
- 1wakeup_in休眠唤醒_gpio唤醒和休眠状态
- 2五分钟搭建一个Suno AI音乐站点_suno api
- 3微信dnf手游服务器上限,DNF手游:服务器跨区规则上线,玩家扎堆进一区,团本互通...
- 4超详细BERT介绍(一)BERT主模型的结构及其组件_bert模型架构图
- 5【Day02】0基础微信小程序入门-学习笔记
- 6【SD教程】全网最详细的AI绘画提示词语法讲解!(附提示词插件包)
- 7sublime text 3教程_sublime text 3 sidebarenhancements
- 8一篇读懂无线充电技术(附方案选型及原理分析)
- 9AR视频技术与EasyDSS流媒体视频管理平台:打造沉浸式视频体验
- 10python中,当sort对象为多个字符串时,如何排序
使用VLM搭建ComfyUI-Dream-Interpreter梦境解析器_comfyui llava
赞
踩
人类学习本质上是多模态 (multi-modal) 的,因为联合利用多种感官有助于我们更好地理解和分析新信息。理所当然地,多模态学习的最新进展即是从这一人类学习过程的有效性中汲取灵感,创建可以利用图像、视频、文本、音频、肢体语言、面部表情和生理信号等各种模态信息来处理和链接信息的模型。随着自然语言处理和计算机视觉的交叉融合,视觉-语言模型(VLM)已成为一个热门的研究领域。
视觉语言模型 (VLM) 采用多模态架构,可同时处理图像和文本数据。他们可以执行视觉问答 (VQA)、图像标题和文本到图像搜索类型的任务。VLM 利用多模态融合与交叉注意力、掩码语言建模和图像文本匹配等技术将视觉语义与文本表示相关联。此存储库包含有关著名视觉语言模型 (VLM) 的信息,包括有关其架构、训练过程和用于训练的数据集的详细信息。单击以展开以了解每种架构的更多详细信息。
接下来我们使用ComfyUI-Dream-Interpreter搭建一个全景的梦境解析器,话不多说,下面开始部署:
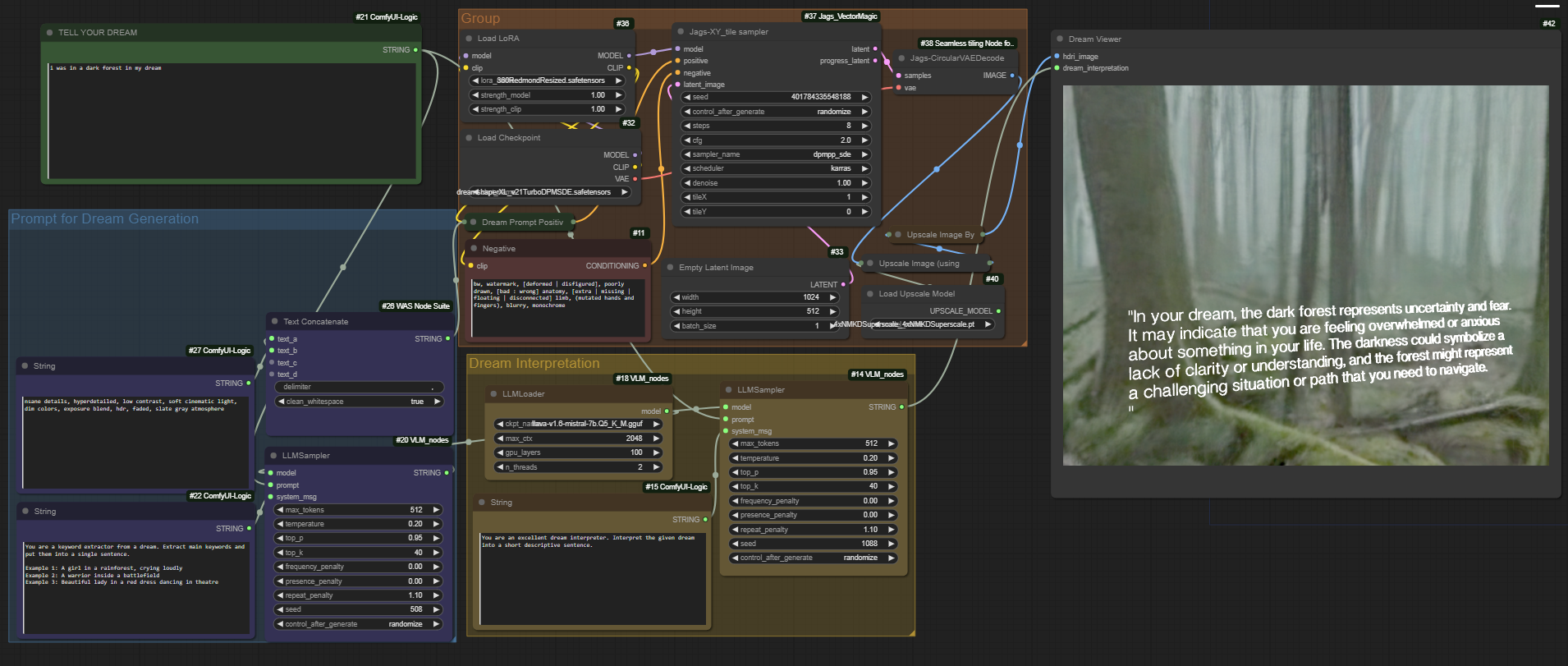
一:安装ComfyUI的三个节点插件
git clone https://github.com/gokayfem/ComfyUI-Dream-Interpreter.git
git clone https://github.com/gokayfem/ComfyUI_VLM_nodes.git
git clone https://github.com/jags111/ComfyUI_Jags_VectorMagic.git
二:下载工作流

