
- 1SqlServer各版本下载(2016-2019)_sql server 2019 standard (x64) - dvd 英文
- 2Android-View 绘制原理(01)-JAVA层分析_android view draw原理分析
- 3[The RUST Programming Language]Chapter 3. Common Programing Concepts (1)_^^^^^^^^ cannot infer type for type `{integer}`
- 4探索中国标准化文献引用:Chinese-STD-GB-T-7714-related-csl
- 5华为AI计算框架昇思MindSpore零基础快速入门 (上)
- 6数据脱敏:守护你的隐私,释放数据的力量_数据脱敏背景
- 7Disco-SLAM算法之Scan-Context
- 8理解NLP中的屏蔽语言模型(MLM)和因果语言模型(CLM)_mlm模型
- 9【论文笔记】《Learning Entity and Relation Embeddings for Knowledge Graph Completion》
- 102024年安卓最全Android Root原理初探,2024Android开发面试解答
MIT6.1810/Fall 2022(which was called 6.S081 then) Lab5-7_mit6.1810(6.s081的2022版本) lab全解
赞
踩
Lab: Copy-on-Write Fork for xv6
8.4 Copy On Write Fork - MIT6.S081 先理解COW机制
Implement copy-on-write fork
您的任务是在xv6内核中实现写时复制分叉。如果修改后的内核成功地执行了cowtest和'usertests -q'程序,那么就完成了。
为了帮助您测试实现,我们提供了一个名为cowtest的xv6程序(源代码在user/cowtest.c中)。Cowtest运行各种测试,但即使第一个测试在未修改的xv6上也会失败。因此,最初,您将看到:
“简单”测试分配了超过一半的可用物理内存,然后fork()。fork失败是因为没有足够的空闲物理内存给子进程提供父进程内存的完整副本。
完成后,内核应该通过cowtest和usertests -q中的所有测试。那就是:
这是一个合理的进攻计划。
1.修改uvmcopy()以将父进程的物理页映射到子进程,而不是分配新页。清除设置了PTE_W的页面的父级和子级pte中的PTE_W。
2.修改usertrap()以识别页面错误。当在最初可写的COW页面上发生写页面错误时,使用kalloc()分配一个新页面,将旧页面复制到新页面,并在PTE_W设置的PTE中安装新页面。原本是只读的页面(没有映射PTE_W,像文本段中的页面)应该保持只读并在父和子之间共享;试图写这样一个页面的进程应该被杀死。
3.确保每个物理页在最后一个PTE引用消失时被释放——但不是在此之前。实现这一点的一个好方法是为每个物理页面保持一个“引用计数”,即引用该页面的用户页表的数量。当kalloc()分配页面时,将页面的引用计数设置为1。当fork导致子进程共享该页时,增加该页的引用计数,当任何进程从其页表中删除该页时,减少该页的计数。Kfree()应该只在引用计数为零的情况下才将页面放回空闲列表。将这些计数保存在固定大小的整数数组中是可以的。您必须制定一个方案,以便为数组建立索引,并选择数组的大小。例如,可以用页的物理地址除以4096对数组进行索引,并通过kinit()在kalloc.c中为数组提供与空闲列表中任何页的最高物理地址相等的元素数。您可以随意修改kalloc.c(例如,kalloc()和kfree())来维护引用计数。
4.修改copyout(),使其在遇到COW页面时使用与页面错误相同的方案。
一些暗示
- 对于每个PTE,有一种记录它是否是COW映射的方法可能是有用的。您可以使用RISC-V PTE中的RSW(为软件保留)位来完成此操作。
- Usertests -q探索了cowtest没有测试的场景,所以不要忘记检查所有测试是否都通过了。
- 一些有用的宏和页表标志的定义在kernel/riscv.h的末尾。
- 如果发生COW页面错误并且没有可用内存,则应该终止该进程。
注意:自己定义的函数记得把声明加到defs.h
在未修改的uvmcopy()中(该函数在fork()中调用,用来让子进程复制父进程的物理页并映射进子进程的页表中),关于内存映射的代码如下,先通过父进程的进程空间的va找到对应的pte,然后提取出物理地址pa和标志位flags,调用kalloc()得到一个空闲的物理页,把pa的内容复制到这个空闲物理页上,再调用mappages来完成va到这个物理页的映射。
- pa = PTE2PA(*pte);
- flags = PTE_FLAGS(*pte);
- if((mem = kalloc()) == 0)
- goto err;
- memmove(mem, (char*)pa, PGSIZE);
- if(mappages(new, i, PGSIZE, (uint64)mem, flags) != 0){
- kfree(mem);
- goto err;
- }
根据题目的意思,首先要在kalloc()和kfree()进行修改,当kalloc()分配页面时,将页面的引用计数设置为1,当fork导致子进程共享该页时,增加该页的引用计数,当任何进程从其页表中删除该页时,减少该页的计数。Kfree()应该只在引用计数为零的情况下才将页面放回空闲列表。
用全局数组来记录每个物理页面保持一个“引用计数”,用页的物理地址除以4096对数组进行索引,在kernel/kalloc.c定义这个全局数组,并实现根据物理地址计算数组元素的索引,根据索引获得数组元素,对数组元素增减或赋值的函数。这里设计到对全局数组进行修改的操作,所以需要使用锁,在kinit()中初始化这个锁。
- struct spinlock ref_lock;
- int pm_ref[(PHYSTOP - KERNBASE)/PGSIZE];
-
- void
- kinit()
- {
- initlock(&kmem.lock, "kmem");
- initlock(&ref_lock,"ref");
- freerange(end, (void*)PHYSTOP);
- }
-
-
- uint64
- getRefIdx(uint64 pa){
- return (pa-KERNBASE)/PGSIZE;
- }
-
- void
- refup(void* pa){
- acquire(&ref_lock);
- pm_ref[getRefIdx((uint64)pa)] ++;
- release(&ref_lock);
- }
-
- void
- refdown(void* pa){
- acquire(&ref_lock);
- pm_ref[getRefIdx((uint64)pa)] --;
- release(&ref_lock);
- }
-
- void
- refinit(void *pa){
- acquire(&ref_lock);
- pm_ref[getRefIdx((uint64)pa)] =1;
- release(&ref_lock);
- }
-
- int
- get_refcnt(void *pa){
- if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
- panic("get_refcnt");
- acquire(&ref_lock);
- int ret = pm_ref[getRefIdx((uint64)pa)];
- release(&ref_lock);
- return ret;
- }

对于kfree(),只有引用计数小于或等于1时才会真正的free物理页。对于kalloc(),在分配物理页时在对应的ref数组元素赋初值。
- void
- kfree(void *pa)
- {
- struct run *r;
-
- if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
- panic("kfree");
-
- //只有引用计数<=1才会真正free物理页
- if(get_refcnt(pa) > 1){
- refdown(pa);
- return;
- }
- // Fill with junk to catch dangling refs.
