
- 1arm64 aarch64 gcc版本信息_gcc arm版本
- 2网络安全之认识日志采集分析审计系统_日志审计
- 3python小游戏开心消消乐制作4-点击消除事件_pygame 获取鼠标点击事件
- 4Antimalware Service Executable占用内存较高问题_antimalware service占用率极高
- 5基于VPN服务器+内网穿透的远程局域网搭建教程_softether csdn
- 6在OS X安装Docker
- 7区块链安全————区块链技术安全讨论_交易平台的密码安全方案
- 8国内首个网络安全行业全景图重磅推出_网关安全业务全景图
- 9查看Linux系统日志及Hadoop日志_linux hdm日志
- 10嵌入式初学-C语言-二
Elasticsearch 索引与文档操作实践指南_elasticsearch文档id
赞
踩
上节我们部署了elasticsearch8.4.1和kibana8.4.1以及ik分词器,本节我们来学习下elasticsearch的相关索引,文档操作。
首先我们kinana的主界面找到开发者工具在里面我们来编写相关操作。
标题查看集群情况
GET /_cluster/health
- 1

详细解释:
- cluster_name: 这是Elasticsearch集群的名称,这里命名为"my-application"。 status:
集群的健康状态。这里的状态是"yellow",表示所有的主分片都已分配,但至少缺少一个副本。Elasticsearch中的健康状态有三种颜色: - green:所有的主分片和副本分片都是活动的。
- yellow:所有的主分片都是活动的,但不是所有的副本都是活动的。数据仍然完整,但高可用性可能受到影响。
- red:一些主分片不可用,可能会丢失数据。 timed_out: 表示查询是否超时。这里的值是false,意味着查询没有超时。
- number_of_nodes 和 number_of_data_nodes:
分别表示集群中的节点总数和数据节点的数量。这里都是1,说明集群中只有一个节点,且这个节点是数据节点。 - active_primary_shards 和 active_shards:
分别表示活跃的主分片和总的活跃分片数量。这里都是10,说明有10个主分片是活跃的,且没有额外的副本分片(因为总数也是10)。 - relocating_shards: 正在迁移的分片数量。这里是0,表示没有分片在迁移。 initializing_shards:
正在初始化的分片数量。这里是0,表示没有分片在初始化。 unassigned_shards:
未分配的分片数量。这里是2,通常这表示有分片因为某些原因(如节点故障、磁盘空间不足等)没有被分配到任何节点上。这是集群状态为yellow的一个原因,因为有副本分片没有被分配。 - delayed_unassigned_shards: 延迟未分配的分片数量。这里是0,表示没有延迟未分配的分片。
- number_of_pending_tasks: 集群中等待执行的挂起任务数量。这里是0,表示没有挂起的任务。
- number_of_in_flight_fetch: 当前正在进行的拉取操作数量。这里是0,表示没有正在进行的拉取操作。
- task_max_waiting_in_queue_millis: 任务在队列中等待的最长时间(毫秒)。这里是0,表示没有任务在等待。
- active_shards_percent_as_number: 活跃分片的百分比。
索引操作
创建索引
PUT /mall-shop
