
- 1Cesium.js基础使用(vue)
- 2网络工程实训_5交换机配置
- 3nginx快速入门,使用多种方式部署nginx(mac/windows/docker/docker-compose)_mac nginx
- 4总结:大模型技术栈---算法与原理
- 5python怎么做gui界面,python gui界面设计_gui练习-制作两个界面
- 6django + mssql + sqlserver2008_django+serversql源码
- 7git 本地改动了,不保留,直接拉取线上最新代码_git强制拉取最新代码覆盖原有代码的命令
- 8性能监控与报告:实时了解ReactFlow应用的性能指标
- 9【蓝桥杯】-刷题技巧-总结_蓝桥杯会员到期可以刷题吗
- 10python获取剪切板内容
nlp基础-文本预处理及循环神经网络_nlp文本预处理
赞
踩
1 认识文本预处理
-
1 文本预处理及其作用
-
定义:文本送给模型之前,提前要做的工作
-
作用:指导模型超参数的选择 、提升模型的评估指标
-
举个例子:
- 思路常识,打造成 X Y
- 关于Y:10分类标签是否均衡
- 关于X:数据有没有脏数据 数据长度(512)样本不够!
-
文本预处理 工作 结束 的标志:准备出来X和Y 能送给模型
-
-
2 文本预处理的主要环节
-
1 文本处理的基本方法
-
分词:按照一定规则对文本重新划分,进行分词
-
词性标注:把文本序列标注出来动词、名词、形容词这个过程词性标注
-
命名实体识别:把专有名词(人名、地名、机构名)给识别出来。
- 比如:对话系统要进行命名实体识别,对语义进理解。
-
-
2 文本张量表示方法: 就是把我们的单词转成数值化的数据 张三【88,87, 86 ,85, 84】文本数值化、数值张量化
-
one-hot编码: low 稀疏词向量表示
-
Word2vec:稠密词向量表示
-
Word Embedding:稠密词向量表示
-
-
3 文本语料的数据分析:就是对数据的x y进行分析
-
标签数量分布:对y:十分类:类别是不是均衡
-
句子长度分布:对x:文本长度有的是100个长度,有的是200,
-
词频统计与关键词词云:形容词词云
-
-
4 文本特征处理:我 爱 北京 天安门
-
添加n-gram特征 【101,102,103,104,105】:105代表【北京 天安门】相邻共现,可以作为一个新的特征加入到文本序列中;增强模型对文本序列特征抽取
-
文本长度规范:有些模型送入的数据长度不能超过512
-
-
