
- 1执子之手简约唯美的表白网站HTML源码_2022唯美执子之手表白网html源码
- 2【2022应届生看过来】一个无经验的大学毕业生,可以转行做软件测试吗?_软件测试应届没有经验
- 3[沫忘录]Golang基础类型与语法
- 4Pycharm基础——文件操作(IO)技术_pycharm文件操作
- 5智慧校园毕业管理:全面解读毕业批次功能
- 6关于高性能滤波器和普通型滤波器的区别说明
- 7【计算机网络】域名劫持无处遁形:基于HTTPDNS打造可靠且安全的域名解析体系_域名解析接口
- 8基于javaweb+mysql的ssm外卖订餐管理系统(java+ssm+jsp+jquery+ajax+mysql)_外卖系统的前后端开发技术
- 9python选择题_python:选择题系列01
- 10动态链接(ELF文件)_elf动态链接
Llama 3 发布!目前最强开源大模型!!
赞
踩
▼最近直播超级多,预约保你有收获

—1—
最强开源大模型
Meta 于昨天正式发布 Llama 3,官方号称「有史以来最强大的开源大模型」。
本次发布了 8B 和 70B 参数的大模型,提供了新功能,改进了推理能力、代码生成和遵循指令,在行业基准测试上均为最先进的性能!

详细评测细节:
https://github.com/meta-llama/llama3/blob/main/eval_details.md