- memset(pa, 1, PGSIZE);
-
- r = (struct run*)pa;
-
- acquire(&kmem.lock);
- r->next = kmem.freelist;
- kmem.freelist = r;
- release(&kmem.lock);
- }
-
- // Allocate one 4096-byte page of physical memory.
- // Returns a pointer that the kernel can use.
- // Returns 0 if the memory cannot be allocated.
- void *
- kalloc(void)
- {
- struct run *r;
-
- acquire(&kmem.lock);
- r = kmem.freelist;
- if(r){
- kmem.freelist = r->next;
- //物理页赋初值
- refinit((void*)r);
- }
-
- release(&kmem.lock);
-
- if(r)
- memset((char*)r, 5, PGSIZE); // fill with junk
- return (void*)r;
- }
kalloc()和kfree()正确修改后,就可以对uvmcopy()进行更改。

根据lec8的内容,设置第八位为COW位,在riscv.h添加
#define PTE_COW (1L << 8)对于uvmcopy(),首先是对父进程的物理页进行设置,全部设置为"COW"的。并且修改函数的行为使不再分配新的物理页给子进程并复制再映射,而是让子进程直接映射父进程的物理页。
- int
- uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
- {
- pte_t *pte;
- uint64 pa, i;
- uint flags;
- //char *mem;
-
- for(i = 0; i < sz; i += PGSIZE){
- if((pte = walk(old, i, 0)) == 0)
- panic("uvmcopy: pte should exist");
- if((*pte & PTE_V) == 0)
- panic("uvmcopy: page not present");
-
- //把原本可写的物理页变成只读的COW页
- if(*pte & PTE_W){
- *pte |= PTE_COW;
- *pte &= ~PTE_W;
- }
- pa = PTE2PA(*pte);
- flags = PTE_FLAGS(*pte);
-
- if(mappages(new, i, PGSIZE, (uint64)pa, flags) != 0){
- printf("uvmcopy: mappages\n");
- goto err;
- }
- //引用计数++
- refup((void *)pa);
- }
- return 0;
-
- err:
- uvmunmap(new, 0, i / PGSIZE, 1);
- return -1;
- }
通过上述的修改,子进程或父进程对COW的物理页进行写入操作时,就会触发page fault然后陷入内核,根据XV6的trap机制就会执行到trampoline的uservec保存寄存器,然后跳转到usertrap()中进行异常处理,于是接下来就要修改usertrap()。
下图为不同的造成陷入内核的原因对应的SCAUSE寄存器保存的值
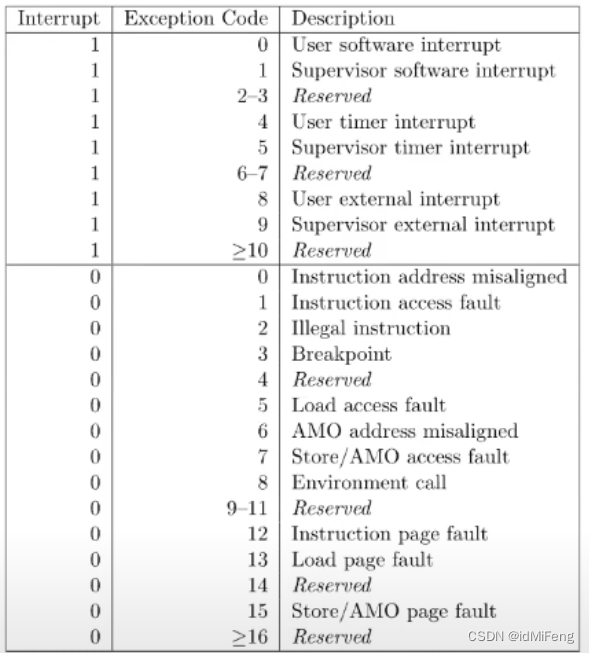
有关写入操作的是Store/AMO Page Fault (写入数据时的页故障) ,它的异常号是15,所以我们对usertrap()多加一个判断分支,当sscause寄存器的值是15并且stval寄存器的值是COW页,那么就可以分配一个新的物理页,让当前的虚拟页映射到新的物理页。
- void
- usertrap(void)
- {
- int which_dev = 0;
-
- if((r_sstatus() & SSTATUS_SPP) != 0)
- panic("usertrap: not from user mode");
-
- // send interrupts and exceptions to kerneltrap(),
- // since we're now in the kernel.
- w_stvec((uint64)kernelvec);
-
- struct proc *p = myproc();
-
- // save user program counter.
- p->trapframe->epc = r_sepc();
-
- if(r_scause() == 8){
- // system call
-
- if(killed(p))
- exit(-1);
-
- // sepc points to the ecall instruction,
- // but we want to return to the next instruction.
- p->trapframe->epc += 4;
-
- // an interrupt will change sepc, scause, and sstatus,
- // so enable only now that we're done with those registers.
- intr_on();
-
- syscall();
- } else if((which_dev = devintr()) != 0){
- // ok
- } else if(r_scause() == 15 && iscowpage(p->pagetable,r_stval())){
- cowcopy(p->pagetable,r_stval());
- }else {
- printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
- printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
- setkilled(p);
- }
-
- if(killed(p))
- exit(-1);
-
- // give up the CPU if this is a timer interrupt.