5 数据增强方法: 数据不够,看如何增加语料
- 1 回译数据增强法:中文–>韩语 -->葡萄牙–>中文,新增了一条样本
-
-
3 思考题,文本处理的主要环节中,哪一些环节是第一个要做的?
- 一般情况,文本语料的数据分析是程序员首先要做的工作。
2 文本处理的基本方法
-
分词定义和作用:
- 定义: 将连续字符按照一定规则重新排序的过程
- 作用: 理解语义的最小单元!
- 为什么要分词:中文没有明显的分解符 英文天然空格是分解符
- 对中文分词来讲:不断寻找分解符的过程
-
流行分词工具jieba
- 支持多种分词模式(三种模式)
- 精确模式:
- 全模式:
- 搜索引擎模式:
- 支持中文繁体分词
- 支持用户自定义词典
- 自定义字典的格式
- 支持多种分词模式(三种模式)
-
结巴分词编程api
-
三种模式
jieba.lcut(content, cut_all=False) 精确模式 jieba.lcut(content, cut_all=True) 全模式 jieba.cut_for_search(content) 搜素引擎模式- 1
- 2
- 3
-
中文繁体分词
- jieba.lcut(content, cut_all=False) 精确模式
-
用户自定义词典
-
jieba.load_userdict('./userdict.txt') mydata2 = jieba.lcut(sentence)- 1
- 2
-
-
-
什么是命名实体识别 (NER)
- 命名实体:指人名地名机构名等专有名字
- 命名实体识别:对一句话中的专有名词进行识别(NER - Named Entity Recognition)
-
词性标注
- 词性定义: 动词名词形容词
- 词性标注定义:对文本先分词,然后再标注词性
- 词向标注也是对此的一种分类方法
- 单词级别的分类
- 词向标注也是对此的一种分类方法
3 文本张量表示方法
- 什么是文本张量表示
- 定义:
- 把词表示成向量的的形式,也就是词向量,一句话表示成词向量矩阵。这个过程就是文本张量表示。
- 作用:
- 方便输入到计算机中
- 文本张量的表示方法:三种
- one-hot
- word2vec
- wordenbedding
- 定义:
-
什么是one-hot词向量表示
-
定义: 有一个位置是1 其他全部是零
-
编程api
-
