- 1SQL Server2012 学习之(十六) :触发器的创建与使用_sql2012 新建触发器
- 2【大数据导论】大数据序言
- 3金融大语言模型(FinGPT):开源金融大型语言模型(FinTech)_fingpt开源地址
- 4仪酷LabVIEW OD实战(3)——Object Detection+onnx工具包快速实现yolo目标检测_labview onnx
- 5【LocalAI】(3):LocalAI本地使用Model gallery,对qwen模型进行配置,使用modescope源下载,本地运行速度快。特别简单!_localai下载慢
- 6【PostgreSQL】Postgres数据库安装、配置、使用DBLink详解_postgresql dblink
- 7Drools基础语法_drools drl语法
- 8运维系列:tcpdump命令详解_tcpdump抓包命令
- 9ONLYOFFICE协作空间服务器如何一键安装自托管私有化部署_onlyoffice官网私有化部署
- 10什么是监督学习?如何理解分类和回归?
PaDiM 无监督异常检测和定位-论文和源码阅读
赞
踩
目录
1.2.1 特征提取embedding extraction
1.2.2 正样本学习Learning of the normality
1.2.3 计算异常图 inference: computation of the anomaly map
1. 论文
https://arxiv.org/abs/2011.08785

思路:数据特征的分布被假定为一个多元高斯分布,异常值通常在多元高斯分布中表现为远离数据集的中心(均值向量)的数据点。协方差矩阵可以描述各个特征之间的相关性和离散程度。通过计算数据点相对于协方差矩阵的马氏距离,可以识别潜在的异常点。
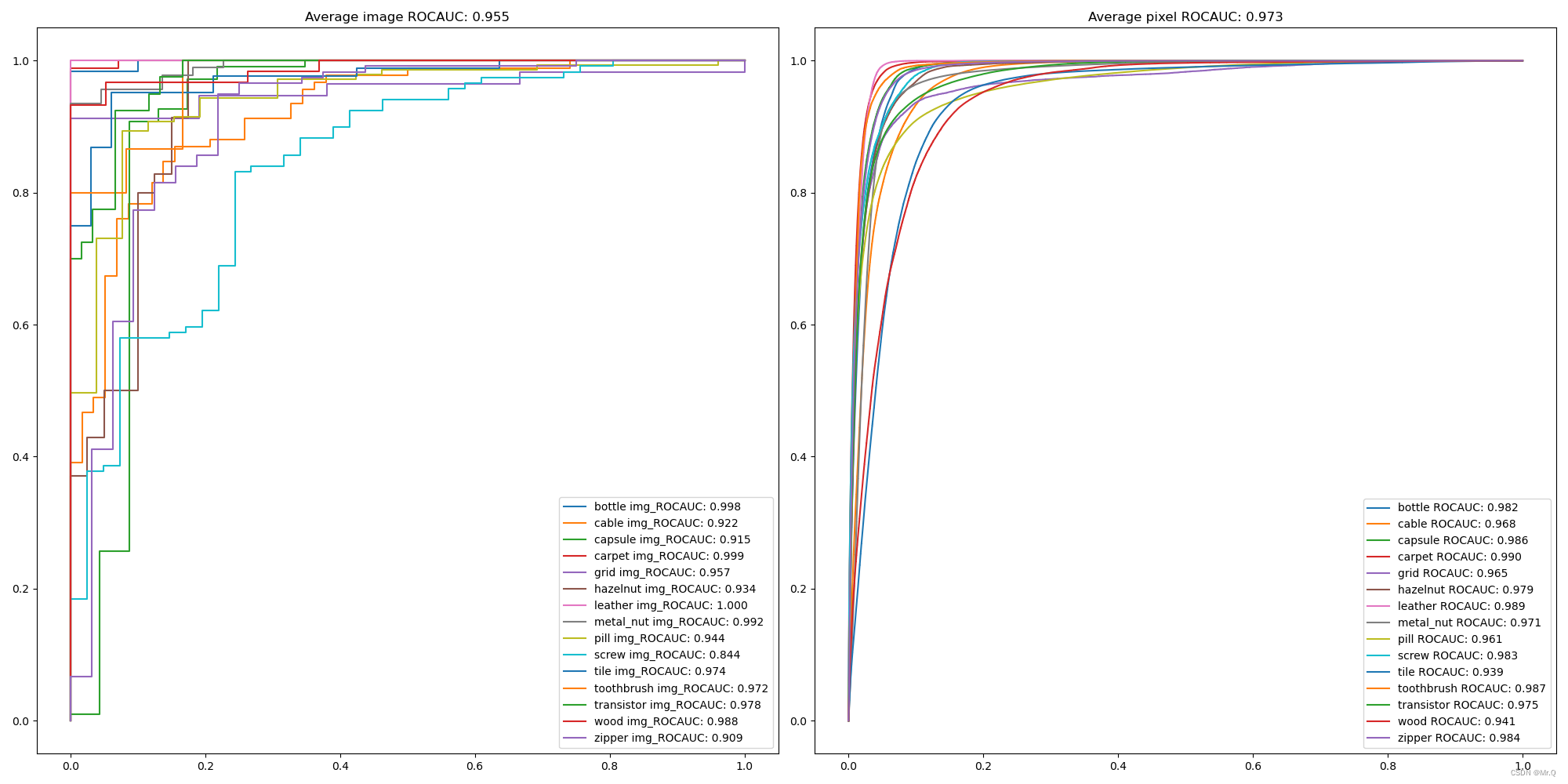
1.1 检测效果

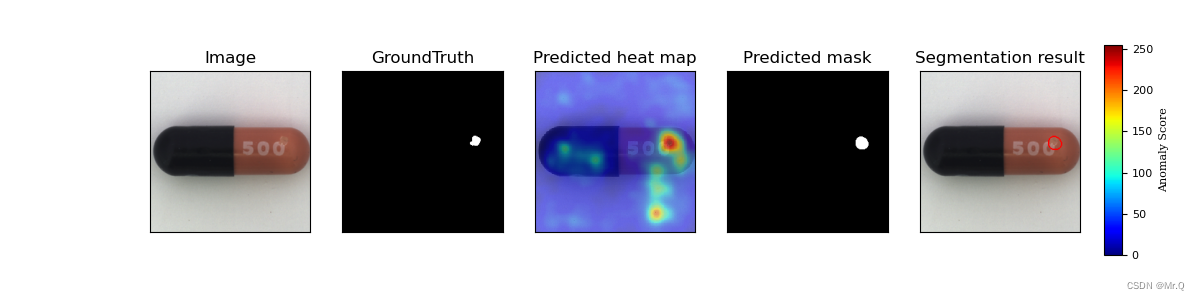
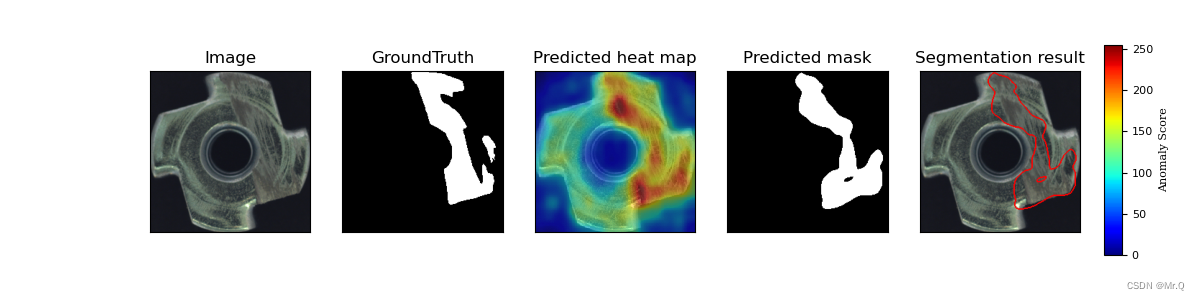
 SPADE精度不错,但是推理会非常慢,因为算法是基于KNN,测试的时候要访问整个训练正常数据集的embedding vectors。
SPADE精度不错,但是推理会非常慢,因为算法是基于KNN,测试的时候要访问整个训练正常数据集的embedding vectors。
PaDiM backbone是resnet18,然后随机选100个特征,和backbone是Wide ResNet-50-2 (WR50) 然后随机选550个特征,可以看到后者的精度更高。
1.2 优缺点
优点:(1)不需要训练过程,输入无缺陷数据,直接使用resnet或者efficient等预训练网络的特征提取层前三层,进行特征,拼接在一起对无缺陷数据建模,速度比起训练快了很多很多;(2)建模过程只需要无缺陷数据;