- if(which_dev == 2)
- yield();
-
- usertrapret();
- }
在上述函数中,首先是判断是否是COW页的函数,大体逻辑就是通过va找到pte后,看是否有效并且有PTE_COW
- int
- iscowpage(pagetable_t pagetable, uint64 va){
- va = PGROUNDDOWN((uint64)va);
- if(va >= MAXVA)
- return 0;
- pte_t* pte = walk(pagetable,va,0);
- if((*pte & PTE_COW) && (*pte & PTE_V))
- return 1;
- else
- return 0;
- }
然后是关键的映射新的物理页的cowcopy(),流程就是申请新物理页,复制物理页内容到新物理页,取消原来的va-pa映射关系,建立新的va-new pa映射关系。注意要处理只有一个引用计数的情况,这时候只需对原来物理页进行修改让它可写。
- void
- cowcopy(pagetable_t pagetable, uint64 va){
- uint64 pa, new_pa;
- uint flags;
- va = PGROUNDDOWN(va);
- pte_t *pte = walk(pagetable, va, 0);
- flags = PTE_FLAGS(*pte);
- pa = PTE2PA(*pte);
- if(get_refcnt((void *) pa) > 1){
- if((new_pa = (uint64) kalloc()) == 0) // 申请一个物理页。
- panic("cowcopy: kalloc");
- memmove((void *)new_pa, (const void *) pa, PGSIZE); // 将原物理页中的内容复制到新物理页中。
- uvmunmap(pagetable, va, 1, 1); // 解除虚拟页和原物理页的映射关系。
- flags &= ~PTE_COW; // 清除页表项中的 COW 位。
- flags |= PTE_W; // 设置页表项中的 W 位。
- if(mappages(pagetable, va, PGSIZE, new_pa, flags) != 0){// 建立虚拟页和新物理页的映射关系。
- kfree((void *)new_pa);
- panic("cowcopy: mappages");
- }
- } else if(get_refcnt((void *) pa) == 1){
- *pte |= PTE_W;
- *pte &= ~PTE_COW;
- }else{
- printf("get_refcnt((void *) pa)=%d\n",get_refcnt((void *) pa));
- panic("cowcopy: refcnt");
- }
- }
这样COW机制就已经实现了,接下来还有一个copyout(),该函数目的是从内核复制数据到用户空间,我们要进行的处理是当复制到COW的物理页时,要把原本的COW物理页变成正常物理页,再进行复制操作,不然后续如果对该页面执行写入操作就会触发错误。
- int
- copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
- {
- uint64 n, va0, pa0;
-
- while(len > 0){
- va0 = PGROUNDDOWN(dstva);
- if(iscowpage(pagetable,va0)){
- cowcopy(pagetable,va0);
- }
- pa0 = walkaddr(pagetable, va0);
- if(pa0 == 0)
- return -1;
- n = PGSIZE - (dstva - va0);
- if(n > len)
- n = len;
- memmove((void *)(pa0 + (dstva - va0)), src, n);
-
- len -= n;
- src += n;
- dstva = va0 + PGSIZE;
- }
- return 0;
- }
Lab: Multithreading
Uthread: switching between threads
在本练习中,您将为用户级线程系统设计上下文切换机制,然后实现它。首先,您的xv6有两个文件user/uthread.c和user/uthread_switch.S,并在Makefile中添加一条规则来构建一个线程程序。c包含了大部分用户级线程包,以及三个简单测试线程的代码。线程包缺少一些创建线程和在线程之间切换的代码。
您的工作是提出一个计划来创建线程和保存/恢复寄存器以在线程之间切换,并实现该计划。当你完成后,评分应该表明你的解决方案通过了线程测试。您需要将代码添加到user/uthread.c中的thread_create()和thread_schedule(),以及user/uthread_switch.S中的thread_switch。一个目标是确保当thread_schedule()第一次运行给定线程时,线程在自己的堆栈上执行传递给thread_create()的函数。另一个目标是确保thread_switch保存被切换到的线程的寄存器,恢复被切换到的线程的寄存器,并返回到后一个线程指令中它最后离开的位置。您必须决定在何处保存/恢复寄存器;修改结构线程来保存寄存器是一个很好的计划。你需要在thread_schedule中添加一个对thread_switch的调用;您可以向thread_switch传递任何需要的参数,但目的是从线程t切换到next_thread。
一些提示:
Thread_switch只需要保存/恢复被调用者保存寄存器。为什么?
您可以在user/uthread中看到uthread的汇编代码。Asm,它可能对调试很方便。
要测试代码,使用riscv64-linux-gnu-gdb对thread_switch进行单步测试可能会有所帮助。
做这个实验之前把Lec11 Thread switching (Robert) - MIT6.S081看完,了解XV6的多线程机制,这题就是对这个机制简单复刻一下。
关键的步骤就是内核线程调用swtch可以通过ra寄存器返回到当前CPU的调度器线程的swtch的下一条语句,调度器线程再次调用swtch可以通过ra寄存器返回到下一个进程的内核线程执行swtch的下一条语句。借鉴以上思路,首先要在struct thread中加上context字段来保存寄存器,直接copy struct proc的context字段就行。
- struct context {
- uint64 ra;
- uint64 sp;
-
- // callee-saved
- uint64 s0;
- uint64 s1;
- uint64 s2;
- uint64 s3;
- uint64 s4;
- uint64 s5;
- uint64 s6;
- uint64 s7;
- uint64 s8;
- uint64 s9;
- uint64 s10;
- uint64 s11;
- };
-
- struct thread {
- char stack[STACK_SIZE]; /* the thread's stack */
- int state; /* FREE, RUNNING, RUNNABLE */
- struct context context;
- };
在 thread_schedule()中,只需要加上对thread_switch()的调用就行了,大概流程就是:
t是当前线程,next_thread是即将要换到的线程,通过thread_switch()把当前寄存器(当前还在运行t)的值保存在t的context,然后从context_thread的context中把值加载到当前寄存器中。
- void
- thread_schedule(void)
- {
- struct thread *t, *next_thread;
-
- /* Find another runnable thread. */
- next_thread = 0;
- t = current_thread + 1;
- for(int i = 0; i < MAX_THREAD; i++){
- if(t >= all_thread + MAX_THREAD)
- t = all_thread;
- if(t->state == RUNNABLE) {
- next_thread = t;
- break;
- }
- t = t + 1;
- }
-
- if (next_thread == 0) {
- printf("thread_schedule: no runnable threads\n");
- exit(-1);
- }
-
- if (current_thread != next_thread) { /* switch threads? */
- next_thread->state = RUNNING;
- t = current_thread;
- current_thread = next_thread;
- /* YOUR CODE HERE
- * Invoke thread_switch to switch from t to next_thread:
- * thread_switch(??, ??);
- */
- thread_switch((uint64)&t->context, (uint64)&next_thread->context);
-
- } else
- next_thread = 0;
- }
题目要求线程在自己的堆栈上执行传递给thread_create()的函数,在thread_create()中加入初始化代码,使ra指向线程的入口函数,sp指向栈底。注意栈底应该是t->stack[STACK_SIZE - 1],因为栈是从高地址向低地址增长的。设置上下文中 ra 指向的地址为线程函数的地址,这样在第一次调度到该线程,执行到 thread_switch 中的 ret 之后就可以跳转到线程函数从而开始执行了。设置 sp 使得线程拥有自己独有的栈,也就是独立的执行流。
- void
- thread_create(void (*func)())
- {
- struct thread *t;
-
- for (t = all_thread; t < all_thread + MAX_THREAD; t++) {
- if (t->state == FREE) break;
- }
- t->state = RUNNABLE;
- // YOUR CODE HERE
- // thread_switch 的结尾会返回到 ra,从而运行线程代码
- t->context.ra = (uint64)func;
- //设置 sp 使得线程拥有自己独有的栈,也就是独立的执行流
- t->context.sp = (uint64)&t->stack[STACK_SIZE - 1];
- }
对于uthread_switch.S,直接copy swtch.S就行了,也就是保存当前寄存器到t的context,然后从next__thread的context把值加载到当前寄存器。
- .text
-
- /*
- * save the old thread's registers,
- * restore the new thread's registers.
