
- 1X64dbg 最新版(2024.06)搜索中文字符串显示乱码的问题_x64dbg中文乱码
- 2Stable Diffusion 【模型推荐】最新发布!绘本故事系列2,拟人化风格动物大模型,你值得拥有!!_拟人化的动物提示词
- 3Mongodb数据库操作
- 4python常用镜像_python镜像
- 5hive之Json解析(普通Json和Json数组)_hive解析json数组
- 6公益单身交友|她93年出生,博士学历,工作与生活并重
- 7现代主流浏览器集成的6大安全技术_uiwebview 浏览器支持 csp 吗
- 8安全多方计算:在不可信环境中创建信任_smpc多方计算
- 9Prompt最全指南(非常详细)从入门到精通,看这一篇就够了_大模型prompt
- 10程序员初学者的心态重要性,对错误的认知以及常出现的BUG错误_敲代码过程中总是出现错误是否是程序员一大缺点
震撼发布!阿里通义FunAudioLLM:重塑自然语音交互新纪元,开源引领语音处理革命!
赞
踩
近年来,人工智能的进步如 GPT-4o 和 Gemini-1.5极大地改变了人与机器的互动方式,2023这种转变在语音处理领域尤为明显。
阿里巴巴通义实验室近日发布并开源了 FunAudioLLM,这是一个旨在增强人与大型语言模型(LLMs)之间自然语音交互的框架,代表了语音处理领域的最新进展。
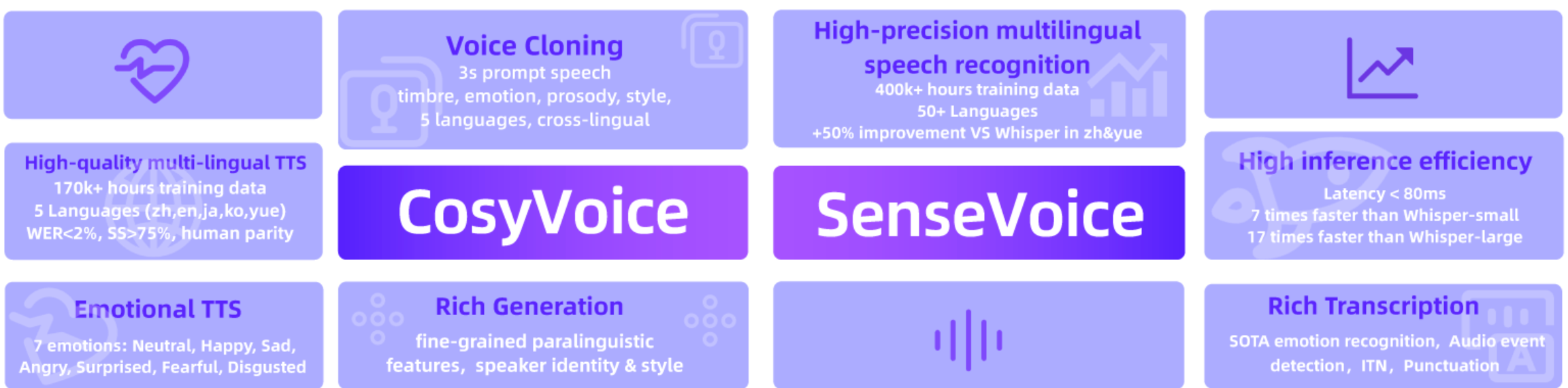
这一框架的核心是两个创新模型:SenseVoice 和 CosyVoice。这两个模型不仅在多语言语音识别、情感识别、音频事件检测和自然语音生成方面表现出色,还展示了极高的成熟度和广泛的应用潜力。
相关链接
Demo展示:https://fun-audio-llm.github.io