缺点:(1)由于是使用预训练网络,所以图像需要缩放到对应网络的输入尺度下,才能使用预训练权重,比如efficient和resnet官方预训练网络的输入都是224,则对于小缺陷,缩放到224会损失精度;(2)误判问题,训练的无缺陷数据需要足够多样,否则测试图像稍微和建模的数据不同则会误判(3)阈值问题,测试时会计算测试特征和建模特征之间的距离,然后设定一个阈值,超过阈值则为缺陷,但是这个阈值有时很难界定。
1.3 框架
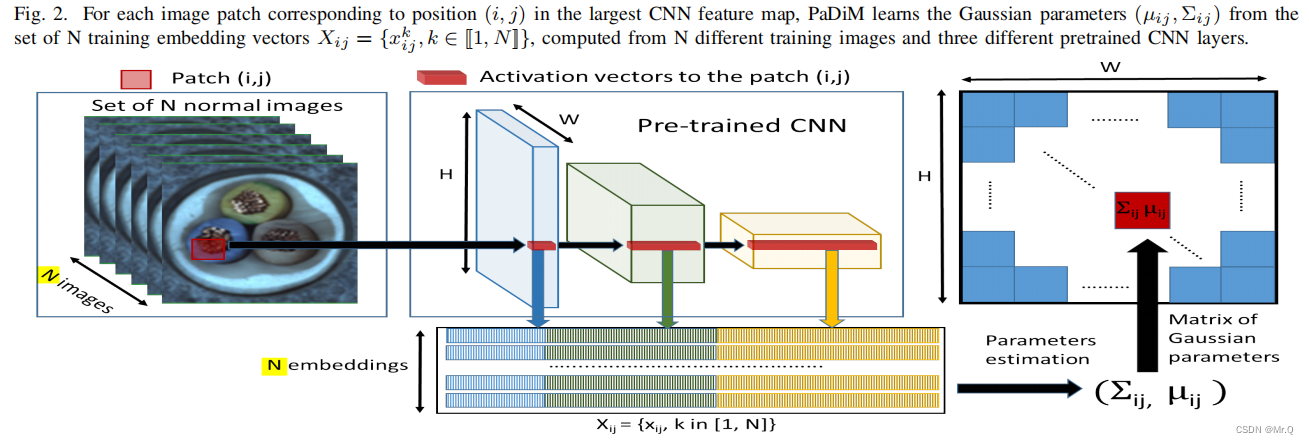
步骤如下:
1.2.1 特征提取embedding extraction
将与此图像块相对应的三个激活图区域特征concat在一起,组成一个特征向量(这样向量就包含了多尺度信息)。N张图,就有N个特征向量。组成X_ij特征空间,该过程不需要训练,直接用预训练权重比如resnet18、resnet50;
(1) infer
layer1: batch infer -> (b,256,56,56) ->cat->(img_num,256,56,56)
layer2: batch infer -> (b,512,28,28) ->cat->(img_num,512,28,28)
layer3: batch infer -> (b,1024,14,14) ->cat->(img_num,1024,14,14)
全部cat在一起, 得到embedding_vectors (img_num,1792,56,56).
(2) 随机选择d个特征
embedding_vectors有56*56个特征块,每个块有1792长度的特征,随机选d(550)个特征。
embedding_vectors.shape -> (img_num,550,56,56).
1.2.2 正样本学习Learning of the normality
为了求整个正样本数据分布情况,作者假设数据是符合多元高斯分布,然后求取此分布的参数: 均值mean和协方差covariance。
(1)均值:特征均值是某一特征(或变量)在数据集中的平均值。它是所有样本中某一特征的数值之和除以样本数量。特征均值用来表示数据在这一特征上的中心趋势。
- B, C, H, W = embedding_vectors.size()
- embedding_vectors = embedding_vectors.view(B, C, H * W) # (img_num,550,56,56) -> (img_num,550,3136). 3136块
- mean = torch.mean(embedding_vectors, dim=0).numpy() # (550,3136). 整个数据集的均值
(2)协方差:协方差反映了多个变量之间的相关性以及它们与各自均值的偏离程度,如果一个变量的值在均值附近波动较大(方差大),那么它对协方差的贡献也会较大。
(3)协方差矩阵:有p个特征,协方差矩阵是一个p x p的矩阵,其中每个元素(i, j)表示特征i和特征j之间的协方差。协方差矩阵通常用Σ来表示。 协方差矩阵的对角线上的元素是各个特征的方差(方差是协方差自己和自己的情况),而非对角线上的元素是不同特征之间的协方差。协方差矩阵计算公式如下。

是第k个图像的图像块ij的特征向量(向量长度是550,所以得到的协方差矩阵大小是(550,550)),
