
- 1Facebook Messenger,实时视频,AI和互联网卫星未来…F8大会精彩看点看过来!_ai 卫星互联网
- 2开源AI智能名片小程序在私域流量运营中的“及时法则”深度应用与策略探讨
- 3python中cursor属性_tkinter中的cursor鼠标样式
- 4手动下载数据,解决nltk.download(‘stopwords‘)问题_nltk.download('stopwords')
- 5利用腾讯云AI绘画做一个自己的绘画平台_云绘平台
- 6kafka数据丢失问题,如何保证数据不丢失_kafka 挂了,数据会丢失吗
- 7git命令行克隆报错fatal: Could not read from remote repository. Please make sure you have the correct acces...
- 8LangGraph介绍_langraph
- 9使用Google gshard缩放巨型模型
- 106分钟看懂 Node.js 武功精髓_如何阅读nodejs项目
用 C 语言进行大模型推理:探索 llama2.c 仓库(一)_c语言 模型推理
赞
踩
前提
最近发现了一个只用c语言就可以推理大模型的仓库llama2.c,作者是openAI的员工。对这个仓库产生了很大的兴趣,所以特地学习一番,这里做个记录。
有关huggingface社区
huggingface 应该是截至目前为止,世界上最大的llm社区了吧,huggingface社区收录了各种各样的模型共开发者使用,同时huggingface自己提供了一个Transformer库可以用来进行llm的推理。
之所以介绍huggingface社区,是因为在下文中我们要使用huggingface社区的模型。直接使用Meta发布的llama2来对程序进行运行分析的话,我的计算机因为配置问题运行不了,所以我们在huggingface社区中找一个和llama2有相同结构的模型,但是decode的层数要少很多的模型进行运行。
chinese-baby-llama2
chinese-baby-llama2是一个参数量115M左右的超微型小模型,采用Llama2架构,我们选择这个模型替代Meta的llama2对llama2.c仓库中的代码进行分析。
注意:在本文中,我们只关心推理代码的架构,以及代码是怎么写的,不关心llm的输出结果是否正确、是否合理。
llama2.c
我们将llama2.c和chinese-baby-llama2的仓库clone到本地。
关于llama.c仓库中每个文件是什么意思,这里不做过多的介绍,你将仓库中的README.md读完就明白了。简单地说下chinese-baby-llama2仓库中我们可能要用到的几个文件:

模型的权重文件是huggingface的格式。
export.py
因为权重文件和分词文件是huggingface的格式,因此按照README.md中指出的,为了可以使用run.c进行推理,我们首先要将hf模型文件转换为.bin文件,那么export.py这个文件就是用来做这个事情的。同理tokenizer.py也是干这个事情的,只不过对象换成了分词器。
export.py导出bin文件的大致流程如下:

读取模型信息
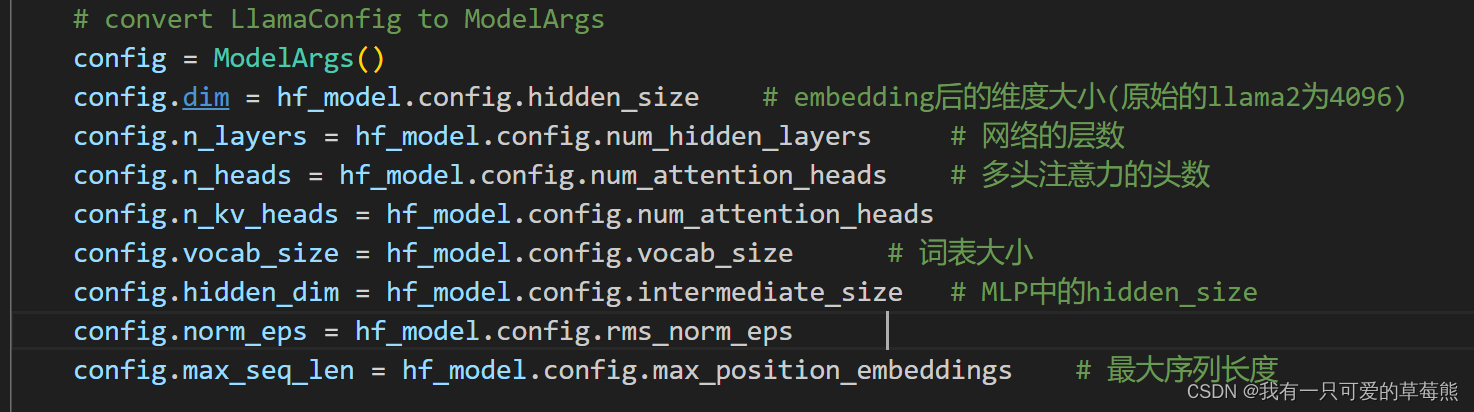
重建模型

对重建出的模型初始化权重
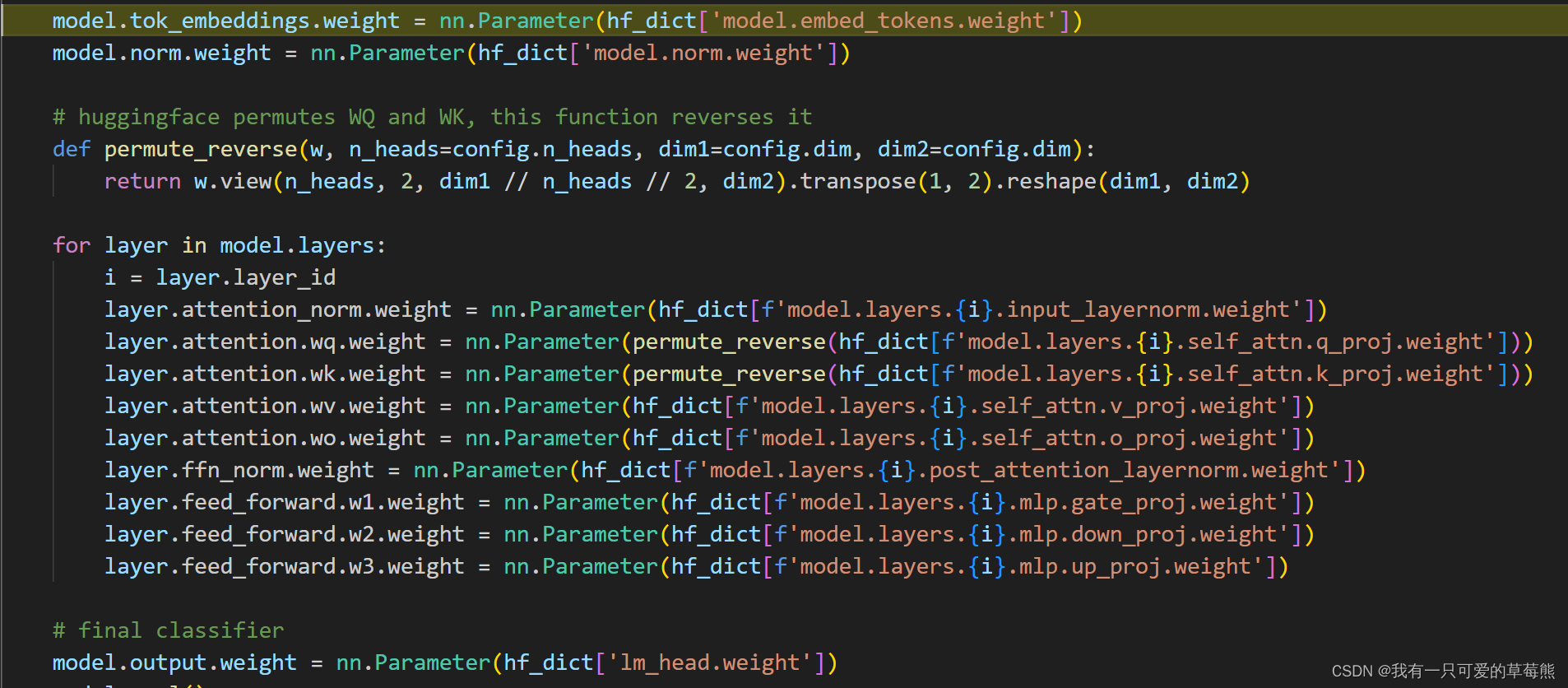
这里说明一下:从pytorch.model中提取的权重参数都存在hf_dict这个字典里,这个字典的长度为111,分别保存了每一层的参数、embedding的参数、最后一个norm的参数以及lm_head的参数。下面给出一个简易的网络结构图。
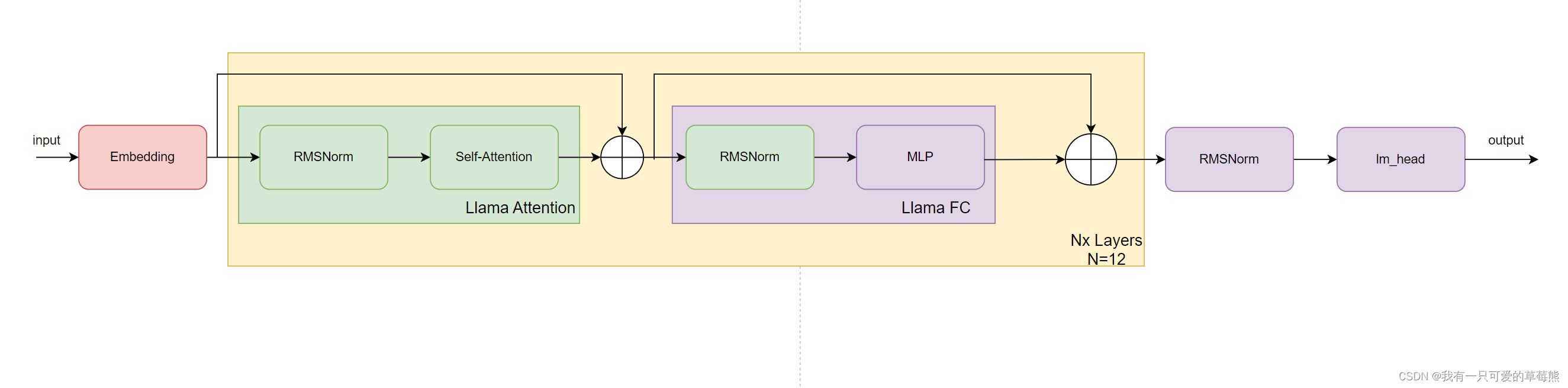
大概就是这个样子,我们根据这个也可以分析出为什么hf_dict的长度等于112,111 = 12 * 9(every layer) + 1(embedding) + 1(norm) +1(lm_head)。
导出run.c要求的.bin文件
第一步还是将模型结构等信息写入到.bin文件中,然后依次写入embedding权重文件等,写完以后,.bin文件的具体结构如下。

这里暂时没有搞清楚为什么不将
lm_head的权重也写入到bin文件中。
tokenizer.py
tokenizer.py的逻辑更为简单,主要是借助了sentencepiece这个库。同样加载tokenizer.model然后将其保存为.bin文件。
一些思考
如果让我们自己使用C语言实现一个llama2的推理,我们会怎么做?对于我来说,一个很简单的想法就是翻译,我们已经知道用python语言是如何对llama2进行推理的,那我将python语言翻译为C语言。当然,这个翻译也没有那么简单,要保证python和C的数据是对齐的。举个例子来说,在python中基本的数据结构是tensor,那么在C中该用什么来表达这个tensor呢?所以还是要有较多的考量。

参考链接
- https://github.com/karpathy/llama2.c
- https://zhuanlan.zhihu.com/p/674666408

