
- 1无人机之电池保养
- 2深度学习在医疗健康领域的应用:疾病预测_深度学习与疾病
- 3AI绘画Stable diffusion的SDXL模型超详细讲解,针不错!(含实操教程)_total amount of video memory allocated by the torc
- 4ubuntu18.04下深度学习环境的配置过程(pytorch、cuda、cudnn)_ubuntu18.04下安装深度学习的库函数
- 5关于利用IBERT核对GTX收发器板级测试的原理与过程详解_gtx ibert
- 6lodash源码分析之Number_lodash hex转num
- 72023全国安全生产合格证危险化学品经营单位安全管理人员真题练习_依据《危险化学品安全管理条例》的规定,依法设立的危险化学品生产企业在其厂区范
- 8动态跨数据库库同步数据_dbsyncer-plugin-demo
- 9显色指数测试软件,显色性
- 10MySQL-存储过程(PROCEDURE)_4.5过程调用…………………………45
爬虫-使用urllib库抓取静态网页数据_urllib怎么抓取网页
赞
踩
目录
前言
基于爬虫的实现原理,进入爬虫的第一阶段:爬取网页数据,即下载包含目标数据的网页。爬取网页需要通过爬虫向服务器发送一个HTTP请求,然后接收服务器返回的响应内容中的整个网页源代码。
利用Python完成这个过程,既可以使用内置的urllib库,也可以使用第三方库requests。使用这两个库,在爬取网页数据时,只需要关心请求的URL格式,要传递什么参数,要设置什么样的请求头,而不需要关心它们的底层是怎样实现的。下面针对urllib和requests库的使用进行详细讲解。
urllib库概述
urllib库是Python内置的HTTP请求库,它可以看作处理URL的组件集合。urllib库包含四大模块:
(1)urllib.request:请求模块。
(2)urllib.error:异常处理模块。
(3)urllib.parse:URL解析模块。

快速爬取一个网页
urllib库的使用比较简单,下面使用urllib快速爬取一个网页,具体代码如下:
- import urllib.request
- #调用urllib.request库的urlopen()方法,并传入一个url
- respones=urllib.request.urlopen("http://www.baidu.com")
- #使用read()方法读取获取到的网页内容
- html=response.read().decode('UTF-8')
- #打印网页内容
- print(html)
运行结果:
上述案例仅仅用了几行代码,就已经帮我们把百度的首页的全部代码下载下来了。
分析urlopen()方法
上一小节在爬取网页的时候,有一句核心的爬虫代码,如下图所示:
response=urllib.request.urlopen('http://www.baidu.com')改代码调用的是urllib.request模块中urlopen()方法,它传入了一个百度首页url,使用得协议使HTTP,这是urlopen()方法最简单的用法。
其实,urlopen()方法可以接受多个参数,该方法的定义格式如下:
- urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,
- capath=None,cadefault=False,countext=None)
上述方法定义中的参数详细介绍如下:
- url --表示目标资源在网站中的位置。
- data --用来指明向服务器发送请求的额外信息。
- timeout 一 该参数用于设置超时时间,单位是秒。
- context 一 实现SSL加密传输,该参数很少使用。
使用HTTPResponse对象
使用urlopen方法发送HTTP请求后,服务器返回 的响应内容封装在一个HTTPResponse类型的对 象中。
- # 例如:
- import urllib.request
- response = urllib.request.urlopen('http://www.itcast.cn') print(type(response))
HTTPResponse类属于http.client模块,该 类提供了获取URL、状态码、响应内容等一 系列方法。