是整个正样本数据集的图像块ij位置上的特征均值向量()。
是正常项。N是数据集中正常图像个数。每个块都有自己的协方差矩阵。
1.2.3 计算异常图 inference: computation of the anomaly map
基于前面求得的正常样本均值mean和协方差矩阵covariance的逆,再求测试图像块特征的马氏距离,此距离作为每个块的异常分数。
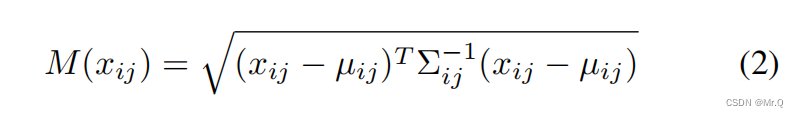
其中是测试图像块的patch embedding. μ和∑是前面正常样本求得的均值和协方差。T是转置,-1是求逆。
2. 源码
https://github.com/xiahaifeng1995/PaDiM-Anomaly-Detection-Localization-master
2.1 dataset
没有数据增强,只有个中心裁剪,因为作者提出的方法没有训练过程,直接使用预训练模型,提取激活层的特征向量。
- import os
- # import tarfile
- from PIL import Image
- from tqdm import tqdm
- # import urllib.request
-
- import torch
- from torch.utils.data import Dataset
- from torchvision import transforms as T
-
-
- # URL = 'ftp://guest:GU.205dldo@ftp.softronics.ch/mvtec_anomaly_detection/mvtec_anomaly_detection.tar.xz'
- CLASS_NAMES = ['bottle', 'cable', 'capsule', 'carpet', 'grid',
- 'hazelnut', 'leather', 'metal_nut', 'pill', 'screw',
- 'tile', 'toothbrush', 'transistor', 'wood', 'zipper']
-
- # CLASS_NAMES = ['len_base']
-
-
- class MVTecDataset(Dataset):
- def __init__(self, dataset_path='D:/dataset/mvtec_anomaly_detection', class_name='bottle', is_train=True,
- resize=256, cropsize=224):
- assert class_name in CLASS_NAMES, 'class_name: {}, should be in {}'.format(class_name, CLASS_NAMES)
- self.dataset_path = dataset_path
- self.class_name = class_name # 'bottle', 'cable' or 'capsule' et al.