代码地址:https://github.com/FunAudioLLM上
介绍
本报告介绍了 FunAudioLLM,这是一个旨在增强人类与大型语言模型 (LLM) 之间的自然语音交互的模型系列。其核心是两个创新模型:
-
SenseVoice,用于处理多语言语音识别、情感识别和音频事件检测;
-
CosyVoice,用于促进自然语音生成,并控制多种语言、音色、说话风格和说话者身份。
SenseVoice-Small 为 5 种语言提供极低延迟的 ASR,SenseVoice-Large 支持 50 多种语言的高精度 ASR,而 CosyVoice 在多语言语音生成、零样本上下文学习、跨语言语音克隆和指令跟踪功能方面表现出色。与 SenseVoice 和 CosyVoice 相关的模型已在 Modelscope 和 Huggingface 上开源,相应的训练、推理和微调代码已在 GitHub 上发布。 FunAudioLLM 将这些模型与 LLM 相结合,实现了语音到语音翻译、情感语音聊天、互动播客和富有表现力的有声读物旁白等应用,从而突破了语音交互技术的界限。
内容简介

方法
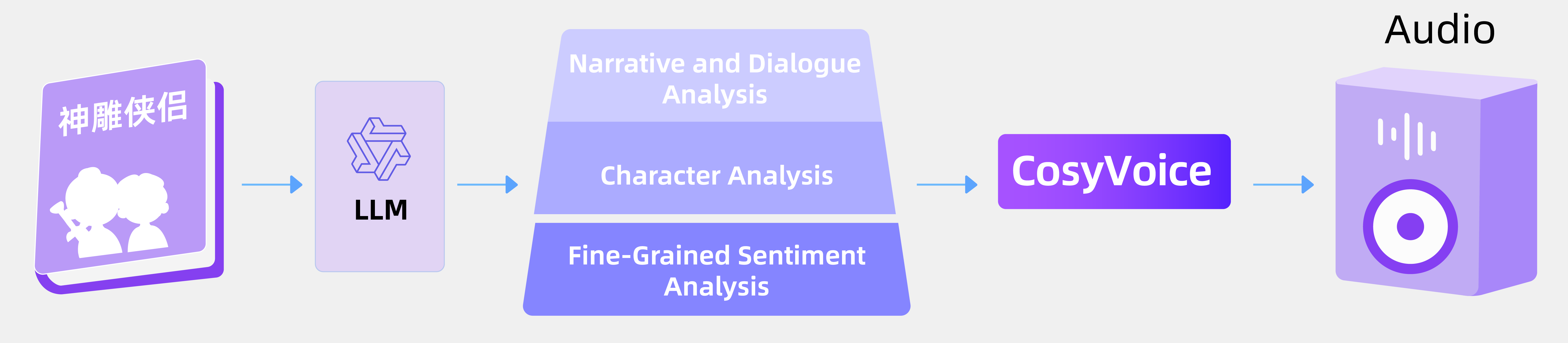
CosyVoice 概述
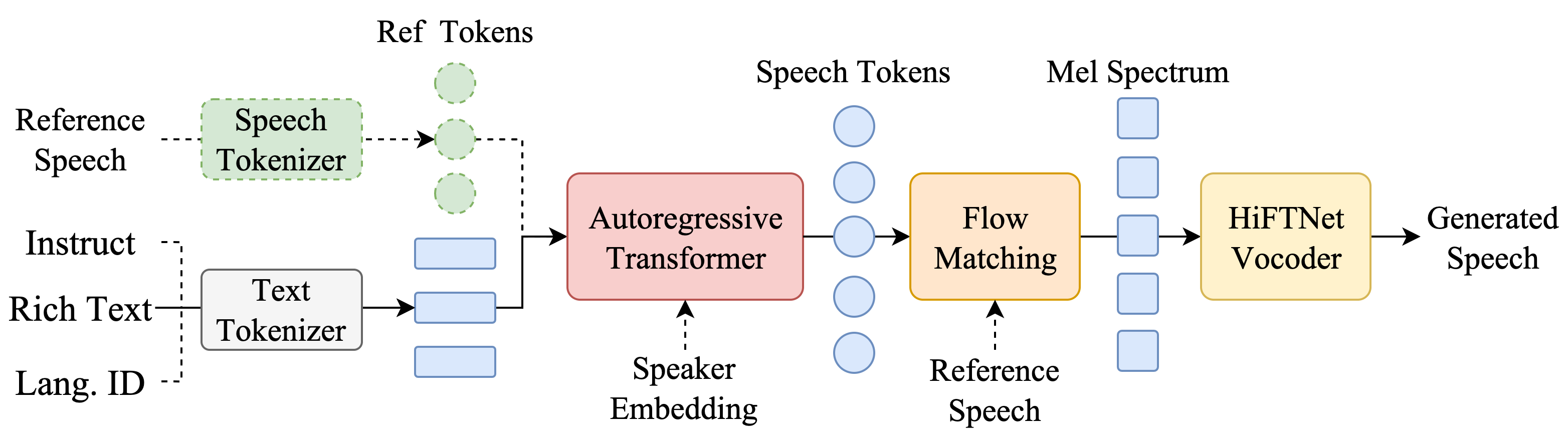
推理阶段 CosyVoice 模型概览。总之,CosyVoice 由一个自回归变换器(用于为输入文本生成相应的语音标记)、一个基于 ODE 的扩散模型、流匹配(用于从生成的语音标记重建梅尔频谱)和一个基于 HiFTNet 的声码器(用于合成波形)组成。虚线模块在特定模型用途中是可选的,例如跨语言、SFT 推理等。
SenseVoice 概述
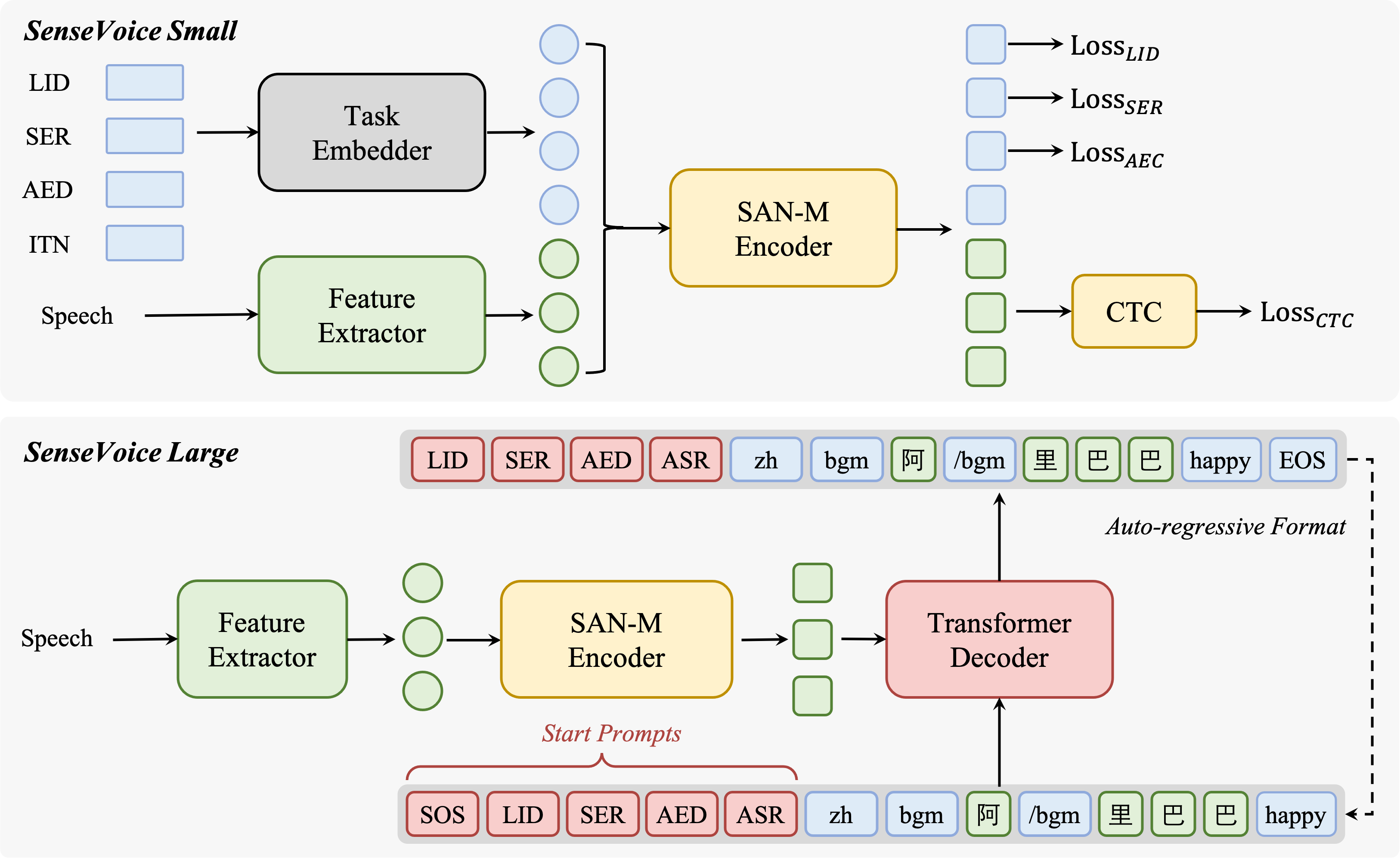
