
- 1Weblogic上传shell路径_weblogic绝对路径
- 2GitHub Copilot 学生认证_copilot 学生续期
- 3配置本地yum源
- 4互联网晚报 | 奇瑞汽车回应要求员工周六上班;好欢螺回应妇女节争议文案;TVB淘宝首播带货2350万...
- 5大数据最新hadoop3 HA部署(1),已拿offer_hadoop3 ha 集群部署
- 6如何在 Java 中将 String 转换为 int?_java string转int
- 7springMVC的导入导出操作_springmvc实现导入导出
- 8WPF之Prism框架_wpf prism开发框架示例
- 9Excel内置Python:给工作带来的变革
- 10LLaMA 3:大模型之战的新序幕_llama3 15b挑战了scaling law吗
SoC芯片设计-AI加速器互连技术分析
赞
踩

SoC芯片设计系列-AI加速器互连技术
AI加速器互连技术
1、概述
AI加速器互连技术,高效数据传输与计算资源协同的核心,尤其在高性能计算、数据中心与分布式计算中。关键互连技术包括:...,助力实现卓越性能。
PCIe(Peripheral Component Interconnect Express)作为顶级高速接口标准,广泛用于连接计算机外设,尤其适配AI加速卡。新一代PCIe 4.0与PCIe 5.0分别实现16 GT/s与32 GT/s的超高带宽,完美满足AI加速器对高速数据传输的严苛需求。凭借卓越的通用性和广泛支持,PCIe已成为加速器连接的首选技术,引领着计算领域的新潮流。
NVLink,NVIDIA的创新之作,专为GPU间及与CPU的高速、低延迟通信打造。其带宽远超PCIe,极大提升了多GPU系统的并行计算与数据共享效率,是高性能计算领域的革新技术。
NVSwitch,由NVIDIA倾力打造,专为多GPU系统量身定做的交换技术,构建GPU间的高速互联网络。该技术实现全带宽通信,大幅提升大规模并行计算效率,引领多GPU性能飞跃。
CXL是Intel主导的新兴开放行业标准,优化CPU与加速器、内存扩展设备的互连。它支持内存共享、缓存一致性等高级功能,尤其适用于加速AI计算,引领计算性能的新高度。
AMD的Infinity Fabric技术,作为领先的片上和芯片间互连解决方案,无缝连接CPU、GPU及多种加速器。在AMD Instinct MI300X平台上,该技术集成多个GPU模块,显著提升了系统的数据交换效率,为计算性能带来质的飞跃。