- geturl() -- 用于获取响应内容的URL,该方法可以验证发送的HTTP请求是否被重新调配。
- info() -- 返回页面的元信息。
- getcode() -- 返回HTTP请求的响应状态码。
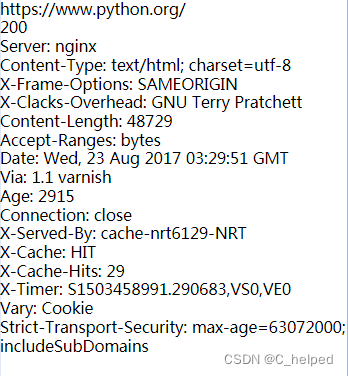
- # 示例
- import urllib.request
- response = urllib.request.urlopen('http://python.org')
- #获取响应信息对应的URL
- print(response.geturl())
- #获取响应码
- print(response.getcode())
- #获取页面的元信息
- print(response.info())
示例结果:
构造Request对象
如果希望对请求执行复杂操作,则需要创建一 个Request对象来作为urlopen方法的参数。
- # 将url作为Reque st方法的参数,构造并返回一个Reque st对象
- request = urllib.request.Request('http://www.baidu.com')
- # 将Request对象作为urlopen方法的参数,发送给服务器并接收响应
- response = urllib.request.urlopen(request)
在使用urllib库发送URL的时候,我们推荐大家使用构造Request对象的方式。
在构建请求时,除了必须设置的urI参数外, 还可以加入很多内容,例如下面的参数:
- data -- 默认为空,该参数表示提交表单数据,同时HTTP请求方法将从默认的GET方式改为POST方式。
- headers -- 默认为空,该参数是一个字典类型,包含了需要发送的HTTP报头的键值对。
使用urllib实现数据传输
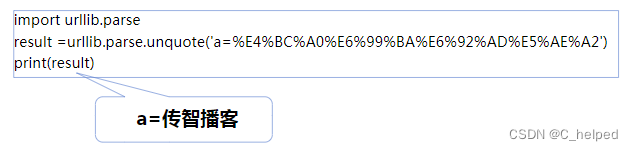
URL编码转换
当传递的URL中包含中文或者其它特殊字符(如 空格等)时,需要使用urllib.parse库中的 urlencode方法将URL进行编码

它可以将“key:value”这样的键值对转换成“key=value” 这样的字符串。
解码使用的是url.parse库的unquote方法。
处理GET请求
GET请求一般用 于向服务器获取 数据,比如说,我们用百度搜索传智播客。
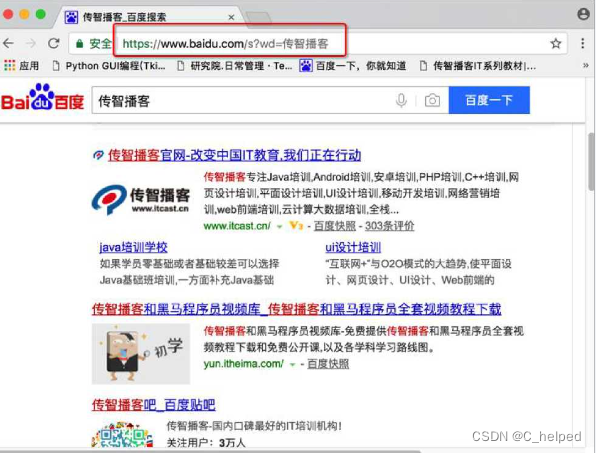
此时,如果使用Fiddler查看HTTP请求,发 现有个GET请求的格式如下:
https://www.baidu.com/s?wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2在这个请求中,“?”后面的字符串就包含了我们要 查询的关键字“传智播客”。
处理POST请求
当访问有道词典翻译网站进行词语翻译时,会发现不管输入什么内容,其URL一直都是不变的。
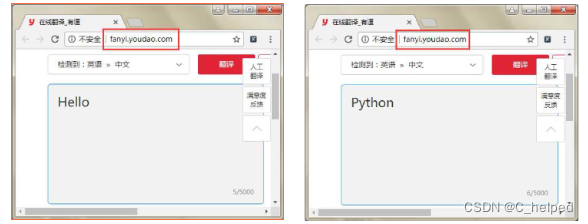
通过使用Fiddler观察,发现该网站向服务器 发送的是POST请求。
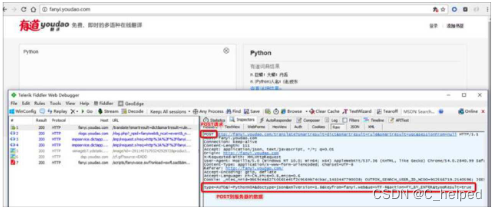
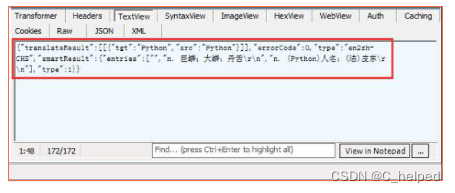
当使用有道词典翻译“Python”时,返回 的结果是一个JSON字符串。
添加特定Headers—请求伪装
如果不是从浏览器发出的请求,我们是不能获得 响应内容的。针对这种情况,我们需要将爬虫程 序发出的请求伪装成一个从浏览器发出的请求。
伪装浏览器需要自定义请求报头,也就是在 发送Request请求时,加入特定的Headers。
- user_agent = ("User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT6.1; Trident/5.0)"}
- request = urllib.request.Request(url, headers = user_agent)
- request.add_header("Connection", "keep-alive")
代理服务器
简单的自定义opener
思考 :
很多网站会检测某一段时间某个IP 的访问次数,如果同一IP访问过于频繁,那么该网站会禁止来自该IP的访问。碰到这种情况要怎么办呢?
