
热门标签
热门文章
- 1苹果电脑 MacOS 系统可以玩Palworld / 幻兽帕鲁游戏吗_macos 游戏
- 2图神经网络实战(17)——深度图生成模型
- 3人/自动化的交互
- 4EC2 windows 手动加入AD_aws ec2 windows 加入域控
- 5前端反显后端图片、上传预览图片
- 6websocket-sdk 解决本地服务与浏览器之间的连接, 以及浏览器与服务器之间的数据传输_本地sdk上传和浏览器上传
- 724-25届最新计算机毕业设计大数据选题推荐 -大数据毕业设计题目参考大全_基于大数据的购物车智能推荐与分析系统
- 8如何应用Python助你在股票中获利?_如何用python编写炒股软件赚钱
- 9Go的数据结构与实现【LinkedList】_go 链表
- 10mysql触发器触发hive_mysql触发器 - osc_e4hg9m7f的个人空间 - OSCHINA - 中文开源技术交流社区...
当前位置: article > 正文
B+Tree原理_b+树叶子节点里的数据是顺序查找还是二分
作者:木道寻08 | 2024-07-15 11:33:03
赞
踩
b+树叶子节点里的数据是顺序查找还是二分
B+Tree结构
B Tree指的是平衡树,并且所有叶子节点位于同一层。
B+Tree是基于B Tree和叶子节点顺序访问指针进行实现,它具有B Tree 的平衡性,并且通过顺序访问指针来提高区间查询的性能。
在B+Tree 中,一个节点中的key从左到右非递减排列,如果某个指针的左右相邻key分别是key1和key2,且不为null,则该指针指向几点的所有key大于等于keyi且小于等于keyi+1.
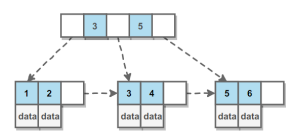
相关操作
- 查找时,首先在根节点进行二分查找,在根节点中找到key所在的指针,然后递归到key子节点进行查找,直到找到那个叶子节点,然后在这个叶子节点上进行二分查找,找出key锁对应的data.
- 插入删除等操作会破坏其平衡性,这里的操作会很复杂,需要对树进行一个分裂、合并、旋转等操作来维护其平衡性。
比较
-
与红黑树比较
红黑树等平衡树也可以用来实现索引,但是文件系统及数据库系统普遍采用B+Tree作为索引结构,因为:
1.查找次数更少
平衡树查找操作的时间复杂度跟树高h有关,o(h)=o(logdn),其中d为每个节点的出度。红黑树的出度为2【因为红黑树是二叉树】,而B+Tree的出度一般都非常的大,所以红黑树的树高h很明显比b+Tree大很多,查找的次数也就更多。
2.利用磁盘预读特性
为了减少磁盘I/O操作,磁盘并不是每次需要才去读取,而是会进行预读取。在预读取的过程中,磁盘进行顺序读取,顺序读取不需要进行磁盘寻道,并且只需要很短的磁盘旋转时间,速度会非常快。
【操作系统一般将内存和磁盘分割成固定大小的块区域,每一块称为一页,内存与磁盘以页为单位交换数据。】
【数据库系统将索引的一个节点的大小,使得一次I/O就能完全载入一个节点,并且可以利用预读特性,相邻的节点也能被预先载入】
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
相关标签