6. UAIlink: 超级加速器链(Ultra Accelerator Link,UALink)同样是一种可提高新一代AI/ML集群性能的高速加速器互连技术。八家发起厂商(和超级以太网联盟一样,我们也没有在UAlink联盟中看到英伟达的身影)也成立了一个开放行业标准机构来制定相关技术规范,以促进新使用模式所需的突破性性能,同时支持数据中心加速器用开放生态系统的发展。包括AMD、博通(Broadcom)、思科(Cisco)、Google、惠普(Hewlett Packard Enterprise,HPE)、英特尔(Intel)、Meta和微软(Microsoft)在内的八家公司宣告,他们已经为人工智能数据中心的网络制定了新的互联技术UALink(Ultra Accelerator Link)。
通过为人工智能加速器之间的通信建立一个开放标准,以打破市场领导者 Nvidia的垄断。
互连技术的优化,特别是针对AI应用,是突破数据传输瓶颈、提升计算效率、促进异构计算架构融合的关键。面对AI模型和工作负载的日益复杂,高效、低延迟的互连方案愈发不可或缺。
2、PCIe
PCIe(Peripheral Component Interconnect Express)是高速串行计算机扩展总线标准,连接主板与硬件如显卡、固态硬盘、网卡等。自2003年发布以来,PCIe已迭代至PCIe 3.0、PCIe 4.0,PCIe 5.0亦逐渐普及。其关键特征包括高带宽、低延迟,为现代计算提供强劲动力。无论AI加速还是数据处理,PCIe均展现卓越性能,推动科技飞速发展。
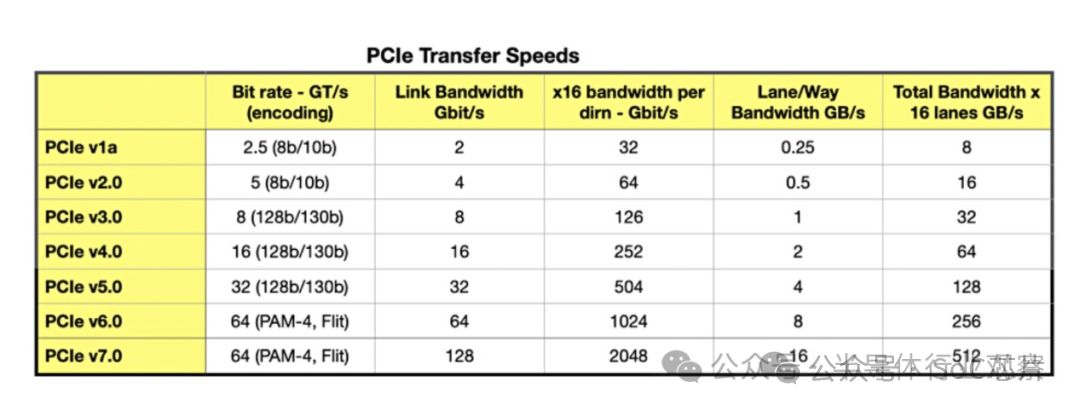
PCIe标准不断刷新数据传输速度。PCIe 3.0通道速率达8GT/s,PCIe 4.0翻倍至16GT/s,PCIe 5.0再翻倍至惊人的32GT/s。每个PCIe插槽可配置1至16条通道,带宽随通道数成倍增长。高速传输,助力您轻松应对大数据挑战,释放无限潜能。
4. 兼容性卓越:新PCIe标准设备兼容旧插槽,确保向后兼容,但速度受限于旧标准最大速率,确保稳定运行。
PCIe凭借卓越性能与广泛适用性,已成为高性能外设连接的行业标准,现代计算机系统普遍支持,实现无缝集成。
PCIe接口在AI加速、高性能计算、图形处理及存储解决方案等领域,凭借高速率特性,对满足数据密集型应用需求具有举足轻重的地位。
随着技术革新,PCIe标准的演进对于实现未来高数据传输速率和低延迟至关重要,特别是在云计算、数据中心及高性能计算等尖端领域,其影响不容小觑。
PCI-SIG于2024年四月初发布了PCI-Express 7.0规范的0.5版,这是第二版草案,标志着成员们向新标准提交功能的最后阶段。PCI-SIG借此更新重申,新标准的开发稳步进行,预计将于2025年发布最终版本,确保行业技术的持续创新与演进。
PCIe 7.0,引领下一代计算机互连技术革命。其数据传输速度高达128 GT/s,较PCIe 6.0翻倍,较PCIe 5.0更是提升四倍。16通道(x16)连接支持双向256 GB/秒带宽,无编码开销。这一飞跃性提升,将极大满足未来数据中心、人工智能及高性能计算对高速数据传输的迫切需求,开启全新的数据处理时代。