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
解释说明
- “settings”:这是一个包含索引级别设置的顶层对象。
- “number_of_shards”:定义了索引中主分片的数量。在这个例子中,它被设置为1,意味着索引将只有一个主分片。
- “number_of_replicas”:定义了每个主分片的副本数量。在这个例子中,它被设置为1,意味着每个主分片将有一个副本。
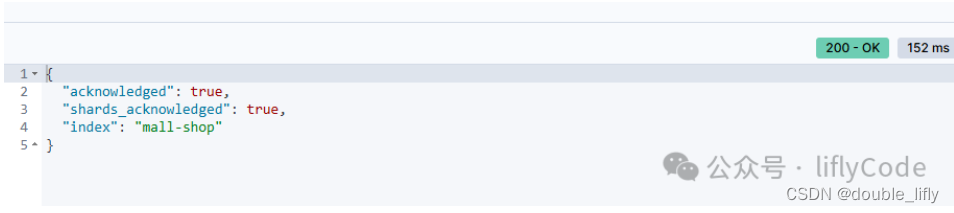
- acknowledged":表示请求是否已经被集群中的主节点所接收。在这里,它被设置为true,意味着请求已被接收。
- “shards_acknowledged”:在Elasticsearch中,索引操作是分布式的,并且会涉及多个分片。这个字段表示分片级别的操作是否已经被成功接收。在这里,它被设置为true,意味着所有相关的分片都接收到了操作请求。
- “index”:返回了操作的索引名称,这里是mall-shop。
更新索引
PUT /mall-shop/_settings
{
"settings": {
"number_of_replicas": 0
}
}
- 1
- 2
- 3
- 4
- 5
- 6

查询索引列表
GET /_cat/indices?v=true&pretty
- 1

查看索引是否存在
GET /mall-shop
- 1

解释说明:
- mall-shop:这是索引的名称,即mall-shop。
- aliases:这是一个空的对象,意味着当前没有为该索引设置别名。别名在Elasticsearch中是一个很有用的功能,允许你为索引提供一个或多个额外的名称,这样你就可以通过别名来查询索引,而不是直接使用索引名。
- mappings:这也是一个空的对象。在Elasticsearch中,mappings定义了索引中每个字段的类型、属性和其他设置。例如,你可以指定某个字段是字符串类型、整数类型、是否应该被索引、是否应该被分析等等。这里为空,可能意味着索引尚未定义任何字段的映射,或者这是一个空的、新的索引。
- settings:这部分包含了索引的设置和元数据。
- routing:定义了与路由相关的设置。在这里,它有一个allocation子对象,用于定义索引分片的分配策略。
- number_of_shards:定义了索引的主分片数量。在这里,它被设置为"1",意味着这个索引只有一个主分片。
- provided_name:这是索引的原始名称,即mall-shop。
- creation_date:这是一个时间戳,表示索引的创建时间。但这里的值"1719236130118"看起来不是一个典型的时间戳格式,可能是示例数据或经过某种处理的。
- number_of_replicas:定义了每个主分片的副本数量。在这里,它被设置为"0",意味着这个索引没有副本。
- uuid:是索引的唯一标识符,通常用于管理和引用特定的索引。
- version:包含了与索引版本相关的信息。
- include:定义了哪些节点应该被包括在索引分片的分配中。这里指定了一个_tier_preference条件,即只有带有"data_content"这个标签的节点才会被考虑用于分配索引的分片。
- created:表示创建索引时Elasticsearch的版本号。这里的"8040199"同样看起来不是一个典型的版本号,可能是示例数据或某种特定的标识符。
- index:这是一个嵌套的JSON对象,包含了索引的特定设置。
删除索引
DELETE /mall-shop
- 1

