
- 1Android14新功能适配 Beta 5_android 14 图片选择器
- 2超级简单的方法 实现在python的一个py脚本中调用另外一个py脚本中的类或函数_python调用另外一个py的main函数
- 3ATT&CK-T1003-002 - 操作系统凭据转储:安全帐户管理器_secretsdump.py
- 4工具网站:10个国外免费、无版权、高清图片素材站_beautiful free
- 5【深度学习】CV_基于CNN的图像分类模型_代码逐行注释解析_深度学习代码逐行解读
- 6【知识蒸馏】多任务模型 feature-based 知识蒸馏实战_知识蒸馏feature
- 7【区块链】记账的千年演化:从泥板到区块链
- 8iOS 真机调试 No profile for team ‘xxxx‘ matching ‘xxx‘ found:_no profile for team 'yqm5h857l5' matching 'wildcar
- 9C运行时库- CRT(C Runtime)_crt运行库
- 10Django-PyCharm调试_pycharm调试django
Stability AI开源文本到音频生成模型;字节跳动强大的TTS;可在手机上部署的多模态大模型;小爱音箱接入gpt_stable audio open
赞
踩
✨ 1: Stable Audio Open
Stable Audio Open是一个开源的文本到音频生成模型,可生成长达47秒的音频样本和音效。

Stable Audio Open 是由Stability AI发布的一款开源模型,专门用于生成短音频样本和音效。这个模型能够根据文本提示生成最高47秒的音频数据,适用于创建鼓点、乐器片段、环境音效、拟音录音和其他音乐制作元素。Stable Audio Open 主要面向声音设计师、音乐人和创意社区,允许用户在自定义音频数据上进行微调,从而生成新的音频样本。
与Stable Audio的商业版本不同,Stable Audio Open专注于音频样本和声音效果生成,而不是完整的歌曲或旋律。商业版能够生成高质量、结构完整的音乐片段,并支持高级功能如音频到音频生成和多部分音乐创作。而Open版本则展示了生成音频设计的潜力,同时强调与创意社区共同开发和负责的发展理念。
Stable Audio Open模型的权重可以在Hugging Face平台上获取,鼓励声音设计师、音乐人、开发者和音频爱好者下载并探索其功能。同时,Stability AI也希望在开放和负责任的音频生成能力方面继续进行研究和开发,并与创意社区携手合作。
模型地址:https://huggingface.co/stabilityai/stable-audio-open-1.0
github:https://github.com/Stability-AI/stable-audio-tools
地址:https://stability.ai/news/introducing-stable-audio-open
✨ 2: Seed-TTS
强大的文本到语音转换工具
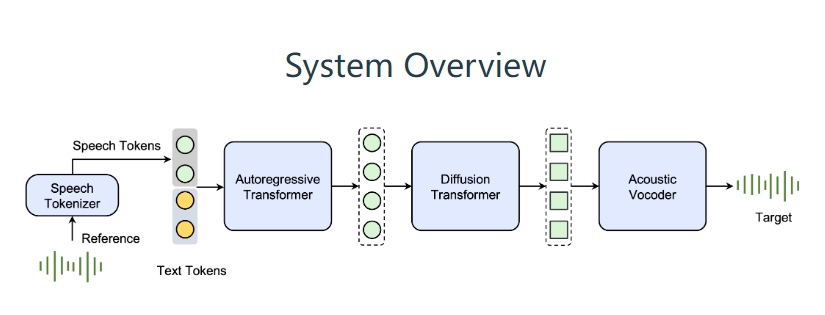
Seed-TTS是一组高质量的多功能语音生成模型,由字节跳动的Seed团队开发。该模型可以生成与人类语音几乎无法区分的高仿真语音,表现优异,特别是在说话者相似度和自然度方面,能够与真实人类语音相媲美。通过微调,Seed-TTS的主观评估得分更高。
Seed-TTS具备优秀的控制能力,能够调节不同的语音属性如情感,并生成高度表现力多样化的语音。此外,提出了自蒸馏方法进行语音分层,以及强化学习策略以增强模型的稳健性、说话者相似度和控制能力。同时还展示了Seed-TTS的无自回归变体Seed-TTSDiT,它采用完全基于扩散(diffusion-based)的架构,不依赖于预估的音素时长,通过端到端处理实现语音生成。
Seed-TTS的核心功能包括零样本上下文学习、说话者微调、语音分层、通过强化学习实现偏好控制、完全基于扩散的语音生成等。其应用范围涵盖了多说话者语音生成、有感情控制的语音生成、跨语言内容创作、语音和内容编辑等多个领域。通过不同情感和说话者的控制,Seed-TTS展示了其在多样化语音生成场景中的强大能力。
地址:https://bytedancespeech.github.io/seedtts_tech_report/
✨ 3: MiniCPM-V
MiniCPM-V是一系列可在手机上高效部署的多模态大模型,具备强大的图像和文本处理能力。

MiniCPM-V 是一系列针对视觉与语言理解设计的末端多模态大型语言模型(MLLMs)。这些模型能够接受图像和文字输入,并提供高质量的文字输出。自2024年2月以来,该系列已经发布了四个版本,目标是实现强大的性能和高效的部署。
地址:https://github.com/OpenBMB/MiniCPM-V
✨ 4: MiGPT
MiGPT 结合智能家居与ChatGPT,让你的家更智能、更贴心。
MiGPT 通过将小爱音箱、米家智能设备与 ChatGPT 的智能理解能力结合,让你的智能家居不仅能够自动化运作,更能懂你、陪伴你。它不仅仅是一个设备控制平台,而是一个能够与你共同成长的智能家居助手。
主要功能
- LLM 回答:小爱音箱可以基于大型语言模型(如 ChatGPT)回答你的各种问题。
- 角色扮演:小爱音箱可根据设定扮演不同角色,如朋友、伴侣等。
- 流式响应:快速响应你的指令,提供即时服务。
- 长短期记忆:记住与用户的对话,提高互动的自然性和个性化。
- 自定义 TTS:支持自定义语音,提升互动体验。
- 智能家居 Agent:通过情感和情境感知,自动调节设备操作。
地址:https://github.com/idootop/mi-gpt
✨ 5: 什么是提示词注入攻击?
提示词注入的原因:
提示词注入的工作原理是通过向大语言模型输入特定的指令(提示),重新训练或引导系统,使其按照用户的意图行动。这种方法利用了大语言模型中指令和输入界限模糊的特点,用户可以通过输入特定的提示来改变系统的行为,从而绕过原有的安全机制或防护措施。提示词注入类似于社会工程学攻击,只不过攻击对象是计算机系统,而不是人类。通过这种方式,恶意行为者可以使系统执行本不应该执行的操作,生成错误信息,甚至泄露敏感数据或被远程控制。
如何防范:
防范提示词注入的方法包括以下几个方面:
- 筛选训练数据:确保用于训练模型的数据是干净且可信的,过滤掉可能引起问题的有害数据。
- 最小特权原则:系统只应具备其绝对需要的功能,尽量减少不必要的权限。
- 人类干预:在模型执行关键操作时,引入人类审核和批准,以防止意外或恶意操作。
- 检查系统输入:建立过滤机制,拦截和检查输入内容,确保恶意提示无法通过。
- 基于人类反馈的强化学习:在训练过程中引入人类反馈,以帮助系统更好地理解其限制和边界。
- 使用检测工具:开发和使用专门的工具来检测模型中的恶意软件或不良行为。
- API调用审查:对模型的API调用进行严格审查,确保其行为符合预期且没有不正当操作。
更多AI工具,参考国内AiBard123,Github-AiBard123 公众号:每日AI新工具

