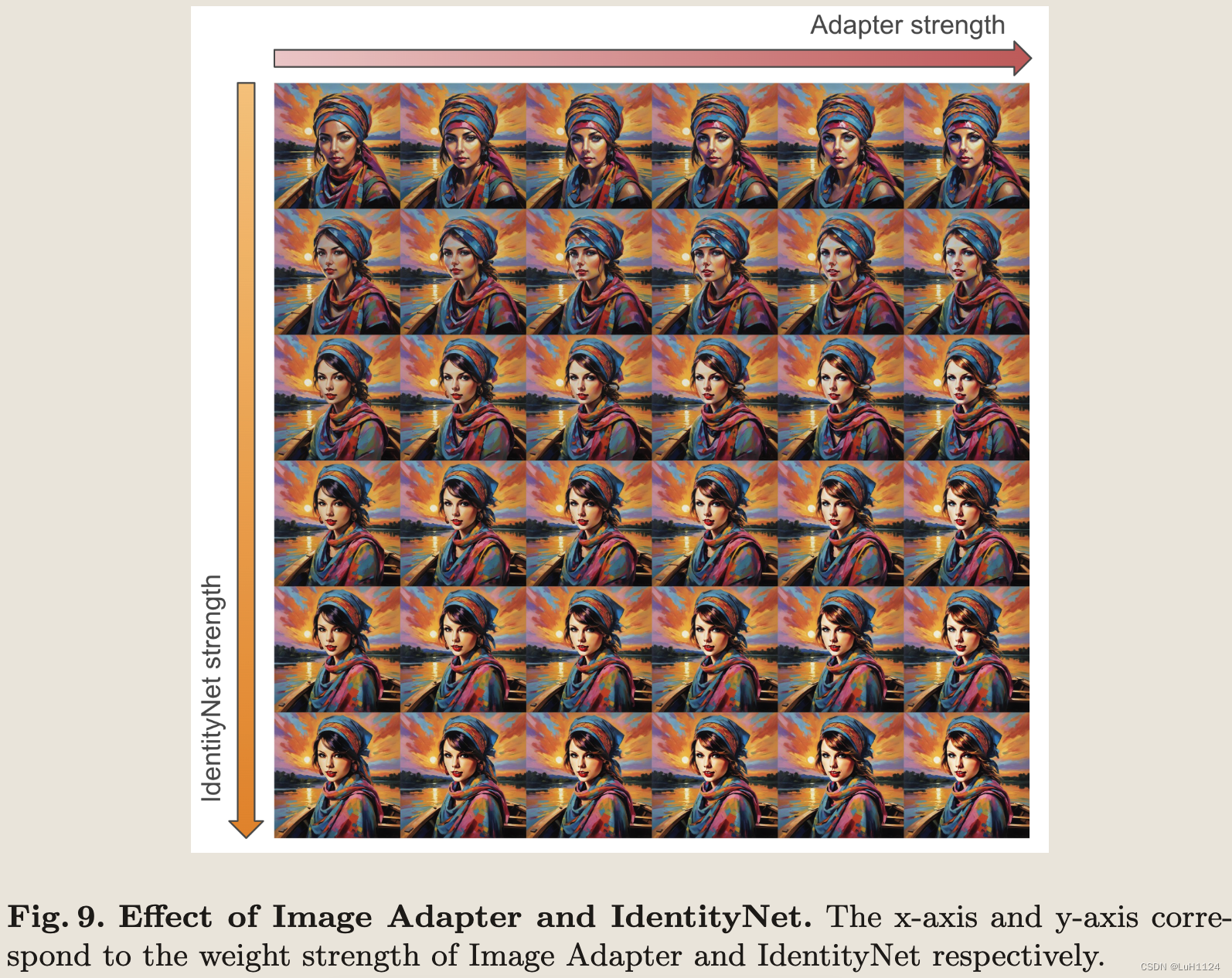
消融实验
-
IdentityNet 单独实现了良好的 ID 保留,并且 Image Adapter 的添加进一步增强了面部细节恢复
-
图片数量的影响

