
热门标签
热门文章
- 1推荐开源邮件服务器:Mailu - 简单、全功能且自由
- 2并查集——村村通(洛谷 P1536),那些年我们一起踩过算法与数据结构的坑_p1536 村村通
- 3Idea中编译错误 internal java compiler error (启动失败)_java: 编译失败: 内部 java 编译器错误
- 4开源模型应用落地-语音转文本-whisper模型-AIGC应用探索(三)_whisper模式
- 5PicGo + gitee 免费搭建个人图床工具_picgo gitee配置owner
- 6Curator 异常处理一: KeeperErrorCode = Unimplemented ``for` `/curator_keepererrorcode =unimplemeted
- 7Error starting userland proxy: listen tcp 0.0.0.0:80: bind: address already in use.的解决办法_error starting userland proxy: listen tcp4 0.0.0.0
- 8什么样的人适合做产品经理?具备这些特质!
- 9猫头虎分享已解决Bug || Kotlin Error: lateinit property has not been initialized
- 10人工智能的八大关键技术,你知道几个?_人工智能涉及哪几项关键技术
当前位置: article > 正文
阿里巴巴多模态模型Qwen-VL刚迎来升级更新,就被网友逮去装进了ComfyUI里面_qwen-vl-max
作者:木道寻08 | 2024-06-20 00:50:48
赞
踩
qwen-vl-max

Qwen-VL-Plus显著提升了细节和文本识别能力,支持超高像素分辨率图像,性能卓越。而Qwen-VL-Max更进一步,拥有高级视觉感知和认知理解,在复杂任务中表现最优。厉害的是,这两款技术还能识别Gif图。这在业界尚属首例,突显其实用性。
其实就是通义千问,Qwen-VL是一种大规模视觉语言模型,由阿里云于2024年1月26日推出。该模型的升级版Qwen-VL-Max拥有更强的视觉推理能力和中文理解能力,能够在多个权威测评中获得佳绩,整体性能堪比GPT-4V和Gemini Ultra。
通义千问国内官网链接:通义官网

Qwen-VL-Max在中文问答和中文文本理解任务上超越了GPT-4V和Gemini。除此之外,Qwen-VL-Plus在图像相关推理能力上实现了大幅提升,能够在更短的时间内提供更准确的推理结果。同时,Qwen-VL-Plus/Max在识别、提取和分析图像及其中文本细节上的能力显著增强,能够更好地理解和处理复杂的视觉信息。该模型还支持超过一百万像素的高清图像和各种宽高比的图像的处理,满足了不同应用场景的需求。
详细介绍:Introducing Qwen-VL | Qwen
在线体验:https://huggingface.co/spaces/Qwen/Qwen-VL-Max
项目地址:https://github.com/ZHO-ZHO-ZHO/ComfyUI-Qwen-VL-API
AIGC专区:aigc

阿里巴巴Qwen-VL的特殊能力:
- 在多个文本-图像多模态任务上,Qwen-VL-Plus与Gemini Ultra和GPT-4V性能相当,均表现出色。
- Qwen-VL-Max在中文问答和中文文本理解任务上超越了GPT-4V和Gemini,展现了更强大的语言理解和生成能力。
- Qwen-VL-Plus/Max在图像相关推理能力上实现了大幅提升,能够在更短的时间内提供更准确的推理结果。
- Qwen-VL-Plus/Max在识别、提取和分析图像及其中文本细节上的能力显著增强,能够更好地理解和处理复杂的视觉信息。
- Qwen-VL-Plus/Max支持超过一百万像素的高清图像和各种宽高比的图像的处理,满足了不同应用场景的需求。
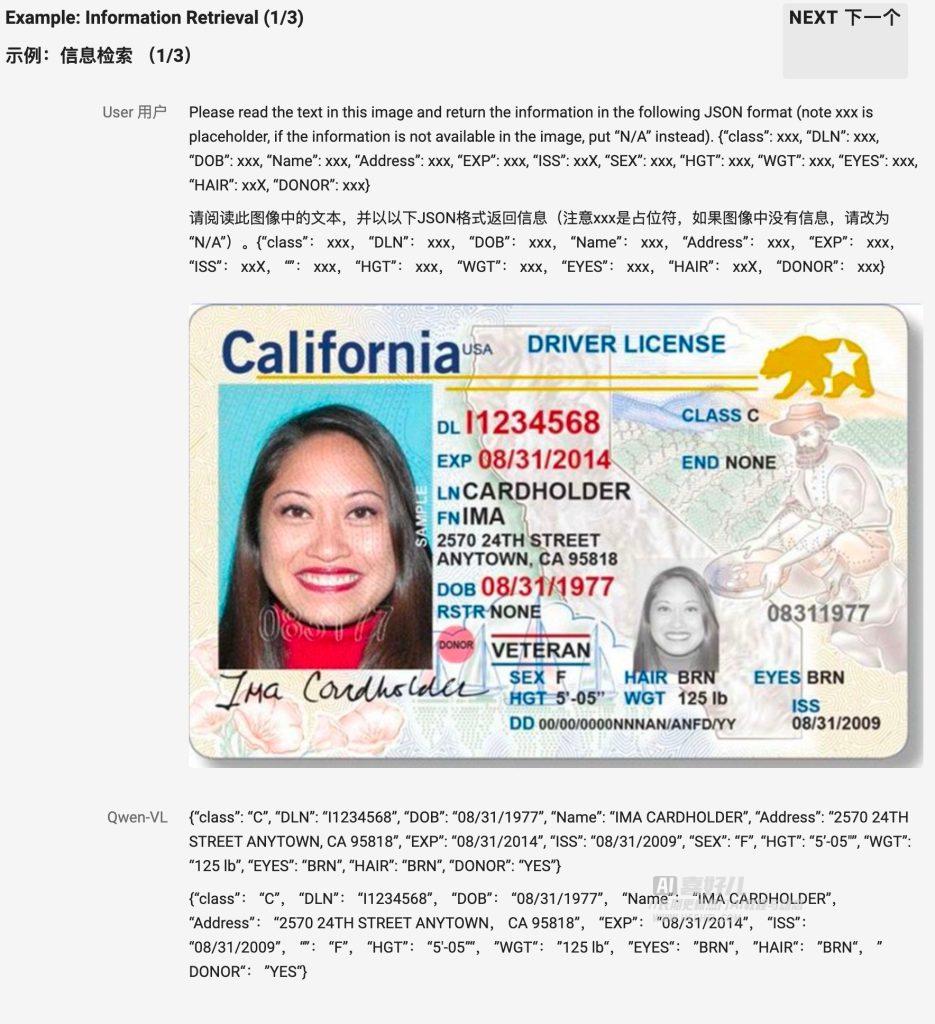
然鹅,这个Qwen-VL已经被网友-Zho-集成到了ComfyUI里面去了,想要的小伙伴点下面的链接下载吧。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/木道寻08/article/detail/738055
推荐阅读
相关标签