PCIe 7.0革新数据传输速率,其物理层总线频率翻倍,远超PCIe 5.0与6.0。它保留PAM4信令、1b/1b FLIT编码和FEC技术,确保数据稳定可靠。PCI-SIG强调,PCIe 7.0更专注于优化通道参数、扩大覆盖范围及提升功率效率,展现其卓越性能与前瞻性设计,引领未来数据传输新篇章。
总体而言,鉴于 PCIe 7.0 需要将物理层的总线频率加倍,而 PCIe 6.0 通过 PAM4 信令回避了这一重大发展,因此该标准背后的工程师们的工作量很大。在改善数据信号方面,没有什么是免费的,而对于 PCIe 7.0,PCI-SIG 可以说又回到了硬模式开发,因为需要再次改进物理层——这次是为了使其能够在 30GHz 左右运行。
不过,有多少繁重的工作将通过智能信号发送(和重定时器)来完成,有多少将通过纯粹的材料改进(例如更厚的印刷电路板(PCB)和低损耗材料)来完成,仍有待观察。
PCIe 7.0的关键里程碑是完成0.7版规范,即完整草案。此版本要求各方面均详尽定义,并通过测试芯片验证电气规范。一旦发布,将不再增加新功能。鉴于PCIe 6.0历经0.3至0.9版才定稿,PCIe 7.0有望遵循相似路径,迈向成熟标准。
预计PCIe 7.0硬件在2025年规范确定后仍需数年方能上市。尽管控制器IP和初始硬件研发已启动,但整个开发流程远超规范发布范畴,仍需耐心等待。
PCI-SIG预告,PCIe 7.0规范预计2025年全面发布,涵盖功能升级目标,引领未来数据传输新篇章。
x16配置实现128 GT/s原始比特率,双向比特率高达512 GB/s,性能卓越,满足高速数据传输需求。
2.利用 PAM4(4 级脉冲幅度调制)信令;
4.继续实现低延迟和高可靠性目标;
5.提高电源效率;
6.保持与所有前几代 PCIe 技术的向后兼容性;
PCIe 7.0技术专为数据密集型市场(如800G以太网、AI/ML、超大规模数据中心、HPC、量子计算和云)打造,提供可扩展的互连解决方案。
该技术专注于提升通道参数、扩大覆盖范围,并优化能效,以满足高带宽应用需求,成为行业创新的有力支撑。
3、NVLink
NVLink,NVIDIA打造的高速互连技术,专为提升GPU间及GPU与CPU数据传输速度与效率而设计,确保数据传输高效迅捷,引领计算性能新纪元。
NVLink高速带宽,显著超越传统PCIe总线,为多GPU系统带来性能飞跃。第四代NVLink带宽高达每秒900GB/s,是PCIe 5.0的7倍。这一突破对深度学习、高性能计算和大数据分析等需求快速数据交换的应用至关重要,助力行业实现更高效率与卓越性能。
NVLink实现低延迟,点对点直接连接大幅减少数据传输延时,显著加速GPU间及GPU与CPU的通信,显著提升系统响应速度与运行效率。
3. 并行处理优化:NVLink技术在多GPU环境下实现显存直连,摒弃系统内存中转,显著提升并行处理效率与数据共享速度,完美适配高数据交换需求的任务。