- self.is_train = is_train # bool.
- self.resize = resize # 256
- self.cropsize = cropsize # 224 CenterCrop
-
- # load dataset: x:整个数据集的图片路径,对应的label(0/1),对应的缺陷mask图像路径(good类别使用None)。
- self.x, self.y, self.mask = self.load_dataset_folder()
-
- # set transforms
- self.transform_x = T.Compose([T.Resize(resize, Image.ANTIALIAS),
- T.CenterCrop(cropsize),
- T.ToTensor(),
- T.Normalize(mean=[0.485, 0.456, 0.406],
- std=[0.229, 0.224, 0.225])])
- self.transform_mask = T.Compose([T.Resize(resize, Image.NEAREST), # 注意mask
- T.CenterCrop(cropsize),
- T.ToTensor()])
-
- def __getitem__(self, idx):
- x, y, mask = self.x[idx], self.y[idx], self.mask[idx] # 获取路径
-
- x = Image.open(x).convert('RGB')
- x = self.transform_x(x)
-
- if y == 0: # good图像的mask路径是None,所以这里生成全0缺陷mask
- mask = torch.zeros([1, self.cropsize, self.cropsize])
- else:
- mask = Image.open(mask)
- mask = self.transform_mask(mask)
-
- return x, y, mask
-
- def __len__(self):
- return len(self.x)
-
- def load_dataset_folder(self):
- phase = 'train' if self.is_train else 'test'
- x, y, mask = [], [], [] # x:整个数据集的图片路径,对应的label(0/1),对应的缺陷mask图像路径(good类别使用None)。
-
- img_dir = os.path.join(self.dataset_path, self.class_name, phase)
- gt_dir = os.path.join(self.dataset_path, self.class_name, 'ground_truth')
-
- img_types = sorted(os.listdir(img_dir)) # train文件夹下只有good文件夹
- for img_type in img_types: # 遍历不同的文件夹,比如train目录下只有good文件夹。test目录下有各种缺陷文件夹。
-
- # load images
- img_type_dir = os.path.join(img_dir, img_type)
- if not os.path.isdir(img_type_dir):
- continue
- img_fpath_list = sorted([os.path.join(img_type_dir, f)
- for f in os.listdir(img_type_dir)
- if f.endswith('.png')])
- x.extend(img_fpath_list)
-
- # load gt labels。二分类问题:good or not.