文档操作
新增文档(指定id,不指定系统也会帮我们自动生成)
PUT /mall-shop/_doc/1
{
"id":101,
"title":"study elasticsearch 8.4.1",
"pv":100
}
- 1
- 2
- 3
- 4
- 5
- 6

解释说明:
- _index: 这是操作发生的索引名称,即"mall-shop"。
- _id: 这是索引中文档的唯一标识符。在这个例子中,文档的ID是"1"。
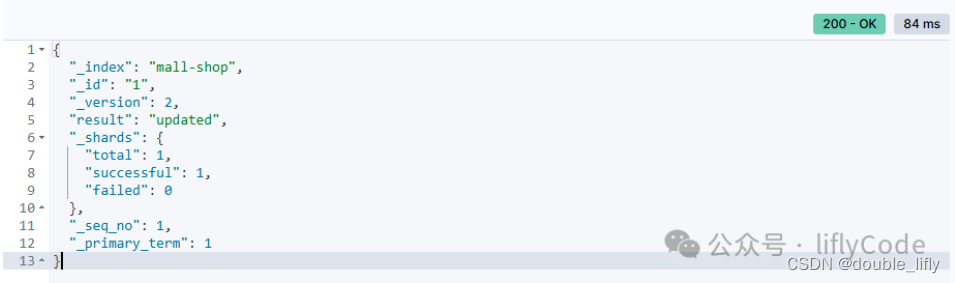
_version: 这是文档的当前版本。每次文档被索引、更新或删除时,其版本号都会递增。在这个例子中,版本号是1,表示这是一个新创建的文档。 - result: 这表示操作的结果。“created"表示文档已成功创建。如果文档已经存在并且你尝试使用相同的ID再次索引它,结果可能会是"updated”。
- _shards: 这是一个关于分片操作的信息块。在Elasticsearch中,索引被分割成多个分片,并且每个分片都可以有零个或多个副本。
- total: 操作涉及的总分片数。在这个例子中,它是1,意味着索引只有一个分片(或操作只涉及一个分片)。
- successful: 成功操作的分片数。这里是1,表示所有涉及的分片都成功完成了操作。
- failed: 失败操作的分片数。这里是0,表示没有分片在操作中失败。
- _seq_no: 这是文档在索引中的序列号。Elasticsearch 6.x及更高版本引入了序列号(sequence numbers)和主要术语(primary terms)作为乐观并发控制(optimistic concurrency control)的一部分。序列号用于跟踪文档版本和确定文档操作的顺序。在这个例子中,序列号是0,因为这是一个新创建的文档。
- _primary_term: 这是与文档相关的主要术语。它也是乐观并发控制的一部分,用于在文档复制和恢复过程中识别文档的“时代”。在这个例子中,主要术语是1,表示这是与文档相关的第一个时代。
查看文档
GET /mall-shop/_doc/1
- 1
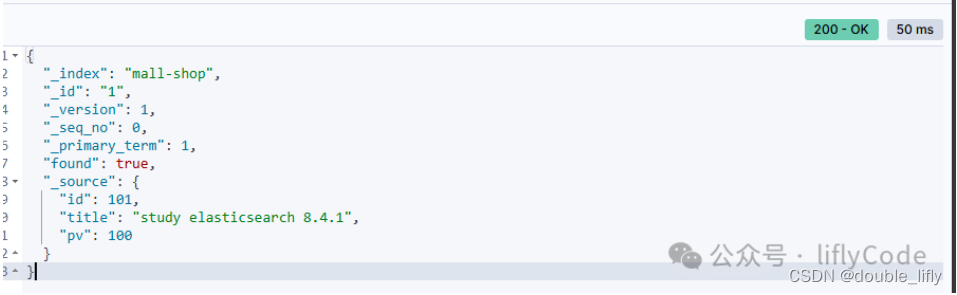
解释说明:
-
_index:这表示文档所在的索引名称,即"mall-shop"。
-
_id:这是文档的唯一标识符,即"1"。在Elasticsearch中,每个文档都有一个唯一的_id,用于在索引中标识和检索该文档。
-
_version:这是文档的版本号,即1。每当文档被修改时(如更新、删除后重新索引等),其版本号都会递增。这有助于跟踪文档的更改历史。
-
_seq_no:这是文档在索引中的序列号(sequence number)。Elasticsearch使用序列号来跟踪文档的变化,它是乐观并发控制(optimistic concurrency control)的一部分。序列号随着文档的变化而递增。
-
_primary_term:这是与文档相关的主要术语(primary term)。它与序列号一起用于在Elasticsearch中处理并发更新。主要术语在索引的主分片生命周期内是唯一的,并且当主分片被替换时(例如,由于故障转移),主要术语会增加。
-
found:这是一个布尔值,表示是否找到了与给定_id匹配的文档。在这个例子中,found是true,表示找到了文档。
-
_source:
id: 文档的内部ID,值为101。请注意,这与_id不同,_id是Elasticsearch中用于索引和检索文档的唯一标识符。