—2—
Llama 3 如何打造出最强性能?
第一、模型架构的优化
Llama 3 模型设计遵循简化高效原则,选用标准解码器型 Transformer 结构。相较于 Llama 2,主要改进包括:采用高效 128K tokens 分词器提升模型性能;在 8B 和 70B 规模模型中应用分组查询注意力(GQA)技术以提高推理效率;训练时模型处理不超过 8,192 Token的序列,运用掩码技巧防止跨文档边界注意力,确保准确性与效率。
第二、构建好的训练数据
构建顶级大语言模型的关键在于庞大且优质的训练数据。Llama 3 预训练使用超 15T Token,源自公开数据,较 Llama 2 训练集规模增七倍,代码数据翻四倍。其中 5% 为覆盖 30+ 种非英语言的高质量数据,预期性能略逊于英语。我们设计先进数据过滤流程(启发式过滤、NSFW剔除、语义去重、文本质量分类),利用 Llama 2 辅助筛选,确保 Llama 3 训练数据优质。通过大量实验优化数据源混合策略,使 Llama 3在问答、STEM、编程、历史等领域表现出色。
第三、扩大预训练规模
为使 Llama 3 充分利用预训练数据,我们制定了详尽 Scaling Laws,指导数据处理与资源使用效率,预估模型在 HumanEval 等任务的最大性能,确保其在各场景表现卓越。研究揭示:无论 8B 或 70B 参数模型,在处理远超 Chinchilla 建议的 200B Token 后,性能仍随 15T Token 训练量对数线性提升。尽管大型模型在少量资源下媲美小型模型,后者因推理高效更受欢迎。
训练最大规格 Llama 3 运用数据、模型、流水线三类并行技术,高效实现单 GPU 超 400 TFLOPS,在 16K GPU 集群上运行。开发先进的训练栈,集成错误检测处理、硬件可靠性提升、静默损坏检测优化及可扩展存储系统,将训练效率提升至 95% 以上,相比 Llama 2 约增三倍。
第四、指令微调(Fine-tuning)
我们创新指令微调方法,结合S FT、拒绝抽样、PPO、DPO,提升聊天应用中预训练模型性能。关键在于提示词质量筛选、偏好排名优化,经多轮人工审核大幅提高模型品质。通过 PPO & DPO 从偏好中学习,Llama 3 在逻辑推理与编程任务显著进步,尤其学会在复杂问题中辨识并选择正确答案。
—3—
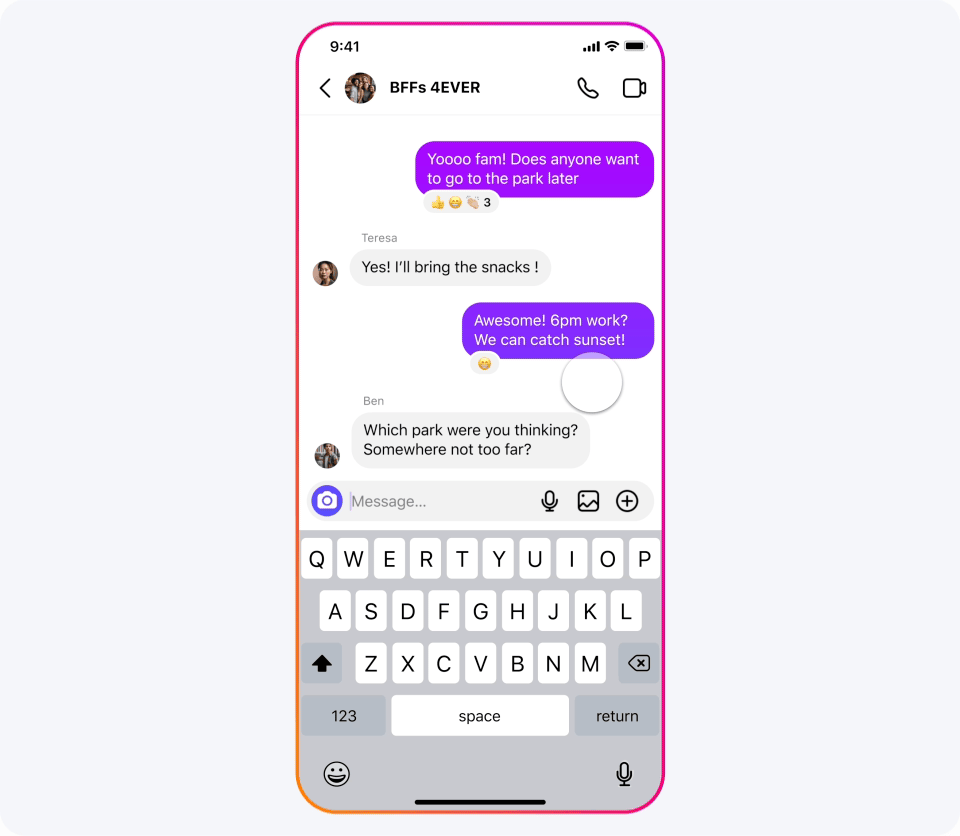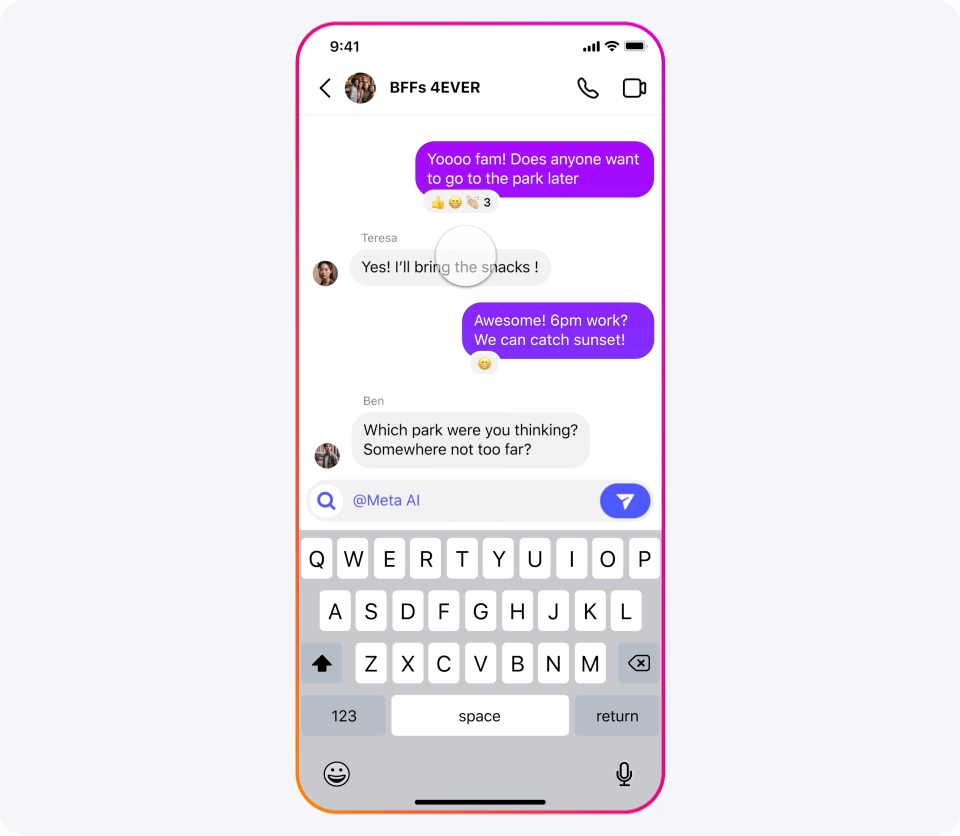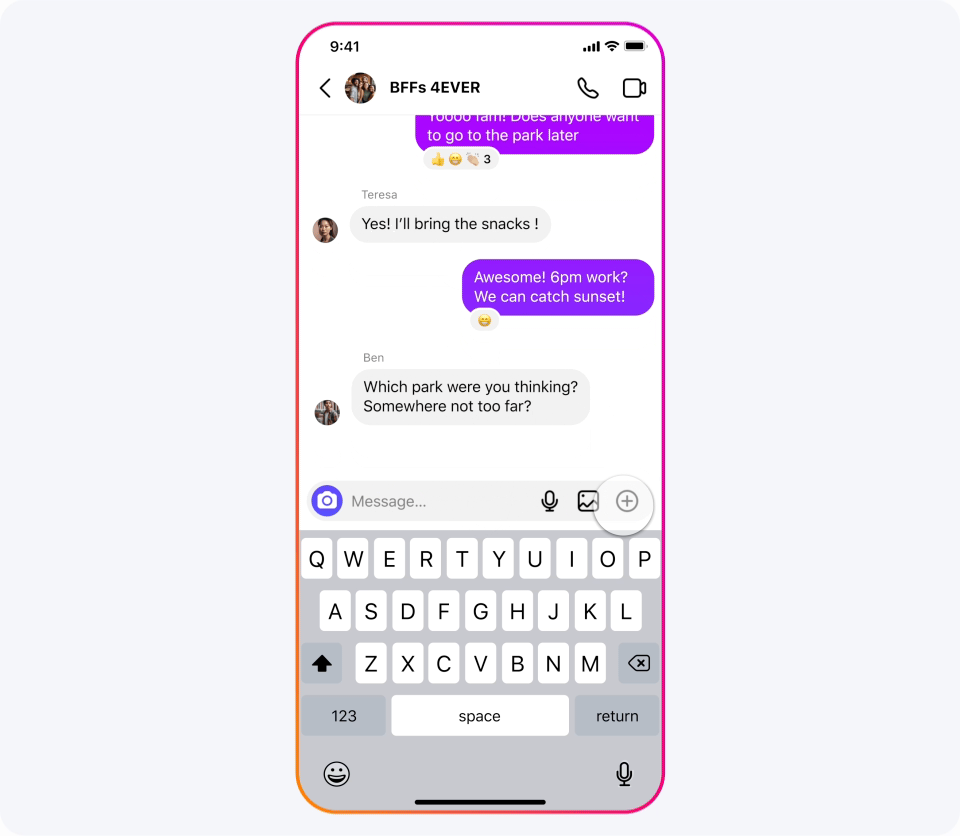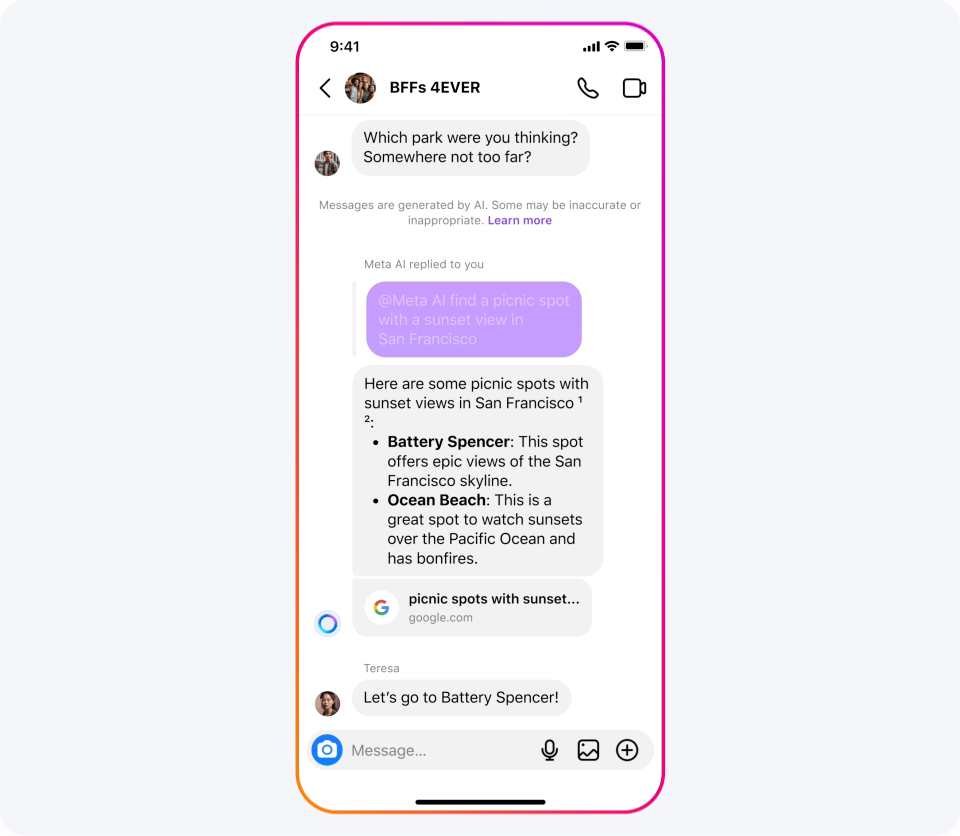
Meta AI:可画图可聊天、随处可见的 AI 助手
我们已经将我们的最新模型集成到 Meta AI 中,我们认为这是世界上领先的 AI 助手。它现在采用 Llama 3 技术构建,并且可以在我们应用的更多国家中使用。
比如以下场景都可以求助 Meta AI:寻求美好夜游、周末短行、临时复习或新居布置?向 Meta AI 求助:推荐观日落兼素食餐厅、搜寻周六音乐会、解析遗传原理、提供理想家居风格的灵感图片。
—4—
基于 Llama 3 的应用架构落地
为了帮助同学们彻底掌握 Llama 3 大模型的知识库、 Agent 智能体、向量数据库、 RAG、知识图谱的应用开发、部署、生产化,今天我会开两场直播和同学们深度剖析,请同学们点击以下预约按钮免费预约。
—5—
!送!AI大模型开发直播课程
大模型的技术体系非常复杂,即使有了知识图谱和学习路线后,快速掌握并不容易,我们打造了大模型应用技术的系列直播课程,包括:通用大模型技术架构原理、大模型 Agent 应用开发、企业私有大模型开发、向量数据库、大模型应用治理、大模型应用行业落地案例等6项核心技能,帮助同学们快速掌握 AI 大模型的技能。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