- if img_type == 'good':
- y.extend([0] * len(img_fpath_list)) # 如果是good类别,则当前所有图像label都0
- mask.extend([None] * len(img_fpath_list)) # good类别没有缺陷mask
- else:
- y.extend([1] * len(img_fpath_list)) # 不是good,则当前所有图像label都是1
- gt_type_dir = os.path.join(gt_dir, img_type)
- img_fname_list = [os.path.splitext(os.path.basename(f))[0] for f in img_fpath_list]
- gt_fpath_list = [os.path.join(gt_type_dir, img_fname + '_mask.png')
- for img_fname in img_fname_list]
- mask.extend(gt_fpath_list) # 并保存对应的mask图像路径
-
- assert len(x) == len(y), 'number of x and y should be same'
-
- return list(x), list(y), list(mask)
2.2 model
- from torchvision.models import wide_resnet50_2, resnet18
-
- def main():
-
- args = parse_args()
-
- # 1, load model
- if args.arch == 'resnet18':
- model = resnet18(pretrained=True, progress=True)
- t_d = 448
- d = 100
- elif args.arch == 'wide_resnet50_2':
- model = wide_resnet50_2(pretrained=True, progress=True)
- t_d = 1792 #
- d = 550
- model.to(device)
- model.eval()
-
- # 这一行将Python内置的random模块的随机种子设置为1024。设置种子可以确保在相同种子的情况下,使用该模块进行的任何随机操作都会生成相同的随机数序列。通常用于实现可重现性。
- random.seed(1024)
- # 这一行将PyTorch的随机数生成器的种子设置为1024。这用于确保在PyTorch内进行的任何随机操作(例如神经网络权重的初始化)在相同种子下生成相同的结果。
- torch.manual_seed(1024)
- if use_cuda:
- # 这一行设置PyTorch的CUDA(GPU)随机数生成器的种子。这将确保在GPU上进行的随机操作在使用种子1024时也能生成可重现的结果。
- torch.cuda.manual_seed_all(1024)
- idx = torch.tensor(sample(range(0, t_d), d)) # 在范围[0,1792]范围内随机生成550个整数。
-
- # set model's intermediate outputs。 只使用中间3个layer输出,第四个layer输出没有使用
- outputs = []
-
- # 提取layer1,layer2,layer3层输出结果。
- def hook(module, input, output):
- outputs.append(output)
- model.layer1[-1].register_forward_hook(hook) # 每次前向都会调用一次hook,然后output会保持到outputs中。
- model.layer2[-1].register_forward_hook(hook)
- model.layer3[-1].register_forward_hook(hook)
2.3 提取特征
没有训练,则不需要定义loss函数、optimizer等等。直接dataset取数据,infer模型推理,获取中间的三个layer输出结果,然后提取特征向量的均值和协方差。
- import random
- from random import sample
- import argparse
- import numpy as np
- import os
- import pickle
- from tqdm import tqdm
- from collections import OrderedDict
-
- import matplotlib.pyplot as plt
- import torch
-
- from torch.utils.data import DataLoader
- from torchvision.models import wide_resnet50_2, resnet18
- import datasets.mvtec as mvtec
-
- # device setup
- from utils import embedding_concat
-
- use_cuda = torch.cuda.is_available()
- device = torch.device('cuda' if use_cuda else 'cpu')
-
-
- def parse_args():
- parser = argparse.ArgumentParser('PaDiM')
- parser.add_argument('--data_path', type=str, default='D:/dataset/mvtec_anomaly_detection')
- parser.add_argument('--save_path', type=str, default='./mvtec_result')
- parser.add_argument('--arch', type=str, choices=['resnet18', 'wide_resnet50_2'], default='wide_resnet50_2')
- return parser.parse_args()
-
-
- def main():
- args = parse_args()
-
- # 1, load model
- if args.arch == 'resnet18':
- model = resnet18(pretrained=True, progress=True)
- t_d = 448
- d = 100
- elif args.arch == 'wide_resnet50_2':
- model = wide_resnet50_2(pretrained=True, progress=True)
- t_d = 1792 # 三个feature通道数的和256+512+1024. 在范围[0,1792]范围内随机生成550个整数。
- d = 550 # 随机选择550个值
- model.to(device) # to cuda
- model.eval()
-
- # 这一行将Python内置的random模块的随机种子设置为1024。设置种子可以确保在相同种子的情况下,使用该模块进行的任何随机操作都会生成相同的随机数序列。通常用于实现可重现性。
- random.seed(1024)
- # 这一行将PyTorch的随机数生成器的种子设置为1024。这用于确保在PyTorch内进行的任何随机操作(例如神经网络权重的初始化)在相同种子下生成相同的结果。
- torch.manual_seed(1024)
- if use_cuda:
- # 这一行设置PyTorch的CUDA(GPU)随机数生成器的种子。这将确保在GPU上进行的随机操作在使用种子1024时也能生成可重现的结果。
- torch.cuda.manual_seed_all(1024)
- idx = torch.tensor(sample(range(0, t_d), d)) # 在范围[0,1792]范围内随机生成550个整数。
-
- # set model's intermediate outputs。 只使用中间3个layer输出,第四个layer输出没有使用
- outputs = []
-
- # 提取layer1,layer2,layer3层输出结果。
- def hook(module, input, output):
- outputs.append(output)
-
- model.layer1[-1].register_forward_hook(hook) # 每次前向都会调用一次hook,然后output会保持到outputs中。
- model.layer2[-1].register_forward_hook(hook)
- model.layer3[-1].register_forward_hook(hook)
-
- # 创建特征pickle文件保存路径,其实就是存放[mean, cov],每个数据集都有一个pickle文件。
- os.makedirs(os.path.join(args.save_path, 'temp_%s' % args.arch), exist_ok=True)
- fig, ax = plt.subplots(1, 2, figsize=(20, 10)) # 一行两列fig
-