下载这个工作流文件dream_interpretation_workflow.json,保存到你能随时找到的地方。
三:下载模型
这个工作很重要,全部模型145G,用的到的主要有以下几个:
1、dreamshaperXL_v21TurboDPMSDE.safetensors,去C站下载,当然如果找不到也可以用其他的标准模型代替。
下载位置:https://civitai.com/models/112902?modelVersionId=351306
安装位置:models\checkpoints
2、下载LoRa,360RedmondResized.safetensors。
下载地址:https://civitai.com/models/118025/360redmond-a-360-view-panorama-lora-for-sd-xl-10
安装位置:models\loras
3、下载视频模型:llava-v1.6-mistral-7b.Q5_K_M.gguf
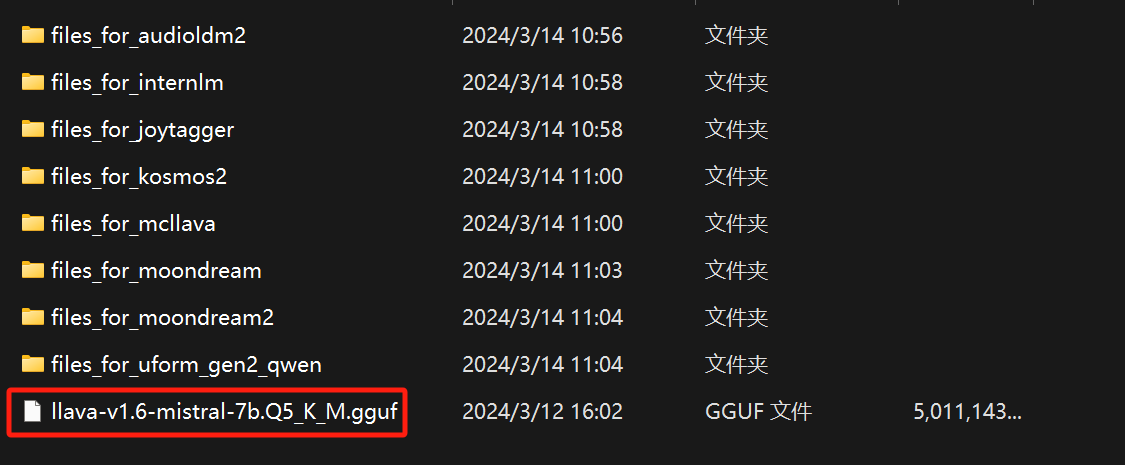
全部这么多文件,不过你可以只下载最后一个。
下载位置:https://huggingface.co/cjpais/llava-1.6-mistral-7b-gguf/tree/main
安装位置: models\LLavacheckpoints
4、下载yolov8:

大约这些文件模型是ComfyUI_Jags_VectorMagic节点所需要的。
下载位置:https://huggingface.co/jags/yolov8_model_segmentation-set/tree/main
安装位置:models\yolov8
5、clipseg

ComfyUI_Jags_VectorMagic节点还需要以下这些模型。
下载位置:https://huggingface.co/CIDAS/clipseg-rd64-refined/tree/main
安装位置:models\clipseg
四:运行
导入工作流文件:dream_interpretation_workflow.json,然后运行就可以了。

