
- 1KMP字符串模式匹配算法_算法思想是这样的:分别利用计数i和j指示主串s和模式串t中当前正待比较的字符位置
- 2PyQt5使用教程
- 3Node 后端 git 提交规范化处理_no staged files match any configured task
- 4Mysql数据库之间表结构比对更新_mysql 表结构对比更新
- 5传统词嵌入方法的千层套路_词嵌入的几种模型
- 6chatgpt赋能Python-pycharm降低numpy版本
- 7从SQL质量管理体系来看SQL审核(2) - SQL质量标准_质量检验sql
- 8卧槽!Kafka 宣布弃用 Java 8。。_spring kafka java8
- 9Ubuntu系统修改SSH默认端口号_ubuntu ssh端口
- 10C++基础-STL基础-常用算法
2025秋招LLM大模型多模态面试题(一)_多模态 面试题
赞
踩
目录
- 大模型常用微调方法LoRA和Ptuning的原理
- 介绍Stable Diffusion的原理
- 为何现在的大模型大部分是Decoder-only结构
- 如何缓解LLMs复读机问题
- 为什么Transformer块使用LayerNorm而不是BatchNorm
- Transformer为何使用多头注意力机制
- 监督微调SFT后LLM表现下降的原因
- 微调阶段样本量规模增大导致的OOM错误
- 连接文本和图像的CLIP架构简介
- Attention计算复杂度以及如何改进
- BERT用于分类任务的优点及后续改进工作
01. 大模型常用微调方法LORA和Ptuning的原理
Lora方法的核心是在大型语言模型上对指定参数增加额外的低秩矩阵,也就是在原始PLM旁边增加一个旁路,做一个降维再升维的操作。并在模型训练过程中,固定PLM的参数,只训练降维矩阵A与升维矩阵B。Ptuning方法的核心是使用可微的virtual token替换了原来的discrete tokens,且仅加入到输入层,并使用prompt encoder(BiLSTM+MLP)对virtual token进行编码学习。
更详细请查阅使用 LoRA(低阶适应)微调 LLM
02. 介绍一下stable diffusion的原理
Stable Diffusion 总共包含三个主要的组件,其中每个组件都拥有一个独立的神经网络: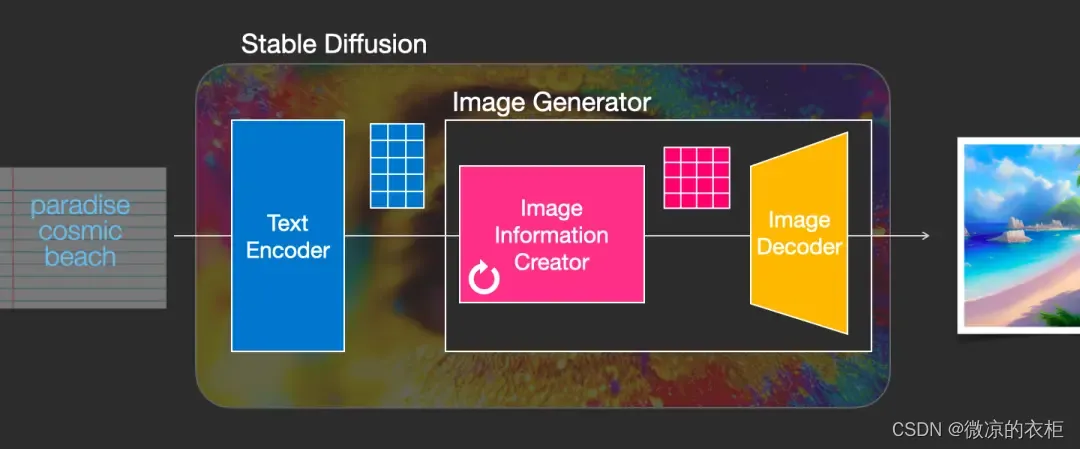
1)Clip Text 用于文本编码。
输入:文本
输出:77 个 token 嵌入向量,其中每个向量包含 768 个维度
2)UNet + Scheduler 在信息(潜)空间中逐步处理 / 扩散信息。
输入:文本嵌入和一个由噪声组成的初始多维数组(结构化的数字列表,也叫张量 tensor)。
输出:一个经过处理的信息阵列
3)自编码解码器(Autoencoder Decoder),使用处理过的信息矩阵绘制最终图像的解码器。
输入:处理过的信息矩阵,维度为(4, 64, 64)
输出:结果图像,各维度为(3,512,512)
更详细请查阅從頭開始學習Stable Diffusion
更详细请查阅十分钟理解Stable Diffusion
03. 为何现在的大模型大部分是Decoder only结构
大模型从模型架构上主要分为三种:Only-encoder, Only-Decoder, Encoder-Decoder三种模型架构-
Only-encoder:例如BERT,通过在大规模无标签文本上进行预训练,然后在下游任务上进行微调,具有强大的语言理解能力和表征能力。
-
Only-Decoder: 例如GPT,通过在大规模无标签文本上进行预训练,然后在特定任务上进行微调,具有很强的生成能力和语言理解能力。
-
Encoder-Decoder:例如T5(Text-to-Text Transfer Transformer)可以用于多种自然语言处理任务,如文本分类、机器翻译、问答等。
而LLM之所以主要都用Decoder-only架构,除了训练效率和工程实现上的优势外,在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。
04. 如何缓解 LLMs 复读机问题
- 多样性训练数据:在训练阶段,尽量使用多样性的语料库来训练模型,避免数据偏差和重复文本的问题。 - 引入噪声:在生成文本时,可以引入一些随机性或噪声,例如通过采样不同的词或短语,或者引入随机的变换操作,以增加生成文本的多样性。 - 温度参数调整:温度参数是用来控制生成文本的多样性的一个参数。通过调整温度参数的值,可以控制生成文本的独创性和多样性,从而减少复读机问题的出现。 - 后处理和过滤:对生成的文本进行后处理和过滤,去除重复的句子或短语,以提高生成文本的质量和多样性。 - Beam搜索调整:在生成文本时,可以调整Beam搜索算法的参数。Beam搜索是一种常用的生成策略,它在生成过程中维护了一个候选序列的集合。通过调整Beam大小和搜索宽度,可以控制生成文本的多样性和创造性。 - 人工干预和控制:对于关键任务或敏感场景,可以引入人工干预和控制机制,对生成的文本进行审查和筛选,确保生成结果的准确性和多样性。更详细请查阅大模型常见面试题解