NVLink技术突破GPU间通信局限,支持GPU与CPU互联,显著提升系统架构灵活性。借助NVLink桥接器和NVSwitch,轻松构建多GPU复杂拓扑,满足各种计算规模需求,展现卓越适应性。
NVLink不仅提供高带宽,其能效也卓越,每字节数据传输仅耗1.3皮焦,能效比PCIe 5.0高出5倍,显著降低大规模数据中心运营成本,为高效运算提供坚实支持。
NVLink技术显著提升NVIDIA高性能计算产品线如Tesla系列GPU在数据中心与专业计算系统中的性能,对计算密集型应用至关重要。

NVLink,作为Nvidia的创新技术,最初用于整合GPU内存。随后,Nvidia Research突破性地研发出交换机,支持杠铃和十字交叉方形拓扑,实现两个以上GPU的高效互联,甚至四个GPU的协同工作。这一技术借鉴了数十年CPU双插槽和四插槽服务器的经典拓扑设计,为GPU计算领域带来了革命性的变革。
AI系统曾需8至16个GPU共享内存,简化编程并提升数据访问速度。为满足这一需求,基于Volta V100 GPU的DGX-2平台于2018年率先采用NVSwitch技术,实现了GPU间的快速互联,从而大幅提升了实验室计算性能,实现了商业化的跨越式发展。
NVLink现以每秒1.8TB的惊人速度在GPU间传输数据。更有NVLink机架级交换机,支持高达576个完全连接的GPU,实现无阻塞计算结构。通过NVLink连接的GPU构成“pod”,拥有独立的数据和计算域,展现卓越性能。
4、CXL(Computer Express Link)
Compute Express Link (CXL) 是由 Intel 领衔,携手阿里巴巴、思科、戴尔、Facebook、Google、IBM、微软、英伟达等行业巨头共同打造的新型高速互连技术。专为满足数据中心内 CPU 与加速器、内存、I/O 设备间日益增长的数据交换需求而生,特别是在人工智能、机器学习及大数据处理等高性能计算领域。CXL 标准的核心优势在于其高效的数据处理能力,为现代计算场景提供了强大的支持。
CXL实现高速互连,带宽远超传统PCIe。CXL 1.0版本支持32GT/s传输速率,匹敌PCIe 5.0。其独特之处在于引入新功能,优化内存与加速器访问效率,为数据处理带来革命性提升。
2. 内存一致性:CXL 引入了内存一致性(Cache Coherent Interconnect)功能,这意味着连接到 CXL 总线的设备可以直接访问和共享主系统内存,而不需要通过CPU,大大减少了数据传输延迟,提高了数据处理效率。3. 多种设备支持:CXL 支持三种设备类型:CXL.cache(用于内存扩展)、CXL.memory(增强的内存设备)和 CXL.io(传统的I/O设备),这使得CXL成为一个灵活的互连解决方案,适用于多样化的加速器和存储设备。
