
- 1130个资源网站,总有一个你用得着(1)_9dy.co
- 2递归与递推---题目练习_常用算法解析法枚举法递归法递推法练习题
- 3LeetCode1893.检查是否区域内所有整数都被覆盖_检查区间覆盖
- 4其他常用漏洞复现工具介绍与配置_常见框架漏洞利用工具
- 5我的一些电脑资源(陪伴)_聚bt
- 6程序员必备的技能矩阵图_技能矩阵图如何分析出来
- 7Ontonotes 3.0 数据集介绍,编号LDC2009T24
- 8预处理1-Tokens and N-grams_n-gram dictionary
- 9priority_queue模拟实现【C++】
- 10详细介绍Pytorch基于GPU训练的一般套路(device)_pytorch 使用显卡训练
手搭一个大模型-part1-Qwen模型的介绍_qwen大模型
赞
踩
前置知识
Transformer的魅力
在2017年,一篇划时代的论文《Attention Is All You Need》发布,极大地推动了自然语言处理(NLP)领域的进展。自此以后,Transformer模型不仅在文本生成中得到了广泛应用,还在扩散模型等多个领域显示出了其强大的能力。接下来,我们将详细介绍Transformer的整体框架。

如上图:我们可以看到Transformer架构分为四个部分,分别是输入部分,编码器部分,解码器部分,输出部分。
-
输入部分:包括编码器输入和解码器输入。对于编码器输入,我们首先将文本通过词嵌入(Word Embedding)和位置嵌入(Position Embedding)转换为向量,然后送入编码器以提取特征。解码器输入则在编码器的基础上增加了一个掩码机制,该机制用于屏蔽未来的信息,防止信息提前泄露。
-
编码器部分:根据Transformer的原始论文,编码器由六个结构相同的编码层堆叠而成。这里我们重点分析单个编码层的结构。从结构图中可以看出,每个编码器层包括两个子模块:多头自注意力(Multi-Head Self-Attention)和前馈全连接层(Feed-Forward Neural Network)。每个子模块都是通过一个残差连接和随后的层归一化(Layer Normalization)来实现的。
-
解码器部分:解码器同样由六个结构相同的解码层堆叠而成,构成整个解码器。在解码器的每个层中,有三个主要的子模块:多头自注意力层、编码器-解码器注意力层(用于从编码器层抽取信息),以及前馈全连接层。与编码器类似,这些子模块也采用残差连接和层归一化。
-
输出部分:最后,输出通过一个全连接层进行特征提取,并通过Softmax函数生成最终的预测结果
我们以机器翻译为例子理解一下Transformer的训练全过程:
假设我们的任务是将我爱北京翻译成I love Beijing
- 预处理和词嵌入
输入处理:首先,中文句子“我爱北京”会被分词为单独的词或字符。假设我们使用字符级的分割,得到“我”、“爱”、“北”、“京”。这一部分是由tokenizer完成的
词嵌入:这些字符通过词嵌入层转换成向量。此外,由于Transformer不具备处理序列顺序的能力,我们还需为每个字符添加位置嵌入,以表示其在句子中的位置。对应结构中的Embedding- 编码器操作
多头自注意力机制:在编码器中,多头自注意力层会评估句子中每个字符与其他字符的关系,这有助于捕获例如“我爱”(我和爱之间的直接关系)这样的局部依赖关系。(Multi-Head Self-Attention)
前馈全连接层机制(Feed-Forward Neural Network): 经过大量的实验表面,全连接层的特征提取能力是很强的,而且结构简单,为了防止多头注意力机制特征提取不够充分,所有加入了这一层,让模型进一步学习到词语词之间的依赖关系
层次结构处理:编码器的每一层都将之前层的输出作为输入,逐层提取更抽象的特征。每个层的输出都是一个加强了输入句子每个部分上下文信息的表示。- 解码器操作
屏蔽未来信息:解码器在生成翻译时使用屏蔽技巧来避免“看到”未来的输出。例如,在预测单词“love”时,模型只能访问到“ I”,而不能访问到“Beijing”。
注意力机制:解码器的编码器-解码器注意力层使得每一步的生成都可以关注到输入句子的不同部分。例如,当生成“Beijing”时,模型可能会特别关注“北京”。- 生成预测和训练
输出:每次解码步骤,模型都会输出一个词的概率分布,选择概率最高的词作为这一位置的翻译。例如,首先生成“I”,然后是“love”,最后是“Beijing”。
训练过程:在训练阶段,我们使用实际的目标句子“ I love Beijing ”作为训练目标。模型通过比较预测输出与实际输出,并通过反向传播优化其参数。
了解GPT模型
为什么要介绍GPT模型呢?