SenseVoice 模型概览。SenseVoice 是一个语音基础模型,具有多种语音理解功能,包括 ASR、LID、SER 和 AED。SenseVoice-Small 是一个仅编码器的语音基础模型,可实现快速语音理解;SenseVoice-Large 是一个编码器-解码器语音基础模型,可实现更准确的语音理解,并且支持更多语言。
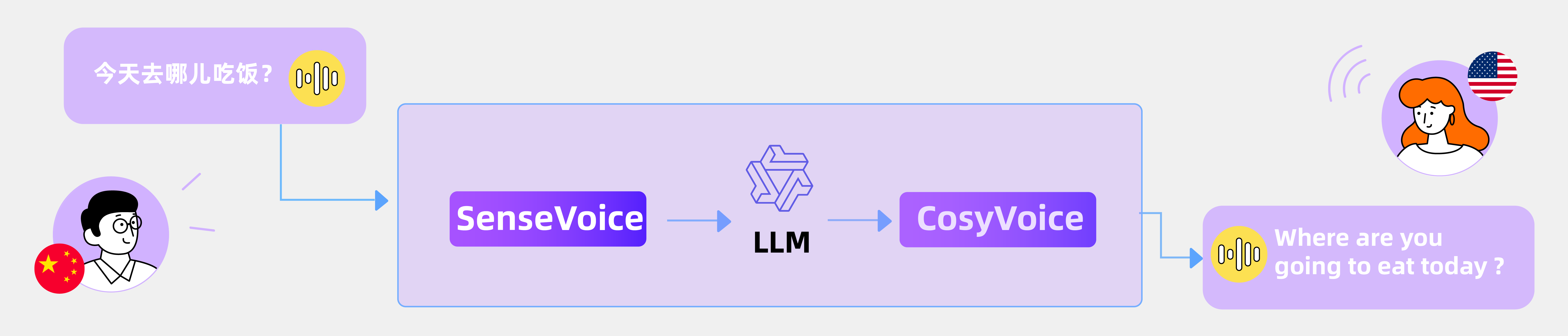
语音到语音翻译
通过整合 SenseVoice、LLM 和 CosyVoice,我们可以轻松进行语音到语音翻译 (S2ST)。请注意,原始录音以粗体突出显示。
情感语音聊天
通过整合SenseVoice、LLMs和CosyVoice,我们可以开发一个情感语音聊天应用程序。在下面的示例中,用户和助手的内容均由CosyVoice合成。

互动播客
