
- 1Java线程池ThreadPoolExecutor详解(一篇就够了)
- 2Python 提取地址中的省、市、县_python提取省份
- 3项目:对话系统。TTS和ASR流前端工程问题总结_vue asr+tts
- 4KDD 2024预讲会,40余位讲者相聚 | 明日开启
- 5面试官,不要再问我“Java虚拟机类加载机制”了_面试答案 java虚拟机类加载机制
- 6RedisSearch_php redis-search
- 7设置SqlServer服务启动方式及网络配置_sqlserver网络配置在哪
- 8设计模式七大原则——迪米特原则
- 9onnx标准 & onnxRuntime加速推理引擎_onnx runtime
- 10Linux Hadoop HDFS 操作 简记_linux hdfs
多模态MLLM都是怎么实现的(10)-Chameleon和Florence-2如果你想玩多模态就不能不了解_florence-2-large
赞
踩
这个也是一个补充文,前9章基本把该讲的讲了,今天这个内容主要是因为Meta出了一个Chameleon,这个以后可能会成为LLaMA的一个很好的补充,或者说都有可能统一起来,叫LLaMA或者Chamleon或者什么别的,另外我司把Florence的第二个版本开源了,google的paligemma瞬间啥也不是了!
Chameleon 5月16日就发了论文,昨天才正式开源
论文地址:2405.09818 (arxiv.org)
github地址:facebookresearch/chameleon: Repository for Meta Chameleon, a mixed-modal early-fusion foundation model from FAIR. (github.com)
其实现在多模态的模型特别多,为什么拿它出来说事,主要原因是它是目前开源世界里面第一个实现和GPTo一样的架构也就是所有的模态共有一套端到端网络(但是它似乎没全实现,feature deleliver进度上来讲)
我们先看一个反面教材LLaVA
也不算反面教材吧,市面上大多数的多模态都是这样的,这种方式叫后融合。
怎么理解后融合呢?
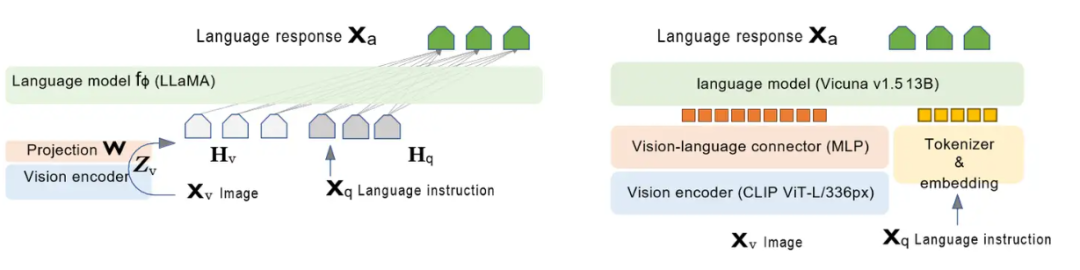
如上图所示是一个实际的LLaVA架构,
根据上面图,我们一起来定义啥叫后融合:
-
视觉编码器与语言模型分开:图中左侧的LLAVA架构将视觉编码器(Vision encoder)和语言模型的encoder(Language model )分开显示,这表明图像和语言的特征提取是独立进行的。(标粗标红)
-
融合在后续步骤进行:在视觉编码器处理完图像生成视觉特征ZvZ_v 后,这些特征通过投影(Projection W)得到视觉特征表示HvH_v(升降维和语言模型的token一个维度比如4096)。然后这些视觉特征
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/正经夜光杯/article/detail/1010011
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