现在很多大模型都是基于transform中的decoder模块发展的,而最典型的模型就是GPT。GPT模型本质上是利用了Transformer的解码器结构。与完整的Transformer相比,GPT仅使用了解码器部分,这是因为它主要被设计为一个生成模型。
下图是GPT模型的结构图

如上图所示, 经典的Transformer Decoder Block包含3个子层, 分别是Masked Multi-Head Attention层, encoder-decoder attention层, 以及Feed Forward层. 但是在GPT中取消了第二个encoder-decoder attention子层, 只保留Masked Multi-Head Attention层, 和Feed Forward层.
上图最后的输出部分还展示了GPT最经典的两个预训练任务,分别为:无监督训练和有监督训练。
- 无监督训练: 在这个阶段,模型主要通过大量的文本数据进行预训练,目的是使模型能够预测下一个词。这一过程称为自回归语言建模。通过这种方式,GPT不仅学习了词汇的共现(co-occurrence)和语法结构,而且还能把握到更复杂的语义信息和上下文关系。
- 有监督训练:GPT模型通常会通过有监督的微调(SFT)来适应具体的任务。这包括但不限于文本分类、情感分析、问答系统等。通过针对性的训练优化特定任务的表现。这种策略能够有效提高了模型的灵活性和效能,使其能够在多种NLP任务中表现出色
千问大模型框架
介绍
介绍完Transformer和GPT模型后,接下来就是正题,手搭一个千问大模型。首先我们先看看千问大模型的结构图
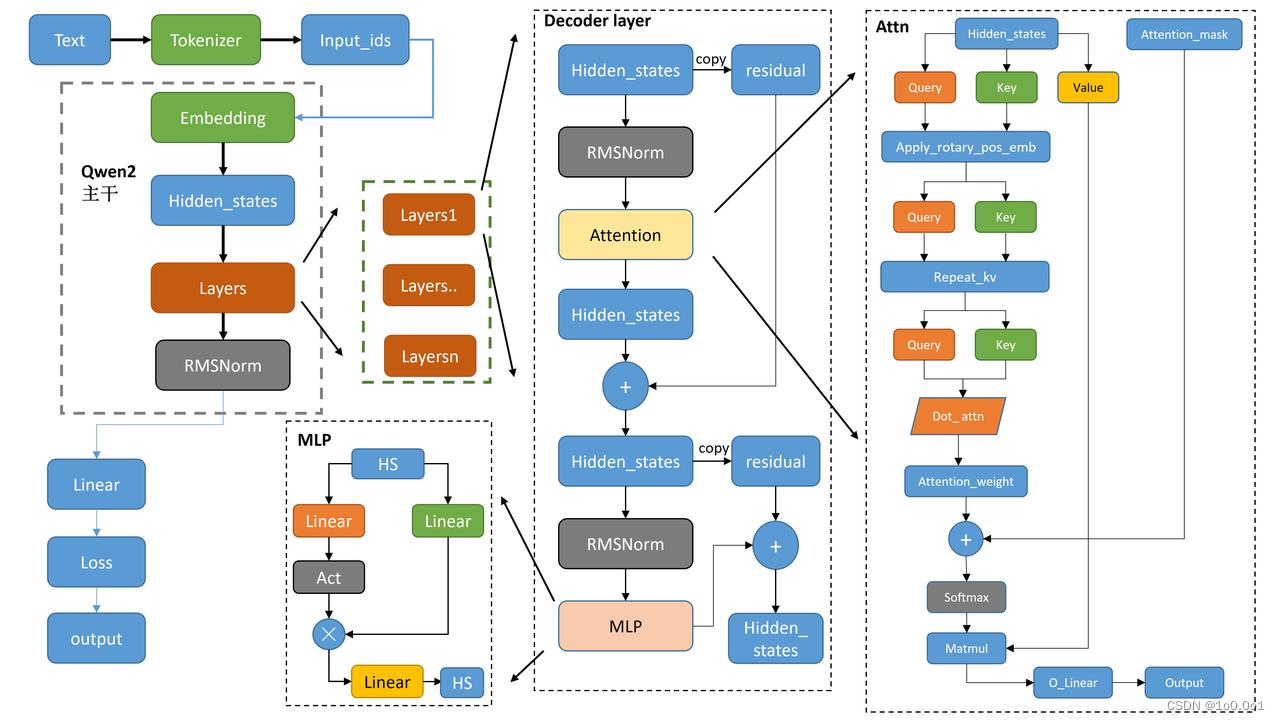
我们现在看主干部分,是不是很熟悉。和我们GPT模型的结构是不是很相似? 现在基本上大模型都是基于GPT的结构来实现的,唯一不同的是可能对GPT每一个模块都有了一定程度的魔改,从而达到GPT模型所做不到的程度。
接着我们开始介绍每一部分的实现
Tokenizer部分
Tokenizer就是一个训练好的分词器,可以理解为,我现在有一张词汇表,上面每个单词都有一个序号,现在我将一个句子划分成一个个词,然后根据这张词汇表将这些词用一个序号表示。这就是Tokenizer的作用
Embedding部分
Qwen的Embedding部分和GPT相比在PositionEmbedding部分做出了一些改变,GPT中的PositionEmbedding通常使用固定的三角函数位置编码。这种位置编码是通过正余弦函数的变化来为模型的每个输入位置生成唯一的编码,从而帮助模型理解单词的顺序关系。
代码如下