title: 文档的标题,值为"study elasticsearch 8.4.1"。这可能是一个描述文档内容的标题。
pv: 可能是页面浏览量(page views)的缩写,值为100。这可能表示该文档(可能是网页、商品页面等)已被访问或查看了100次。
这是文档的实际内容,也称为源字段(source field)。它包含了文档的所有原始JSON数据。在这个例子中,文档包含三个字段:
修改文档(pots/put都支持,需要指定id)
POST /mall-shop/_doc/1
{
"id":102,
"title":"post study elasticsearch8.4.1",
"pv":300,
"uv":101
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
搜索
GET /mall-shop/_search
- 1
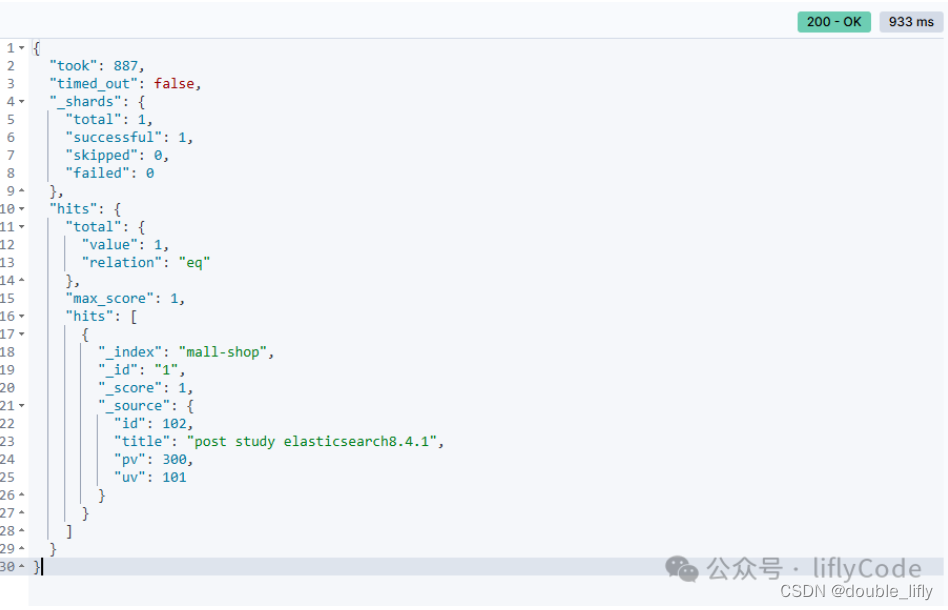
解释说明:
-
took:这个字段表示执行查询所花费的时间,以毫秒为单位。在这个例子中,查询花费了887毫秒。
-
timed_out:这是一个布尔值,表示查询是否超时。false表示查询没有超时。
-
_shards:
-
total: 查询涉及的总分片数。这里是1,意味着索引可能只有一个主分片。
-
successful: 查询成功执行的分片数。
-
skipped: 查询被跳过的分片数。在一些特定的查询和过滤条件下,某些分片可能不需要被查询,因此会被跳过。
-
failed: 查询失败的分片数。这里为0,表示所有涉及的分片都成功返回了结果。
这个部分提供了有关查询涉及的分片的信息。 -
hits:
- total:
- max_score: 查询返回文档中的最高评分。在Elasticsearch中,每个文档都有一个与查询相关的评分,这个评分决定了文档在结果列表中的排序。在这个例子中,所有匹配的文档评分都是1(可能是因为这是一个简单的term查询或match查询,且没有额外的评分逻辑)。
- hits:
- value: 匹配查询的文档总数。这里是1,表示只有一个文档匹配了查询条件。
relation: 表示value字段是如何与真实的文档数量相关的。"eq"表示value字段的值与真实的文档数量相等。 - _index: 文档的索引名,这里是mall-shop。
- _id: 文档的ID,这里是1。
- _score: 文档的评分,这里是1。
- _source: 这是文档的原始内容(即源JSON),包含了文档的所有字段和它们的值。在这个例子中,文档包含了id、title、pv和uv四个字段,分别表示文档的内部ID、标题、页面浏览量(page views)和独立访客数(unique visitors)。
这是一个数组,包含了查询返回的具体文档。在这个例子中,只有一个文档被返回。
这是查询返回的主要部分,包含了查询的结果。
- value: 匹配查询的文档总数。这里是1,表示只有一个文档匹配了查询条件。
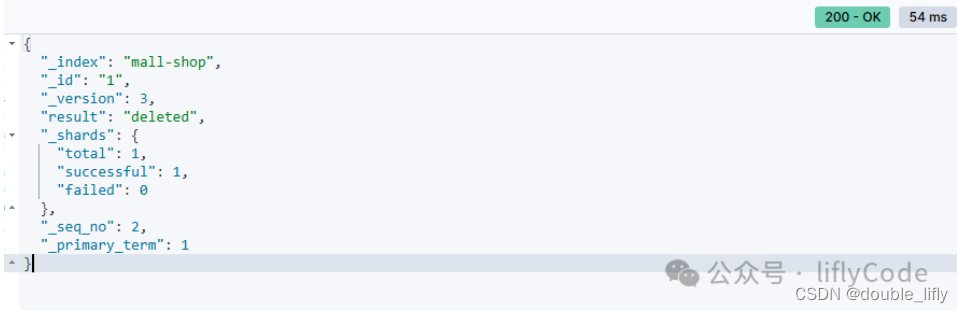
删除文档
DELETE /mall-shop/_doc/1
- 1
通过上述实践,我们不仅掌握了如何监控和管理Elasticsearch集群的健康状况,还学会了如何高效地操作索引和文档,这涵盖了从索引创建到文档的生命周期管理的全过程。理解并熟练运用这些基础操作,是构建复杂搜索应用和数据分析系统的基石。实践出真知,建议读者动手尝试这些命令,结合实际应用场景不断深化对Elasticsearch功能的理解和掌握,以支撑更加丰富多样的数据处理需求。
更多内容请关注一下公众号