与先前方法的对比
相比于ipadapter实现了更好的风格融入和控制

相比于LoRA无需额外训练,直接单次推理

换脸层面能够更自然的融合身份与图片风格

富有创意的更多任务
新视角合成

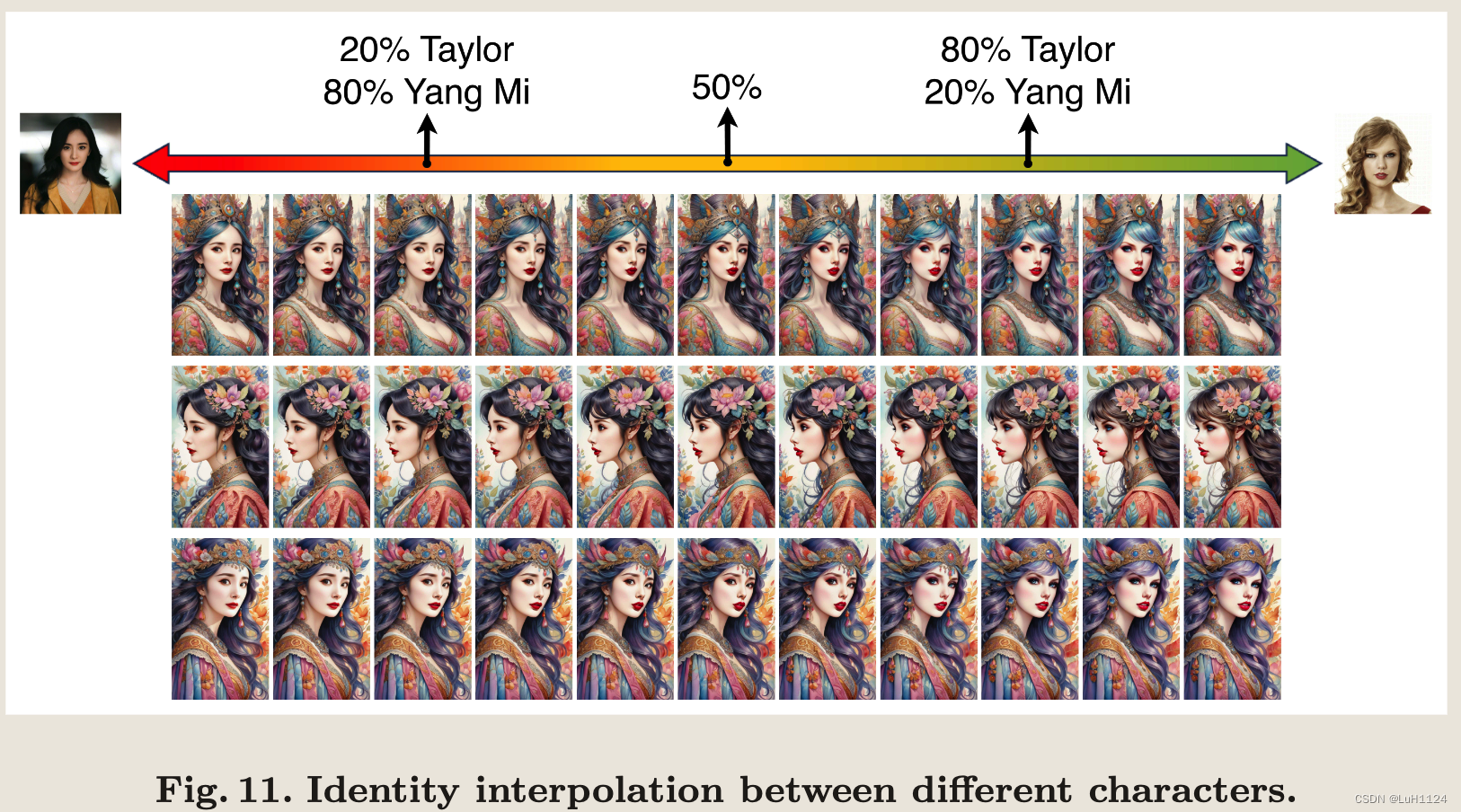
身份插值
这个face embedding具有这么好连续性是令人惊讶的
多身份区域控制合成

结论和未来工作
关注一下Limitation:
- 模型中的 ID 嵌入虽然富含性别和年龄等语义信息,但具有高度耦合的面部属性,这对面部编辑提出了挑战。未来的发展可能涉及解耦这些面部属性特征以增强灵活性。
- 我们可以观察到 InstantID 与我们使用的人脸模型中固有的偏差有关的一些限制(具体指?)