- */
-
- .globl thread_switch
- thread_switch:
- /* YOUR CODE HERE */
- sd ra, 0(a0)
- sd sp, 8(a0)
- sd s0, 16(a0)
- sd s1, 24(a0)
- sd s2, 32(a0)
- sd s3, 40(a0)
- sd s4, 48(a0)
- sd s5, 56(a0)
- sd s6, 64(a0)
- sd s7, 72(a0)
- sd s8, 80(a0)
- sd s9, 88(a0)
- sd s10, 96(a0)
- sd s11, 104(a0)
-
- ld ra, 0(a1)
- ld sp, 8(a1)
- ld s0, 16(a1)
- ld s1, 24(a1)
- ld s2, 32(a1)
- ld s3, 40(a1)
- ld s4, 48(a1)
- ld s5, 56(a1)
- ld s6, 64(a1)
- ld s7, 72(a1)
- ld s8, 80(a1)
- ld s9, 88(a1)
- ld s10, 96(a1)
- ld s11, 104(a1)
- ret /* return to ra */
Using threads
在本作业中,您将探索使用哈希表进行线程和锁并行编程。您应该在具有多个内核的真正的Linux或MacOS计算机(不是xv6,也不是qemu)上执行此任务。大多数最新的笔记本电脑都有多核处理器。
这个作业使用UNIX pthread线程库。您可以通过man pthreads从手册页找到有关它的信息,也可以在web上查找
文件notxv6/ph.c包含一个简单的哈希表,如果从单个线程使用它是正确的,但如果从多个线程使用它就不正确了。在您的主xv6目录中(也许是~/xv6-labs-2021),输入如下:
请注意,要构建ph, Makefile使用的是操作系统的gcc,而不是6.S081工具。ph的参数指定在哈希表上执行put和get操作的线程数。运行一段时间后,ph 1将产生类似于以下的输出:
100000 puts, 3.991 seconds, 25056 puts/second 0: 0 keys missing 100000 gets, 3.981 seconds, 25118 gets/second您看到的数字可能与这个示例输出相差两倍或更多,这取决于您的计算机有多快,是否有多个核心,以及它是否忙于做其他事情。
Ph运行两个基准。首先,它通过调用put()将许多键添加到哈希表中,并以每秒放置次数为单位打印实现的速率。它使用get()从哈希表中获取键。它打印由于put操作而应该在哈希表中但缺少的数字键(在本例中为零),并打印每秒实现的get次数。通过给ph一个大于1的参数,可以告诉它同时从多个线程使用它的哈希表。试试ph 2:
$ ./ph 2 100000 puts, 1.885 seconds, 53044 puts/second 1: 16579 keys missing 0: 16579 keys missing 200000 gets, 4.322 seconds, 46274 gets/second这个ph2输出的第一行表明,当两个线程并发地向哈希表中添加条目时,它们达到了每秒53,044次插入的总速率。这大约是运行ph 1时单线程速率的两倍。这是一个出色的“并行加速”,大约是2倍,这是人们可能希望的(即两倍的内核产生两倍的单位时间的工作)。
但是,缺少16579个键的两行表明,大量本应在哈希表中的键不在哈希表中。也就是说,put应该将这些键添加到哈希表中,但是出了问题。看看notxv6/ph.c,特别是put()和insert()。
为什么有2个线程,而不是1个线程丢失的键?用两个线程确定可能导致丢失密钥的事件序列。在answers-thread.txt中提交您的序列并附上简短的解释
为了避免这种事件序列,请在notxv6/ph.c的put和get中插入lock和unlock语句,以便在两个线程中丢失的键数始终为0。相关的pthread调用是:
pthread_mutex_t锁;//声明pthread_mutex_init(&lock, NULL);//初始化pthread_mutex_lock(&lock);//获取锁pthread_mutex_unlock(&lock);//释放锁
当make grade表示您的代码通过ph_safe测试时,您就完成了,该测试要求两个线程中的零丢失键。此时,ph_fast测试失败也没关系。不要忘记调用pthread_mutex_init()。先用一个线程测试你的代码,然后用两个线程测试。它是否正确(即你是否消除了丢失的键?)?相对于单线程版本,双线程版本是否实现了并行加速(即每单位时间内完成的总工作量更多)?
在某些情况下,并发put()操作在哈希表中读取或写入的内存没有重叠,因此不需要锁来相互保护。您可以更改ph.c以利用这种情况来获得一些put()s的并行加速吗?提示:每个哈希桶加一个锁怎么样?
