
热门标签
热门文章
- 1【HAL库】STM32CubeMX开发----STM32F407----LAN8720A----移植FreeModbus实现ModbusTCP_stm32cube移植freemodbus
- 2历史最全Transformer&注意力机制综述论文、代码及网站资源整理分享_transformer网站
- 3探索ComfyUI ControlNet Auxiliary:一个创新的UI设计辅助工具
- 4Linux nohup 后台运行java服务,日志输出到指定文件_nohup输出的日志
- 5Flutter初体验(一)——Mac 安装配置_flutter sdk路径
- 6NOIP2018普及T4暨洛谷P5018 对称二叉树题解_求出点p5018的坐标,
- 7ESP32-IDF开发实例-I2C从机通信_esp32做i2c 从机
- 8Mysql数据库迁移到达梦DM_mysql建表转为达梦
- 9【ChatGPT实践】联网插件以及常见问题处理方案_no search results found. please try again with a d
- 10华为“仓颉”不是中文编程:中文编程早有所属,势如破竹_仓颉编程语言下载
当前位置: article > 正文
【Python特征工程系列】利用随机森林模型分析特征重要性(源码)_python随机森林特征重要性
作者:木道寻08 | 2024-07-05 05:57:40
赞
踩
python随机森林特征重要性
一、引言
如果有一个包含数十个甚至数百个特征的数据集,每个特征都可能对你的机器学习模型的性能有所贡献。但是并不是所有的特征都是一样的。有些可能是冗余的或不相关的,这会增加建模的复杂性并可能导致过拟合。
特征重要性分析可以识别并关注最具信息量的特征,从而带来以下几个优势:
- 改进的模型性
- 能减少过度拟合
- 更快的训练和推理
- 增强的可解释性
随机森林是一种集成学习方法,由多个决策树组成。使用随机森林模型来分析特征重要性是一种常见的方法。随机森林模型的特征重要性是基于模型的训练结果得出的,因此它反映了模型对特征的相对重要性。这些重要性值可以用于帮助你理解哪些特征对于模型的预测结果具有更大的影响力。
我将持续更新特征重要性分析的一些方法,关注我,不错过!本文将详细解读利用随机森林模型分析特征重要性的步骤!
二、具体实现过程
2.1 准备数据
- data = pd.read_csv(r'E:\数据杂坛\\UCI Heart Disease Dataset.csv')
- df = pd.DataFrame(data)
2.2 目标变量和特征变量
- target = 'target'
- features = df.columns.drop(target)
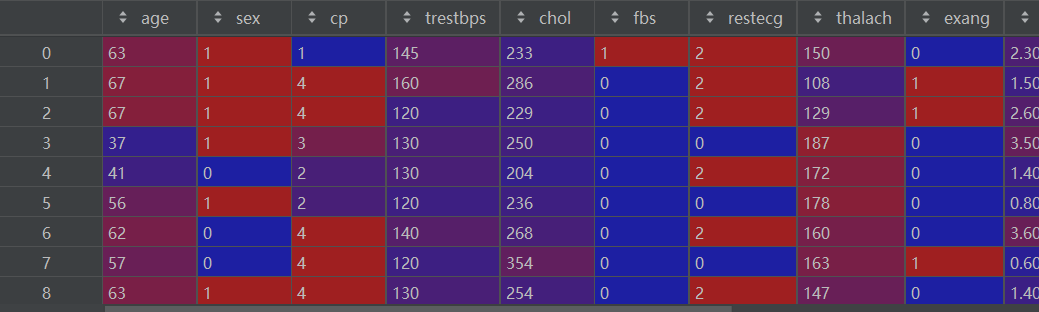
特征变量如下:

2.3 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)X_train如下:
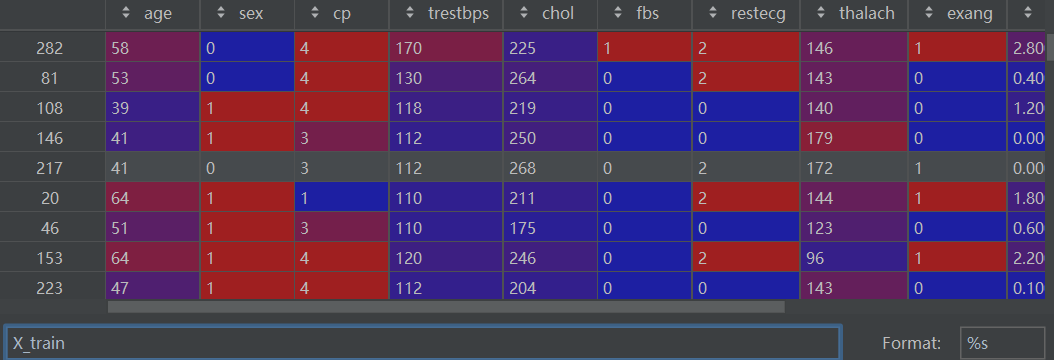
2.4 训练随机森林模型
- model = RandomForestClassifier(n_estimators=100, random_state=0)
- model.fit(X_train, y_train)
2.5 提取特征重要性
- feature_importance = model.feature_importances_
- feature_names = features
feature_importance如下:

2.6 创建特征重要性的dataframe
importance_df = pd.DataFrame({'Feature': feature_names, 'Importance': feature_importance})import_df如下:
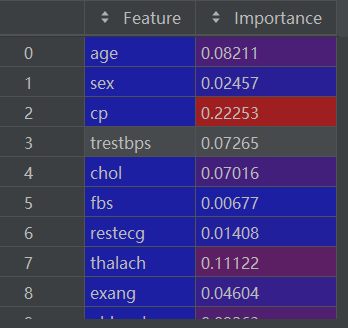
2.7 对特征重要性进行排序
importance_df = importance_df.sort_values(by='Importance', ascending=False)排序后的 importance_df如下:
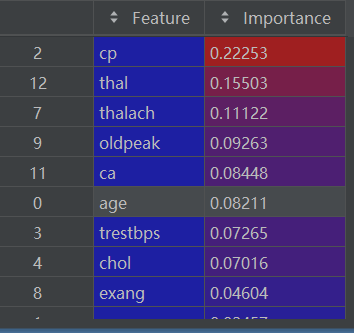
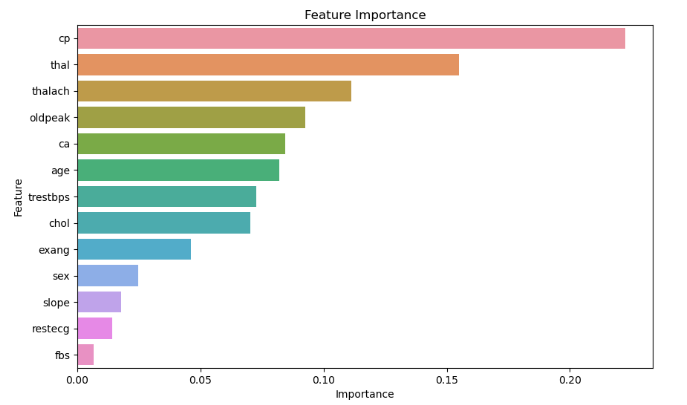
2.8 可视化特征重要性
- plt.figure(figsize=(10, 6))
- sns.barplot(x='Importance', y='Feature', data=importance_df)
- plt.title('Feature Importance')
- plt.xlabel('Importance')
- plt.ylabel('Feature')
- plt.show()
可视化结果如下:
好了,本篇内容就到这里,需要数据集和源码的小伙伴可以关注底部公众号领取!
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/木道寻08/article/detail/789357

