
- 1【RabbitMQ】RabbitMQ配置与交换机学习_rabbit mq 交换机怎么加
- 2MySQL8.0两台数据库互为主从实验_mysql8.0主从切换
- 3MySQL8新特性:公用表表达式_mysql 公共子表达式
- 4【深度学习】变分自编码器 VAE,什么是变分?(1)
- 5手把手教你用coze (扣子)打造一个属于自己的微信AI对话机器人_扣子打造自己
- 6git切换分支报错:error: pathspec ‘dev‘ did not match any file(s) known to git._error: pathspec 'dev' did not match any file(s) kn
- 7智能制造不是机器人_智能制造是个伪命题
- 8python第三方库安装[pip、whl]_python-pip-whl
- 9什么是大模型?大模型有什么用?为什么要学习大模型?_大模型研究意义
- 10【Sql Server】新手一分钟看懂在已有表基础上增加字段和说明_sql新增字段
终于等到你!PaddleOCR 新版本发布!
赞
踩

PaddleOCR是基于飞桨深度学习开源框架的文字识别开发套件,旨在打造一套丰富领先实用的OCR工具库,打通数据准备、模型训练、压缩和推理部署全流程。在开源社区的热烈期盼与共同努力下,PaddleOCR迎来了里程碑式的版本更新——v2.8.0!本次更新不仅引入了前沿的OCR技术成果,还对项目结构进行了深度优化,解决了若干历史疑难问题,旨在为广大开发者提供更加高效、便捷的OCR解决方案。
让我们一同探索一下PaddleOCR v2.8.0带来的全新体验与无限可能吧!
 顶尖模型引入,引领OCR技术潮流
顶尖模型引入,引领OCR技术潮流
PaddleOCR v2.8.0隆重引入了PaddleOCR算法模型挑战赛的冠军方案,为OCR领域树立了新的标杆。
其中,赛题一“OCR端到端识别任务”的冠军方案——场景文本识别算法SVTRv2,以其卓越的识别性能与泛化能力,为用户带来了前所未有的识别体验,如下图所示。
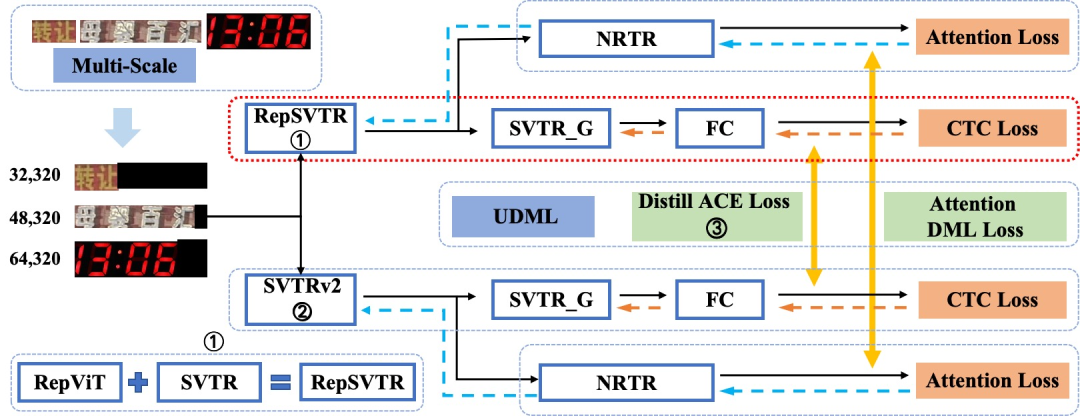
SVTRv2技术方案示意图
赛题二“通用表格识别任务”的冠军方案——表格识别算法SLANet-LCNetV2,则以其精准高效的表格识别能力,为数据处理与分析提供了强有力的支持,如下图所示。

SLANet-LCNetV2技术方案示意图
 项目结构优化,聚焦OCR核心
项目结构优化,聚焦OCR核心
为了进一步提升PaddleOCR项目的专业性与易用性,我们决定将非核心模块PPOCRLabel和StyleText迁移至新的仓库,使PaddleOCR项目更加专注于OCR与版面识别的核心技术。这不仅简化了项目结构,也为开发者提供了更加清晰的项目导航与资源访问路径。
详见:https://github.com/PaddlePaddle/PaddleOCR/discussions/13020

历史疑难问题解决,提升用户体验
为提升广大开发者的使用体验,在新版本中,我们重点解决了更新Backbone后无法运行模型、numpy版本依赖冲突、Mac系统中运行卡顿等一系列历史疑难问题。部分疑难问题还在解决过程中,欢迎广大开发者一起参与!
详见:https://github.com/PaddlePaddle/PaddleOCR/discussions/13057

其它优化改进,持续精进
除了上述重大更新外,PaddleOCR v2.8.0还包含了一系列细微但重要的优化改进。包括但不限于:
1. 解决版面分析中,OCR结果偶尔丢失的问题。
2. 添加 pyproject.toml,使PaddleOCR符合 PEP 518规范。
3. 对于大图推理,引入滑动窗口操作。
这些改进旨在进一步提升软件的稳定性、兼容性和性能表现,确保PaddleOCR能够应用在更广泛的场景。
开源共建,共创辉煌
需要特别强调的是,PaddleOCR v2.8.0的每一个进步与成就都离不开开源社区的支持与贡献。在PMC(Project Management Committee)的统一管理下,众多社区开发者携手并进,共同努力,才使得PaddleOCR能够不断前行、日益完善。这里要特别感谢PaddleOCR PMC成员:GreatV (PMC Chair)、tink2123 (PMC Chair)、Topdu 、SWHL、Liyulingyue、Sunting78、jzhang533,也感谢虽然暂未加入PMC但是作出了大量贡献的热心开发者。
新版本contributors列表,贡献者数量创历史新高!
PaddleOCR PMC信息详见:https://github.com/PaddlePaddle/PaddleOCR/discussions/13019
这里预告一下,为了更好地服务广大开发者,PaddleOCR文档教程专属站点正在由PMC展开建设。该站点将汇集仓库中原先散落在各处的文档资源,支持关键词检索功能,界面优雅舒适,相信大家一定会喜欢。
建设中的PaddleOCR文档教程专属站点
我们诚挚邀请更多开发者和开源爱好者加入我们的行列,一起将PaddleOCR越做越好!
PaddleOCR v2.8.0的发布是我们迈向新征程的重要一步。我们坚信,在未来的日子里,在大家的共同努力下,PaddleOCR将不断创新、持续进步,为OCR领域的发展贡献更多的智慧与力量!
如有技术问题问询、产品使用反馈、商业合作,欢迎通过paddle-up@baidu.com与我们取得联系




关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
点击阅读原文,体验PaddleOCR 新版本!