结论:
我们可以使用代理服务器,每隔一段时间换一个 代理。如果某个IP被禁止,那么就可以换成其他 IP继续爬取数据,从而可以有效解决被网站禁止 访问的情况。
opener 是urllib.request.OpenerDirector类的对象,我们之前一直都在使用的urlopen, 就是模块帮我们构建好的一个opener。但是,urlopen不支持代理、Cookie等其他的 HTTP/HTTPS高级功能,所以如果要想设置代理,不能使用自带的urlopen,而是要自定义opener
自定义opener需要执行下列三个步骤:
- 使用相关的Handler处理器创建特定功能的处理器对象。
- 通过urllib.request.build_ opener()方法使用这些处理器对象创 建自定义的opener 对象。
- 使用自定义的opener对象,调用open方法发送 请求。
如果程序里所有的请求都使用自定义的opener,可以使用urllib2.install_opener() 将自定义的opener对象定义为全局opener,表示之后凡是调用urlopen,都将使用自定义的opener。
我们可以使用urllib.request中的ProxyHandler 方法来设置代理服务器。
- httpproxy_handler =urllib.request.ProxyHandler(
- {"http" : "124.88.67.81:80"})
- opener =urllib.request.build_opener(httpproxy_handler)
免费开放代理的获取基本没有成本,我们可以在一些代理网站上收集这些免费代理,测试后如果可以用,就把它收集起来用在爬虫上面。免费代 理网站主要有以下几个:
- 西刺免费代理IP Proxy360代理
- 全网代理IP 快代理免费代理
如果代理IP足够多,就可以像随机获取User-Agent 样,随机选择一个代理去访问网站。
- import random
- proxy_list =
- [{"http" : "124.88.67.81:80"}, {http" : "124.88.67.81:80"}, {"http" : "124.88.67.81:80"}, {"http" : "124.88.67.81:80"}, {"http" : "124.88.67.81:80"}]
- #随机选择一个代理
- proxy = random.choice(proxy_list)
免费开放代理一般会有很多人都在使用,而且代理有寿命短,速度慢,匿名度不高等缺 点。所以,专业爬虫工程师或爬虫公司会使 用高品质的私密代理,这些代理通常需要找 专门的代理供应商购买,再通过用户名/密 码授权使用。
超时设置
假设我们要爬取1000个网站,如果其中有100个网站需要等待30s才能返回数据,则要返回所有的数据,至少需要等待3000秒。
我们可以为HTTP请求设置超时时间,一旦超过这个时 间,服务器还没有返回响应内容,那么就会抛出一个 超时异常,这个异常需要使用try语句来捕获。
- try:
- url = 'http://218.56.132.157:8080,
- # timeout设置超时的时间
- file = urllib.request.urlopen(url, timeout=1) result = file.read()
- print(result)
- except Exception as error:
- print(error)
小结:
本章分享了Python中用作抓取网页库:urllib。 首先简单地介绍了一下什么是urllib库,然后讲解了关于urllib的一些使用技巧,包括使用urllib传输数据、添加特定的Headers.简单自定义opener、服务器响应超时设置,以及一些常见的网络异常,的案例,介绍了如何使用urllib抓取网页数据。