# 定义位置编码器 class PositionalEncoding(nn.Module): def __init__(self, d_model, dropout=0.1, max_len=5000): """位置编码器类的初始化函数, 共有三个参数, 分别是d_model: 词嵌入维度, dropout: 置0比率, max_len: 每个句子的最大长度""" super(PositionalEncoding, self).__init__() # 实例化nn中预定义的Dropout层, 并将dropout传入其中, 获得对象self.dropout self.dropout = nn.Dropout(p=dropout) # 初始化一个位置编码矩阵, 它是一个0阵,矩阵的大小是max_len x d_model. pe = torch.zeros(max_len, d_model) # 初始化一个绝对位置矩阵, 在我们这里,词汇的绝对位置就是用它的索引去表示. # 所以我们首先使用arange方法获得一个连续自然数向量,然后再使用unsqueeze方法拓展向量维度使其成为矩阵, # 又因为参数传的是1,代表矩阵拓展的位置,会使向量变成一个max_len x 1 的矩阵, position = torch.arange(0, max_len).unsqueeze(1) # 绝对位置矩阵初始化之后,接下来就是考虑如何将这些位置信息加入到位置编码矩阵中, # 最简单思路就是先将max_len x 1的绝对位置矩阵, 变换成max_len x d_model形状,然后覆盖原来的初始位置编码矩阵即可, # 要做这种矩阵变换,就需要一个1xd_model形状的变换矩阵div_term,我们对这个变换矩阵的要求除了形状外, # 还希望它能够将自然数的绝对位置编码缩放成足够小的数字,有助于在之后的梯度下降过程中更快的收敛. 这样我们就可以开始初始化这个变换矩阵了. # 首先使用arange获得一个自然数矩阵, 但是细心的同学们会发现, 我们这里并没有按照预计的一样初始化一个1xd_model的矩阵, # 而是有了一个跳跃,只初始化了一半即1xd_model/2 的矩阵。 为什么是一半呢,其实这里并不是真正意义上的初始化了一半的矩阵, # 我们可以把它看作是初始化了两次,而每次初始化的变换矩阵会做不同的处理,第一次初始化的变换矩阵分布在正弦波上, 第二次初始化的变换矩阵分布在余弦波上, # 并把这两个矩阵分别填充在位置编码矩阵的偶数和奇数位置上,组成最终的位置编码矩阵. # 跳跃式初始化 div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) # 将pe注册乘buffer # 最后把pe位置编码矩阵注册成模型的buffer,什么是buffer呢, # 我们把它认为是对模型效果有帮助的,但是却不是模型结构中超参数或者参数,不需要随着优化步骤进行更新的增益对象. # 注册之后我们就可以在模型保存后重加载时和模型结构与参数一同被加载. pe = pe.unsqueeze(0) self.register_buffer('pe', pe) def forward(self, x): """forward函数的参数是x, 表示文本序列的词嵌入表示""" # 在相加之前我们对pe做一些适配工作, 将这个三维张量的第二维也就是句子最大长度的那一维将切片到与输入的x的第二维相同即x.size(1), # 