CXL具备PCIe 5.0物理层向后兼容性,允许现有PCIe设备通过适配器轻松融入CXL系统,既保护投资又简化过渡,为技术演进提供平滑路径。
优化AI与数据中心应用,CXL助力GPU、FPGA及AI芯片与CPU高效协同,加速数据交换与处理,尤其适用于机器学习模型训练、推理及大数据分析,大幅提升计算效率。
CXL标准的发布,是数据中心架构的里程碑式进步。它突破数据密集型应用性能瓶颈,为计算体系结构开启新篇章,推动异构计算发展。随着CXL技术日益成熟,其在加速计算、内存扩展及高性能计算领域的潜力愈发凸显,未来可期。
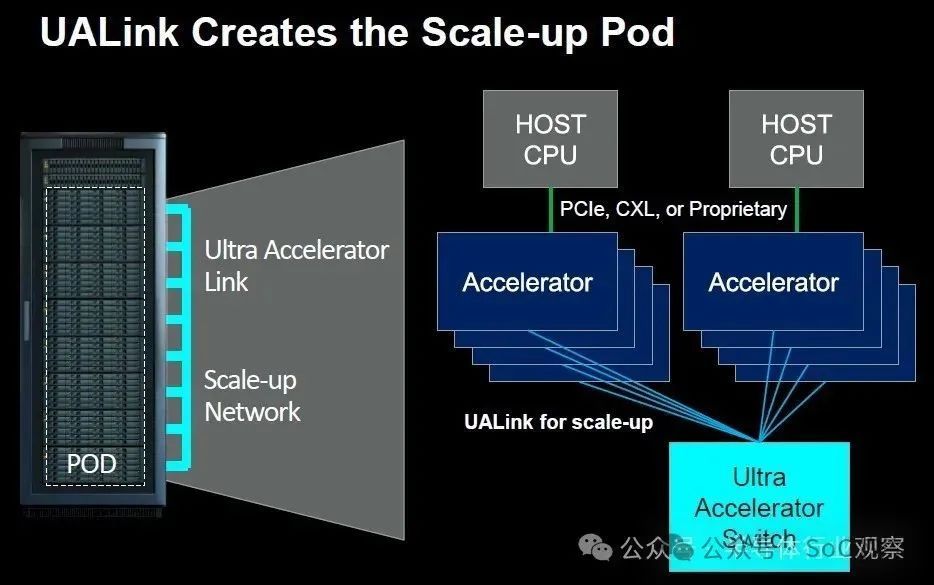
5、UALink(Ultra Accelerator Link)
超级加速器链(UALink)是一项高速加速器互连技术,专为提升新一代AI/ML集群性能而设计。八家领军企业携手成立开放行业标准机构,制定技术规范,旨在推动突破性性能以满足新应用需求,同时支持数据中心加速器的开放生态系统发展。UALink联盟中尚未见到英伟达身影,但行业合力正驱动着技术革新。
从相关资料可以看到,Ultra Accelerator Link 联盟的核心于去年 12 月就已经建立,当时 CPU 和 GPU 制造商 AMD 和 PCI-Express 交换机制造商博通表示,博通未来的 PCI-Express 交换机将支持 xGMI 和 Infinity Fabric 协议,用于将其 Instinct GPU 内存相互连接,以及使用 CPU NUMA 链接的加载/存储内存语义将其内存连接到 CPU 主机的内存。
相关消息显示,这将是未来的“Atlas 4”交换机,它将遵循 PCI-Express 7.0 规范,并于 2025 年上市。博通数据中心解决方案集团副总裁兼总经理 Jas Tremblay 证实,这项工作仍在进行中,但不要妄下结论。换而言之,我们不要以为 PCI-Express 是唯一的 UALink 传输,也不要以为 xGMI 是唯一的协议。
AMD 为 UALink 项目贡献了范围更广的 Infinity Fabric 共享内存协议以及功能更有限且特定于 GPU 的 xGMI,而所有其他参与者都同意使用 Infinity Fabric 作为加速器互连的标准协议。
英特尔高级副总裁兼网络和边缘事业部总经理 Sachin Katti 表示,由 AMD、博通、思科系统、谷歌、惠普企业、英特尔、Meta Platforms 和微软组成的 Ultra Accelerator Link“推动者小组”正在考虑使用以太网第 1 层传输层,并在其上采用 Infinity Fabric,以便将 GPU 内存粘合到类似于 CPU 上的 NUMA 的巨大共享空间中。
如下图所示,我们分享了如何使用以太网将 Pod 链接到更大的集群:
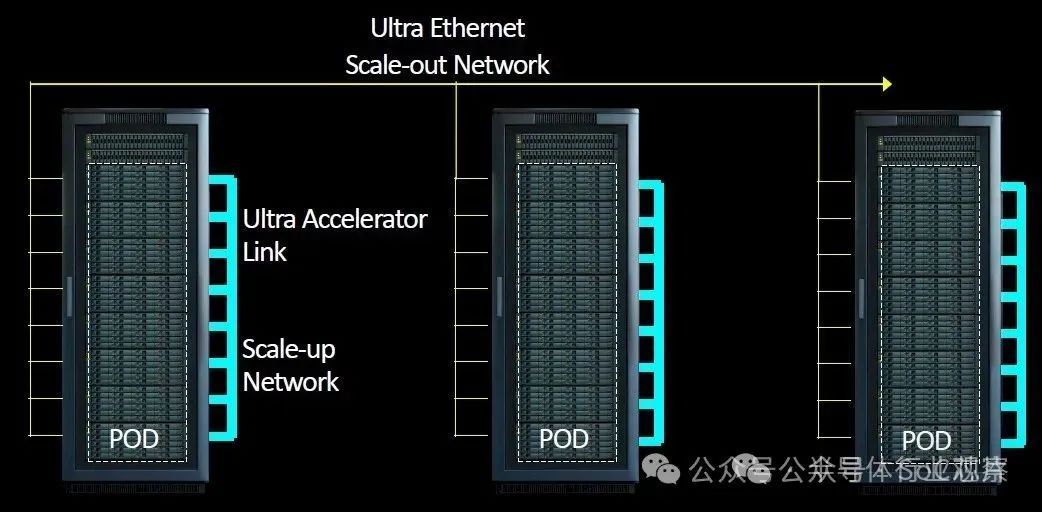