mytokenizer.fit_on_texts(vocabs) # 生成两个表 word2idx idx2word zero_list = [0] * len(vocabs) zero_list[idx] = 1 joblib.dump(mytokenizer, './mytokenizer') mytokenizer = joblib.load('./mytokenizer') # oov单词问题- 1
- 2
- 3
- 4
- 5
- 6
-
-
one-hot编码的优劣势:
- 优点: 简单
- 缺点: 割裂了词和词之间的关系 浪费空间、内存
- 稀疏词向量表示
-
-
什么是word2vec
-
word2vec概念
- 1 也是一种词向量的表示方法 (把词表示成向量 ;一句话表示成向量矩阵)
- 2 使用深度学习的方法 也就是使用深度学习网络的方法
- 使用深度学习网络的参数 来表示词向量
- 深度学习网络(模型)入门的重要点:区分数据和参数
- word2vec的思想使用:深度神经网络的参数 来充当词向量
-
CBOW(Continuous bag of words)模式:
-
skipgram词向量训练模型
-
-
使用fasttext工具实现word2vec的训练和使用
-
第一步: 获取训练数据
-
wikifil.pl 文件处理脚本来清除XML/HTML格式的内容 1. 下载语料库, wget -http://mattmahoney.net/dc/enwik9.zip 2. 解压语料库, unzip enwik9.zip 3. 处理语料库, perl wikifil.pl enwik9 > fil9 4. head -n enwik9 查看多少行 5. head -c 200 fil9_3 查看前200个单词- 1
- 2
- 3
- 4
- 5
- 6
-
-
第二步: 训练词向量
-
词向量安装
-
源码安装
-
import fasttext model = fasttext.train_unsupervised('data/fil9') model.get_word_vector("the") # 获取词向量 如何查看fasttext源码安装的路径 pip freeze | grep fasttext > fasttext @ file:///Users/bombing/.virtualenvs/nlp-py37-env/fastText # 思考题:获取词向量的流程? # 思考题:是无监督学习吗?- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
-
-
第三步: 模型超参数设定
- dim: 默认为100
- epoch: 默认为5