修改代码,使一些put操作在保持正确性的同时并行运行。当make grade表示代码通过了ph_safe和ph_fast测试时,就完成了。ph_fast测试要求两个线程每秒的put次数至少是一个线程的1.25倍。
首先看ph.c的main函数的关键代码片段,主要就是调用pthread_create ()创建nthread个线程执行 put_thread (),然后调用 pthread_join()等待所有线程的完成。同样,调用 pthread_create() 创建nthread个线程执行 get_thread ()。调用 pthread_join 等待所有线程的完成。
- t0 = now();
- for(int i = 0; i < nthread; i++) {
- assert(pthread_create(&tha[i], NULL, put_thread, (void *) (long) i) == 0);
- }
- for(int i = 0; i < nthread; i++) {
- assert(pthread_join(tha[i], &value) == 0);
- }
- t1 = now();
-
- printf("%d puts, %.3f seconds, %.0f puts/second\n",
- NKEYS, t1 - t0, NKEYS / (t1 - t0));
-
- //
- // now the gets
- //
- t0 = now();
- for(int i = 0; i < nthread; i++) {
- assert(pthread_create(&tha[i], NULL, get_thread, (void *) (long) i) == 0);
- }
- for(int i = 0; i < nthread; i++) {
- assert(pthread_join(tha[i], &value) == 0);
- }
- t1 = now();
-
- printf("%d gets, %.3f seconds, %.0f gets/second\n",
- NKEYS*nthread, t1 - t0, (NKEYS*nthread) / (t1 - t0));
在 put_thread 中,int b = NKEYS/nthread; 计算出每个线程要插入的键值对数量,然后通过 put(keys[b*n + i], n); 的方式,不同的线程会负责不同范围的键值对。其中 n 是线程编号,b 是每个线程要处理的键值对数量。
- static void *
- put_thread(void *xa)
- {
- int n = (int) (long) xa; // thread number
- int b = NKEYS/nthread;
-
- for (int i = 0; i < b; i++) {
- put(keys[b*n + i], n);
- }
-
- return NULL;
- }
然而,可能会发生键冲突的情况,如果多个线程同时尝试插入具有相同哈希值的键,它们会访问相同的桶,并且可能会出现竞态条件。举个例子
[假设键 k1、k2 属于同个 bucket]
thread 1: 尝试设置 k1 thread 1: 发现 k1 不存在,尝试在 bucket 末尾插入 k1 --- scheduler 切换到 thread 2 thread 2: 尝试设置 k2 thread 2: 发现 k2 不存在,尝试在 bucket 末尾插入 k2 thread 2: 分配 entry,在桶末尾插入 k2 --- scheduler 切换回 thread 1 thread 1: 分配 entry,没有意识到 k2 的存在,在其认为的 “桶末尾”(实际为 k2 所处位置)插入 k1 [k1 被插入,但是由于被 k1 覆盖,k2 从桶中消失了,引发了键值丢失]
为了解决这个问题,在put函数读写bucket之前加锁,在函数结束时释放锁。get不涉及修改操作,所以不需要加锁。
- pthread_mutex_t lock;//声明锁
-
- int
- main(int argc, char *argv[])
- {
- pthread_t *tha;
- void *value;
- double t1, t0;
-
- pthread_mutex_init(&lock, NULL);
-
- // ...
- }
-
- static
- void put(int key, int value)
- {
- int i = key % NBUCKET;
-
- // is the key already present?
- struct entry *e = 0;
-
- pthread_mutex_lock(&lock);
-
- for (e = table[i]; e != 0; e = e->next) {
- if (e->key == key)
- break;
- }
- if(e){
- // update the existing key.
- e->value = value;
- } else {
- // the new is new.
- insert(key, value, &table[i], table[i]);
- }
-
- pthread_mutex_unlock(&lock);
-
- }
但是加锁后多线程的性能变得比单线程还要低了,这是因为表级锁将所有的操作都串行化了,无法利用多线程的性能,而多线程的初始化和切换以及锁的获取和释放本身也会带来一定的性能开销。
这里的优化思路,也是多线程效率的一个常见的优化思路,就是降低锁的粒度。由于哈希表中,不同的 bucket 是互不影响的,一个 bucket 处于修改未完全的状态并不影响 put 对其他 bucket 的操作,所以实际上只需要确保两个线程不会同时操作同一个 bucket 即可。
- pthread_mutex_t locks[NBUCKET];
-
- int
- main(int argc, char *argv[])
- {
- pthread_t *tha;
- void *value;
- double t1, t0;
-
- for(int i=0;i<NBUCKET;i++) {
- pthread_mutex_init(&locks[i], NULL);
- }
-
- //...
- }
-
- static
- void put(int key, int value)
- {
- int i = key % NBUCKET;
-
- // is the key already present?
- struct entry *e = 0;
- pthread_mutex_lock(&locks[i]);
- for (e = table[i]; e != 0; e = e->next) {
- if (e->key == key)
- break;
- }
- if(e){
- // update the existing key.
- e->value = value;
- } else {
- // the new is new.