通过整合 SenseVoice(一个基于 LLM 且具有实时世界知识的多智能体系统)和 CosyVoice,我们可以创建一个交互式播客。

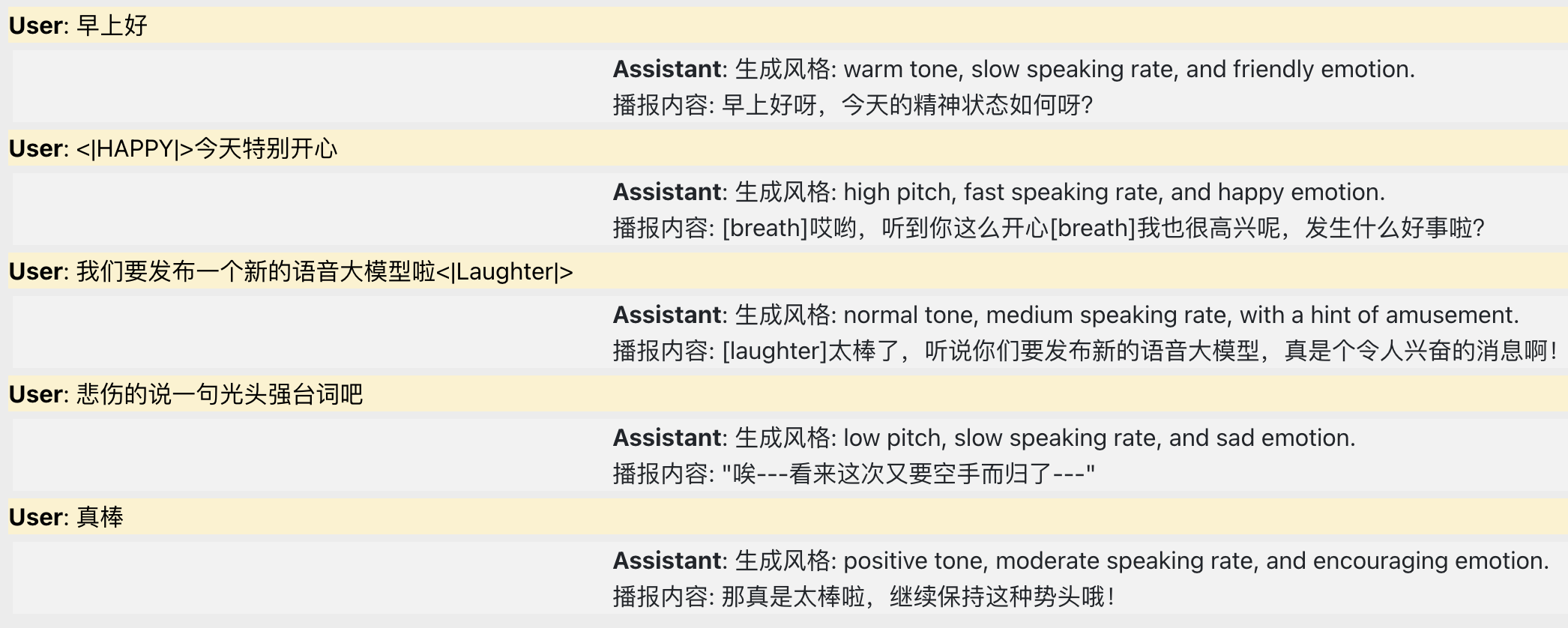
富有表现力的有声读物
通过 LLM 的分析能力来构建和识别书中的情感,并将其与 CosyVoice 相结合,我们实现了表现力增强的有声读物。
效果


多语言语音识别
我们在开源基准数据集(包括 AISHELL-1、AISHELL-2、Wenetspeech、Librispeech 和 Common Voice)上对比了 SenseVoice 和 Whisper 的多语言识别性能和推理效率。推理效率评估使用 A800 机器进行。SenseVoice-small 采用非自回归端到端架构,推理延迟极低,比 Whisper-small 快 7 倍,比 Whisper-large 快 17 倍。