05. 为什么transformer块使用LayerNorm而不是BatchNorm
Batch Normalization 是对这批样本的同一维度特征做归一化, Layer Normalization 是对这单个样本的所有维度特征做归一化。LN不依赖于batch的大小和输入sequence的长度,因此可以用于batchsize为1和RNN中sequence的normalize操作。-
为什么BN在NLP中效果差
- BN计算特征的均值和方差是需要在batch_size维度,而这个维度表示一个特征,比如身高、体重、肤色等,如果将BN用于NLP中,其需要对每一个单词做处理,让每一个单词是对应到了MLP中的每一个特征明显是违背直觉得;
- BN是对单词做缩放,在NLP中,单词由词向量来表达,本质上是对词向量进行缩放。词向量是什么?是我们学习出来的参数来表示词语语义的参数,不是真实存在的。
-
为什么LayerNorm单独对一个样本的所有单词做缩放可以起到效果
- layner-norm 针对每一个样本做特征的缩放。换句话讲,保留了N维度,在C/H/W维度上做缩放。
- layner-norm 也是在对同一个特征下的元素做归一化,只不过这里不再是对应N(或者说batch size),而是对应的文本长度。
06. Transformer为何使用多头注意力机制
多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。论文原作者发现这样效果确实好,更详细的解析可以查阅[Multi-head Attention](https://www.zhihu.com/question/341222779)07. 监督微调SFT后LLM表现下降的原因
SFT(Supervised Fine-Tuning)是一种常见的微调技术,它通过在特定任务的标注数据上进行训练来改进模型的性能。然而,SFT可能会导致模型的泛化能力下降,这是因为模型可能过度适应于微调数据,而忽视了预训练阶段学到的知识。这种现象被称为灾难性遗忘,可以使用一些策略,如:- 使用更小的学习率进行微调,以减少模型对预训练知识的遗忘。
- 使用正则化技术,如权重衰减或者早停,以防止模型过度适应微调数据。
- 使用Elastic Weight Consolidation(EWC)等技术,这些技术试图在微调过程中保留模型在预训练阶段学到的重要知识。
08. 微调阶段样本量规模增大导致的OOM错误
全参数微调的显存需求取决于多个因素,包括模型的大小(参数数量),批次大小,序列长度,以及是否使用了混合精度训练等。对于GPT-3这样的大模型,如果想要在单个GPU上进行全参数微调,可能需要数十GB甚至上百GB的显存。当样本量规模增大时,可能会出现OOM(Out of Memory)错误,这是因为模型需要更多的内存来存储和处理数据。为了解决这个问题,可以尝试以下方法:
- 减小批量大小:这可以减少每次训练需要处理的数据量,从而减少内存使用。
- 使用梯度累积:这种方法可以在不减小批量大小的情况下,减少内存使用。
- 使用模型并行:这种方法可以将模型的不同部分放在不同的设备上进行训练,从而减少每个设备需要的内存。
09. 连接文本和图像的CLIP架构简介
CLIP 把自然语言级别的抽象概念带到计算机视觉里了。确定一系列query,然后通过搜索引擎搜集图像,最后通过50万条query,搜索得到4亿个图像文本对。然后将Text Decoder从文本中提取的语义特征和Image Decoder从图像中提取的语义特征进行匹配训练。10. Attention计算复杂度以及如何改进
- 代码中的to_qkv()函数,即用于生成q、k、v三个特征向量
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.to_out = nn.Linear(inner_dim, dim)
- 1
- 2
- 在标准的Transformer中,Attention计算的时间复杂度为O(N^2),其中N是输入序列的长度。为了降低计算复杂度,可以采用以下几种方法:
- 使用自注意力机制,减少计算复杂度。自注意力机制不需要计算输入序列之间的交叉关系,而是计算每个输入向量与自身之间的关系,从而减少计算量。
- 使用局部注意力机制,只计算输入序列中与当前位置相关的子序列的交互,从而降低计算复杂度。
- 采用基于近似的方法,例如使用随机化和采样等方法来近似计算,从而降低计算复杂度。
- 使用压缩注意力机制,通过将输入向量映射到低维空间来减少计算量,例如使用哈希注意力机制和低秩注意力机制等。
11. BERT用于分类任务的优点,后续改进工作有哪些?
在分类任务中,BERT的结构中包含了双向的Transformer编码器,这使得BERT能够更好地捕捉文本中的双向上下文信息,从而在文本分类任务中表现更好。BERT的后续改进工作主要包括以下方面:- 基于BERT的预训练模型的改进,例如RoBERTa、ALBERT等;
- 通过调整BERT的架构和超参数来进一步优化模型性能,例如Electra、DeBERTa等;
- 改进BERT在特定任务上的应用方法,例如ERNIE、MT-DNN等;