如thenextplatform所说,没人期望将来自多个供应商的 GPU 连接到一个机箱内,甚至可能是一个机架或多个机架中的一个Pod内。但 UALink 联盟成员确实相信,系统制造商将创建使用 UALink 的机器,并允许在客户构建其舱时将来自许多参与者的加速器放入这些机器中。您可以有一个带有 AMD GPU 的Pod,一个带有 Intel GPU 的Pod,另一个带有来自任意数量的其他参与者的自定义加速器Pod。它允许在互连级别实现服务器设计的通用性,就像 Meta Platforms 和 Microsoft 发布的开放加速器模块 (OAM) 规范允许系统板上加速器插槽的通用性一样。
UALink的核心优势在于为业界同步NVIDIA技术提供机遇。NVIDIA已掌握NVSwitch盒的制造能力,并将其融入NVIDIA DGX GB200 NVL72等产品中,展现了强大的技术实力。
英特尔AI加速器年销售额数亿美元,预计售出数万台。AMD MI300X虽数十亿美元,仍不敌NVIDIA。UALink技术助力Broadcom等公司制造交换机,助力企业扩大AI规模,实现多家公司加速器的高效互联。技术革新,推动AI产业蓬勃发展。
Broadcom Atlas交换机计划与AMD Infinity Fabric AFL Scale Up及NVIDIA NVLink展开竞争,预示其将搭载于PCIe Gen7交换机。据悉,该技术可能实现UALink V1.0,尽管该规范尚未正式发布。这一动向标志着Broadcom在高性能互联技术领域的积极布局,值得行业内外密切关注。
UALink 1.0版规范即将在2024年第三季度推出,支持AI容器组连接最多1,024个加速器,实现加速器(如GPU)内存间的直接加载与存储。UALink联盟已成立,预计同季度正式运作,并向联盟成员开放此规范。此规范将极大地推动AI计算效率,引领行业新标准。
ARM架构作为全球热门处理器架构,历经多年深耕,打造出多款经典、嵌入式及应用型处理器系列。其中,ARM Cortex系列作为ARM11的升级之作,广泛服务于不同市场,基于ARMv7或ARMv8架构,细分为Cortex-A、Cortex-R和Cortex-M三大系列,持续为客户提供卓越性能与可靠服务。

UCIe(通用芯片粒互联快车道)是业界巨头AMD、Arm、Google Cloud、Intel、高通、台积电、日月光、三星等共同推出的开放芯片粒互连标准。它旨在打破厂商壁垒,简化芯片粒互操作性,推动技术的广泛应用。UCIe的关键特性聚焦于提升芯片粒技术的互连效率与兼容性,为行业发展注入新动力。
UCIe通过通用物理层、协议层和软件堆栈规范,实现不同供应商芯片粒的无缝互连,无论是同一封装内还是跨封装。这一创新促进了芯片设计的模块化和灵活性,显著降低了设计复杂度和成本,为行业带来革命性变革。
多源兼容性卓越,兼容2.5D与3D封装技术,无缝对接各代工厂与封装商芯片粒,确保高效互通,实现跨源无缝融合。