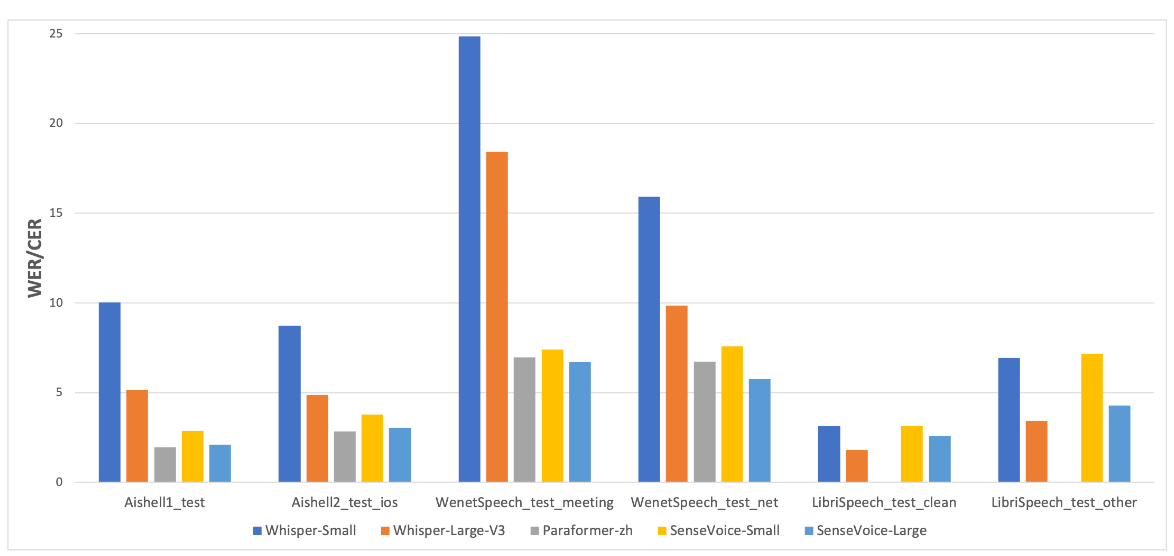
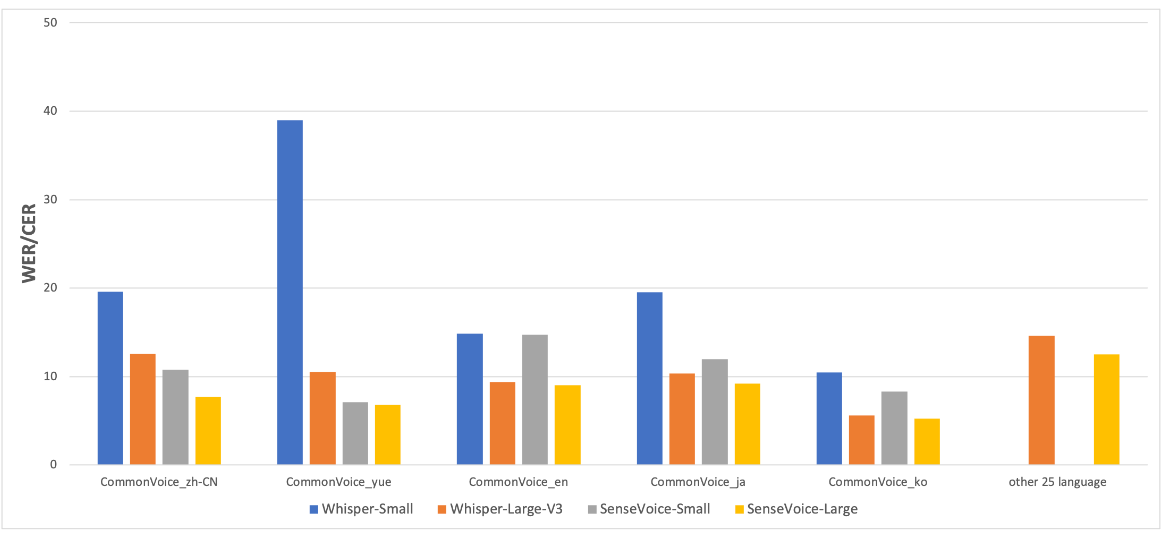
SenseVoice 与 Whisper 在多语言语音识别基准上的比较。
语音情感识别
SenseVoice 还可用于离散情绪识别。支持快乐、悲伤、愤怒和中性。我们在 7 种流行的情绪识别数据集上对其进行了评估。即使没有对目标语料库进行微调,SenseVoice-Large 也可以在大多数数据集上接近或超过 SOTA 结果。
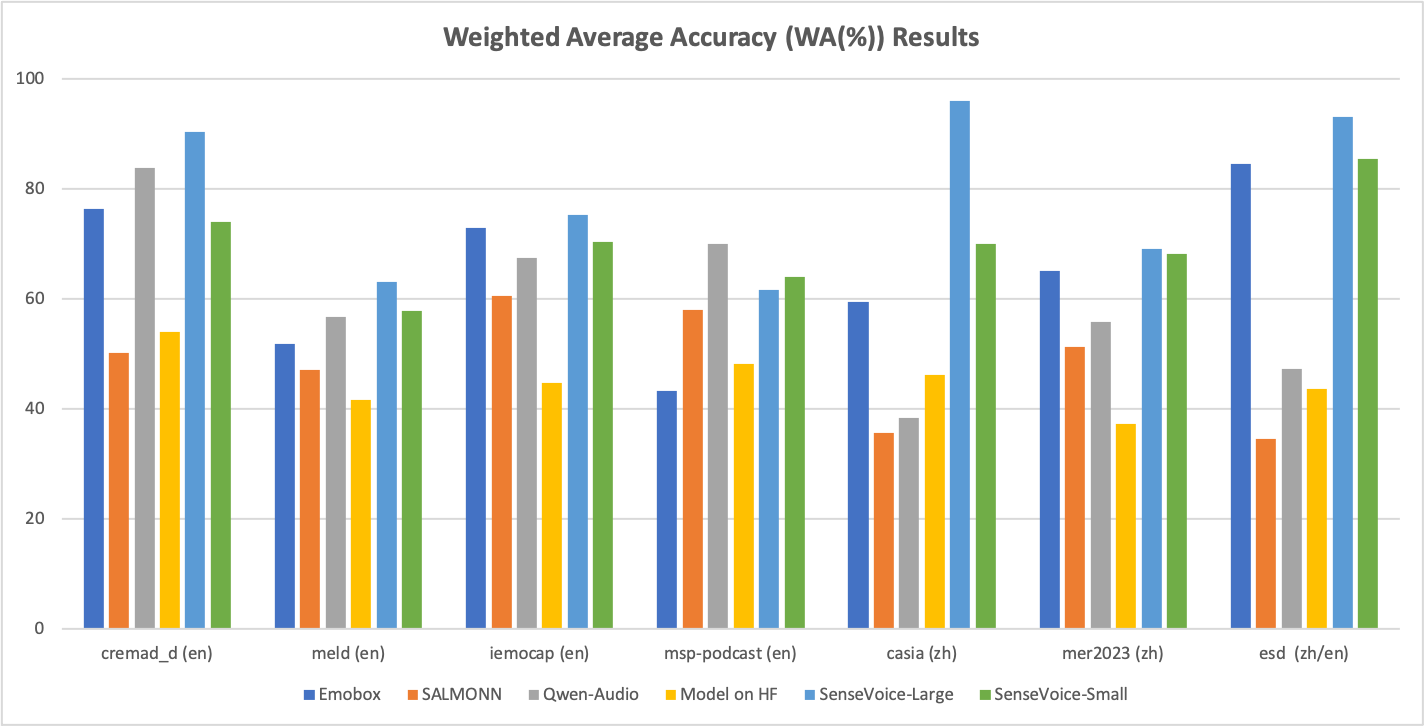
7种情绪识别数据集上的加权平均准确率 (WA(%)) 比较。EmoBox 是基于自监督模型和 Whisper 的最新语音情绪识别基准。HF 上的模型代表 HuggingFace 上最流行的语音情绪识别模型。