- for class_name in mvtec.CLASS_NAMES: # 遍历不同的数据集
- # 2, dataset
- train_dataset = mvtec.MVTecDataset(args.data_path, class_name=class_name, is_train=True)
- train_dataloader = DataLoader(train_dataset, batch_size=32, pin_memory=True)
- # layer1:所有数据集layer1输出向量,每个向量的shape是[b,256,56,56]
- # layer2: 所有数据集layer2输出向量,每个向量的shape是[b,512,28,28]
- # layer3: 所有数据集layer3输出向量,每个向量的shape是[b,1024,14,14]
- train_outputs = OrderedDict([('layer1', []), ('layer2', []), ('layer3', [])])
-
- # 3, extract train set features (pickle文件保存)
- train_feature_filepath = os.path.join(args.save_path, 'temp_%s' % args.arch, 'train_%s.pkl' % class_name)
- if not os.path.exists(train_feature_filepath): # 不存在此数据集的特征pickle文件,则进行特征提取
- for (x, _, _) in tqdm(train_dataloader, '| feature extraction | train | %s |' % class_name):
- # model prediction
- with torch.no_grad(): # 没有训练,x(b,32,224,224) to cuda,然后直接 batch infer
- _ = model(x.to(device)) # 没有使用返回结果,因为前面定义了hook保存了中间结果到outputs
- # get intermediate layer outputs
- for k, v in zip(train_outputs.keys(), outputs): # 保存3个cuda tensor到字典中
- train_outputs[k].append(v.cpu().detach())
- # initialize hook outputs
- outputs = [] # 置空,迭代赋值
- for k, v in train_outputs.items():
- train_outputs[k] = torch.cat(v, 0) # list of tensor(b,256,56,56). -> (img_num,256,56,56)
-
- # Embedding concat
- embedding_vectors = train_outputs['layer1']
- for layer_name in ['layer2', 'layer3']:
- embedding_vectors = embedding_concat(embedding_vectors, train_outputs[layer_name])
-
- # randomly select d dimension
- embedding_vectors = torch.index_select(embedding_vectors, 1, idx) # 在范围[0,1792]范围内随机生成550个整数。
-
- # calculate multivariate Gaussian distribution
- B, C, H, W = embedding_vectors.size()
- embedding_vectors = embedding_vectors.view(B, C, H * W) # (img_num,550,56,56) -> (img_num,550,3136). 3136块
- mean = torch.mean(embedding_vectors, dim=0).numpy() # (550,3136). 整个数据集的均值
- cov = torch.zeros(C, C, H * W).numpy() # (550,550,3136)协方差矩阵
- I = np.identity(n=C) # (550,550).单位矩阵
- for i in range(H * W): # 依次求每个块的协方差矩阵(550,550)。每个块都有自己的协方差矩阵。
- # cov[:, :, i] = LedoitWolf().fit(embedding_vectors[:, :, i].numpy()).covariance_
- # np.cov: covariance matrix
- # rowvar=False: each column represents a variable(特征、变量), while the rows contain observations(观察,样本).
- cov[:, :, i] = np.cov(embedding_vectors[:, :, i].numpy(), rowvar=False) + 0.01 * I
- # save learned distribution
- train_outputs = [mean, cov] # list of numpy. mean.shape=(550,3136). cov.shape=(550,550,3136)
- with open(train_feature_filepath, 'wb') as f:
- print("start dump feature: %s --------" % class_name)
- pickle.dump(train_outputs, f)
- print("finish dump-----------")
- else: # 已存在,则直接载入。
- print('The file already exists: %s' % train_feature_filepath)
-
-
- if __name__ == '__main__':
- main()
2.4 infer
- import random
- from random import sample
- import argparse
- import numpy as np
- import os
- import pickle
- from tqdm import tqdm
- from collections import OrderedDict
- from sklearn.metrics import roc_auc_score
- from sklearn.metrics import roc_curve
- from sklearn.metrics import precision_recall_curve
- from scipy.spatial.distance import mahalanobis
- from scipy.ndimage import gaussian_filter
- import matplotlib.pyplot as plt
-
- import torch
- import torch.nn.functional as F
- from torch.utils.data import DataLoader
- from torchvision.models import wide_resnet50_2, resnet18
- import datasets.mvtec as mvtec
-
- # device setup
- from utils import embedding_concat, plot_fig
-
- use_cuda = torch.cuda.is_available()
- device = torch.device('cuda' if use_cuda else 'cpu')
-
-
- def parse_args():
- parser = argparse.ArgumentParser('PaDiM')
- parser.add_argument('--data_path', type=str, default='D:/dataset/mvtec_anomaly_detection')
- parser.add_argument('--save_path', type=str, default='./mvtec_result')
- parser.add_argument('--arch', type=str, choices=['resnet18', 'wide_resnet50_2'], default='wide_resnet50_2')
- return parser.parse_args()
-
-
- def main():
- args = parse_args()
-
- # 1, load model
- if args.arch == 'resnet18':
- model = resnet18(pretrained=True, progress=True)
- t_d = 448
- d = 100
- elif args.arch == 'wide_resnet50_2':