因为我们默认max_len为5000一般来讲实在太大了,很难有一条句子包含5000个词汇,所以要进行与输入张量的适配. # 最后使用Variable进行封装,使其与x的样式相同,但是它是不需要进行梯度求解的,因此把requires_grad设置成false. x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False) return x

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
我们可以通过代码查看一下,单词在不同位置下,对应的波长变化
import matplotlib.pyplot as plt import numpy as np # 创建一张15 x 5大小的画布 plt.figure(figsize=(15, 5)) # 实例化PositionalEncoding类得到pe对象, 输入参数是20和0 pe = PositionalEncoding(20, 0) # 然后向pe传入被Variable封装的tensor, 这样pe会直接执行forward函数, # 且这个tensor里的数值都是0, 被处理后相当于位置编码张量 # 100个词,每个词表达成20维的词向量 y = pe(Variable(torch.zeros(1, 100, 20))) # 然后定义画布的横纵坐标, 横坐标到100的长度, 纵坐标是某一个词汇中的某维特征在不同长度下对应的值 # 因为总共有20维之多, 我们这里只查看4,5,6,7维的值. plt.plot(np.arange(100), y[0, :, 4:8].data.numpy()) # 在画布上填写维度提示信息 plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
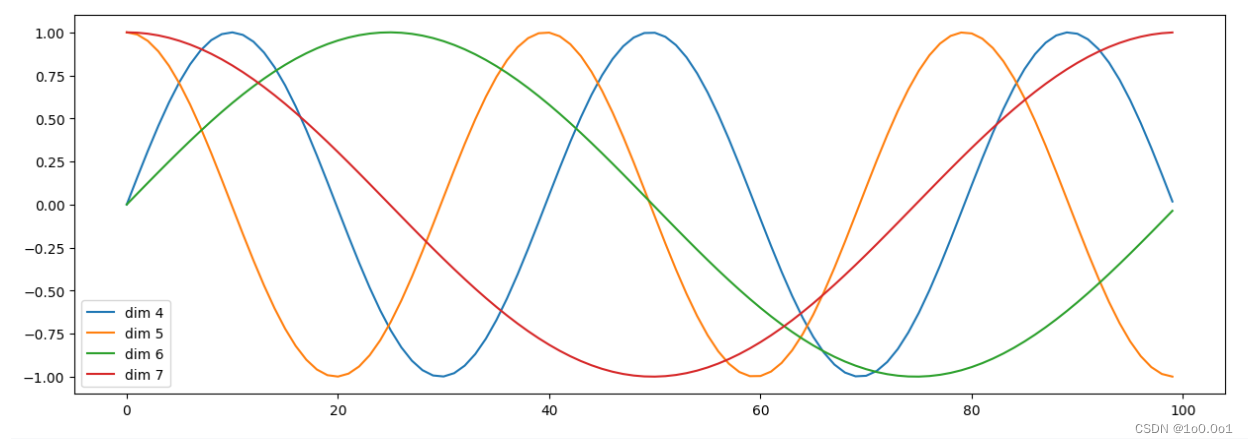
通过这种方式能够对词向量引入位置关系。
而Qwen的Position Embedding也是用的这种编码。
hidden_stage
hidden_stage就是我们词汇经过tokenizer变成索引张量后,然后经过Embedding层变成一个词向量,这个时候我们就称其为一个hidden_stage
Qwen attention
Qwen attention的结构图如下:

接下来我将从注意力机制开始,介绍每一个框架的作用
注意力机制
我们先介绍一下什么是注意力机制,首先我们先看一下下面的图片:

大家看到这图后第一时间的关注点在哪里呢(手动狗头)?
我们观察事物时,之所以能够快速判断一种事物(当然允许判断是错误的), 是因为我们大脑能够很快把注意力放在事物最具有辨识度的部分从而作出判断,而并非是从头到尾的观察一遍事物后,才能有判断结果. 正是基于这样的理论,就产生了注意力机制.
注意力机制有三种计算方法:
将
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