高性能互连,实现高带宽、低延迟,灵活配置多种带宽,全面支持高性能计算、数据中心、移动及边缘计算等多场景需求。
安全性卓越,集成安全框架,涵盖认证、加密及数据完整性保护,确保芯片间通信安全,对云服务、数据中心等应用至关重要。
UCIe凭借标准化接口,简化了芯片粒设计与测试流程,快速验证并加速产品上市。开发者可轻松利用最佳芯片粒组合,构建定制化系统级芯片(SoC),实现高效开发与灵活定制。
UCIe标准的发布,引领芯片行业迈向模块化、异构集成新时代,将促进设计创新,降低开发成本,加速新技术商业化。此举对提升AI、高性能计算和数据中心等领域的系统性能和能效具有深远影响,意义重大。
UCIe规范深受英特尔AIB技术启发,该技术已于2020年赠予CHIPS联盟。UCIe规范全面涵盖物理层、通讯电气信号标准、通道数量及触点间距,并定义高阶协议与必要功能集,展现强大兼容性与灵活性。
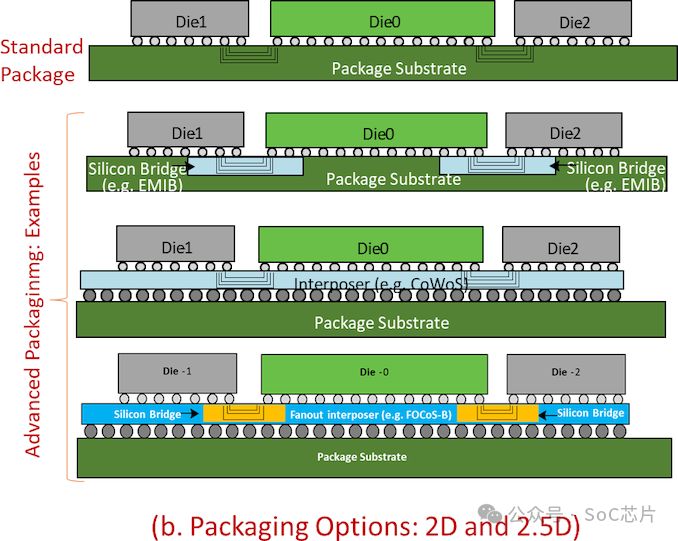
UCIe虽未规定芯粒间物理连接封装与桥接技术,但允许通过硅中介层等多种方式协同工作。只要芯粒符合UCIe标准,无论封装或桥接方式,均可与另一支持UCIe的芯粒实现通讯,展现了高度的灵活性和兼容性。
中间层由Die to Die适配单元管理链路状态、协商参数,并增设CRC循环冗余校验码与链路级重试功能,为数据传输提供双重可靠性保障。
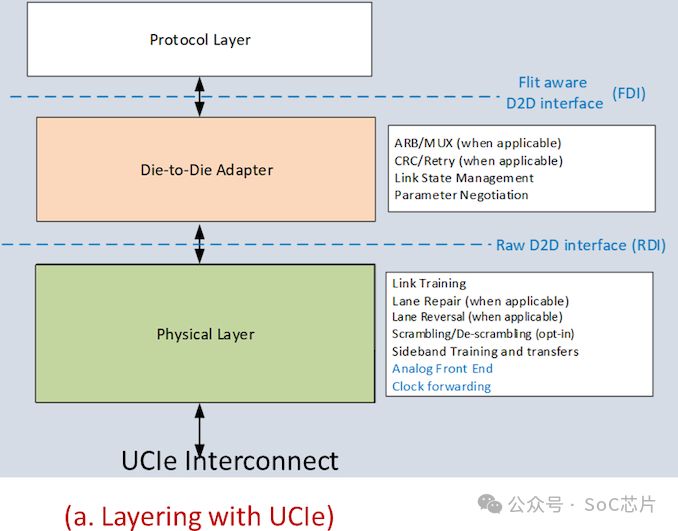
厂商在协议层将享有多重选择,特别是CXL(Compute Express Link)标准,这一源自PCIe的创新技术,为行业带来更广泛的标准化支持。
UCIe组织声明技术来源不局限于PCIe、CXL标准,将视需求灵活选择其他互联协议,确保技术前沿与多元化。
UCIe虽主打芯粒互联,但也支持片外连接。芯片与系统制造商可借助UCIe构建远程通讯,虽需牺牲延迟与功率,但可实现机架间服务器通讯,甚至光学互联,为行业带来革新性解决方案。
UCIe 1.0规范标志着新纪元的开端,专注于物理层与通讯协议,主要适用于2D及2.5D芯片封装。尽管面对AMD的Infinity Fabric或英特尔Foveros Direct 3D技术时略显基础,但对多数厂商而言,通过IP芯片选购与不同制程芯片互联,实现高效益与成本优化,仍极具吸引力。
UCIe自发布起,即获谷歌、微软、Meta等巨头支持,ASE Group、高通亦加入,联盟阵容强大。然而,NVIDIA却未在其列。在GTC2022上,NVIDIA推出了NVLink-C2C技术,实现了GPU与CPU的互联,独树一帜地构建了自家的互联体系,与AMD IF、英特尔Foveros齐名,展现了其技术实力与创新精神。

-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-