- insert(key, value, &table[i], table[i]);
- }
- pthread_mutex_unlock(&locks[i]);
- }
Barrier
在本作业中,您将实现一个屏障:应用程序中的一个点,所有参与的线程必须等待,直到所有其他参与的线程也到达该点。您将使用pthread条件变量,这是一种序列协调技术,类似于xv6的睡眠和唤醒。
您应该在一台真正的计算机(不是xv6,也不是qemu)上完成这个任务。
文件notxv6/barrier.c包含一个损坏的barrier。
$ make barrier $ ./barrier 2 barrier: notxv6/barrier.c:42: thread: Assertion `i == t' failed.其中的数字 2 指定了在屏障上同步的线程数量(在 barrier.c 中为 nthread)。每个线程执行一个循环。在每个循环迭代中,线程调用 barrier(),然后休眠随机微秒数。断言(assert)被触发的原因是,一个线程在另一个线程到达屏障之前就离开了屏障。期望的行为是,每个线程在 barrier() 中阻塞,直到所有 nthreads 的线程都调用了 barrier()。
您的目标是实现期望的障碍行为。除了在ph赋值中看到的锁原语之外,还需要以下新的pthread原语;
pthread_cond_wait(&cond, &mutex); // go to sleep on cond, releasing lock mutex, acquiring upon wake up pthread_cond_broadcast(&cond); // wake up every thread sleeping on cond确保你的答案通过了年级的屏障测试。
Pthread_cond_wait在被调用时释放互斥锁,并在返回之前重新获取互斥锁。
我们已经给出了barrier_init()。你的工作是实现barrier(),这样恐慌就不会发生。我们已经为你们定义了结构障碍;它的字段供您使用。
有两个问题会使你的任务复杂化:
- 你必须处理一连串的障碍叫牌,每一次叫一轮。bstate。Round记录当前轮。您应该增加bstate。每轮所有线程都到达障碍。
- 您必须处理这样一种情况:在其他线程退出屏障之前,一个线程在循环中赛跑。特别是,您正在重用bstate。从一轮到下一轮的Nthread变量。确保离开屏障并在循环中赛跑的线程不会增加bstate。当上一轮仍在使用它时。
Barrier -维基百科 屏障的策略解释得还是比较详细的,看完之后很容易理解,这题就是复刻一下barrier(),并且题目已经提供了两个POSIX 线程库中用于条件变量操作的函数。
-
pthread_cond_wait(&cond, &mutex);:- 这个函数用于在条件变量 (
cond) 上等待。调用该函数的线程会阻塞,直到另一个线程调用pthread_cond_signal或pthread_cond_broadcast通知条件变量发生了变化。 - 在等待前,调用线程必须已经获得
mutex的锁,因为这个函数在等待时会自动释放mutex,并在被唤醒后重新获取锁。 - 一般情况下,该函数在一个循环中使用,以确保在线程被唤醒后仍然检查等待条件,以防止虚假唤醒(spurious wake-ups)。
- 这个函数用于在条件变量 (
-
pthread_cond_broadcast(&cond);:- 这个函数用于广播通知(broadcast),唤醒等待在条件变量上的所有线程。即使只有一个线程在等待,调用
pthread_cond_broadcast也会唤醒所有等待的线程。 - 调用此函数会通知所有等待在条件变量上的线程,使它们从
pthread_cond_wait调用中返回。
- 这个函数用于广播通知(broadcast),唤醒等待在条件变量上的所有线程。即使只有一个线程在等待,调用
所以实现barrier()会更加简单,就是加锁然后判断到达屏障点的线程数,如果所有线程都到达了就调用pthread_cond_broadcast()唤醒其他线程,否则就调用pthread_cond_wait()进行等待。这里和维基百科中barri()的区别就是把条件判断直接用函数封装了。
维基百科的barrier()使用 counter 和 flag 进行同步,每个线程到达屏障时递增 counter,并通过 flag 来通知其他线程。
这里使用 nthread 记录到达屏障的线程数量,每个线程到达屏障时递增 nthread,通过条件变量广播通知,唤醒所有等待的线程。
- static void
- barrier()
- {
- pthread_mutex_lock(&bstate.barrier_mutex);
-
- bstate.nthread++;
-
- if(bstate.nthread == nthread){
- bstate.round++;
- bstate.nthread = 0;
- pthread_cond_broadcast(&bstate.barrier_cond);
- }else{
- pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
- }
-
- pthread_mutex_unlock(&bstate.barrier_mutex);
- }
Lab: networking
实现网卡的
e1000_transmit和e1000_recv函数,一个对于驱动发送数据, 一个对于驱动接收数据。在E1000 .c中提供的e1000_init()函数将E1000配置为读取要从RAM传输的数据包,并将接收到的数据包写入RAM。这种技术称为DMA,即直接内存访问,指的是E1000硬件直接向RAM写入和读取数据包。
因为数据包的突发可能比驱动程序处理它们的速度要快,所以e1000_init()为E1000提供了多个缓冲区,E1000可以向其中写入数据包。E1000要求这些缓冲区由RAM中的“描述符”数组来描述;每个描述符在RAM中包含一个地址,E1000可以在其中写入接收到的数据包。rx_desc结构描述了描述符的格式。描述符数组称为接收环或接收队列。从某种意义上说,当卡或驱动程序到达阵列的末端时,它会包装回开始处。e1000_init()使用mbufalloc()为E1000分配mbuf数据包缓冲区,以便DMA进入。还有一个传输环,驱动程序应该在其中放置它想要E1000发送的数据包。e1000_init()配置两个环的大小分别为RX_RING_SIZE和TX_RING_SIZE。
当net.c中的网络堆栈需要发送数据包时,它调用e1000_transmit(),并使用mbuf保存要发送的数据包。您的传输代码必须在TX(传输)环的描述符中放置一个指向数据包数据的指针。结构体tx_desc描述了描述符的格式。您将需要确保每个mbuf最终被释放,但只有在E1000完成传输数据包之后(E1000在描述符中设置E1000_TXD_STAT_DD位来指示这一点)。
当E1000从以太网接收到每个数据包时,它将数据包dma到下一个RX(接收)环描述符中由addr指向的内存。如果E1000的中断尚未挂起,则E1000会在中断启用后立即请求PLIC下发中断。e1000_recv()代码必须扫描RX环,并通过调用net_rx()将每个新数据包的mbuf传递到网络堆栈(在net.c中)。然后,您需要分配一个新的mbuf并将其放入描述符中,以便当E1000再次到达RX环中的该点时,它会找到一个新的缓冲区,以便对新数据包进行DMA。
除了在RAM中读写描述符环之外,您的驱动程序还需要通过其内存映射的控制寄存器与E1000进行交互,以检测接收到的数据包何时可用,并通知E1000驱动程序已经填充了一些TX描述符和要发送的数据包。全局变量regs保存着一个指向E1000的第一个控制寄存器的指针;您的驱动程序可以通过索引regs作为数组来获取其他寄存器。您特别需要使用索引E1000_RDT和E1000_TDT。
Hints