- 学习率lr: 默认为0.05,
- thread: 默认为12个线程
-
第四步: 模型效果检验
- model.get_nearest_neighbors(‘music’)
-
第五步: 模型的保存与重加载
-
mymodel.save_model(“./data/fil9.bin”)
-
mymodel = fasttext.load_model(‘./data/fil9.bin’)
-
-
-
word embedding(词嵌入)
- 广义的word embedding: 用深度神经网络来训练我们的词向量
- 神经网络是浅层 – word2vec
- 大型-----wordembedding
- 狭义的word embedding
- 神经网络的某一个层 nn.Eembedding
- 广义的word embedding: 用深度神经网络来训练我们的词向量
1.1 RNN模型
1 有关seq2seq架构重要场景

2 有关rnn的9个参数重要场景
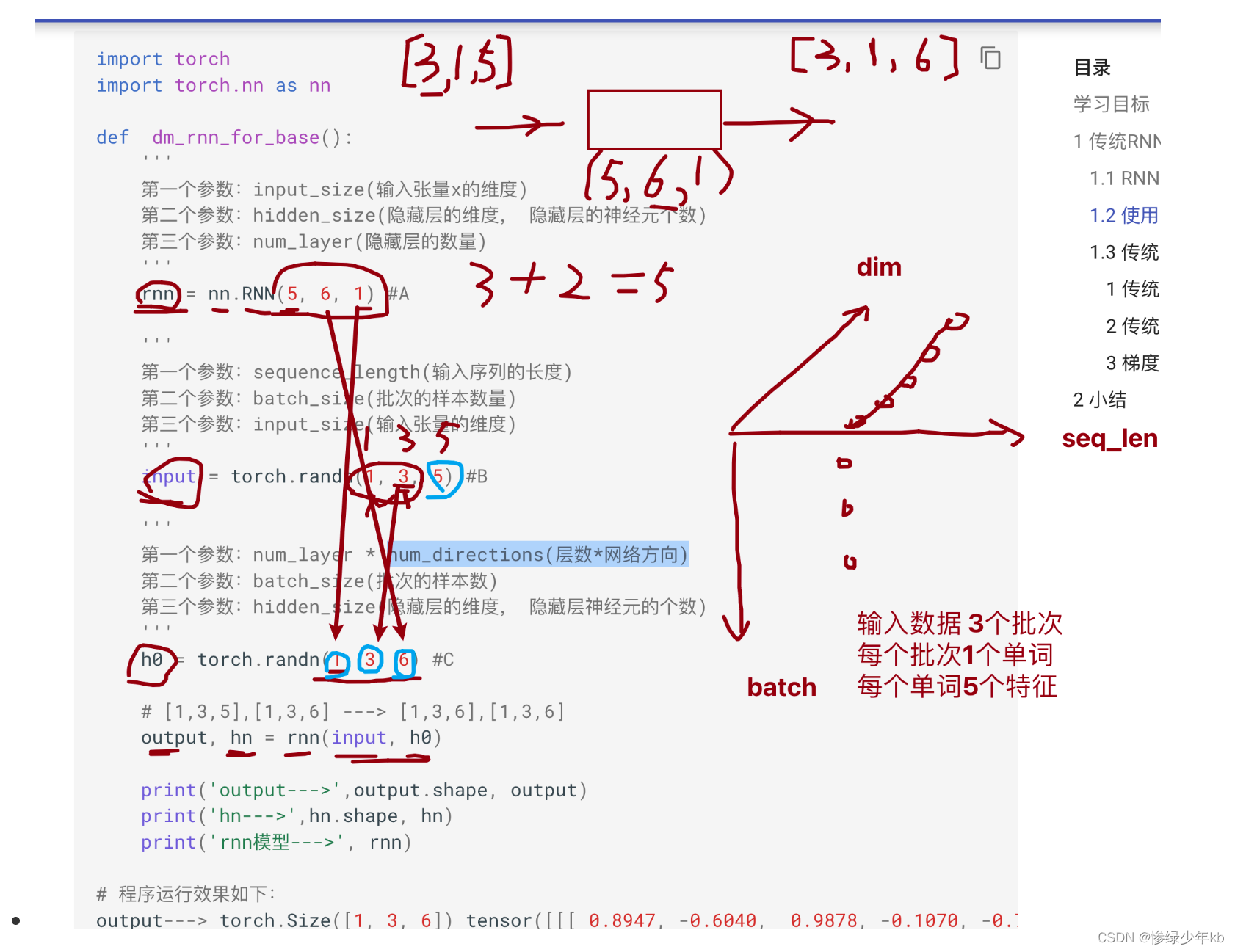
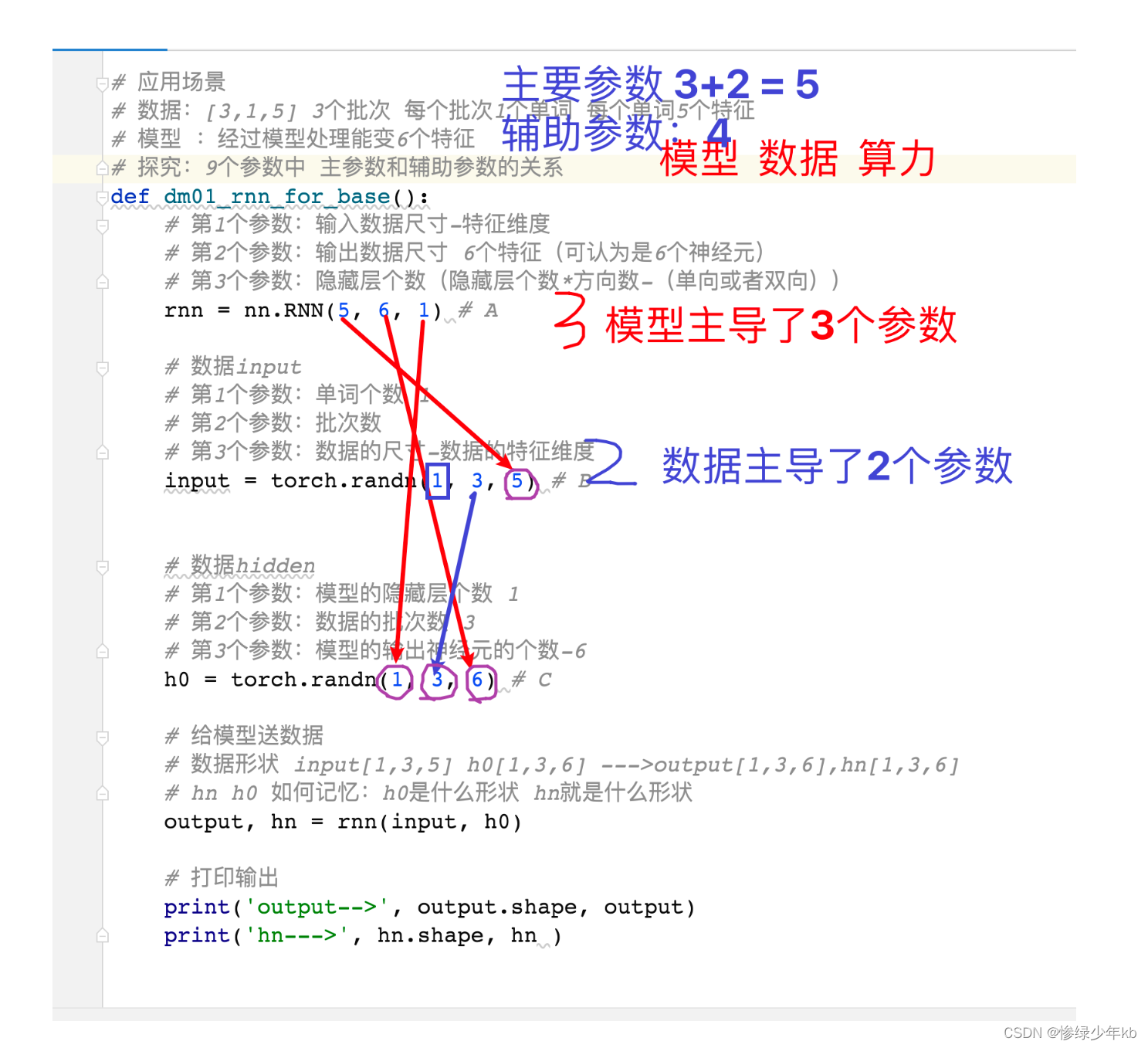
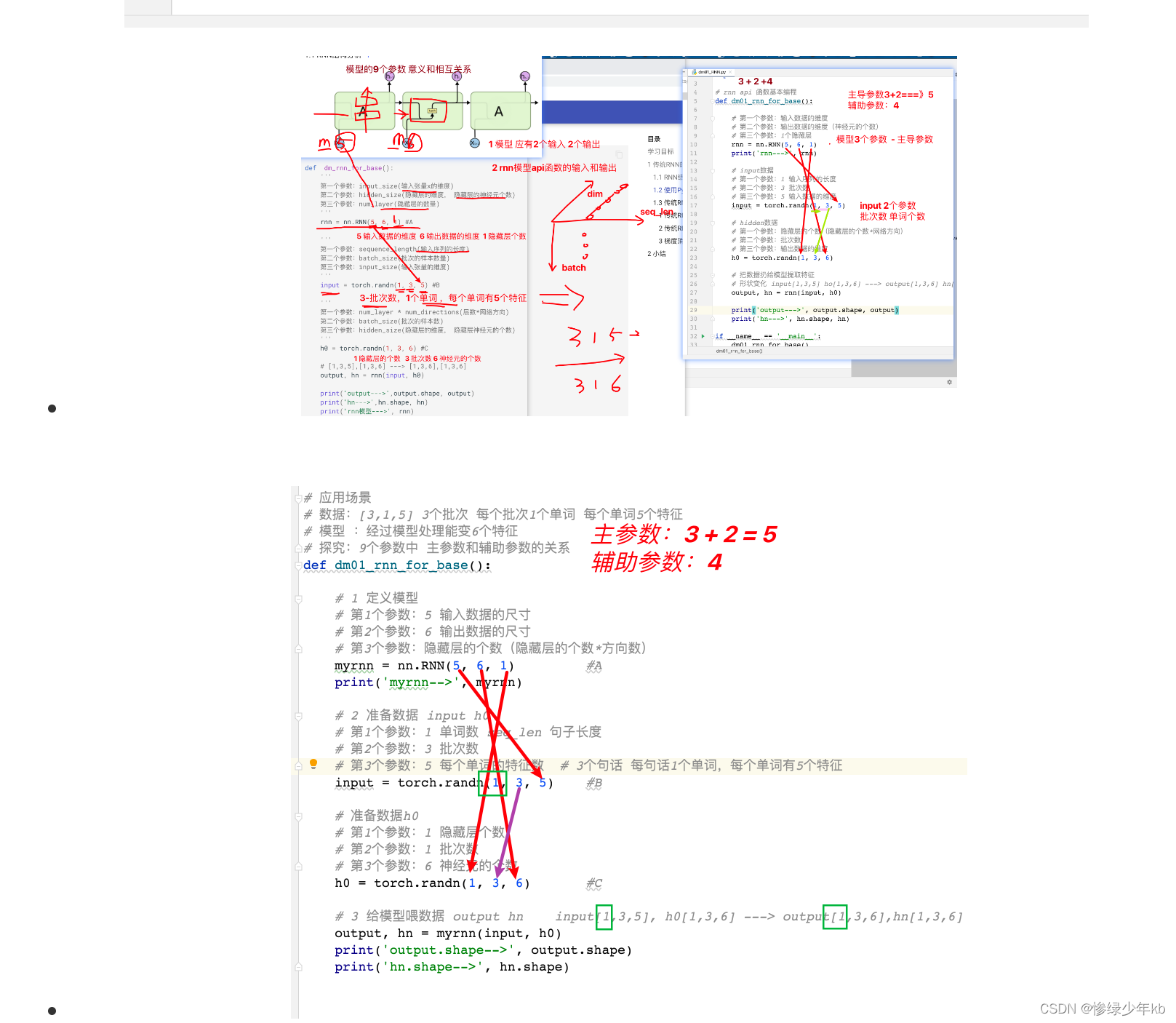