- model = wide_resnet50_2(pretrained=True, progress=True)
- t_d = 1792 # 三个feature通道数的和256+512+1024. 在范围[0,1792]范围内随机生成550个整数。
- d = 550 # 随机选择550个值
- model.to(device) # to cuda
- model.eval()
-
- # 这一行将Python内置的random模块的随机种子设置为1024。设置种子可以确保在相同种子的情况下,使用该模块进行的任何随机操作都会生成相同的随机数序列。通常用于实现可重现性。
- random.seed(1024)
- # 这一行将PyTorch的随机数生成器的种子设置为1024。这用于确保在PyTorch内进行的任何随机操作(例如神经网络权重的初始化)在相同种子下生成相同的结果。
- torch.manual_seed(1024)
- if use_cuda:
- # 这一行设置PyTorch的CUDA(GPU)随机数生成器的种子。这将确保在GPU上进行的随机操作在使用种子1024时也能生成可重现的结果。
- torch.cuda.manual_seed_all(1024)
- idx = torch.tensor(sample(range(0, t_d), d)) # 在范围[0,1792]范围内随机生成550个整数。
-
- # set model's intermediate outputs。 只使用中间3个layer输出,第四个layer输出没有使用
- outputs = []
-
- # 提取layer1,layer2,layer3层输出结果。
- def hook(module, input, output):
- outputs.append(output)
-
- model.layer1[-1].register_forward_hook(hook) # 每次前向都会调用一次hook,然后output会保持到outputs中。
- model.layer2[-1].register_forward_hook(hook)
- model.layer3[-1].register_forward_hook(hook)
-
- # 创建特征pickle文件保存路径,其实就是存放[mean, cov],每个数据集都有一个pickle文件。
- os.makedirs(os.path.join(args.save_path, 'temp_%s' % args.arch), exist_ok=True)
- fig, ax = plt.subplots(1, 2, figsize=(20, 10)) # 一行两列fig
- fig_img_rocauc = ax[0] # 第0列fig
- fig_pixel_rocauc = ax[1] # 第1列fig
-
- total_roc_auc = [] # test auc list. 不同class的auc
- total_pixel_roc_auc = [] #
-
- for class_name in mvtec.CLASS_NAMES: # 遍历不同的数据集
- train_feature_filepath = os.path.join(args.save_path, 'temp_%s' % args.arch, 'train_%s.pkl' % class_name)
- with open(train_feature_filepath, 'rb') as f:
- train_outputs = pickle.load(f)
-
- # 2, dataset
- test_dataset = mvtec.MVTecDataset(args.data_path, class_name=class_name, is_train=False)
- test_dataloader = DataLoader(test_dataset, batch_size=32, pin_memory=True)
- # layer1:所有数据集layer1输出向量,每个向量的shape是[b,256,56,56]
- # layer2: 所有数据集layer2输出向量,每个向量的shape是[b,512,28,28]
- # layer3: 所有数据集layer3输出向量,每个向量的shape是[b,1024,14,14]
- test_outputs = OrderedDict([('layer1', []), ('layer2', []), ('layer3', [])])
-
- gt_list = []
- gt_mask_list = []
- test_imgs = []
-
- # 4, extract test set features
- for (x, y, mask) in tqdm(test_dataloader, '| feature extraction | test | %s |' % class_name):
- test_imgs.extend(x.cpu().detach().numpy())
- gt_list.extend(y.cpu().detach().numpy())
- gt_mask_list.extend(mask.cpu().detach().numpy())
- # model prediction
- with torch.no_grad():
- _ = model(x.to(device)) # x to cuda. x.shape=(32,3,224,224)
- # get intermediate layer outputs
- for k, v in zip(test_outputs.keys(), outputs):
- test_outputs[k].append(v.cpu().detach())
- # initialize hook outputs
- outputs = []
- for k, v in test_outputs.items():
- test_outputs[k] = torch.cat(v, 0)
-
- # Embedding concat. 将不同层的输出cat在一起
- # layer1(img_num,256,56,56),layer2(img_num,512,28,28),layer3(img_num,1024,14,14)
- embedding_vectors = test_outputs['layer1']
- for layer_name in ['layer2', 'layer3']:
- embedding_vectors = embedding_concat(embedding_vectors, test_outputs[layer_name])
-
- # randomly select d dimension. embedding_vectors.shape=torch.Size([img_num, 1792, 56, 56])
- # 注意idx,要和前面train一样。
- embedding_vectors = torch.index_select(embedding_vectors, 1, idx) # (img_num,1792,56,56)->(img_num,550,56,56)
-
- # 5. calculate distance matrix
- B, C, H, W = embedding_vectors.size()
- embedding_vectors = embedding_vectors.view(B, C, H * W).numpy() # (img_num,550,56,56)->(img_num,550,56*56)
- dist_list = []
- for i in range(H * W): # 遍历每个patch
- mean = train_outputs[0][:, i] # train_outputs=[mean(550,3136), cov(550,550,3136)]. 第i块均值
- conv_inv = np.linalg.inv(train_outputs[1][:, :, i]) # 第i块协方差矩阵的逆矩阵。(550,550)
-
- # embedding_vectors.shape(img_num,550,3136). sample.shape(550,3136)
- # 特征块 sample[:, i].shape(550). 均值mean.shape(550). 协方差矩阵的逆矩阵conv_inv(550,550)
- # dist. list of dis. len=(img_num). 每张图像的每个patch有一个距离值. scipy.spatial.distance
- dist = [mahalanobis(sample[:, i], mean, conv_inv) for sample in embedding_vectors] # 遍历测试图像,马氏距离
- dist_list.append(dist) # {0: list(img_num), 1: list(img_num), patch_idx: list(img_num)}
-
- dist_list = np.array(dist_list).transpose(1, 0).reshape(B, H, W) # (patch_num,image_num)->(83,3136)->(83,56,56)
-
- # 6. upsample distance map.