首先向e1000_transmit()和e1000_recv()添加print语句,并运行make server和(在xv6中)nettests。您应该从print语句中看到,nettests生成了对e1000_transmit的调用。
实现e1000_transmit的一些提示:
- 首先,通过读取E1000_TDT控制寄存器,向E1000询问它期待下一个数据包所在的TX环索引。
- 然后检查密封圈是否溢出。如果E1000_TDT索引的描述符中没有设置E1000_TXD_STAT_DD,则E1000没有完成相应的先前传输请求,因此返回错误。
- 否则,使用mbuffree()释放从该描述符传输的最后一个mbuf(如果有的话)。
- 然后填写描述符。M ->head指向内存中的数据包内容,M ->len是数据包长度。设置必要的cmd标志(参见E1000手册中的3.3节),并隐藏一个指向mbuf的指针,以便稍后释放。
- 最后,通过向E1000_TDT模TX_RING_SIZE添加1来更新环位置。
- 如果e1000_transmit()成功地将mbuf添加到环中,则返回0。在失败时(例如,没有可用的描述符来传输mbuf),返回-1以便调用者知道释放mbuf。
实现e1000_recv的一些提示:
- 首先,通过获取E1000_RDT控制寄存器并添加一个模RX_RING_SIZE,向E1000询问下一个等待接收的数据包(如果有的话)所在的环索引。
- 然后通过检查描述符状态部分中的E1000_RXD_STAT_DD位来检查是否有新的数据包可用。如果不是,停下来。
- 否则,将mbuf的m->len更新为描述符中报告的长度。使用net_rx()将mbuf发送到网络堆栈。
- 然后使用mbufalloc()分配一个新的mbubuf来取代刚刚给net_rx()的mbubuloc()。将其数据指针(m->head)写入描述符。将描述符的状态位清除为零。
- 最后,更新E1000_RDT寄存器,使其成为处理的最后一个环描述符的索引。
- e1000_init()用mbufs初始化RX环,您可能想看看它是如何做到这一点的,并可能借用代码。
- 在某一点上,到达的数据包总数将超过环的大小(16);确保你的代码可以处理这个问题。
您需要锁来处理以下情况:xv6可能从多个进程中使用E1000,或者在中断到来时在内核线程中使用E1000。
在网络数据包的处理中,使用环形缓冲区是一种常见的技术。环形缓冲区允许持续地处理数据包流,而无需对整个内存进行复制。头指针和尾指针是环形缓冲区的两个关键指针,用于跟踪数据包的进入和离开。
在接收描述符的环形缓冲区中,头指针和尾指针的作用如下:
-
尾指针(Tail Pointer):尾指针指向环形缓冲区中下一个可用的描述符槽位。当网络数据包到达时,硬件将数据包存储在尾指针指向的描述符槽位,并递增尾指针,使其指向下一个可用的槽位。这样,尾指针不断地指向接收下一个数据包的位置。
-
头指针(Head Pointer):头指针指向环形缓冲区中下一个要写回的数据包的描述符槽位。当软件处理完一个数据包后,它递增头指针,指向下一个待处理的数据包。这样,头指针不断地指向下一个要被处理的数据包的位置。
通过使用环形缓冲区,可以不断地循环使用有限的描述符槽位,而无需为每个数据包分配新的内存。当头指针和尾指针相等时,表示环形缓冲区为空;当尾指针逼近头指针时,表示环形缓冲区快满了。这种结构允许在不中断处理的情况下循环使用缓冲区,并有效地管理内存。
对于发送模型,有两个结构体需要重点注意:mbuf、tx_desc。而他们各自又有着自己的队列,分别为 tx_mbufs、tx_ring。
- mbuf:内存中存放报文的空间;
- tx_desc:上述 mbuf 的描述符,可以理解为指向它具体内容的指针;
- tx_mbufs:mbuf 地址 组成的队列,以 desc 的 idx 作为索引,用于标识后续要释放的空间;
- tx_ring:tx_desc 组成的队列;
- struct tx_desc
- {
- uint64 addr; // 指向待发送数据包的缓冲区的物理地址
- uint16 length; // 数据包的长度
- uint8 cso; // Checksum Offset(校验和偏移),指示校验和的插入位置相对于数据包起始位置的偏移
- uint8 cmd; // Command(命令)字段,包含一些控制标志,用于指示硬件执行的操作
- uint8 status; // 存储硬件对该描述符的处理结果
- uint8 css; // 指示从数据包的哪个位置开始计算校验和
- uint16 special; // 一些特殊的控制信息
- };
-
- struct mbuf {
- struct mbuf *next; // the next mbuf in the chain
- char *head; // the current start position of the buffer
- unsigned int len; // the length of the buffer
- char buf[MBUF_SIZE]; // the backing store
- };
-
- //以下是/e1000.c 的初始化代码片段
- #define TX_RING_SIZE 16
- static struct tx_desc tx_ring[TX_RING_SIZE] __attribute__((aligned(16)));
- static struct mbuf *tx_mbufs[TX_RING_SIZE];
-
- #define RX_RING_SIZE 16
- static struct rx_desc rx_ring[RX_RING_SIZE] __attribute__((aligned(16)));
- static struct mbuf *rx_mbufs[RX_RING_SIZE];
首先需要说明的是网卡的发送数据队列 tx_ring, 其中每个元素是一个发送数据描述符, 同时有 addr 字段指向发送的以太网帧数据的缓冲区地址, 对应 tx_mbufs每个元素的head字段. 根据开发手册 3.4 节描述的发送描述符的队列结构. 这其中涉及了队列在内存的地址E1000_TDBAL和长度E1000_TDLEN, 队列的首尾指针 E1000_TDH和E1000_TDT, 这些变量都在对应的寄存器中, 可由 regs 数组进行访问. 在 kernel/e1000.c 的 e1000_init() 函数中, 会进行发送初始化, 会对以上变量进行初始化。
对xv6里面的网卡驱动程序的剖析,首先先看kernel/e1000.c
这个函数接收一个参数 xregs,表示 e1000 寄存器的内存映射地址
- void
- e1000_init(uint32 *xregs)
重点是初始化发送队列 tx_ring,将其清零并设置默认状态。然后将发送队列的基地址 E1000_TDBAL 和队列的大小 E1000_TDLEN 注册进行配置,并将发送队列的头尾指针 E1000_TDH 和 E1000_TDT 置零
- // [E1000 14.5] Transmit initialization
- memset(tx_ring, 0, sizeof(tx_ring));
- for (i = 0; i < TX_RING_SIZE; i++) {
- tx_ring[i].status = E1000_TXD_STAT_DD;
- tx_mbufs[i] = 0;
- }
- regs[E1000_TDBAL] = (uint64) tx_ring;
- if(sizeof(tx_ring) % 128 != 0)
- panic("e1000");
- regs[E1000_TDLEN] = sizeof(tx_ring);
- regs[E1000_TDH] = regs[E1000_TDT] = 0;
初始化接收队列 rx_ring,分配 RX_RING_SIZE 个 mbuf 用于存放接收的数据包,并配置接收队列的基地址 E1000_RDBAL、头指针 E1000_RDH、尾指针 E1000_RDT、队列大小 E1000_RDLEN 寄存器
- // [E1000 14.4] Receive initialization