3 有关隐藏层个数理解重要场景
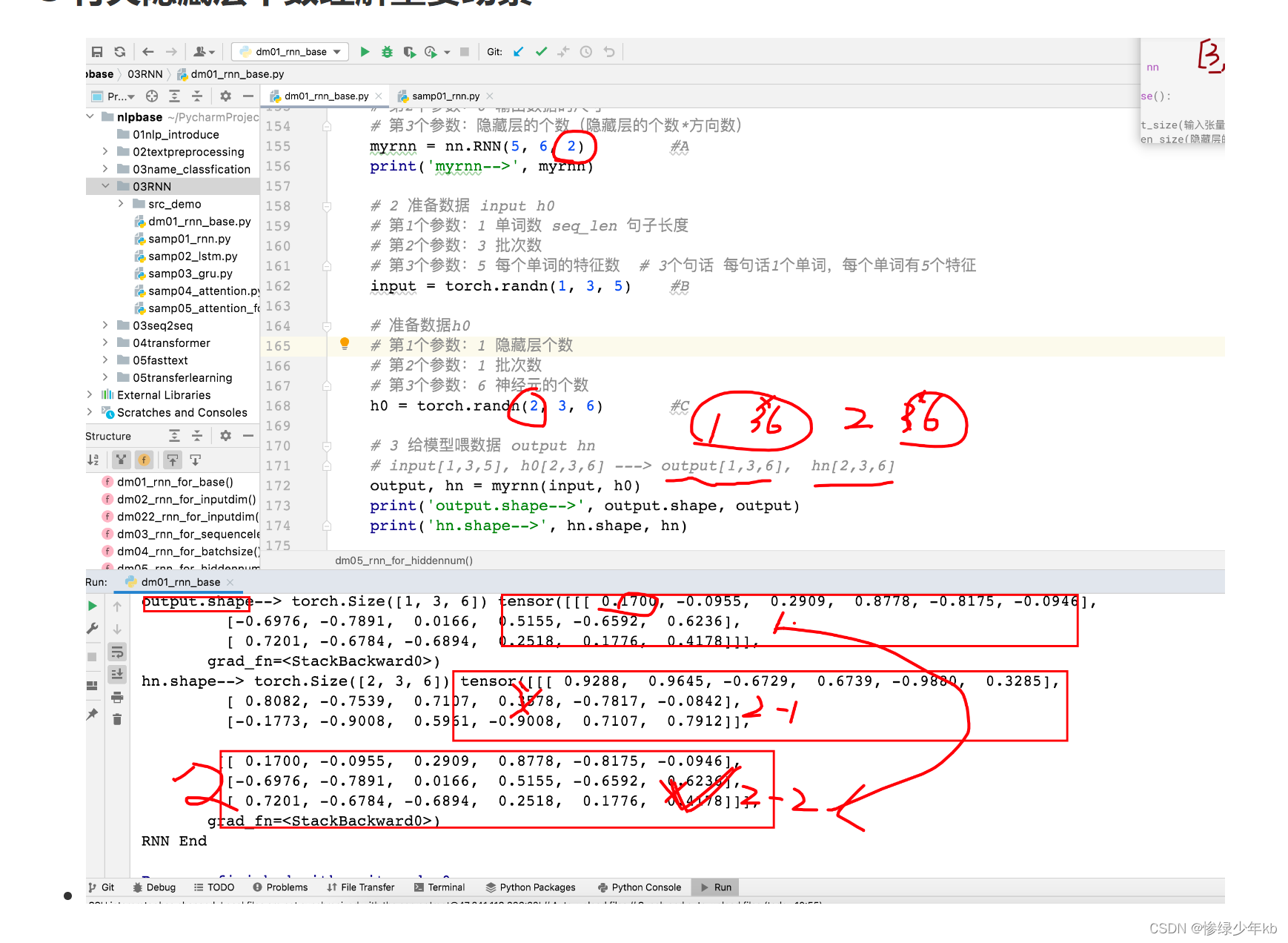
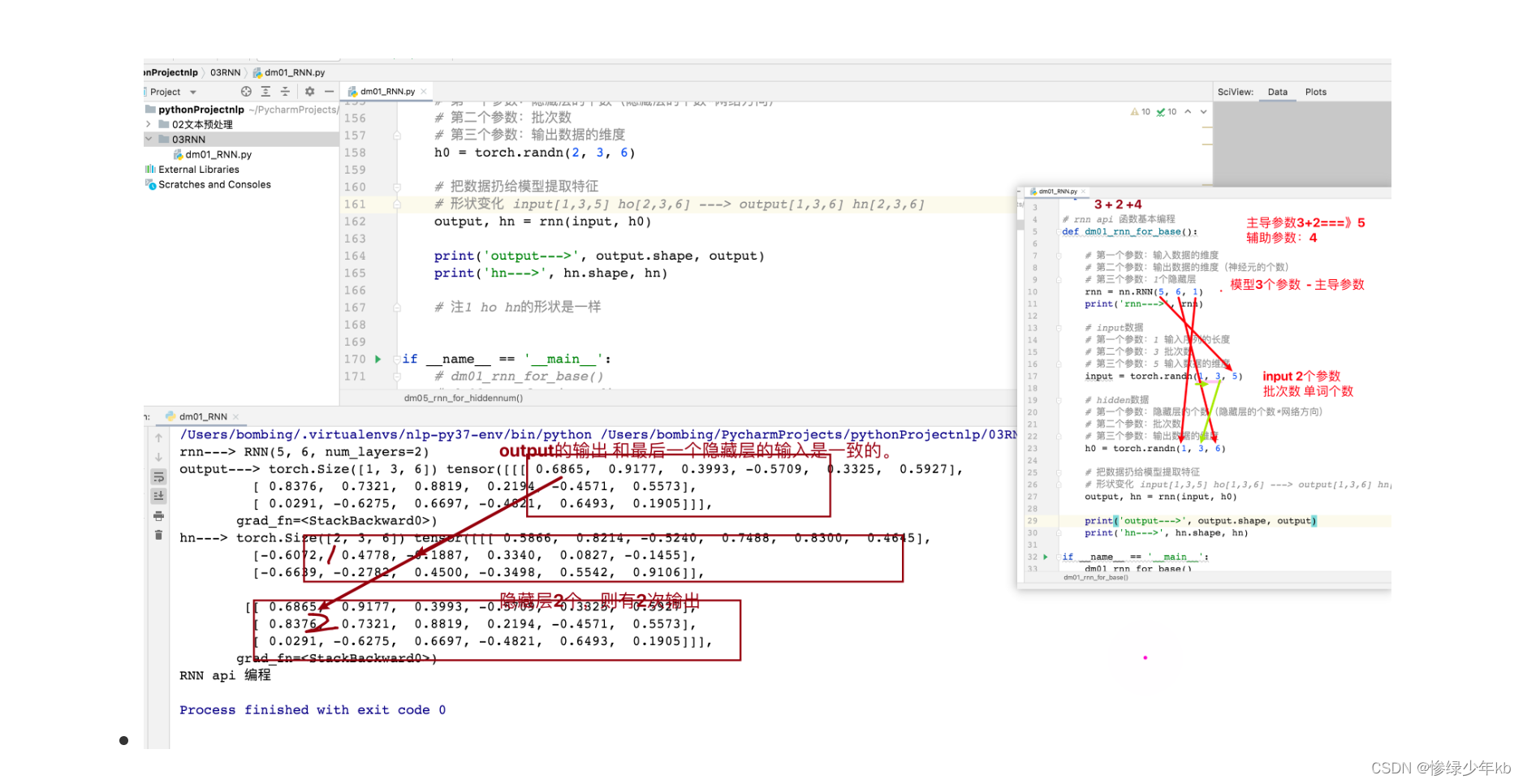
4 场景:每个时间步都是用rnn的模型权重参数
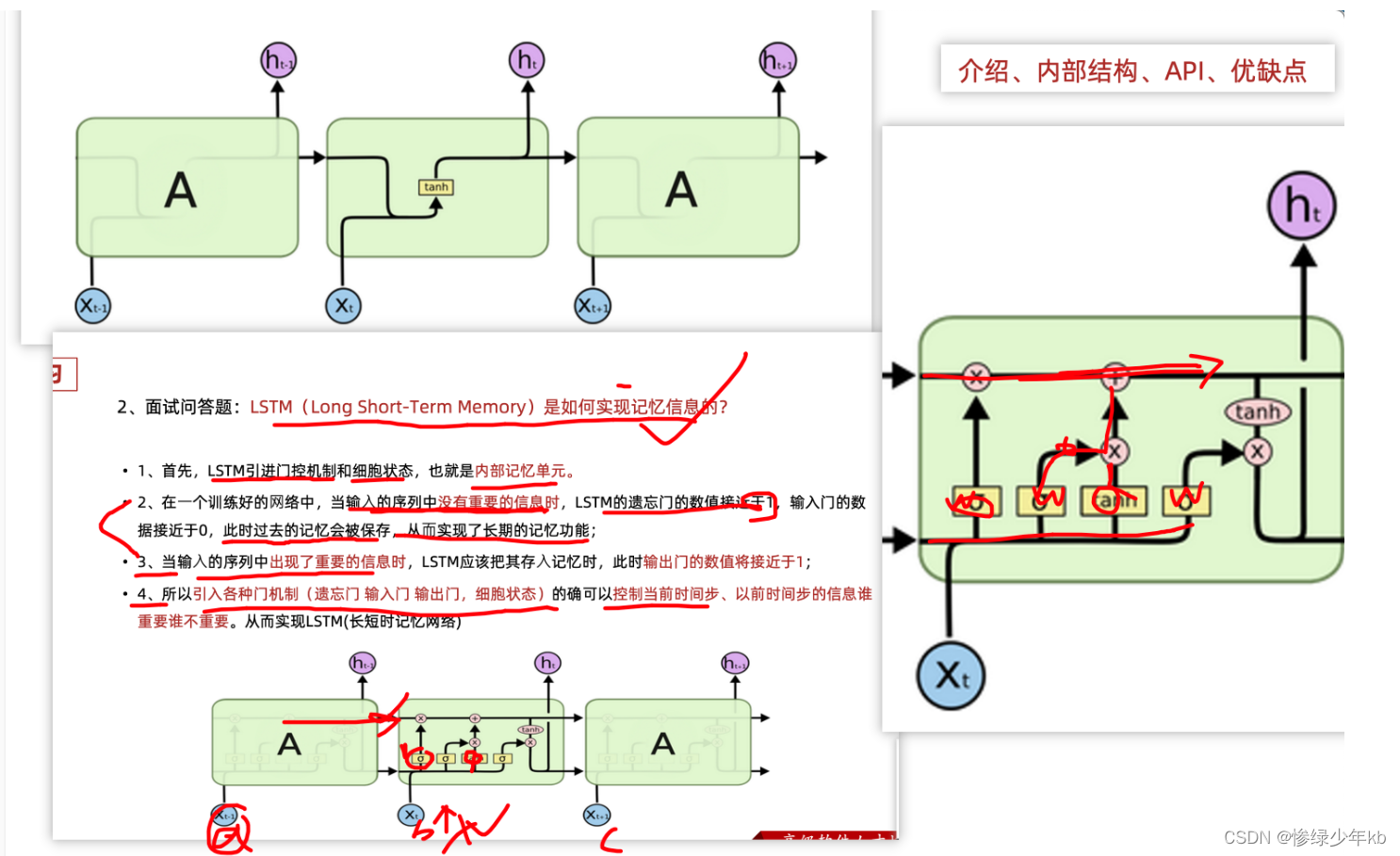
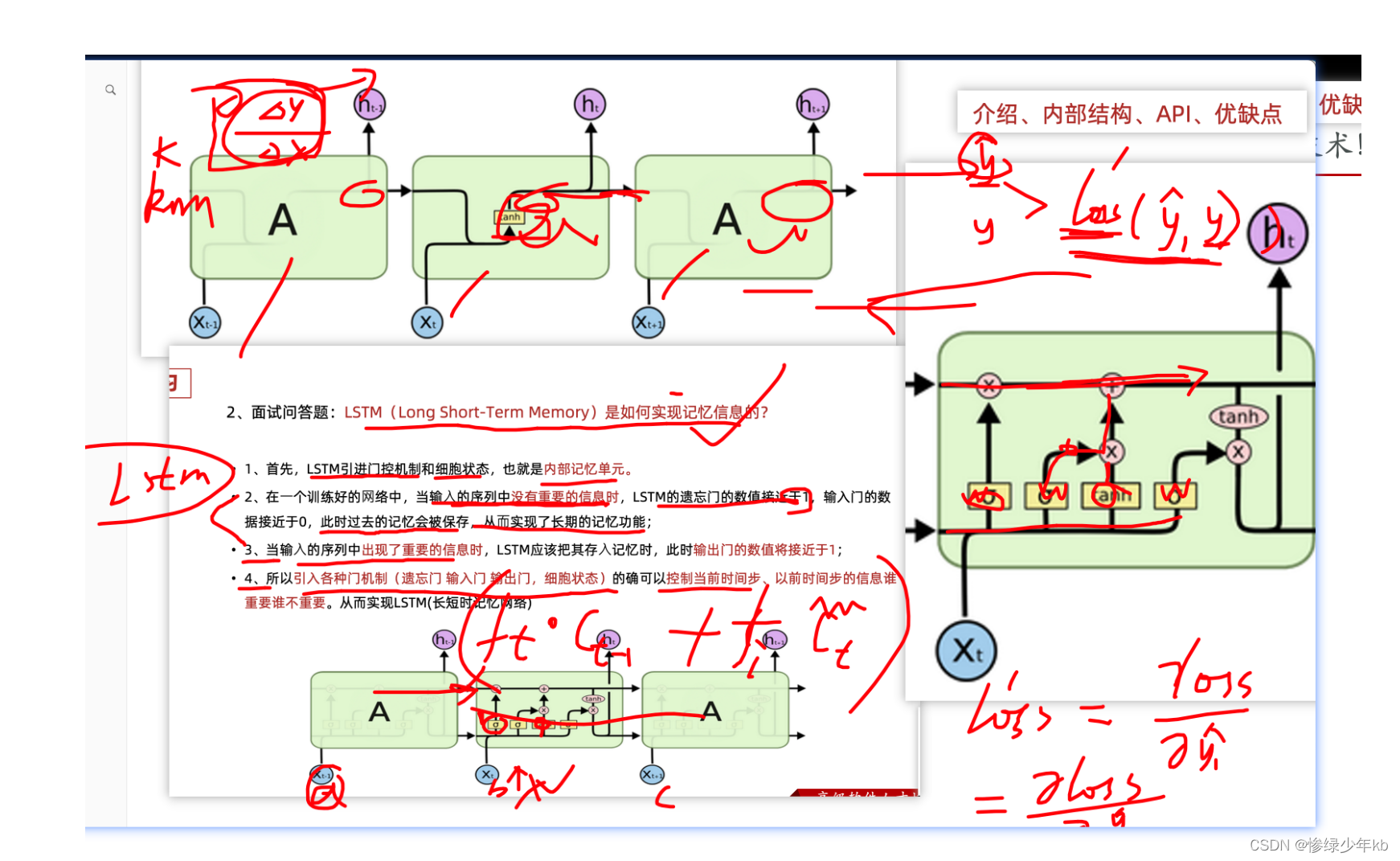
1.2 LSTM(长短时记忆网络)
- 门如何理解
- 缩放系数:对一堆数据乘上一个门,相当于给一堆数据乘上一个缩放系数
- 对输入数据进行加权!
1 场景:门的综合图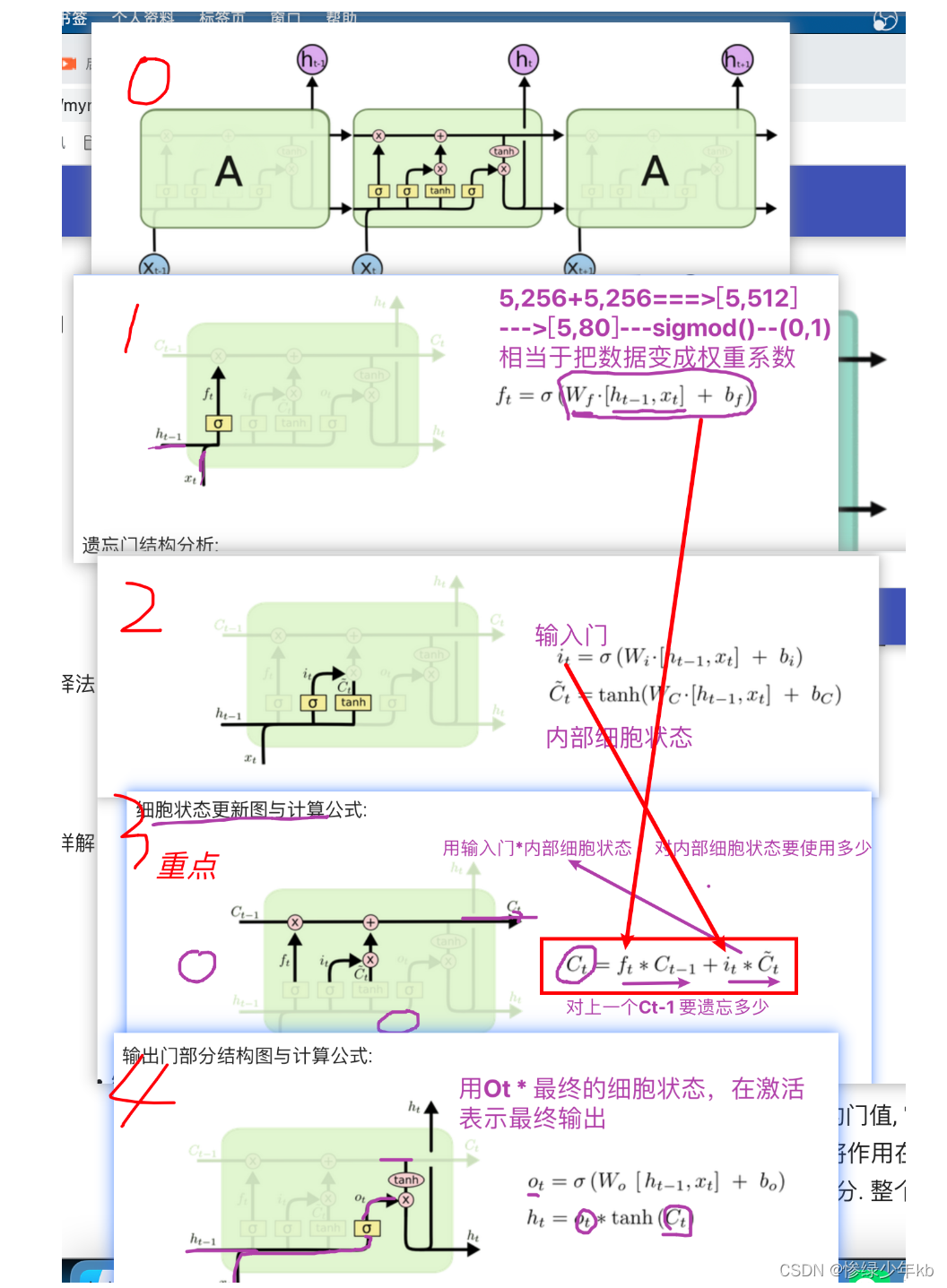
2 场景:遗忘门和输入门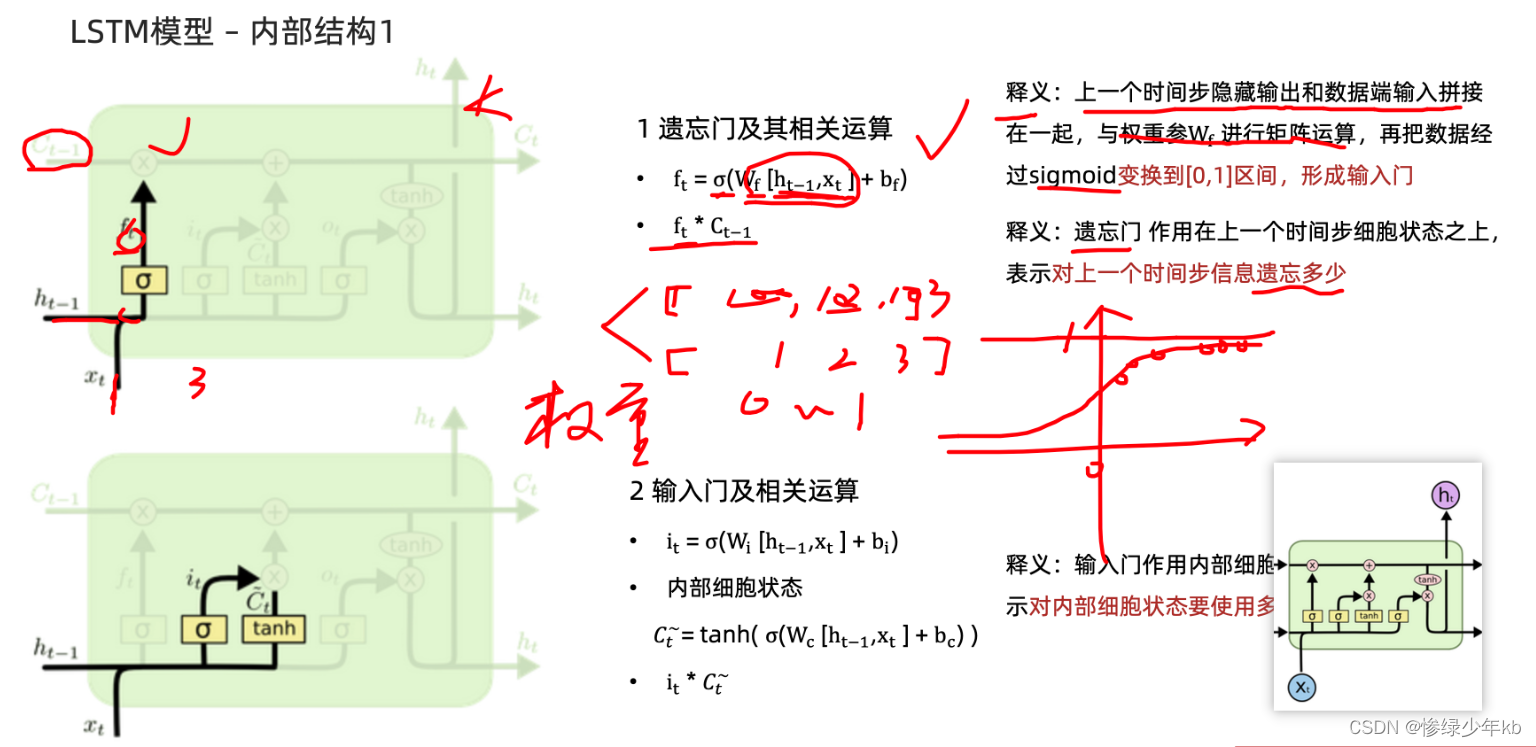
3 场景:细胞状态和输入门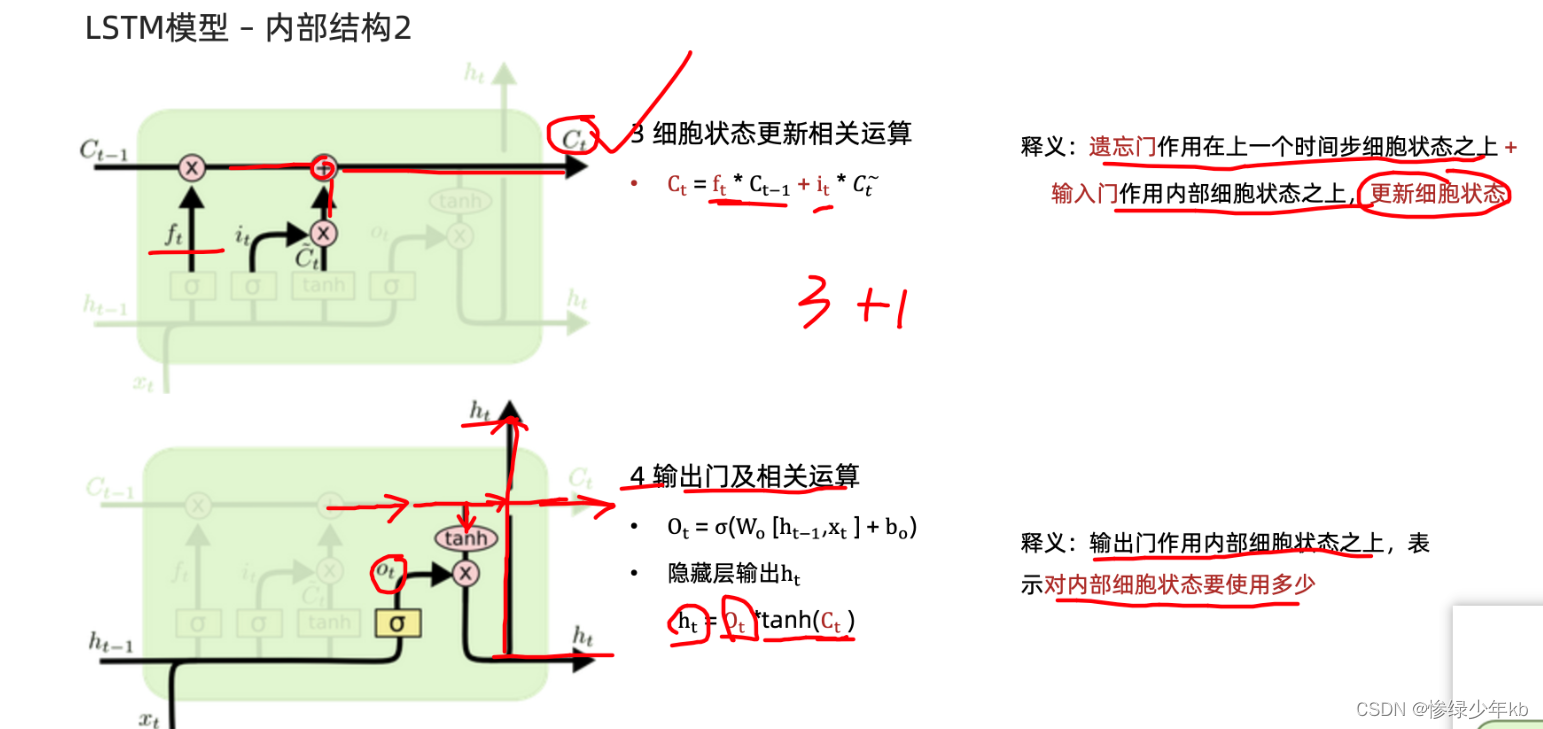
1.4 GRU模型
1 场景:门的综合图
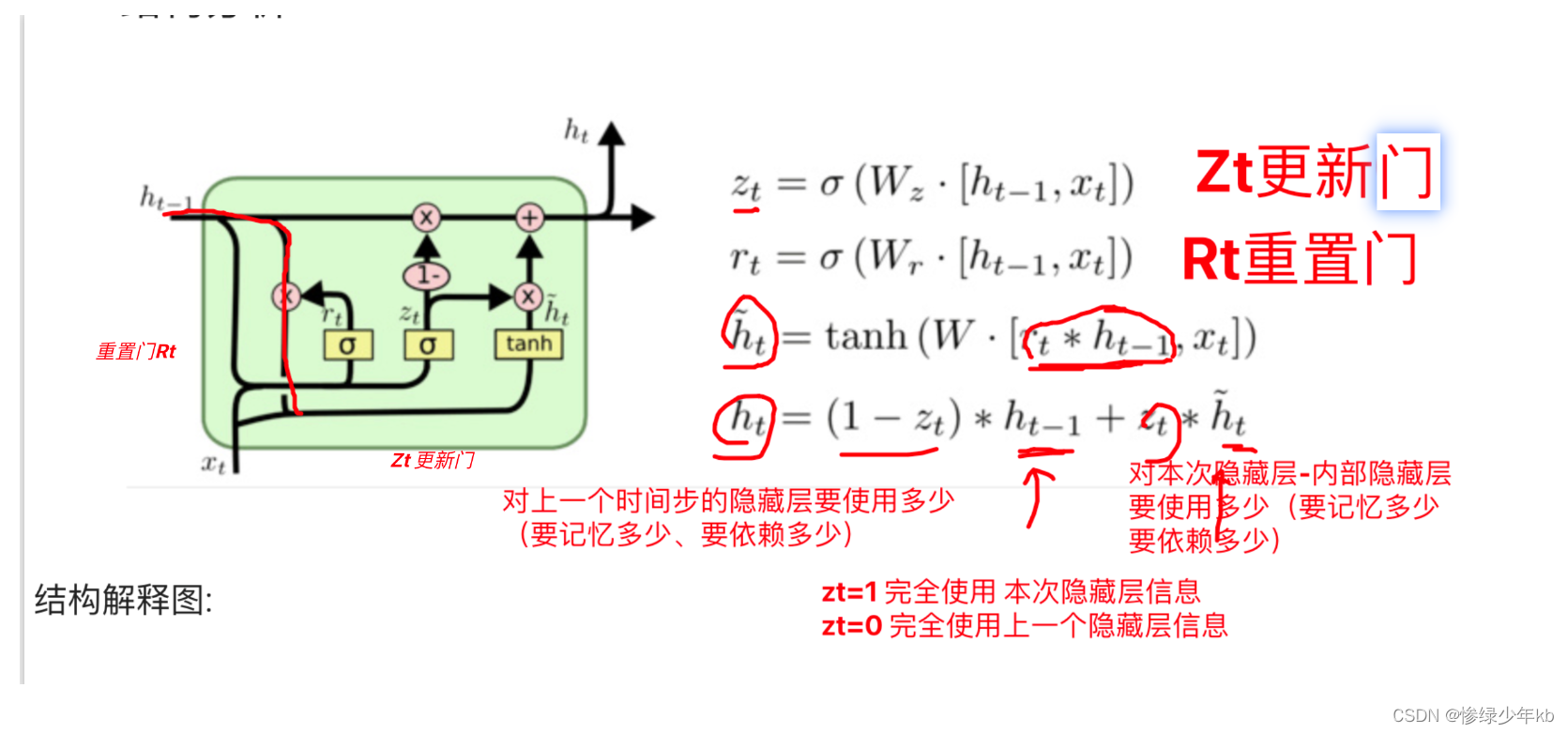
2场景 矩阵参数数量对比

3 场景:有关批量的给RNN送数据
重要场景