- dist_list = torch.tensor(dist_list)
- score_map = F.interpolate(dist_list.unsqueeze(1), size=x.size(2), mode='bilinear',
- align_corners=False).squeeze().numpy() # (83,56,56)->(83,224,224)
-
- # 7. apply gaussian smoothing on the score map. 将patch score平滑成image score.
- for i in range(score_map.shape[0]): # each test image. scipy.ndimage
- score_map[i] = gaussian_filter(score_map[i], sigma=4) # (224,224)
-
- # Normalization. val->(0,1)
- max_score = score_map.max()
- min_score = score_map.min()
- scores = (score_map - min_score) / (max_score - min_score) # (img_num,224,224)
-
- # 8. calculate image-level ROC AUC score. 图像级别的异常分数
- img_scores = scores.reshape(scores.shape[0], -1).max(
- axis=1) # (img_num,224,224) -> (img_num,224*224) ->(img_num)
- gt_list = np.asarray(gt_list) # (img_num,)
- fpr, tpr, _ = roc_curve(gt_list, img_scores) # sklearn.metrics. shape (img_num)
- img_roc_auc = roc_auc_score(gt_list, img_scores) # auc.
- total_roc_auc.append(img_roc_auc) # auc list
- print('image ROCAUC: %.3f' % (img_roc_auc)) # 当前数据集类别(bottle)的auc
- fig_img_rocauc.plot(fpr, tpr, label='%s img_ROCAUC: %.3f' % (class_name, img_roc_auc))
-
- # get optimal threshold:# 使用最大F值对应的那个阈值(同时考虑召回率和准确率)
- gt_mask = np.asarray(gt_mask_list) # list of tensor. -> (img_num,1,224,224). scores.shape(img_num,224,224)
- # thresholds不同的阈值,返回不同的准确率和召回率
- precision, recall, thresholds = precision_recall_curve(gt_mask.flatten(), scores.flatten()) # sklearn.metrics
- a = 2 * precision * recall # 不同的阈值下,求F值
- b = precision + recall # a/b
- f1 = np.divide(a, b, out=np.zeros_like(a), where=b != 0) # 防止除0操作
- threshold = thresholds[np.argmax(f1)] # 使用最大F值对应的那个阈值。
-
- # calculate per-pixel level ROCAUC. (img_num,1,224,224). scores.shape(img_num,224,224)
- fpr, tpr, _ = roc_curve(gt_mask.flatten(), scores.flatten())
- per_pixel_rocauc = roc_auc_score(gt_mask.flatten(), scores.flatten())
- total_pixel_roc_auc.append(per_pixel_rocauc)
- print('pixel ROCAUC: %.3f' % (per_pixel_rocauc))
-
- fig_pixel_rocauc.plot(fpr, tpr, label='%s ROCAUC: %.3f' % (class_name, per_pixel_rocauc))
- save_dir = args.save_path + '/' + f'pictures_{args.arch}'
- os.makedirs(save_dir, exist_ok=True)
- # 原图list (3,224,224).
- plot_fig(test_imgs, scores, gt_mask_list, threshold, save_dir, class_name)
-
- print('Average ROCAUC: %.3f' % np.mean(total_roc_auc))
- fig_img_rocauc.title.set_text('Average image ROCAUC: %.3f' % np.mean(total_roc_auc))
- fig_img_rocauc.legend(loc="lower right")
-
- print('Average pixel ROCUAC: %.3f' % np.mean(total_pixel_roc_auc))
- fig_pixel_rocauc.title.set_text('Average pixel ROCAUC: %.3f' % np.mean(total_pixel_roc_auc))
- fig_pixel_rocauc.legend(loc="lower right")
-
- fig.tight_layout()
- fig.savefig(os.path.join(args.save_path, 'roc_curve.png'), dpi=100)
-
-
-
-
- if __name__ == '__main__':
- main()