- memset(rx_ring, 0, sizeof(rx_ring));
- for (i = 0; i < RX_RING_SIZE; i++) {
- rx_mbufs[i] = mbufalloc(0);
- if (!rx_mbufs[i])
- panic("e1000");
- rx_ring[i].addr = (uint64) rx_mbufs[i]->head;
- }
- regs[E1000_RDBAL] = (uint64) rx_ring;
- if(sizeof(rx_ring) % 128 != 0)
- panic("e1000");
- regs[E1000_RDH] = 0;
- regs[E1000_RDT] = RX_RING_SIZE - 1;
- regs[E1000_RDLEN] = sizeof(rx_ring);
在整个发送过程中,tx_ring 是核心数据结构。驱动程序通过管理 tx_ring,维护待发送网络报文的描述符,以及追踪报文发送状态。具体流程如下:
- 待发送的报文首先被分配一个
mbuf,其中包含了报文的实际内容和相关信息。 - 为了进行发送,驱动程序创建一个对应的
tx_desc,并将其放入tx_ring中。同时,将对应的mbuf的首地址记录在tx_mbufs中。 - 驱动程序使用网络设备的硬件(如 E1000 网卡)将
tx_ring中的描述符指向的报文发送出去。 - 当报文发送完成后,驱动程序通过检查硬件状态或中断来获取发送完成的信息。
- 针对已经发送完成的报文,释放对应的
mbuf内存空间,以及相应的tx_desc。
最终,通过管理 tx_ring 和相关数据结构,网络驱动程序实现了高效的网络报文发送。
因此e1000_transmit() 的具体实现可以综合以上知识和题目给的提示完成。
- 首先读取发送尾指针对应的寄存器
regs[E1000_TDT]获取到软件可以写入的位置 - 检查尾指针指向的描述符是否设置了
E1000_TXD_STAT_DD标志位,该标志位表示描述符对应的数据帧已经被处理完成。如果未设置,则说明队列满,不能继续发送数据帧。 - 如果缓冲区未被释放,调用
mbuffree函数释放它。这是为了防止内存泄漏,因为描述符指向的缓冲区需要在数据帧发送完成后释放。 - 更新尾指针指向的描述符的
addr字段为数据帧缓冲区的头部,length字段为数据帧的长度,cmd字段设置E1000_TXD_CMD_EOP表示数据包的结束,E1000_TXD_CMD_RS表示设置状态信息,要查文档的就是cmd域,但其实这个域的宏定义里面就只给了E1000_TXD_CMD_R和E1000_TXD_CMD_EOP这两个,也就是说我们只要关注这两个就行了。
- /* Transmit Descriptor command definitions [E1000 3.3.3.1] */
- #define E1000_TXD_CMD_EOP 0x01 /* End of Packet */
- #define E1000_TXD_CMD_RS 0x08 /* Report Status */
-
- /* Transmit Descriptor status definitions [E1000 3.3.3.2] */
- #define E1000_TXD_STAT_DD 0x00000001 /* Descriptor Done */
- 记录数据帧的缓冲区到缓冲区队列
tx_mbufs中,为后续释放做准备。 - 最后更新尾指针,由于可能有多个进程同时调用该函数,使用取余操作保证队列循环。
- 在整个操作结束后释放锁,确保对发送队列的操作是线程安全的。
- int
- e1000_transmit(struct mbuf *m)
- {
- //
- // Your code here.
- //
- // the mbuf contains an ethernet frame; program it into
- // the TX descriptor ring so that the e1000 sends it. Stash
- // a pointer so that it can be freed after sending.
- //
- acquire(&e1000_lock);
- uint32 tail = regs[E1000_TDT];
-
- if (!(tx_ring[tail].status & E1000_TXD_STAT_DD)){
- release(&e1000_lock);
- return -1;
- }
-
- if (tx_mbufs[tail])
- mbuffree(tx_mbufs[tail]);
-
- tx_ring[tail].addr = (uint64)m->head;
- tx_ring[tail].length = (uint16)m->len;
- tx_ring[tail].cmd = E1000_TXD_CMD_EOP | E1000_TXD_CMD_RS;
-
- tx_mbufs[tail] = m;
-
- regs[E1000_TDT] = (tail + 1) % TX_RING_SIZE;
-
- release(&e1000_lock);
-
- return 0;
- }
与发送模型对应的结构相同,接收模型也有 mbuf、rx_desc、rx_bufs 和 rx_ring。在实验指导中, 需要通过读取 (regs[E1000_RDT]+1)%RX_RING_SIZE 来确定进行解封装的数据帧, 而非直接读取 regs[E1000_RDT]. 因此可以推断出, 接收尾指针指向的是已被软件处理的数据帧, 其下一个才为当前需要处理的数据帧。然后是e1000_recv函数,这里注意一次中断应该把所有到达的数据都处理掉,通过 while 循环让一次中断触发后网卡软件会一直将可解封装的数据传递到网络栈,以避免队列中的可处理数据帧的堆积。
- 计算接收队列尾指针,即下一个待处理的数据包位置。
- 检查描述符的 DD(Descriptor Done)标志位是否被设置,如果未设置,不执行循环。
- 调用
net_rx()处理数据包 - 分配一个新的缓冲区,用于替换处理完毕的缓冲区。
- 更新描述符的地址字段,指向新的缓冲区的头部。
- 清空描述符的状态字段,准备描述符用于后续硬件接收数据。
- 更新接收队列尾指针,表示处理完当前数据包。
- static void
- e1000_recv(void)
- {
- //
- // Your code here.
- //
- // Check for packets that have arrived from the e1000
- // Create and deliver an mbuf for each packet (using net_rx()).
- //
- uint32 next_index = (regs[E1000_RDT]+1)%RX_RING_SIZE;
-
- while(rx_ring[next_index].status & E1000_RXD_STAT_DD){
- if(rx_ring[next_index].length>MBUF_SIZE){
- panic("MBUF_SIZE OVERFLOW!");
- }
- rx_mbufs[next_index]->len = rx_ring[next_index].length;
- net_rx(rx_mbufs[next_index]);
- rx_mbufs[next_index] = mbufalloc(0);
- rx_ring[next_index].addr = (uint64)rx_mbufs[next_index]->head;
- rx_ring[next_index].status = 0;
- next_index = (next_index+1)%RX_RING_SIZE;
- }
-
- regs[E1000_RDT] = (next_index-1)%RX_RING_SIZE;
-
- }

